

评估 GLM 4.7 Flash 的开发者面临两个直接问题:实际需要多少显存?哪条部署路径能让基础设施不成为负担?本文用具体数字和操作清晰度回答了这两个问题。它将 GLM 4.7 Flash 映射到精确的显存区间,然后比较本地自部署与 GPU 模板部署,展示每种选择如何影响成本、控制权、可靠性和 API 上线时间。目标很简单:帮助您以最小的摩擦获得一个稳定、可用于生产的 GLM 4.7 Flash 端点。
GLM 4.7 Flash 的显存需求
GLM 4.7 Flash 是一个 30B MoE 模型,每个 token 仅激活约 3.6B 参数。与同等级的密集模型相比,这种设计大幅降低了运行时内存压力。在实践中,可用的部署落在一个较窄且可预测的显存区间内。
| 精度/量化 | 近似显存 | 典型硬件 | 使用场景 |
|---|---|---|---|
| FP16 | 60 GB | A100, H100 | 研究、基准测试 |
| FP8 | 30 GB | RTX 6000 Ada, L40S | 近乎无损的生产环境 |
| Q8 | 22 GB | RTX 4090 | 质量与成本的平衡 |
| Q4 | 15 GB | RTX 3090, 4090 | 消费级 GPU 部署 |
| Q3 | 12 GB | 边缘或受限节点 | 极致的成本敏感场景 |
GLM 4.7 Flash 的两种部署路径
部署 GLM 4.7 Flash 主要有两种方式:
- 使用 vLLM、SGLang 或 MLX 等引擎进行本地自部署
- 在 Novita 等平台上使用 GPU 模板进行托管部署
两者最终都暴露一个兼容 OpenAI 的 API。区别在于谁承担运维负担。
GLM 4.7 Flash 的本地自部署
典型的本地部署栈包括:
- NVIDIA 驱动和 CUDA 版本匹配
- PyTorch、vLLM 或 SGLang 安装
- 模型下载和存储管理
- 启动脚本和端口绑定
- 进程监控和重启逻辑
这种路径最适用于:
- 研究
- 离线环境
- 深度引擎定制
- 具备强大基础设施经验的团队
对于初级开发者或快速迭代的产品团队来说,这存在风险。
GLM 4.7 Flash 的 GPU 模板部署
GPU 模板定义了:
- 容器镜像
- 启动命令
- 磁盘分配
- 暴露的端口
- 环境变量
- 启动行为
从开发者角度来看:
- 无需安装 CUDA
- 无需编译引擎
- 无需处理网络粘合
- 无需手动配置模型
| 方面 | 本地部署 | GPU 模板 |
|---|---|---|
| 你需要编写的代码 | 数千行 | 数十行 |
| 你拥有的层 | 推理、调度、API、流处理、故障处理 | 配置和启动 |
| 所需知识 | GPU 推理内部原理、系统工程、API 语义 | API 使用和参数含义 |
| 故障所有权 | 完全由你承担 | 主要由模板承担 |
| 你的角色 | 平台构建者 | 平台使用者 |
本地部署意味着你编写并拥有完整的 LLM 服务栈,涵盖 GPU 推理、内存管理、调度、流处理以及完整的
/v1/chat/completions语义,这通常需要数千行代码,并要求深厚的系统和 GPU 专业知识。GPU 模板意味着所有这一切都已存在,你只需提供配置和少量粘合代码,通常只需数十行。区别并非增量式的。一种情况是在构建 LLM 平台,另一种则仅仅是使用平台。
为什么 GLM 4.7 Flash 适合 GPU 模板以及如何部署
即时、低摩擦的部署
该模型的小体积和快速启动与模板的假设高度吻合。它可以被放入预配置的 GPU 栈中,在几分钟内即可投入使用,无需自定义调优或基础设施工作。
极低的每小时成本
它可以在 RTX 4090 等消费级 GPU 上轻松运行,每小时成本仅为 $0.35,无需高端硬件即可提供强大的吞吐量。这使得基于模板的部署即使在规模化时也经济可行。
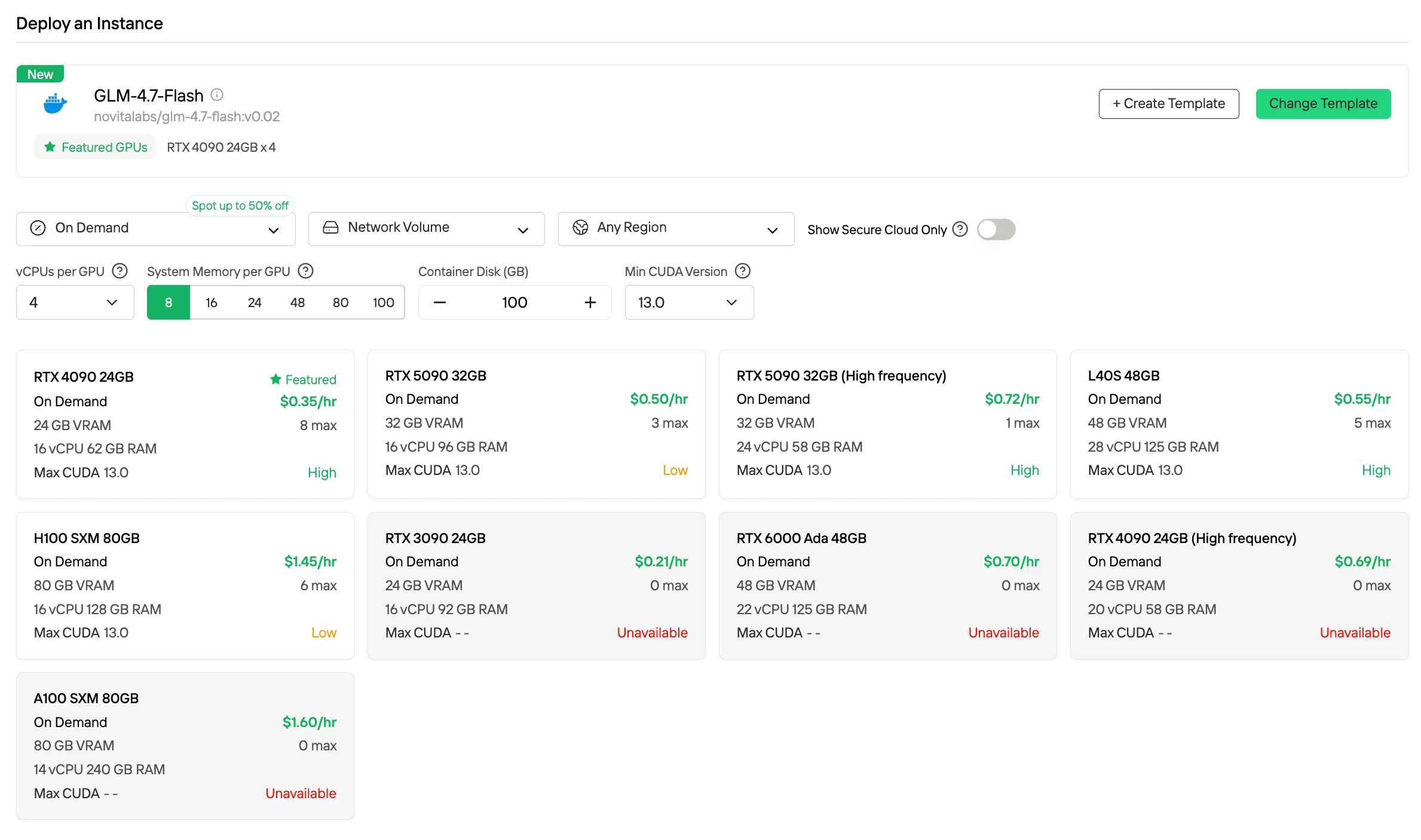
如何在 Fast GPU Template 中部署 GLM 4.7 Flash?
第一步:进入控制台
启动 GPU 界面,选择 Get Started 进入部署管理。
第二步:选择软件包
在模板仓库中找到 GLM-4.7-Flash,开始安装流程。
第三步:基础设施配置
配置计算参数,包括内存分配、存储需求和网络设置。选择 Deploy 执行。
第四步:审核并创建
仔细检查配置详情和成本摘要。确认无误后,点击 Deploy 开始创建过程。
第五步:等待创建
启动部署后,系统会自动跳转到实例管理页面。您的实例将在后台创建。
第六步:监控下载进度
实时跟踪镜像下载进度。部署完成后,实例状态将从 Pulling 变为 Running。点击实例名称旁的箭头图标可查看详细进度。
第七步:验证实例状态
点击 Logs 按钮查看实例日志,确认 InvokeAI 服务已正常启动。
第八步:访问环境
通过 Connect 界面启动开发空间,然后初始化 Start Web Terminal。
第九步:一个示例
curl --location --request POST 'http://127.0.0.1:8000/v1/chat/completions' \
> --header 'Content-Type: application/json' \
> --header 'Accept: */*' \
> --header 'Connection: keep-alive' \
> --data-raw '{
> "model": "zai-org/GLM-4.7-Flash",
> "messages": [
> {
> "role": "system",
> "content": "you are a helpful assitant."
> },
> {
> "role": "user",
> "content": "hello"
> }
> ],
> "max_tokens": 20,
> "stream": false
> }'
{"id":"chatcmpl-943f20f1c3a690ba","object":"chat.completion","created":1768823899,"model":"zai-org/GLM-4.7-Flash","choices":[{"index":0,"message":{"role":"assistant","content":"1. **Analyze the Input:** The user said \"hello\".\
2. **Ident","refusal":null,"annotations":null,"audio":null,"function_call":null,"tool_calls":[],"reasoning":null,"reasoning_content":null},"logprobs":null,"finish_reason":"length","stop_reason":null,"token_ids":null}],"service_tier":null,"system_fingerprint":null,"usage":{"prompt_tokens":14,"total_tokens":34,"completion_tokens":20,"prompt_tokens_details":null},"prompt_logprobs":null,"prompt_token_ids":null,"kv_transfer_params":null}
两条路径的选择
| 问题 | 如果答案为“是” | 推荐路径 |
|---|---|---|
| 你是否需要完全控制引擎 | 是 | 本地 |
| 你的团队是否擅长基础设施 | 是 | 本地 |
| 是否需要离线操作 | 是 | 本地 |
| 你希望几分钟内完成部署 | 是 | 模板 |
| 你正在交付产品 | 是 | 模板 |
| 你的团队中初级开发者居多 | 是 | 模板 |
| 你希望行为可预测 | 是 | 模板 |
本地部署用金钱换取工程时间。
模板部署用控制权换取速度和确定性。两者产生相同的 API 表面。只是运维边界发生了变化。
GLM 4.7 Flash 在可预测的显存限制内提供代理级能力,这些限制适合主流 GPU。你可以选择本地运行并拥有整个栈,或者通过 GPU 模板部署并将其作为现成 API 消费。模型本身保持不变。唯一区别是谁来承担运维负担。对于大多数生产团队,GPU 模板将 GLM 4.7 Flash 从一个基础设施项目转变为一个立即可用的系统组件。
GLM 4.7 Flash 在实际使用中需要多少显存?
GLM 4.7 Flash 运行在一个较窄的显存范围内,从 Q3 的大约 12 GB 到 FP8 的大约 30 GB,而在消费级 GPU 上 24 GB 即可实现稳定的生产级部署。
GLM 4.7 Flash 能在 RTX 4090 上运行吗?
可以。GLM 4.7 Flash 在 RTX 4090 上使用 Q8 或 Q4 量化运行良好,在 24 GB 显存上提供生产级性能。
对于 GLM 4.7 Flash,本地部署和 GPU 模板的主要区别是什么?
本地部署 GLM 4.7 Flash 使您拥有完整的服务栈,而 GPU 模板则将 GLM 4.7 Flash 作为现成 API 暴露,无需任何基础设施工作。
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的便捷方式,同时提供用于构建和扩展的可负担且可靠的 GPU 云。



