

Los desarrolladores que evalúan GLM 4.7 Flash se enfrentan a dos preguntas inmediatas: ¿cuánta VRAM se necesita realmente y qué ruta de despliegue evita que la infraestructura se convierta en una carga? Este artículo responde ambas con números concretos y claridad operativa. Mapea GLM 4.7 Flash en rangos precisos de VRAM y luego compara el auto-despliegue local con el despliegue mediante plantillas de GPU para mostrar cómo cada elección afecta el costo, el control, la fiabilidad y el tiempo hasta la API. El objetivo es simple: ayudarte a alcanzar un endpoint de GLM 4.7 Flash estable y listo para producción con la menor fricción posible.
Requisitos de VRAM para GLM 4.7 Flash
GLM 4.7 Flash es un modelo MoE de 30B que activa solo unos 3.6B parámetros por token. Este diseño reduce drásticamente la presión de memoria en tiempo de ejecución en comparación con modelos densos de la misma clase. En la práctica, los despliegues utilizables se sitúan en un rango de VRAM estrecho y predecible.
| Precisión/Cuantización | VRAM Aproximada | Hardware Típico | Caso de Uso |
|---|---|---|---|
| FP16 | 60 GB | A100, H100 | Investigación, benchmarks |
| FP8 | 30 GB | RTX 6000 Ada, L40S | Producción casi sin pérdida |
| Q8 | 22 GB | RTX 4090 | Equilibrio entre calidad y coste |
| Q4 | 15 GB | RTX 3090, 4090 | Despliegue en GPU de consumo |
| Q3 | 12 GB | Nodos periféricos o limitados | Sensibilidad extrema al coste |
Dos caminos de despliegue para GLM 4.7 Flash
Hay dos formas principales de desplegar GLM 4.7 Flash:
- Auto-despliegue local utilizando motores como vLLM, SGLang o MLX
- Despliegue gestionado mediante plantillas de GPU en plataformas como Novita
Ambos exponen finalmente una API compatible con OpenAI. La diferencia radica en quién asume la carga operativa.
Auto-despliegue local de GLM 4.7 Flash
Una pila local típica incluye:
- Controlador NVIDIA y alineación de CUDA
- Instalación de PyTorch, vLLM o SGLang
- Descarga del modelo y gestión de almacenamiento
- Scripts de inicio y enlace de puertos
- Supervisión de procesos y lógica de reinicio
Este camino es óptimo para:
- Investigación
- Entornos sin conexión
- Personalización profunda del motor
- Equipos con sólida experiencia en infraestructura
Es arriesgado para desarrolladores junior o equipos de producto que avanzan rápido.
Despliegue mediante plantilla de GPU de GLM 4.7 Flash
Una plantilla de GPU define:
- Imagen de contenedor
- Comando de inicio
- Asignación de disco
- Puertos expuestos
- Variables de entorno
- Comportamiento de arranque
Desde la perspectiva del desarrollador:
- Sin instalación de CUDA
- Sin compilación del motor
- Sin pegamento de red
- Sin cableado manual del modelo
| Aspecto | Despliegue Local | Plantilla de GPU |
|---|---|---|
| Código que escribes | Miles de líneas | Decenas de líneas |
| Capas que posees | Inferencia, planificación, API, streaming, manejo de fallos | Configuración e inicio |
| Conocimiento requerido | Internals de inferencia en GPU, ingeniería de sistemas, semántica de API | Uso de la API y significado de parámetros |
| Responsabilidad de fallos | Completamente tuya | Mayoría de la plantilla |
| Tu rol | Constructor de plataforma | Consumidor de plataforma |
Despliegue Local significa que escribes y posees toda la pila de servicio LLM, desde la inferencia en GPU y la gestión de memoria hasta la planificación, el streaming y la semántica completa de
/v1/chat/completions, lo que típicamente cuesta miles de líneas de código y requiere un profundo conocimiento de sistemas y GPU. Plantilla de GPU significa que todo eso ya existe y solo proporcionas configuración y un pegamento mínimo, a menudo solo decenas de líneas. La diferencia no es incremental. En un caso estás construyendo una plataforma LLM. En el otro, simplemente la estás utilizando.
Por qué GLM 4.7 Flash encaja en las plantillas de GPU y cómo desplegarlo
Despliegue instantáneo y de baja fricción
La huella pequeña del modelo y su arranque rápido se alinean con las suposiciones de las plantillas. Se puede colocar en una pila de GPU preconfigurada y estar listo para servir en minutos, sin ajustes personalizados ni trabajo de infraestructura.
Coste excepcionalmente bajo por hora
Funciona cómodamente en GPU básicas como RTX 4090 a $0.35/hora, ofreciendo un alto rendimiento sin necesidad de hardware premium. Esto mantiene los despliegues basados en plantillas económicamente viables incluso a escala.
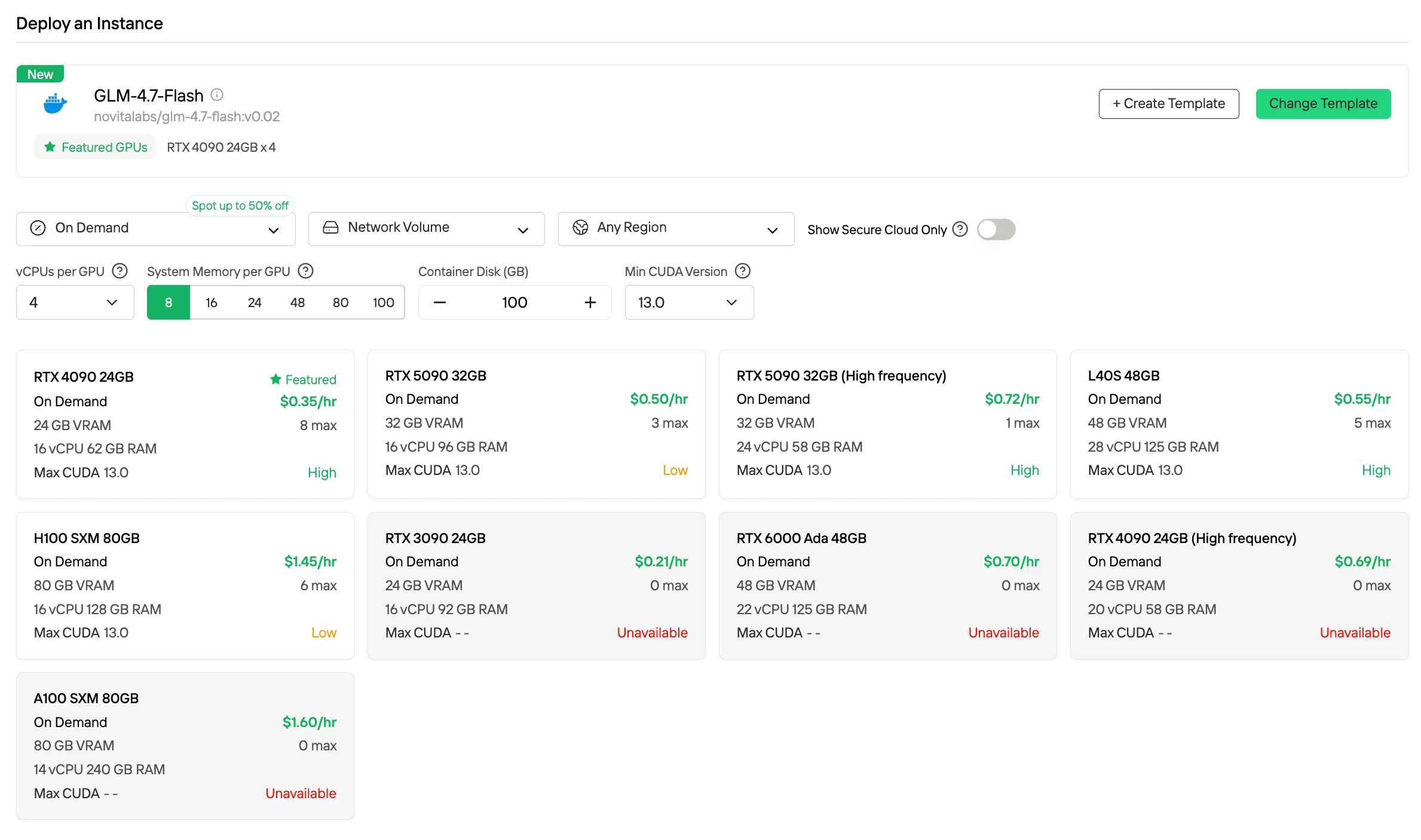
Cómo desplegar GLM 4.7 Flash en una Plantilla de GPU Rápida
Paso 1: Entrada a la Consola
Abre la interfaz de GPU y selecciona Comenzar para acceder a la gestión de despliegues.
Paso 2: Selección del Paquete
Localiza GLM-4.7-Flash en el repositorio de plantillas e inicia la secuencia de instalación.
Paso 3: Configuración de Infraestructura
Configura los parámetros de computación, incluyendo asignación de memoria, requisitos de almacenamiento y ajustes de red. Selecciona Desplegar para implementar.
Paso 4: Revisar y Crear
Verifica los detalles de configuración y el resumen de costes. Cuando estés satisfecho, haz clic en Desplegar para iniciar el proceso de creación.
Paso 5: Esperar la Creación
Tras iniciar el despliegue, el sistema te redirigirá automáticamente a la página de gestión de instancias. Tu instancia se creará en segundo plano.
Paso 6: Monitorear el Progreso de Descarga
Sigue el progreso de descarga de la imagen en tiempo real. El estado de tu instancia cambiará de Pulling a Running una vez que el despliegue esté completo. Puedes ver el progreso detallado haciendo clic en el icono de flecha junto al nombre de tu instancia.
Paso 7: Verificar el Estado de la Instancia
Haz clic en el botón Logs para ver los registros de la instancia y confirmar que el servicio InvokeAI se ha iniciado correctamente.
Paso 8: Acceso al Entorno
Inicia el espacio de desarrollo a través de la interfaz Connect, luego inicializa Start Web Terminal.
Paso 9: Un Demo
curl --location --request POST 'http://127.0.0.1:8000/v1/chat/completions' \
> --header 'Content-Type: application/json' \
> --header 'Accept: */*' \
> --header 'Connection: keep-alive' \
> --data-raw '{
> "model": "zai-org/GLM-4.7-Flash",
> "messages": [
> {
> "role": "system",
> "content": "you are a helpful assitant."
> },
> {
> "role": "user",
> "content": "hello"
> }
> ],
> "max_tokens": 20,
> "stream": false
> }'
{"id":"chatcmpl-943f20f1c3a690ba","object":"chat.completion","created":1768823899,"model":"zai-org/GLM-4.7-Flash","choices":[{"index":0,"message":{"role":"assistant","content":"1. **Analyze the Input:** The user said \"hello\".\
2. **Ident","refusal":null,"annotations":null,"audio":null,"function_call":null,"tool_calls":[],"reasoning":null,"reasoning_content":null},"logprobs":null,"finish_reason":"length","stop_reason":null,"token_ids":null}],"service_tier":null,"system_fingerprint":null,"usage":{"prompt_tokens":14,"total_tokens":34,"completion_tokens":20,"prompt_tokens_details":null},"prompt_logprobs":null,"prompt_token_ids":null,"kv_transfer_params":null}
Elegir entre los dos caminos
| Pregunta | Si es Sí | Camino Recomendado |
|---|---|---|
| ¿Necesitas control total del motor? | Sí | Local |
| ¿Tu equipo tiene mucha experiencia en infraestructura? | Sí | Local |
| ¿Necesitas operación sin conexión? | Sí | Local |
| ¿Quieres estar en producción en minutos? | Sí | Plantilla |
| ¿Estás lanzando un producto? | Sí | Plantilla |
| ¿Tu equipo es mayoritariamente junior? | Sí | Plantilla |
| ¿Quieres un comportamiento predecible? | Sí | Plantilla |
El despliegue local intercambia dinero por tiempo de ingeniería.
El despliegue con plantillas intercambia control por velocidad y determinismo.Ambos producen la misma superficie de API. Solo cambia el límite operativo.
GLM 4.7 Flash ofrece capacidades de nivel agente dentro de límites de VRAM predecibles que encajan en GPU convencionales. Puedes ejecutarlo localmente y poseer toda la pila, o desplegarlo mediante plantillas de GPU y consumirlo como una API lista. El modelo sigue siendo idéntico. La única diferencia es quién carga con el peso operativo. Para la mayoría de los equipos de producción, las plantillas de GPU convierten GLM 4.7 Flash de un proyecto de infraestructura en un componente de sistema inmediatamente utilizable.
¿Cuánta VRAM necesita GLM 4.7 Flash en la práctica?
GLM 4.7 Flash funciona en un rango estrecho, desde unos 12 GB en Q3 hasta unos 30 GB en FP8, y 24 GB permiten una producción estable en GPU de consumo.
¿Puede GLM 4.7 Flash ejecutarse en una RTX 4090?
Sí. GLM 4.7 Flash funciona bien en RTX 4090 usando Q8 o Q4, ofreciendo un rendimiento de nivel productivo en 24 GB de VRAM.
¿Cuál es la principal diferencia entre el despliegue local y las plantillas de GPU para GLM 4.7 Flash?
El despliegue local de GLM 4.7 Flash te hace responsable de toda la pila de servicio, mientras que las plantillas de GPU exponen GLM 4.7 Flash como una API lista sin trabajo de infraestructura.
Novita AI es una plataforma de nube de IA que ofrece a los desarrolladores una forma sencilla de desplegar modelos de IA usando nuestra API simple, al mismo tiempo que proporciona una nube de GPU asequible y fiable para construir y escalar.



