

Desenvolvedores que avaliam o GLM 4.7 Flash enfrentam duas perguntas imediatas: quanta VRAM é realmente necessária e qual caminho de implantação evita que a infraestrutura se torne um passivo. Este artigo responde a ambas com números concretos e clareza operacional. Ele mapeia o GLM 4.7 Flash em faixas de VRAM precisas, depois compara a implantação local própria com a implantação por modelo de GPU para mostrar como cada escolha afeta custo, controle, confiabilidade e tempo até a API. O objetivo é simples: ajudar você a chegar a um endpoint estável e pronto para produção do GLM 4.7 Flash com o mínimo de atrito possível.
Requisitos de VRAM para o GLM 4.7 Flash
O GLM 4.7 Flash é um modelo MoE de 30B que ativa apenas cerca de 3,6B de parâmetros por token. Esse design reduz drasticamente a pressão de memória em tempo de execução em comparação com modelos densos da mesma classe. Na prática, implantações utilizáveis se enquadram em uma faixa de VRAM estreita e previsível.
| Precisão / Quantização | VRAM Aproximada | Hardware Típico | Caso de Uso |
|---|---|---|---|
| FP16 | 60 GB | A100, H100 | Pesquisa, benchmark |
| FP8 | 30 GB | RTX 6000 Ada, L40S | Produção quase sem perdas |
| Q8 | 22 GB | RTX 4090 | Qualidade e custo equilibrados |
| Q4 | 15 GB | RTX 3090, 4090 | Implantação em GPU de consumidor |
| Q3 | 12 GB | Nós de borda ou com recursos limitados | Sensibilidade extrema a custos |
Dois Caminhos de Implantação do GLM 4.7 Flash
Existem duas formas dominantes de implantar o GLM 4.7 Flash:
- Implantação local própria usando mecanismos como vLLM, SGLang ou MLX
- Implantação gerenciada usando modelos de GPU em plataformas como a Novita
Ambas acabam expondo uma API compatível com a OpenAI. A diferença está em quem assume o ônus operacional.
Implantação Local Própria do GLM 4.7 Flash
Uma pilha local típica inclui:
- Driver NVIDIA e alinhamento com CUDA
- Instalação do PyTorch, vLLM ou SGLang
- Download do modelo e gerenciamento de armazenamento
- Scripts de inicialização e vinculação de portas
- Supervisão de processos e lógica de reinício
Esse caminho é ideal para:
- Pesquisa
- Ambientes offline
- Personalização profunda do mecanismo
- Equipes com forte experiência em infraestrutura
É arriscado para desenvolvedores júnior ou equipes de produto com ritmo acelerado.
Implantação por Modelo de GPU do GLM 4.7 Flash
Um modelo de GPU define:
- Imagem de contêiner
- Comando de inicialização
- Alocação de disco
- Portas expostas
- Variáveis de ambiente
- Comportamento de inicialização
Da perspectiva do desenvolvedor:
- Sem instalação de CUDA
- Sem compilação de mecanismo
- Sem configuração de rede
- Sem conexão manual do modelo
| Aspecto | Implantação Local | Modelo de GPU |
|---|---|---|
| Código que você escreve | Milhares de linhas | Dezenas de linhas |
| Camadas que você gerencia | Inferência, agendamento, API, streaming, tratamento de falhas | Configuração e inicialização |
| Conhecimento necessário | Internos de inferência em GPU, engenharia de sistemas, semântica de API | Uso da API e significado dos parâmetros |
| Responsabilidade por falhas | Totalmente sua | Maiormente do modelo |
| Seu papel | Construtor de plataforma | Consumidor de plataforma |
Implantação Local significa que você escreve e gerencia toda a pilha de serviço de LLM, desde a inferência em GPU e gerenciamento de memória até agendamento, streaming e toda a semântica de
/v1/chat/completions, o que geralmente custa milhares de linhas de código e requer profunda expertise em sistemas e GPU. Modelo de GPU significa que tudo isso já existe e você só fornece a configuração e uma conexão mínima, geralmente apenas dezenas de linhas. A diferença não é incremental. Em um caso você está construindo uma plataforma de LLM. No outro você está apenas usando uma.
Por que o GLM 4.7 Flash se Adapta a Modelos de GPU e Como Implantá-lo
Implantação instantânea e com baixo atrito
A pequena ocupação de recursos do modelo e a inicialização rápida se alinham com as premissas dos modelos de implantação. Ele pode ser inserido em uma pilha de GPU pré-configurada e se tornar utilizável em minutos, sem ajustes personalizados ou trabalho de infraestrutura.
Custo por hora excepcionalmente baixo
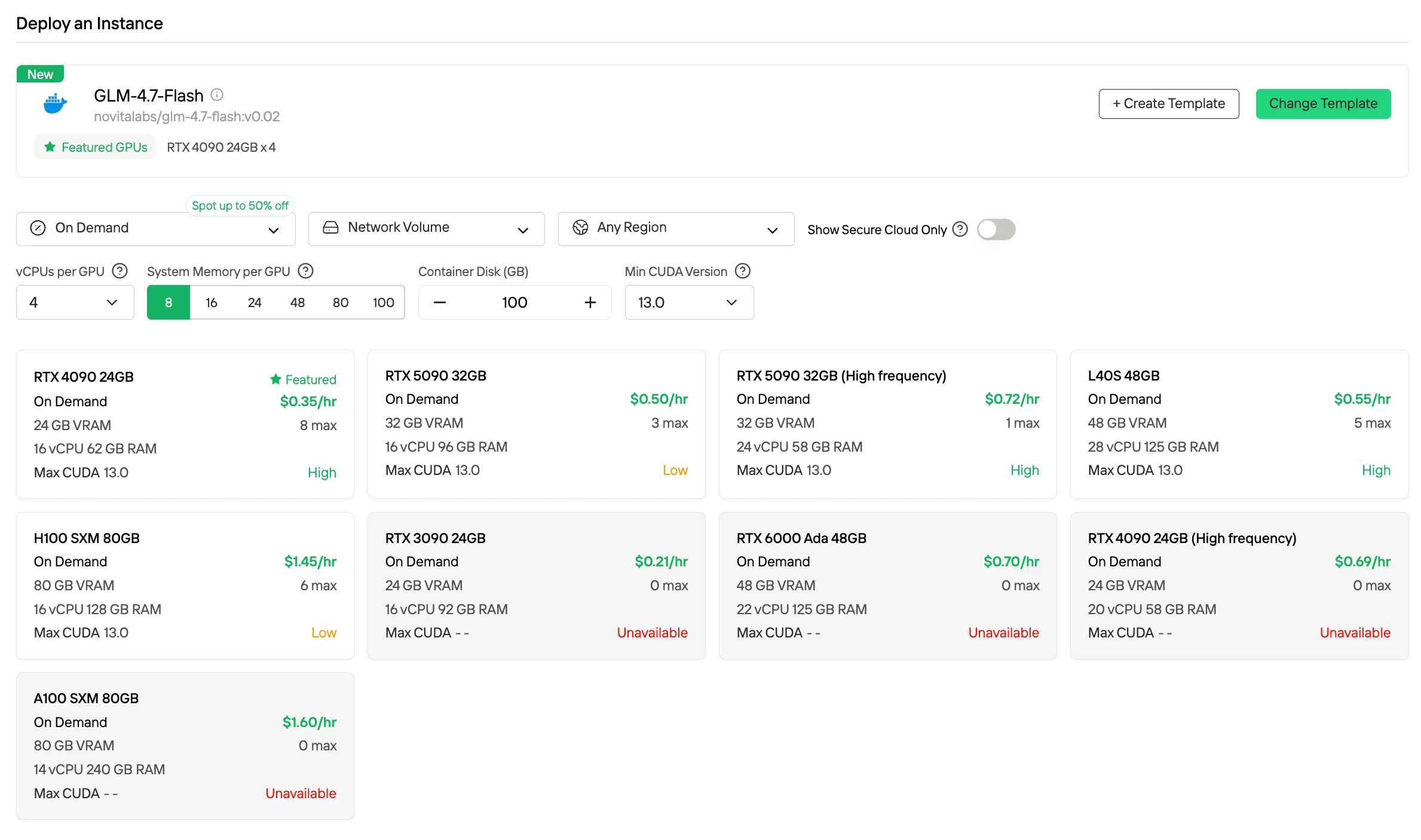
Ele roda confortavelmente em GPUs de consumo como a RTX 4090 por US$ 0,35/hora, entregando alta taxa de transferência sem hardware premium. Isso mantém as implantações baseadas em modelos economicamente viáveis mesmo em escala.
Experimente o GLM 4.7 Flash Agora!
Como Implantar o GLM 4.7 Flash em um Modelo de GPU Rápido?
Passo 1: Entrada no Console
Abra a interface de GPU e selecione Começar para acessar o gerenciamento de implantações.
Passo 2: Seleção de Pacote
Localize o GLM-4.7-Flash no repositório de modelos e inicie a sequência de instalação.
Experimente o GLM 4.7 Flash Agora!
Passo 3: Configuração de Infraestrutura
Configure os parâmetros de computação, incluindo alocação de memória, requisitos de armazenamento e configurações de rede. Selecione Implantar para executar.
Passo 4: Revisão e Criação
Verifique novamente os detalhes da sua configuração e o resumo de custos. Quando estiver satisfeito, clique em Implantar para iniciar o processo de criação.
Passo 5: Aguarde a Criação
Após iniciar a implantação, o sistema redirecionará você automaticamente para a página de gerenciamento de instâncias. Sua instância será criada em segundo plano.
Passo 6: Monitore o Progresso do Download
Acompanhe o progresso do download da imagem em tempo real. O status da sua instância mudará de Pulling para Running assim que a implantação for concluída. Você pode ver o progresso detalhado clicando no ícone de seta ao lado do nome da sua instância.
Passo 7: Verifique o Status da Instância
Clique no botão Logs para ver os registros da instância e confirmar que o serviço InvokeAI foi iniciado corretamente.
Passo 8: Acesso ao Ambiente
Abra o espaço de desenvolvimento pela interface Conectar, depois inicialize o Terminal Web Iniciar.
Passo 9: Uma Demonstração
curl --location --request POST 'http://127.0.0.1:8000/v1/chat/completions' \
> --header 'Content-Type: application/json' \
> --header 'Accept: */*' \
> --header 'Connection: keep-alive' \
> --data-raw '{
> "model": "zai-org/GLM-4.7-Flash",
> "messages": [
> {
> "role": "system",
> "content": "you are a helpful assitant."
> },
> {
> "role": "user",
> "content": "hello"
> }
> ],
> "max_tokens": 20,
> "stream": false
> }'
{"id":"chatcmpl-943f20f1c3a690ba","object":"chat.completion","created":1768823899,"model":"zai-org/GLM-4.7-Flash","choices":[{"index":0,"message":{"role":"assistant","content":"1. **Analyze the Input:** The user said \"hello\".\
2. **Ident","refusal":null,"annotations":null,"audio":null,"function_call":null,"tool_calls":[],"reasoning":null,"reasoning_content":null},"logprobs":null,"finish_reason":"length","stop_reason":null,"token_ids":null}],"service_tier":null,"system_fingerprint":null,"usage":{"prompt_tokens":14,"total_tokens":34,"completion_tokens":20,"prompt_tokens_details":null},"prompt_logprobs":null,"prompt_token_ids":null,"kv_transfer_params":null}
Escolhendo Entre os Dois Caminhos
| Pergunta | Se Sim | Caminho Recomendado |
|---|---|---|
| Você precisa de controle total do mecanismo | Sim | Local |
| Sua equipe é pesada em infraestrutura | Sim | Local |
| Você precisa de operação offline | Sim | Local |
| Você quer implantação em minutos | Sim | Modelo |
| Você está lançando um produto | Sim | Modelo |
| Sua equipe tem muitos desenvolvedores júnior | Sim | Modelo |
| Você quer comportamento previsível | Sim | Modelo |
A implantação local troca dinheiro por tempo de engenharia.
A implantação por modelo troca controle por velocidade e determinismo.Ambas produzem a mesma superfície de API. Apenas o limite operacional muda.
O GLM 4.7 Flash entrega capacidade de nível de agente dentro de limites de VRAM previsíveis que se encaixam em GPUs convencionais. Você pode executá-lo localmente e gerir toda a pilha, ou implantá-lo por meio de modelos de GPU e consumi-lo como uma API pronta. O modelo permanece idêntico. A única diferença é quem assume o peso operacional. Para a maioria das equipes de produção, os modelos de GPU convertem o GLM 4.7 Flash de um projeto de infraestrutura em um componente de sistema utilizável imediatamente.
Quanta VRAM o GLM 4.7 Flash precisa na prática?
O GLM 4.7 Flash roda em uma faixa estreita de cerca de 12 GB no Q3 a cerca de 30 GB no FP8, com 24 GB permitindo produção estável em GPUs de consumidor.
O GLM 4.7 Flash pode rodar em uma RTX 4090?
Sim. O GLM 4.7 Flash roda bem na RTX 4090 usando Q8 ou Q4, entregando desempenho de nível de produção com 24 GB de VRAM.
Qual a principal diferença entre a implantação local e os modelos de GPU para o GLM 4.7 Flash?
A implantação local do GLM 4.7 Flash faz com que você gerencie toda a pilha de serviço, enquanto os modelos de GPU expõem o GLM 4.7 Flash como uma API pronta, sem trabalho de infraestrutura.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma forma fácil de implantar modelos de IA usando nossa API simples, além de fornecer nuvem de GPU acessível e confiável para construção e escalonamento.



