

Разработчики, оценивающие возможность использования GLM 4.7 Flash, сталкиваются с двумя насущными вопросами: сколько VRAM действительно требуется, и какой путь развертывания не позволит инфраструктуре стать источником лишних расходов. В этой статье мы даем ответы на оба вопроса, опираясь на конкретные цифры и операционную ясность. Мы разбиваем требования к VRAM для GLM 4.7 Flash по точным диапазонам, а затем сравниваем локальное самостоятельное развертывание с развертыванием через GPU-шаблоны, чтобы показать, как каждый из вариантов влияет на стоимость, уровень контроля, надежность и время до получения рабочего API. Цель проста: помочь вам получить стабильный, готовый к промышленной эксплуатации эндпоинт GLM 4.7 Flash с минимальными усилиями.
Требования к VRAM для GLM 4.7 Flash
GLM 4.7 Flash — это модель MoE на 30 млрд параметров, которая активирует только около 3,6 млрд параметров на каждый токен. Такая архитектура значительно снижает нагрузку на оперативную память во время работы по сравнению с плотными моделями того же класса. На практике варианты развертывания укладываются в узкий и предсказуемый диапазон VRAM.
| Точность / Квантизация | Приблизительный объем VRAM | Типовое оборудование | Сценарий использования |
|---|---|---|---|
| FP16 | 60 ГБ | A100, H100 | Исследования, тестирование производительности |
| FP8 | 30 ГБ | RTX 6000 Ada, L40S | Промышленное использование с минимальными потерями качества |
| Q8 | 22 ГБ | RTX 4090 | Баланс качества и стоимости |
| Q4 | 15 ГБ | RTX 3090, 4090 | Развертывание на потребительских GPU |
| Q3 | 12 ГБ | Граничные или ресурсоограниченные узлы | Для сценариев с максимальной чувствительностью к стоимости |
Попробуйте дешевые GPU сейчас!
Два пути развертывания GLM 4.7 Flash
Существует два основных способа развертывания GLM 4.7 Flash:
- Локальное самостоятельное развертывание с использованием движков таких как vLLM, SGLang или MLX
- Управляемое развертывание с использованием GPU-шаблонов на платформах вроде Novita
Оба в итоге предоставляют совместимый с OpenAI API. Разница заключается в том, кто несет операционную нагрузку.
Локальное самостоятельное развертывание GLM 4.7 Flash
Типичный локальный стек включает в себя:
- Драйвер NVIDIA и согласованность версий CUDA
- Установка PyTorch, vLLM или SGLang
- Загрузка модели и управление хранилищем
- Стартовые скрипты и привязка портов
- Контроль выполнения процессов и логика перезапуска
Этот путь оптимален для:
- Исследовательских задач
- Офлайн-сред
- Глубокой кастомизации движка
- Команд с большим опытом работы с инфраструктурой
Он рискован для начинающих разработчиков или быстро развивающихся продуктовых команд.
Развертывание GLM 4.7 Flash через GPU-шаблоны
GPU-шаблон определяет:
- Образ контейнера
- Стартовая команда
- Распределение дискового пространства
- Открытые порты
- Переменные окружения
- Поведение при загрузке
С точки зрения разработчика:
- Не нужно устанавливать CUDA
- Не нужно компилировать движок
- Не нужно настраивать сетевые соединения вручную
- Не нужно подключать модель вручную
| Аспект | Локальное развертывание | GPU-шаблон |
|---|---|---|
| Код, который вы пишете | Тысячи строк | Десятки строк |
| Слои, за которые вы отвечаете | Инференс, планирование, API, стриминг, обработка ошибок | Конфигурация и запуск |
| Требуемые знания | Внутреннее устройство GPU-инференса, системное проектирование, семантика API | Использование API и смысл параметров |
| Ответственность за сбои | Полностью ваша | В основном лежит на шаблоне |
| Ваша роль | Создатель платформы | Потребитель платформы |
Локальное развертывание означает, что вы пишете и владеете всем стеком обслуживания LLM: от GPU-инференса и управления памятью до планирования, стриминга и полной семантики
/v1/chat/completions, что обычно требует тысяч строк кода и глубоких знаний в области системного проектирования и работы с GPU. GPU-шаблон означает, что все это уже реализовано, и вам нужно только предоставить конфигурацию и минимальный связующий код, часто всего несколько десятков строк. Разница не является постепенной. В одном случае вы создаете платформу для LLM, в другом — просто используете готовую.
Почему GLM 4.7 Flash подходит для GPU-шаблонов и как его развернуть
Мгновенное развертывание с минимальными усилиями
Небольшой объем модели и быстрый запуск соответствуют предположениям, заложенным в шаблоны. Ее можно просто добавить в предварительно настроенный GPU-стек и получить работоспособный сервис за несколько минут, без необходимости кастомизации тонкой настройки или работы с инфраструктурой.
Исключительно низкая стоимость за час использования
Модель стабильно работает на массовых GPU вроде RTX 4090 стоимостью $0.35 в час, обеспечивая высокую пропускную способность без использования дорогостоящего оборудования. Это делает развертывания на основе шаблонов экономически выгодными даже при больших масштабах.
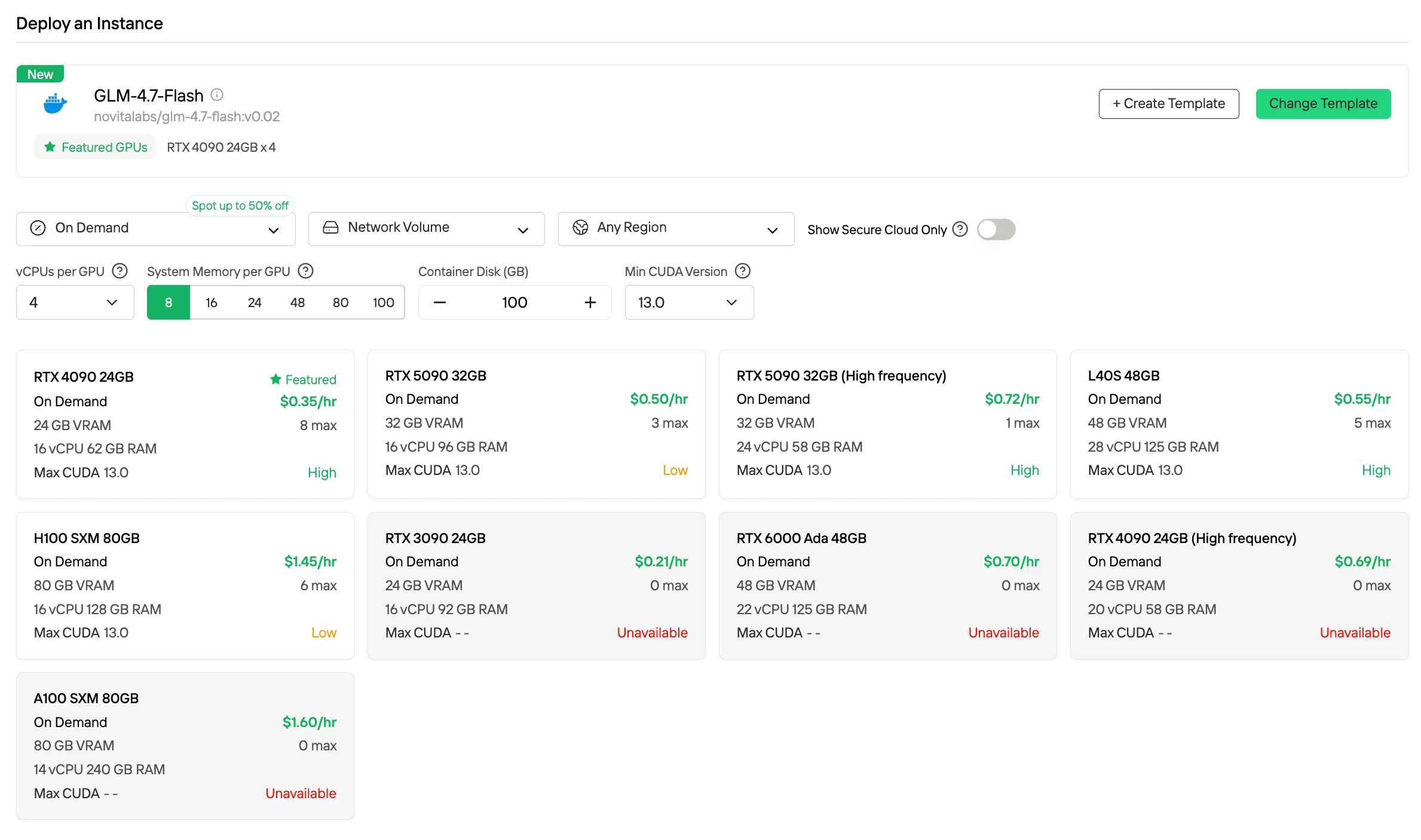
Попробуйте GLM 4.7 Flash сейчас!
Как развернуть GLM 4.7 Flash в быстром GPU-шаблоне?
Шаг 1: Вход в консоль
Запустите GPU-интерфейс и выберите «Начать работу», чтобы перейти к управлению развертываниями.
Шаг 2: Выбор пакета
Найдите GLM-4.7-Flash в репозитории шаблонов и запустите последовательность установки.
Попробуйте GLM 4.7 Flash сейчас!
Шаг 3: Настройка инфраструктуры
Настройте вычислительные параметры, включая распределение памяти, требования к хранилищу и сетевые настройки. Выберите «Развернуть» для запуска.
Шаг 4: Проверка и создание
Еще раз проверьте детали конфигурации и сводку по стоимости. Если все вас устраивает, нажмите «Развернуть», чтобы запустить процесс создания.
Шаг 5: Ожидание создания
После запуска развертывания система автоматически перенаправит вас на страницу управления инстансами. Ваш инстанс будет создан в фоновом режиме.
Шаг 6: Отслеживание прогресса загрузки
Отслеживайте прогресс загрузки образа в реальном времени. После завершения развертывания статус инстанса изменится с «Загрузка» на «Работает». Подробный прогресс можно посмотреть, нажав на иконку стрелки рядом с названием вашего инстанса.
Шаг 7: Проверка статуса инстанса
Нажмите кнопку «Логи», чтобы посмотреть логи инстанса и убедиться, что сервис InvokeAI запустился корректно.
Шаг 8: Доступ к окружению
Запустите пространство для разработки через интерфейс «Подключение», затем инициализируйте «Запустить веб-терминал».
Шаг 9: Демонстрация
curl --location --request POST 'http://127.0.0.1:8000/v1/chat/completions' \
> --header 'Content-Type: application/json' \
> --header 'Accept: */*' \
> --header 'Connection: keep-alive' \
> --data-raw '{
> "model": "zai-org/GLM-4.7-Flash",
> "messages": [
> {
> "role": "system",
> "content": "you are a helpful assitant."
> },
> {
> "role": "user",
> "content": "hello"
> }
> ],
> "max_tokens": 20,
> "stream": false
> }'
{"id":"chatcmpl-943f20f1c3a690ba","object":"chat.completion","created":1768823899,"model":"zai-org/GLM-4.7-Flash","choices":[{"index":0,"message":{"role":"assistant","content":"1. **Analyze the Input:** The user said \"hello\".\
2. **Ident","refusal":null,"annotations":null,"audio":null,"function_call":null,"tool_calls":[],"reasoning":null,"reasoning_content":null},"logprobs":null,"finish_reason":"length","stop_reason":null,"token_ids":null}],"service_tier":null,"system_fingerprint":null,"usage":{"prompt_tokens":14,"total_tokens":34,"completion_tokens":20,"prompt_tokens_details":null},"prompt_logprobs":null,"prompt_token_ids":null,"kv_transfer_params":null}
Как выбрать между двумя путями
| Вопрос | Если да | Рекомендуемый путь |
|---|---|---|
| Вам нужен полный контроль над движком | Да | Локальный |
| Ваша команда сильно заточена под работу с инфраструктурой | Да | Локальный |
| Вам нужна работа в офлайн-режиме | Да | Локальный |
| Вы хотите развертывание за несколько минут | Да | Шаблон |
| Вы выпускаете продукт | Да | Шаблон |
| В вашей команде много начинающих специалистов | Да | Шаблон |
| Вы хотите предсказуемого поведения | Да | Шаблон |
Локальное развертывание тратит деньги вместо инженерного времени.
Развертывание через шаблоны тратит контроль в обмен на скорость и детерминизм.Оба варианта предоставляют одинаковый API. Меняется только граница операционной ответственности.
Попробуйте дешевые GPU сейчас!
GLM 4.7 Flash обеспечивает возможности уровня агента в рамках предсказуемых лимитов VRAM, которые подходят для массовых GPU. Вы можете запустить его локально и владеть всем стеком, или развернуть через GPU-шаблоны и использовать как готовый API. Модель остается идентичной. Единственная разница в том, кто несет операционную нагрузку. Для большинства продуктовых команд GPU-шаблоны превращают GLM 4.7 Flash из инфраструктурного проекта в немедленно готовый к использованию системный компонент.
Сколько VRAM требуется GLM 4.7 Flash на практике?
GLM 4.7 Flash работает в узком диапазоне от около 12 ГБ при квантизации Q3 до около 30 ГБ при FP8, при этом 24 ГБ достаточно для стабильной промышленной эксплуатации на потребительских GPU.
Может ли GLM 4.7 Flash работать на RTX 4090?
Да. GLM 4.7 Flash стабильно работает на RTX 4090 при квантизации Q8 или Q4, обеспечивая производительность уровня промышленной эксплуатации на 24 ГБ VRAM.
В чем основная разница между локальным развертыванием и GPU-шаблонами для GLM 4.7 Flash?
При локальном развертывании GLM 4.7 Flash вы владеете всем стеком обслуживания, в то время как GPU-шаблоны предоставляют GLM 4.7 Flash как готовый API без необходимости работы с инфраструктурой.
Novita AI — это облачная AI-платформа, которая предлагает разработчикам простой способ развертывания AI-моделей с помощью нашего простого API, а также предоставляет доступное и надежное облако GPU для разработки и масштабирования.



