

GLM 4.7 Flash の評価を検討している開発者が最初に直面するのは、実際に必要な VRAM の量と、インフラの負担を最小限にするデプロイ方法の選択です。本記事では、具体的な数値と運用の明確さをもって両方の疑問に答えます。GLM 4.7 Flash を正確な VRAM 帯域にマッピングし、ローカルでの自己デプロイと GPU テンプレートによるデプロイを比較して、それぞれの選択がコスト、制御性、信頼性、API 利用開始までの時間にどのような影響を与えるかを示します。目的はシンプルです。最小限の摩擦で、本番環境に耐えうる GLM 4.7 Flash エンドポイントに到達できるよう支援することです。
GLM 4.7 Flash の VRAM 要件
GLM 4.7 Flash は 30B の MoE モデルで、トークンごとに約 3.6B のパラメータのみを活性化します。この設計により、同じクラスの dense モデルと比較して実行時のメモリ負荷が大幅に低減されます。実際には、利用可能なデプロイは狭く予測可能な VRAM 帯域に収まります。
| 精度/量子化 | おおよその VRAM | 代表的なハードウェア | ユースケース |
|---|---|---|---|
| FP16 | 60 GB | A100, H100 | 研究、ベンチマーク |
| FP8 | 30 GB | RTX 6000 Ada, L40S | ほぼロスレスな本番環境 |
| Q8 | 22 GB | RTX 4090 | 品質とコストのバランス |
| Q4 | 15 GB | RTX 3090, 4090 | コンシューマ GPU でのデプロイ |
| Q3 | 12 GB | エッジまたは制約のあるノード | 極度のコスト重視 |
GLM 4.7 Flash の 2 つのデプロイ方法
GLM 4.7 Flash をデプロイする主な方法は 2 つあります。
- vLLM、SGLang、MLX などのエンジンを使用したローカル自己デプロイ
- Novita のようなプラットフォームで GPU テンプレートを使用したマネージドデプロイ
どちらも最終的には OpenAI 互換の API を公開します。違いは運用負荷を誰が負うかです。
GLM 4.7 Flash のローカル自己デプロイ
典型的なローカルスタックは以下を含みます。
- NVIDIA ドライバと CUDA の整合性
- PyTorch、vLLM または SGLang のインストール
- モデルのダウンロードとストレージ管理
- 起動スクリプトとポートバインディング
- プロセス監視と再起動ロジック
この方法が最適なケース:
- 研究
- オフライン環境
- エンジンの深いカスタマイズ
- 強力なインフラ経験を持つチーム
ジュニア開発者や迅速な製品チームにはリスクが伴います。
GLM 4.7 Flash の GPU テンプレートデプロイ
GPU テンプレートは以下を定義します。
- コンテナイメージ
- 起動コマンド
- ディスク割り当て
- 公開ポート
- 環境変数
- 起動動作
開発者の視点:
- CUDA インストールは不要
- エンジンコンパイルは不要
- ネットワーク接続用のグルーコードは不要
- 手動でのモデル配線は不要
| 項目 | ローカルデプロイ | GPU テンプレート |
|---|---|---|
| 記述するコード | 数千行 | 数十行 |
| 自分で管理するレイヤー | 推論、スケジューリング、API、ストリーミング、フォールトハンドリング | 設定と起動 |
| 必要な知識 | GPU 推論の内部、システムエンジニアリング、API セマンティクス | API の使用方法とパラメータの意味 |
| 障害の責任 | すべて自分 | ほとんどがテンプレート側 |
| 自分の役割 | プラットフォームビルダー | プラットフォーム利用者 |
ローカルデプロイとは、GPU 推論やメモリ管理、スケジューリング、ストリーミング、そして完全な
/v1/chat/completionsセマンティクスに至るまで、LLM サービングスタック全体を自分で記述し所有することを意味します。これには通常数千行のコードと、システムおよび GPU に関する深い専門知識が必要です。一方 GPU テンプレートでは、それらはすべて既に存在しており、設定と最小限のグルーコード(多くの場合数十行)を提供するだけで済みます。この差は漸進的なものではありません。一方は LLM プラットフォームを構築しているのに対し、もう一方は単にそのプラットフォームを利用しているに過ぎません。
GLM 4.7 Flash が GPU テンプレートに適している理由とデプロイ方法
即時、低摩擦のデプロイ
モデルのフットプリントが小さく起動が速いため、テンプレートの前提条件に合致します。事前設定された GPU スタックにドロップインするだけで数分で利用可能になり、カスタムチューニングやインフラ作業は不要です。
時間あたりコストが非常に低い
RTX 4090 のような一般的な GPU 上で $0.35/時間で快適に動作し、プレミアムハードウェアを必要とせず高いスループットを実現します。そのため、テンプレートベースのデプロイはスケールしても経済的に成り立ちます。
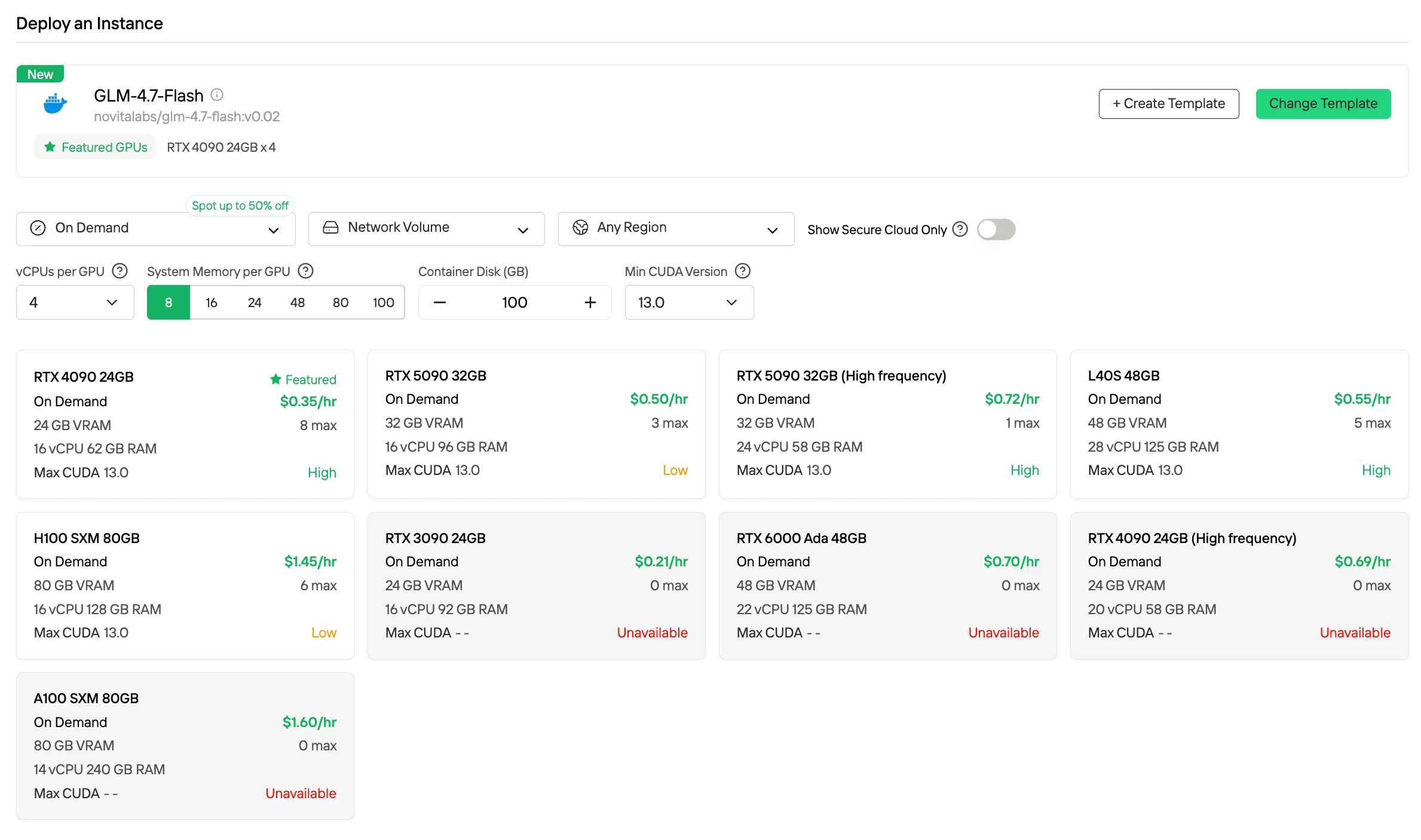
高速 GPU テンプレートで GLM 4.7 Flash をデプロイする方法
ステップ 1: コンソールエントリ
GPU インターフェースを起動し、「Get Started」を選択してデプロイ管理にアクセスします。
ステップ 2: パッケージ選択
テンプレートリポジトリから GLM-4.7-Flash を見つけ、インストールシーケンスを開始します。
ステップ 3: インフラ設定
メモリ割り当て、ストレージ要件、ネットワーク設定などのコンピューティングパラメータを設定します。「Deploy」を選択して実装します。
ステップ 4: 確認と作成
設定の詳細とコストのサマリーを再確認します。問題がなければ「Deploy」をクリックして作成プロセスを開始します。
ステップ 5: 作成を待つ
デプロイを開始すると、システムは自動的にインスタンス管理ページにリダイレクトします。インスタンスはバックグラウンドで作成されます。
ステップ 6: ダウンロード進捗の監視
イメージのダウンロード進捗をリアルタイムで確認できます。デプロイが完了すると、インスタンスのステータスが Pulling から Running に変わります。インスタンス名の横にある矢印アイコンをクリックすると、詳細な進捗を確認できます。
ステップ 7: インスタンスステータスの確認
「Logs」ボタンをクリックしてインスタンスログを表示し、InvokeAI サービスが正しく起動したことを確認します。
ステップ 8: 環境へのアクセス
「Connect」インターフェースから開発スペースを起動し、「Start Web Terminal」を初期化します。
ステップ 9: デモ
curl --location --request POST 'http://127.0.0.1:8000/v1/chat/completions' \
> --header 'Content-Type: application/json' \
> --header 'Accept: */*' \
> --header 'Connection: keep-alive' \
> --data-raw '{
> "model": "zai-org/GLM-4.7-Flash",
> "messages": [
> {
> "role": "system",
> "content": "you are a helpful assitant."
> },
> {
> "role": "user",
> "content": "hello"
> }
> ],
> "max_tokens": 20,
> "stream": false
> }'
{"id":"chatcmpl-943f20f1c3a690ba","object":"chat.completion","created":1768823899,"model":"zai-org/GLM-4.7-Flash","choices":[{"index":0,"message":{"role":"assistant","content":"1. **Analyze the Input:** The user said \"hello\".\
2. **Ident","refusal":null,"annotations":null,"audio":null,"function_call":null,"tool_calls":[],"reasoning":null,"reasoning_content":null},"logprobs":null,"finish_reason":"length","stop_reason":null,"token_ids":null}],"service_tier":null,"system_fingerprint":null,"usage":{"prompt_tokens":14,"total_tokens":34,"completion_tokens":20,"prompt_tokens_details":null},"prompt_logprobs":null,"prompt_token_ids":null,"kv_transfer_params":null}
2 つの方法の選び方
| 質問 | はいの場合 | 推奨方法 |
|---|---|---|
| エンジンを完全に制御する必要がありますか? | はい | ローカル |
| チームはインフラに強いですか? | はい | ローカル |
| オフライン運用が必要ですか? | はい | ローカル |
| 数分でデプロイしたいですか? | はい | テンプレート |
| 製品をリリースしていますか? | はい | テンプレート |
| チームはジュニア中心ですか? | はい | テンプレート |
| 予測可能な動作が必要ですか? | はい | テンプレート |
ローカルデプロイは、コストをエンジニアリング時間に換算します。
テンプレートデプロイは、制御性を速度と決定論性と交換します。どちらも同じ API サーフェスを提供します。変化するのは運用の境界だけです。
GLM 4.7 Flash は、主流の GPU に収まる予測可能な VRAM 制限内でエージェントグレードの性能を提供します。ローカルで実行してスタック全体を所有することも、GPU テンプレートを通じてデプロイして即座に利用可能な API として利用することもできます。モデル自体は同じです。異なるのは、運用負荷を誰が負うかだけです。ほとんどの本番チームにとって、GPU テンプレートは GLM 4.7 Flash をインフラプロジェクトから即座に使用可能なシステムコンポーネントに変えます。
GLM 4.7 Flash には実際にどれくらいの VRAM が必要ですか?
GLM 4.7 Flash は、Q3 で約 12 GB から FP8 で約 30 GB までの狭い範囲で動作し、24 GB でコンシューマ GPU 上での安定した本番運用が可能です。
GLM 4.7 Flash は RTX 4090 で動作しますか?
はい。GLM 4.7 Flash は RTX 4090 上で Q8 または Q4 を使用して良好に動作し、24 GB VRAM で本番グレードの性能を実現します。
GLM 4.7 Flash のローカルデプロイと GPU テンプレートの主な違いは何ですか?
ローカルデプロイでは GLM 4.7 Flash のサービングスタック全体を自分で管理する必要がありますが、GPU テンプレートではインフラ作業なしで GLM 4.7 Flash をすぐに利用可能な API として提供します。
Novita AI は、開発者がシンプルな API を使用して AI モデルを簡単にデプロイできる AI クラウドプラットフォームであり、スケーリングのための手頃で信頼性の高い GPU クラウドも提供しています。



