

يواجه المطورون الذين يقيمون نموذج GLM 4.7 Flash سؤالين فوريين: ما هي كمية ذاكرة الفيديو (VRAM) المطلوبة فعليًا، وأي مسار نشر يمنع البنية التحتية من أن تصبح عبئًا. يجيب هذا المقال على كلا السؤالين بأرقام ملموسة ووضوح تشغيلي. يحدد المقال نطاقات ذاكرة الفيديو (VRAM) الدقيقة لنموذج GLM 4.7 Flash، ثم يقارن بين النشر المحلي الذاتي والنشر باستخدام قوالب وحدات المعالجة الرسومية (GPU) لإظهار كيف يؤثر كل خيار على التكلفة والتحكم والموثوقية والوقت اللازم للوصول إلى واجهة برمجة التطبيقات (API). الهدف بسيط: مساعدتك في الوصول إلى نقطة نهاية مستقرة وجاهزة للإنتاج لنموذج GLM 4.7 Flash بأقل قدر ممكن من الاحتكاك.
متطلبات ذاكرة الفيديو (VRAM) لنموذج GLM 4.7 Flash
نموذج GLM 4.7 Flash هو نموذج MoE (خبير مختلط) بحجم 30 مليار معامل، حيث يتم تفعيل حوالي 3.6 مليار معامل فقط لكل رمز (token). يقلل هذا التصميم بشكل كبير من ضغط الذاكرة أثناء التشغيل مقارنة بالنماذج الكثيفة في نفس الفئة. في الممارسة العملية، تندمج عمليات النشر القابلة للاستخدام في نطاق ضيق ويمكن التنبؤ به من ذاكرة الفيديو (VRAM).
| الدقة / التكميم | ذاكرة الفيديو (VRAM) التقريبية | الأجهزة النموذجية | حالة الاستخدام |
|---|---|---|---|
| FP16 | 60 جيجابايت | A100, H100 | البحث، المعايرة المعيارية |
| FP8 | 30 جيجابايت | RTX 6000 Ada, L40S | إنتاج شبه خالٍ من الخسارة |
| Q8 | 22 جيجابايت | RTX 4090 | توازن بين الجودة والتكلفة |
| Q4 | 15 جيجابايت | RTX 3090, 4090 | نشر على وحدات معالجة رسومية للمستهلكين |
| Q3 | 12 جيجابايت | عقد حافة أو عقد ذات موارد محدودة | حساسية قصوى للتكلفة |
جرب وحدات معالجة رسومية رخيصة الآن!
مساران للنشر لنموذج GLM 4.7 Flash
هناك طريقتان سائدتان لنشر نموذج GLM 4.7 Flash:
- النشر المحلي الذاتي باستخدام محركات مثل vLLM أو SGLang أو MLX
- النشر المُدار باستخدام قوالب وحدات المعالجة الرسومية (GPU) على منصات مثل Novita
كلاهما يعرض في النهاية واجهة برمجة تطبيقات (API) متوافقة مع OpenAI. الفرق يكمن في من يتحمل العبء التشغيلي.
النشر المحلي الذاتي لنموذج GLM 4.7 Flash
يتضمن المكدس المحلي النموذجي ما يلي:
- محرك NVIDIA ومواءمة CUDA
- تثبيت PyTorch أو vLLM أو SGLang
- إدارة تنزيل النموذج وتخزينه
- نصوص بدء التشغيل وربط المنافذ
- منطق الإشراف على العمليات وإعادة تشغيلها
هذا المسار مثالي لـ:
- البحث
- البيئات غير المتصلة بالإنترنت
- تخصيص عميق للمحرك
- الفرق ذات الخبرة القوية في البنية التحتية
إنه محفوف بالمخاطر للمطورين المبتدئين أو الفرق المنتجة للمنتجات سريعة التحرك.
نشر نموذج GLM 4.7 Flash باستخدام قوالب وحدات المعالجة الرسومية (GPU)
يحدد قالب GPU ما يلي:
- صورة الحاوية
- أمر بدء التشغيل
- تخصيص القرص
- المنافذ المعروضة
- متغيرات البيئة
- سلوك الإقلاع
من منظور المطور:
- لا حاجة لتثبيت CUDA
- لا حاجة لتجميع المحرك
- لا حاجة لأدوات ربط الشبكة
- لا حاجة لتوصيل النموذج يدويًا
| الجانب | النشر المحلي | قالب GPU |
|---|---|---|
| الكود الذي تكتبه | آلاف الأسطر | عشرات الأسطر |
| الطبقات التي تملكها | الاستدلال، الجدولة، واجهة برمجة التطبيقات (API)، البث، معالجة الأخطاء | التكوين وبدء التشغيل |
| المعرفة المطلوبة | تفاصيل استدلال GPU، هندسة الأنظمة، دلالات واجهة برمجة التطبيقات (API) | استخدام واجهة برمجة التطبيقات (API) ومعنى المعاملات |
| مسؤولية الأعطال | بالكامل لك | في الغالب للقالب |
| دورك | باني المنصة | مستهلك المنصة |
يعني النشر المحلي أنك تكتب وتملك مكدس تقديم نماذج اللغة الكبيرة (LLM) بالكامل، من استدلال وحدات المعالجة الرسومية (GPU) وإدارة الذاكرة إلى الجدولة والبث وكافة دلالات نقطة النهاية
/v1/chat/completions، مما يتطلب عادةً آلاف الأسطر من الكود وخبرة عميقة في الأنظمة ووحدات المعالجة الرسومية. يعني قالب GPU أن كل هذا موجود بالفعل، وأنت تقدم فقط التكوين وأدوات ربط بسيطة، وغالبًا عشرات الأسطر فقط. الفرق ليس تزايديًا. في إحدى الحالتين، أنت تبني منصة لنماذج اللغة الكبيرة. وفي الحالة الأخرى، أنت تستخدم منصة فقط.
لماذا يتوافق نموذج GLM 4.7 Flash مع قوالب وحدات المعالجة الرسومية (GPU) وكيفية نشره
نشر فوري باحتكاك منخفض
يتوافق الحجم الصغير للنموذج وبدء تشغيله السريع مع افتراضات القوالب. يمكن إسقاطه في مكدس GPU مُعد مسبقًا ويصبح قابلاً للاستخدام في دقائق، دون الحاجة إلى ضبط مخصص أو عمل على البنية التحتية.
تكلفة استثنائية منخفضة لكل ساعة
يعمل بشكل مريح على وحدات معالجة رسومية commoditiy مثل RTX 4090 بتكلفة 0.35 دولار للساعة، ويقدم إنتاجية عالية دون الحاجة إلى أجهزة عالية الجودة. هذا يجعل عمليات النشر القائمة على القوالب مجدية اقتصاديًا حتى على نطاق واسع.
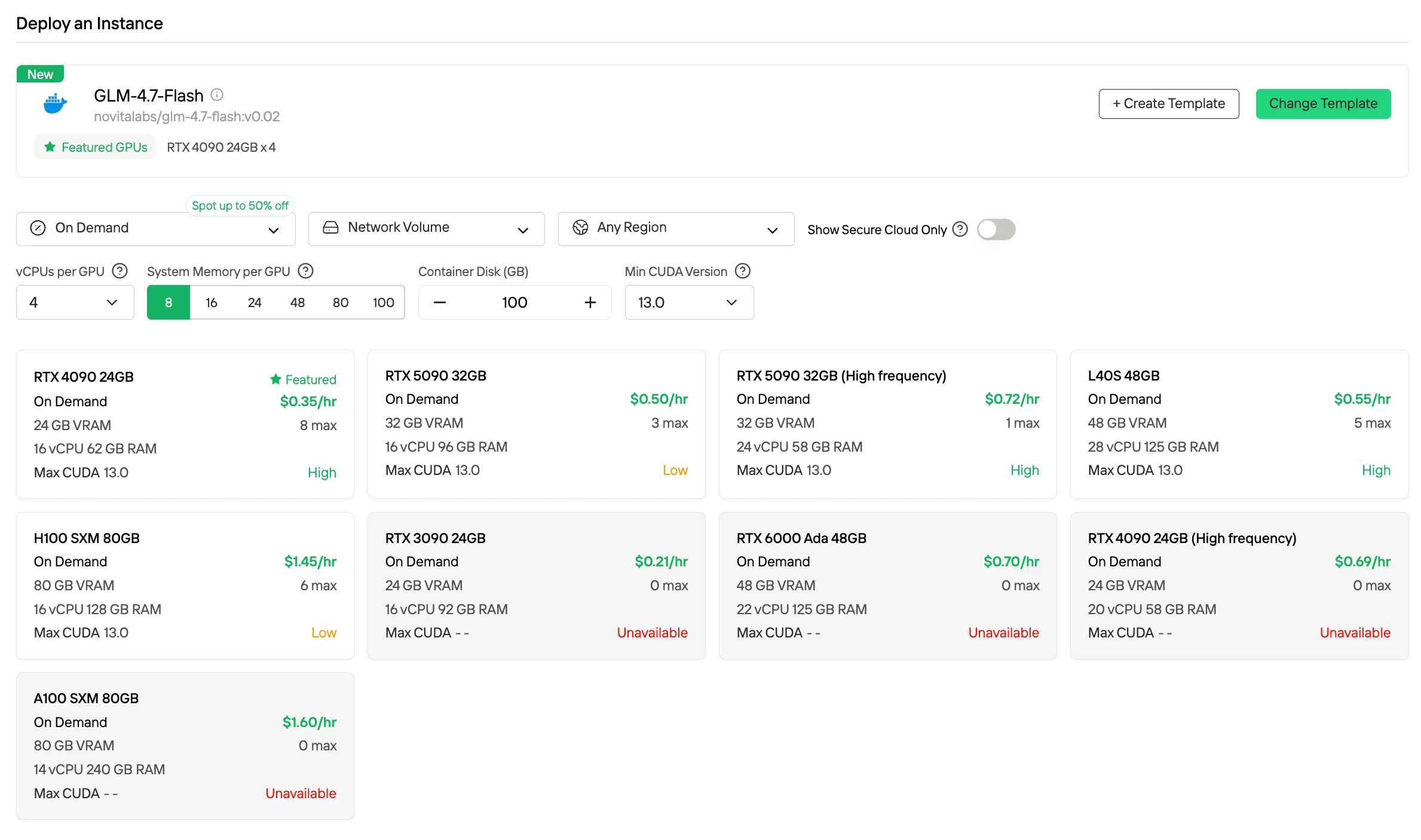
كيفية نشر نموذج GLM 4.7 Flash في قالب GPU سريع؟
الخطوة 1: الدخول إلى وحدة التحكم
أطلق واجهة GPU واختر “ابدأ” للوصول إلى إدارة النشر.
الخطوة 2: اختيار الحزمة
ابحث عن نموذج GLM-4.7-Flash في مستودع القوالب وابدأ تسلسل التثبيت.
الخطوة 3: إعداد البنية التحتية
قم بتكوين معاملات الحوسبة بما في ذلك تخصيص الذاكرة ومتطلبات التخزين وإعدادات الشبكة. اختر “نشر” لتنفيذ العملية.
الخطوة 4: المراجعة والإنشاء
تحقق مرة أخرى من تفاصيل التكوين وملخص التكلفة. عندما تكون راضيًا، انقر على “نشر” لبدء عملية الإنشاء.
الخطوة 5: انتظر حتى اكتمال الإنشاء
بعد بدء النشر، سيقوم النظام بإعادة توجيهك تلقائيًا إلى صفحة إدارة المثيلات. سيتم إنشاء مثيلك في الخلفية.
الخطوة 6: مراقبة تقدم التنزيل
تتبع تقدم تنزيل الصورة في الوقت الفعلي. ستتغير حالة مثيلك من “سحب” إلى “قيد التشغيل” بمجرد اكتمال النشر. يمكنك عرض التقدم التفصيلي بالنقر على أيقونة السهم بجانب اسم مثيلك.
الخطوة 7: التحقق من حالة المثيل
انقر على زر “السجلات” لعرض سجلات المثيل والتأكد من أن خدمة InvokeAI قد بدأت بشكل صحيح.
الخطوة 8: الوصول إلى البيئة
أطلق مساحة التطوير من خلال واجهة “اتصال”، ثم قم بتهيئة “بدء طرفية الويب”.
الخطوة 9: عرض تجريبي
curl --location --request POST 'http://127.0.0.1:8000/v1/chat/completions' \
> --header 'Content-Type: application/json' \
> --header 'Accept: */*' \
> --header 'Connection: keep-alive' \
> --data-raw '{
> "model": "zai-org/GLM-4.7-Flash",
> "messages": [
> {
> "role": "system",
> "content": "you are a helpful assitant."
> },
> {
> "role": "user",
> "content": "hello"
> }
> ],
> "max_tokens": 20,
> "stream": false
> }'
{"id":"chatcmpl-943f20f1c3a690ba","object":"chat.completion","created":1768823899,"model":"zai-org/GLM-4.7-Flash","choices":[{"index":0,"message":{"role":"assistant","content":"1. **Analyze the Input:** The user said \"hello\".\
2. **Ident","refusal":null,"annotations":null,"audio":null,"function_call":null,"tool_calls":[],"reasoning":null,"reasoning_content":null},"logprobs":null,"finish_reason":"length","stop_reason":null,"token_ids":null}],"service_tier":null,"system_fingerprint":null,"usage":{"prompt_tokens":14,"total_tokens":34,"completion_tokens":20,"prompt_tokens_details":null},"prompt_logprobs":null,"prompt_token_ids":null,"kv_transfer_params":null}
الاختيار بين المسارين
| السؤال | إذا كان الجواب نعم | المسار الموصى به |
|---|---|---|
| هل تحتاج إلى تحكم كامل في المحرك | نعم | محلي |
| هل فريقك لديه خبرة كبيرة في البنية التحتية | نعم | محلي |
| هل تحتاج إلى تشغيل غير متصل بالإنترنت | نعم | محلي |
| هل تريد نشرًا في دقائق | نعم | قالب GPU |
| هل تقوم بإطلاق منتج للإنتاج | نعم | قالب GPU |
| هل فريقك يضم عددًا كبيرًا من المطورين المبتدئين | نعم | قالب GPU |
| هل تريد سلوكًا يمكن التنبؤ به تمامًا | نعم | قالب GPU |
يبادل النشر المحلي المال بوقت الهندسة. يبادل النشر باستخدام القوالب التحكم بالسرعة والحدية.
كلاهما يقدم نفس واجهة برمجة التطبيقات (API). الفرق الوحيد هو الحدود التشغيلية.
جرب وحدات معالجة رسومية رخيصة الآن!
يقدم نموذج GLM 4.7 Flash قدرات على مستوى الوكلاء (agents) ضمن حدود يمكن التنبؤ بها من ذاكرة الفيديو (VRAM) تناسب وحدات المعالجة الرسومية السائدة. يمكنك تشغيله محليًا وامتلاك المكدس بالكامل، أو نشره من خلال قوالب GPU واستهلاكه كواجهة برمجة تطبيقات (API) جاهزة. يبقى النموذج متطابقًا. الفرق الوحيد هو من يتحمل العبء التشغيلي. بالنسبة لمعظم فرق الإنتاج، تحول قوالب GPU نموذج GLM 4.7 Flash من مشروع بنية تحتية إلى مكون نظام قابل للاستخدام فورًا.
كم كمية ذاكرة الفيديو (VRAM) التي يحتاجها نموذج GLM 4.7 Flash في الممارسة العملية؟
يعمل نموذج GLM 4.7 Flash في نطاق ضيق يتراوح من حوالي 12 جيجابايت في وضع التكميم Q3 إلى حوالي 30 جيجابايت في وضع FP8، حيث يتيح 24 جيجابايت تشغيلًا مستقرًا للإنتاج على وحدات المعالجة الرسومية للمستهلكين.
هل يمكن تشغيل نموذج GLM 4.7 Flash على وحدة معالجة رسومية RTX 4090؟
نعم. يعمل نموذج GLM 4.7 Flash بشكل جيد على RTX 4090 باستخدام وضعي التكميم Q8 أو Q4، ويقدم أداءً على مستوى الإنتاج على ذاكرة الفيديو (VRAM) سعة 24 جيجابايت.
ما هو الفرق الرئيسي بين النشر المحلي وقوالب GPU لنموذج GLM 4.7 Flash؟
يجعل النشر المحلي لنموذج GLM 4.7 Flash تمتلك مكدس التقديم بالكامل، بينما تعرض قوالب GPU نموذج GLM 4.7 Flash كواجهة برمجة تطبيقات (API) جاهزة دون الحاجة إلى أي عمل على البنية التحتية.
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة التطبيقات (API) البسيطة الخاصة بنا، بالإضافة إلى توفير سحابة وحدات معالجة رسومية (GPU) بأسعار معقولة وموثوقة للبناء والتوسع.



