

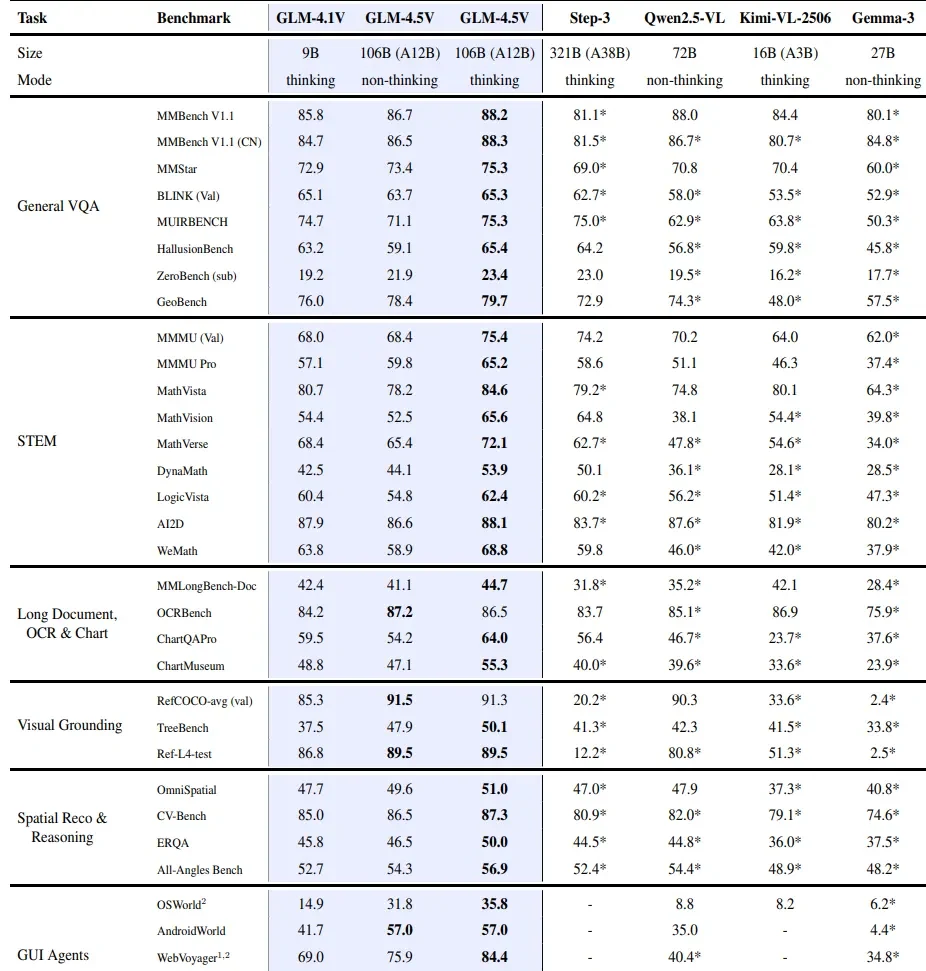
GLM-4.5V ist eines der leistungsstärksten Vision-Language-Modelle (VLMs), die heute verfügbar sind. Mit 106B Gesamtparametern und 12B aktiven Parametern kombiniert es die Stärke von GLM-4.5 mit fortschrittlichen visuellen Encodern für Bilder, Dokumente und Videos. Diese unübertroffene Fähigkeit hat einen Preis: VRAM. Wie viel Speicher wird benötigt, um das stärkste VLM der Welt lokal auszuführen?
Wie viel VRAM benötigt GLM 4.5V?
GLM-4.5V ist die Vision-Language-Variante von GLM-4.5, mit der gleichen Architektur wie das „Air“-Modell mit 106 Milliarden Gesamtparametern und 12 Milliarden aktiven Parametern, aber erweitert um visuelle Encoder zur Verarbeitung von Bildern und Videos. Diese Vision-Komponente erhöht die Speicheranforderungen deutlich.
| GLM 4.5V | 106B | 12B | 128K Token | Multimodal: Vision, Text, Dokumente, Videos |
Optimale VRAM für die Ausführung von GLM-4.5V liegt bei etwa 640 GB auf 8xH100 GPUs, was gerade ausreicht, um Inferenz in FP16 durchzuführen, einschließlich der aktiven Parameter, des visuellen Encoders und der Zwischen-Bild-Tensoren. Während 640 GB für typische Anwendungsfälle ausreichen, können Bilder mit höherer Auflösung oder volle 128k-Token-Kontexte zusätzlichen Speicher oder mehrere GPUs für optimale Leistung erfordern.
GLM 4.5V VRAM im Vergleich zu anderen VLMs
| Modell | Parameter | VRAM-Anforderung (Inferenz) |
|---|---|---|
| GLM‑4.1V‑Thinking (9B) | 9B aktiv | 22–24 GB |
| GLM‑4.5V | 106B gesamt / 12B aktiv | 48 GB |
| Gemma 3 27B | 27B | 70GB |
| Qwen 2.5‑VL (72B) | 72B | 384 GB |
| Kimi VL A3B Thinking 2506 | 16.4GB | 12GB |
GLM 4.5V Leistung im Vergleich zu anderen VLMs
Welche GPU wird für die Ausführung von GLM 4.5V empfohlen?
1. A6000 / L40S (≈48 GB)
- Warum es großartig ist: Passt genau zur FP16-VRAM-Anforderung von GLM‑4.5V (~48 GB), sodass das vollständige Modell (aktive Parameter + Vision-Modul) auf eine einzelne GPU passt.
- Am besten geeignet für: Kostengünstige Bereitstellungen auf einer einzelnen GPU ohne die Komplexität von mehreren GPUs.
- Kompromisse: Geringere Speicherbandbreite und Rechenleistung im Vergleich zu A100/H100. Eingeschränkt für 128K-Kontexte oder Fine-Tuning-Arbeitslasten.
2. A100 80GB
- Warum es zuverlässig ist: Mit 80 GB HBM2e-Speicher führt es GLM‑4.5V komfortabel aus und kann leichtes Fine-Tuning unterstützen. Bewährt im LLM-Training und in der Inferenz.
- Am besten geeignet für: Ausgewogene Trainings- und Inferenz-Arbeitslasten, insbesondere wenn FP8 nicht essenziell ist.
- Kompromisse: Langsamere Inferenz im Vergleich zu H100; keine native FP8-Unterstützung. Ältere Hardware-Generation.
3. H100 80GB
- Warum es hervorsticht: Liefert den höchsten Durchsatz und die beste Effizienz. Unterstützt FP8 für reduzierten VRAM-Verbrauch und schnelle Inferenz – ideal für Long-Context (128K-Token) und anspruchsvolle Bereitstellungen.
- Am besten geeignet für: Vollständige, latenzarme Inferenz in Produktionsumgebungen mit großen Eingaben oder mehreren gleichzeitigen Anfragen.
- Kompromisse: Höchste Kosten, begrenzte Verfügbarkeit und erfordert den neuesten Software-Stack (CUDA 12+, PyTorch Nightly) für FP8-Unterstützung.
Probiere die Bereitstellung von GLM 4.5V jetzt aus!
Fehlerbehebung bei GLM 4.5V VRAM-Problemen
1. Quantisierung
- Verwende 4-Bit- oder 8-Bit-Gewichte, um VRAM zu reduzieren (z. B. 12B → ~6 GB).
- Tools:
GPTQ,LLAMA.cpp,Unsloth GGUF. - Quantisiere auch den KV-Cache für Effizienz bei langen Kontexten.
2. MoE-Offloading
- Behalte die aktiven 12B auf der GPU, offloade inaktive Experten auf die CPU.
- Benötigt schnelle Verbindungen und viel CPU-RAM (≥1 TB für das vollständige Modell).
- Verwende
device_map="auto"mit DeepSpeed oder Accelerate.
3. Kontextlänge begrenzen
- Die Reduzierung von 128k auf 32k/8k senkt den Speicherbedarf um das 4–16-fache.
- Ermöglicht Inferenz auf 12–16 GB GPUs.
- Lange Eingaben bei Bedarf in Blöcken streamen.
4. KV-Cache-Optimierung
- Verwende Genauigkeiten von float16 / int8 / int4.
- Verschiebe den KV-Cache auf die CPU, wenn der GPU-Speicher knapp ist (langsamer, aber funktionsfähig).
5. Kleinere Komponenten verwenden
- Bevorzuge GLM-4.5-Air (nur Text).
- Offloade den visuellen Encoder oder verwende externe Bildmodelle (z. B. CLIP).
- Air ist fast 2× schneller und für die meisten NLP-Aufgaben gut geeignet.
6. Speichereffizientes Fine-Tuning
- Wende LoRA, QLoRA, Gradienten-Checkpointing an.
- Fine-Tune immer Air, es sei denn, Vision wird benötigt.
- 4×80 GB GPUs für Air vs. 16×80 GB für das vollständige GLM.
7. Inferenz-Engine-Anpassungen
- Verwende effiziente Engines:
vLLM,SGLang. - Auf H100: Teile per MIG in 2×40GB für Multi-Instanz-Inferenz auf.
Optimierung von GLM 4.5V für Umgebungen mit wenig VRAM
- CUDA OOM beim Laden: Verwende quantisierte Modelle +
device_map="auto"+ lösche den Cache. - OOM während der Inferenz: Senke
max_new_tokens; kürze den Kontext; offloade den Cache. - FP8-Fehler: Vermeide auf nicht unterstützten GPUs; wechsle zu FP16/BF16.
- Wiederholungen/unsinnige Ausgaben: Können durch niedrigpräzisen Cache oder Überlastung verursacht werden.
- Speicherfragmentierung: Starte die Umgebung neu; reduziere die Batch-Größe; deaktiviere Autotuning.
- CPU-RAM OOM: Überwache die Nutzung; vermeide große Modelle, wenn der RAM gering ist.
- Framework-Fehler: Validiere Speicherkonfigurationen; lies Fehlerprotokolle zu Tensor-/Geräteproblemen.
Wenn du einen bequemeren Weg bevorzugst, kannst du die API wählen!
Die GLM-4.5V-API von Novita AI bietet einen 65,5K-Kontext, mit Eingaben zum Preis von $0,60 pro 1K Token, Ausgaben zum Preis von $1,80 pro 1K Token, sowie Unterstützung für Funktionsaufrufe und strukturierte Ausgaben.
Schritt 1: Einloggen und auf die Modellbibliothek zugreifen
Logge dich in deinem Konto ein und klicke auf die Schaltfläche Modellbibliothek.

Schritt 2: Wähle dein Modell
Durchstöbere die verfügbaren Optionen und wähle das Modell, das deinen Anforderungen entspricht.

Schritt 3: Starte deine kostenlose Testversion
Beginne deine kostenlose Testversion, um die Funktionen des ausgewählten Modells zu erkunden.

Schritt 4: Hol dir deinen API-Schlüssel
Um dich mit der API zu authentifizieren, stellen wir dir einen neuen API-Schlüssel zur Verfügung. Auf der Seite „Einstellungen“ kannst du den API-Schlüssel wie im Bild gezeigt kopieren.

Schritt 5: Installiere die API
Installiere die API über den für deine Programmiersprache spezifischen Paketmanager.
Nach der Installation importierst du die benötigten Bibliotheken in deine Entwicklungsumgebung. Initialisiere die API mit deinem API-Schlüssel, um mit Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat-Completions-API für Python-Nutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_rDfpD7GWNXFvnoIbmYNFkVlStqevDItFJac__3tAuw3ZiENHe3wm498Kv9rZEc5JhZgEJ7c9To5Y3EmZZewMbw==",
)
model = "zai-org/glm-4.5v"
stream = True # or False
max_tokens = 32768
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
GLM-4.5V setzt einen neuen Maßstab für multimodale KI, aber die lokale Bereitstellung erfordert erhebliche GPU-Leistung. 48 GB VRAM (A6000/L40S) sind das Minimum für Standard-Inferenz, während 640 GB über 8×H100 GPUs für vollständige 128K-Kontext- und hochauflösende multimodale Arbeitslasten empfohlen werden.
Kurz gesagt: VRAM bestimmt die Leistung. API bestimmt den Komfort.
Wie viel VRAM benötigt GLM-4.5V lokal? Mindestens 48 GB für Basis-Inferenz. Für vollständige Arbeitslasten mit langem Kontext und umfangreichen Vision-Eingaben liegt der Bedarf bei 640 GB (8×H100 GPUs).
Was, wenn ich nicht so viel VRAM habe? Verwende Quantisierung (4-Bit/8-Bit), reduziere die Kontextlänge, optimiere den KV-Cache oder wende MoE-Offloading an, um den Speicherbedarf zu senken.
Welche GPUs eignen sich am besten für GLM-4.5V?
A6000 / L40S (48 GB): Inferenz auf einer einzelnen GPU, kostengünstig.
A100 (80 GB): Zuverlässig für Inferenz und leichtes Fine-Tuning.
H100 (80 GB): Bester Durchsatz, FP8-Unterstützung, ideal für Produktion.
Novita AI ist die All-in-One-Cloud-Plattform, die deine KI-Ambitionen ermöglicht. Integrierte APIs, Serverless, GPU-Instanzen – die kostengünstigen Tools, die du brauchst. Eliminiere Infrastruktur, starte kostenlos und mache deine KI-Vision zur Realität.



