

- Сколько VRAM требуется для GLM 4.5V?
- VRAM для GLM 4.5V в сравнении с другими VLM
- Какие GPU рекомендуются для запуска GLM 4.5V?
- Устранение ошибок, связанных с нехваткой VRAM для GLM 4.5V
- Оптимизация GLM 4.5V для сред с ограниченным объемом VRAM
- Если вы хотите более удобный способ, вы можете использовать API!
GLM-4.5V — одна из самых мощных доступных на сегодняшний день визуально-языковых моделей (VLM). С 106 млрд общих параметров и 12 млрд активных параметров она сочетает сильные стороны рассуждений GLM-4.5 с продвинутыми визуальными энкодерами для обработки изображений, документов и видео. Эти уникальные возможности имеют свою цену: объем VRAM. Сколько памяти требуется для локального запуска самой мощной VLM в мире?
Сколько VRAM требуется для GLM 4.5V?
GLM-4.5V — это vision-language версия GLM-4.5, имеющая ту же архитектуру, что и модель «Air» с 106 млрд общих параметров и 12 млрд активных параметров, но дополненная визуальными энкодерами для обработки изображений и видео. Этот визуальный компонент значительно повышает требования к памяти.
| GLM 4.5V | 106B | 12B | 128K tokens | Мультимодальная: зрение, текст, документы, видео |
Оптимальный объем VRAM для запуска GLM-4.5V составляет около 640 ГБ на 8 GPU H100, чего достаточно для выполнения инференса в формате FP16, включая активные параметры, визуальный энкодер и промежуточные тензоры изображений. Хотя 640 ГБ хватает для стандартного использования, для изображений с высоким разрешением или полных контекстов из 128k токенов может потребоваться дополнительная память или несколько GPU для оптимальной производительности.
VRAM для GLM 4.5V в сравнении с другими VLM
| Модель | Параметры | Требования к VRAM (инференс) |
|---|---|---|
| GLM‑4.1V‑Thinking (9B) | 9B активных | 22–24 ГБ |
| GLM‑4.5V | 106 млрд общих / 12 млрд активных | 48 ГБ |
| Gemma 3 27B | 27B | 70 ГБ |
| Qwen 2.5‑VL (72B) | 72B | 384 ГБ |
| Kimi VL A3B Thinking 2506 | 16,4 ГБ | 12 ГБ |
Производительность GLM 4.5V в сравнении с другими VLM
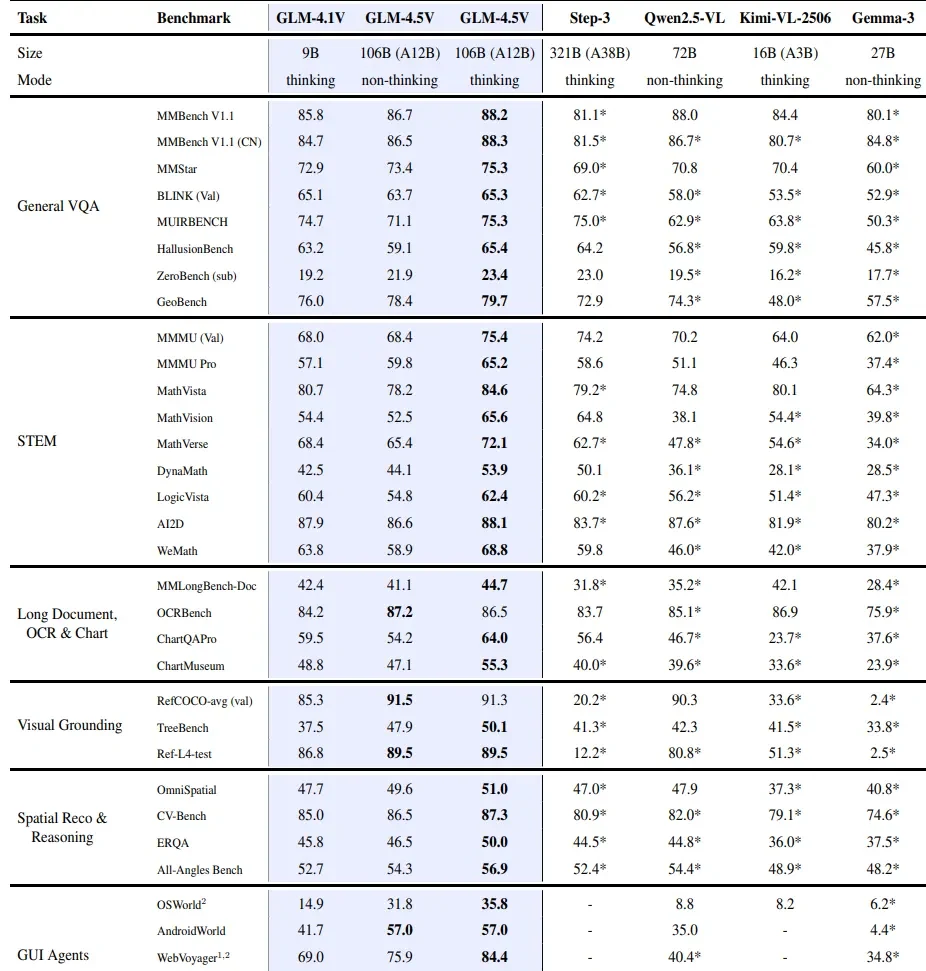
Какие GPU рекомендуются для запуска GLM 4.5V?
1. A6000 / L40S (≈48 ГБ)
- Почему это отличный вариант: Идеально соответствует требованию GLM‑4.5V к VRAM в формате FP16 (~48 ГБ), что позволяет разместить полную модель (активные параметры + визуальный модуль) на одной GPU.
- Лучше всего подходит для: Экономичных развертываний на одной GPU без сложностей мульти-GPU конфигураций.
- Недостатки: Более низкая пропускная способность памяти и вычислительная производительность по сравнению с A100/H100. Ограничения для контекстов 128K или задач дообучения.
2. A100 80GB
- Почему это надежный вариант: С 80 ГБ памяти HBM2e он комфортно запускает GLM‑4.5V и поддерживает легкое дообучение. Широко распространен для обучения и инференса LLM.
- Лучше всего подходит для: Сбалансированных рабочих нагрузок по обучению и инференсу, особенно когда поддержка FP8 не является обязательной.
- Недостатки: Более медленный инференс по сравнению с H100; отсутствует нативная поддержка FP8. Оборудование предыдущего поколения.
3. H100 80GB
- Почему он выделяется: Обеспечивает максимальную пропускную способность и эффективность. Поддерживает FP8 для снижения использования VRAM и быстрого инференса — идеально для развертываний с длинным контекстом (128k токенов) и высокими требованиями.
- Лучше всего подходит для: Полноценного инференса с низкой задержкой в производственных средах с большими входными данными или множеством одновременных запросов.
- Недостатки: Максимальная стоимость, ограниченная доступность, а для поддержки FP8 требуется самый свежий стек программного обеспечения (CUDA 12+, ночные сборки PyTorch).
Попробуйте развернуть GLM 4.5V прямо сейчас!
Устранение ошибок, связанных с нехваткой VRAM для GLM 4.5V
1. Квантизация
- Используйте веса в 4-битном или 8-битном формате, чтобы снизить потребление VRAM (например, 12B → ~6 ГБ).
- Инструменты:
GPTQ,LLAMA.cpp,Unsloth GGUF. - Также выполните квантизацию KV-кэша для повышения эффективности работы с длинным контекстом.
2. Выгрузка экспертов MoE
- Разместите активные 12B параметров на GPU, выгрузите неактивные эксперты на CPU.
- Требуется быстрая межсоединительная шина и большой объем оперативной памяти CPU (≥1 ТБ для полной модели).
- Используйте
device_map="auto"с DeepSpeed или Accelerate.
3. Ограничение длины контекста
- Снижение длины контекста с 128k до 32k/8k уменьшает потребление памяти в 4–16 раз.
- Позволяет выполнять инференс на GPU с 12–16 ГБ памяти.
- При необходимости передавайте длинные входные данные потоковыми фрагментами.
4. Оптимизация KV-кэша
- Используйте точность float16 / int8 / int4.
- Перенесите KV-кэш на CPU, если не хватает памяти GPU (работает медленнее, но является рабочей опцией).
5. Использование более легких компонентов
- Отдавайте предпочтение GLM-4.5-Air (только текст).
- Выгрузите визуальный энкодер или используйте внешние модели для обработки изображений (например, CLIP).
- Air работает почти в 2 раза быстрее и подходит для большинства задач NLP.
6. Энергоэффективное дообучение (с низким потреблением памяти)
- Применяйте LoRA, QLoRA, градиентный чекпоинтинг.
- Всегда дообучайте версию Air, если не требуется поддержка зрения.
- Для Air требуется 4 GPU по 80 ГБ, для полной версии GLM — 16 GPU по 80 ГБ.
7. Настройка движка инференса
- Используйте эффективные движки:
vLLM,SGLang. - На H100: разделите GPU на 2 экземпляра по 40 ГБ через MIG для мультиинстансного инференса.
Оптимизация GLM 4.5V для сред с ограниченным объемом VRAM
- Ошибка CUDA OOM при загрузке: Используйте квантизованные модели +
device_map="auto"+ очистка кэша. - Ошибка OOM во время инференса: Уменьшите значение
max_new_tokens; сократите контекст; выгрузите кэш. - Ошибки FP8: Избегайте использования на неподдерживаемых GPU; переключитесь на FP16/BF16.
- Повторяющийся/бессмысленный вывод: Может возникать из-за низкоточного кэша или перегрузки.
- Фрагментация памяти: Перезапустите окружение; уменьшите размер батча; отключите автонастройку.
- Ошибка OOM оперативной памяти CPU: Контролируйте использование; избегайте запуска больших моделей при низком объеме ОЗУ.
- Ошибки фреймворка: Проверяйте конфигурации памяти; изучайте логи ошибок для выявления проблем с тензорами/устройствами.
Если вы хотите более удобный способ, вы можете использовать API!
API Novita AI для GLM-4.5V предлагает контекст длиной 65,5K токенов, стоимость ввода составляет $0,60 за 1K токенов, стоимость вывода — $1,80 за 1K токенов, поддерживаются вызов функций и структурированные выводы.
Шаг 1: Войдите в аккаунт и перейдите в библиотеку моделей
Войдите в свой аккаунт и нажмите кнопку Библиотека моделей.

Попробуйте GLM4.5V прямо сейчас!
Шаг 2: Выберите нужную модель
Просмотрите доступные варианты и выберите модель, которая подходит для ваших задач.

Шаг 3: Начните бесплатный пробный период
Начните бесплатный пробный период, чтобы изучить возможности выбранной модели.

Шаг 4: Получите ваш API-ключ
Для аутентификации через API мы предоставим вам новый API-ключ. Перейдя на страницу «Настройки», вы можете скопировать API-ключ, как показано на изображении.

Шаг 5: Установите API
Установите API с помощью менеджера пакетов, соответствующего вашему языку программирования.
После установки импортируйте необходимые библиотеки в вашу среду разработки. Инициализируйте API с вашим API-ключом, чтобы начать взаимодействие с LLM Novita AI. Ниже приведен пример использования API завершений чата для пользователей Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_rDfpD7GWNXFvnoIbmYNFkVlStqevDItFJac__3tAuw3ZiENHe3wm498Kv9rZEc5JhZgEJ7c9To5Y3EmZZewMbw==",
)
model = "zai-org/glm-4.5v"
stream = True # or False
max_tokens = 32768
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
GLM-4.5V задает новый стандарт для мультимодального ИИ, но локальное развертывание требует серьезных вычислительных мощностей GPU. 48 ГБ VRAM (A6000/L40S) — это минимум для стандартного инференса, а для полноценных рабочих нагрузок с контекстом 128K и высоким разрешением мультимодальных данных рекомендуется 640 ГБ на 8 GPU H100.
Короче говоря: Объем VRAM определяет производительность. API определяет удобство.
Сколько VRAM требуется для локального запуска GLM-4.5V?
Как минимум 48 ГБ для базового инференса. Для полноценных рабочих нагрузок с длинным контекстом и большим объемом визуальных входных данных ожидайте потребности в 640 ГБ (8 GPU H100).
Что делать, если у меня нет такого объема VRAM?
Используйте квантизацию (4-бит/8-бит), уменьшите длину контекста, оптимизируйте KV-кэш или примените выгрузку экспертов MoE, чтобы снизить требования к памяти.
Какие GPU лучше всего подходят для GLM-4.5V?
A6000 / L40S (48 ГБ): Инференс на одной GPU, экономичный вариант.
A100 (80 ГБ): Надежный вариант для инференса и легкого дообучения.
H100 (80 ГБ): Максимальная пропускная способность, поддержка FP8, идеально для production-сред.
Novita AI — это универсальная облачная платформа, которая помогает реализовать ваши амбиции в области ИИ. Интегрированные API, серверless, GPU-инстансы — необходимые вам экономичные инструменты. Избавьтесь от необходимости управления инфраструктурой, начните бесплатно и воплотите ваше видение ИИ в реальность.



