

GLM-4.5V est l’un des modèles de langage visuel (VLM) les plus puissants disponibles aujourd’hui. Avec 106 milliards de paramètres totaux et 12 milliards de paramètres actifs, il allie la puissance de raisonnement de GLM-4.5 à des encodeurs visuels avancés pour les images, les documents et les vidéos. Cette capacité inégalée a un coût : la VRAM. Quelle quantité de mémoire faut-il pour exécuter localement le VLM le plus puissant au monde ?
Combien de VRAM GLM 4.5V nécessite-t-il ?
GLM-4.5V est la variante vision-langage de GLM-4.5, dotée de la même architecture que le modèle « Air » avec 106 milliards de paramètres totaux et 12 milliards de paramètres actifs, mais améliorée avec des encodeurs visuels pour traiter les images et les vidéos. Ce composant visuel augmente considérablement les exigences en mémoire.
| GLM 4.5V | 106B | 12B | 128K tokens | Multimodal : vision, texte, documents, vidéos |
La VRAM optimale pour exécuter GLM-4.5V est d’environ 640 Go sur 8 GPU H100, ce qui est juste suffisant pour gérer l’inférence en FP16, y compris les paramètres actifs, l’encodeur visuel et les tenseurs d’image intermédiaires. Bien que 640 Go soit suffisant pour une utilisation typique, des images à haute résolution ou des contextes complets de 128k tokens peuvent nécessiter de la mémoire supplémentaire ou plusieurs GPU pour des performances optimales.
VRAM de GLM 4.5V vs autres VLM
| Modèle | Paramètres | Exigence VRAM (Inférence) |
|---|---|---|
| GLM‑4.1V‑Thinking (9B) | 9B actifs | 22–24 Go |
| GLM‑4.5V | 106B totaux / 12B actifs | 48 Go |
| Gemma 3 27B | 27B | 70 Go |
| Qwen 2.5‑VL (72B) | 72B | 384 Go |
| Kimi VL A3B Thinking 2506 | 16,4 Go | 12 Go |
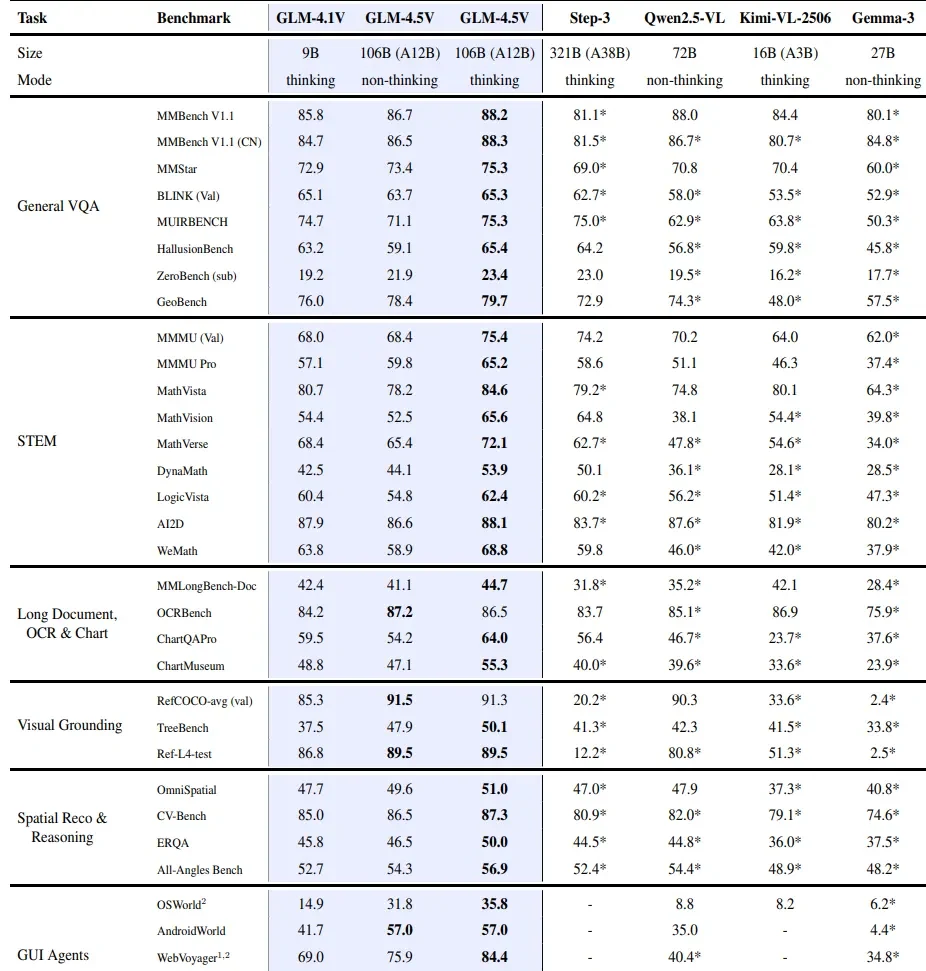
Performances de GLM 4.5V vs autres VLM
Quel GPU est recommandé pour exécuter GLM 4.5V ?
1. A6000 / L40S (≈48 Go)
- Pourquoi c’est un excellent choix : Correspond exactement à l’exigence VRAM FP16 de GLM‑4.5V (~48 Go), permettant au modèle complet (paramètres actifs + module vision) de tenir sur un seul GPU.
- Idéal pour : Des déploiements sur GPU unique économiques, sans la complexité du multi-GPU.
- Inconvénients : Bande passante mémoire et performances de calcul inférieures à l’A100/H100. Limité pour les contextes 128K ou les charges de travail de fine-tuning.
2. A100 80Go
- Pourquoi c’est fiable : Avec 80 Go de mémoire HBM2e, il exécute confortablement GLM‑4.5V et peut prendre en charge un fine-tuning léger. Éprouvé pour l’entraînement et l’inférence LLM.
- Idéal pour : Des charges de travail équilibrées d’entraînement et d’inférence, surtout lorsque le FP8 n’est pas essentiel.
- Inconvénients : Inférence plus lente que le H100 ; pas de prise en charge native du FP8. Matériel de génération précédente.
3. H100 80Go
- Pourquoi il excelle : Offre le débit et l’efficacité les plus élevés. Prend en charge le FP8 pour réduire l’utilisation de la VRAM et une inférence rapide — idéal pour les déploiements à long contexte (128k tokens) et à forte demande.
- Idéal pour : Inférence à grande échelle, faible latence, dans des environnements de production avec des entrées volumineuses ou plusieurs requêtes simultanées.
- Inconvénients : Coût le plus élevé, disponibilité limitée, et nécessite la pile logicielle la plus récente (CUDA 12+, PyTorch nightly) pour la prise en charge du FP8.
Essayez de déployer GLM 4.5V dès maintenant !
Résolution des erreurs de VRAM de GLM 4.5V
1. Quantification
- Utilisez des poids en 4 bits ou 8 bits pour réduire la VRAM (ex : 12B → ~6 Go).
- Outils :
GPTQ,LLAMA.cpp,Unsloth GGUF. - Quantifiez également le cache KV pour l’efficacité des longs contextes.
2. Déchargement MoE
- Gardez les 12B actifs sur le GPU, déchargez les experts inactifs sur le CPU.
- Nécessite une interconnexion rapide et une RAM CPU importante (≥ 1 To pour le modèle complet).
- Utilisez
device_map="auto"avec DeepSpeed ou Accelerate.
3. Limiter la longueur du contexte
- Réduire 128k → 32k/8k réduit la mémoire de 4 à 16 fois.
- Permet l’inférence sur des GPU de 12 à 16 Go.
- Diffusez les entrées longues par morceaux si nécessaire.
4. Optimisation du cache KV
- Utilisez une précision float16 / int8 / int4.
- Déplacez le cache KV vers le CPU si la VRAM du GPU est limitée (plus lent mais fonctionnel).
5. Utiliser des composants plus petits
- Préférez GLM-4.5-Air (texte uniquement).
- Déchargez l’encodeur visuel ou utilisez des modèles d’image externes (ex : CLIP).
- Air est presque 2 fois plus rapide et adapté à la plupart des tâches NLP.
6. Fine-tuning économe en mémoire
- Appliquez LoRA, QLoRA, le checkpointing de gradient.
- Fine-tunez toujours Air sauf si la vision est requise.
- 4 GPU de 80 Go pour Air contre 16 GPU de 80 Go pour le GLM complet.
7. Ajustements du moteur d’inférence
- Utilisez des moteurs efficaces :
vLLM,SGLang. - Sur H100 : Divisez en 2×40Go via MIG pour une inférence multi-instance.
Optimiser GLM 4.5V pour des environnements à faible VRAM
OOM CUDA au chargement : Utilisez des modèles quantifiés + device_map="auto" + videz le cache.
OOM pendant l’inférence : Baissez max_new_tokens ; réduisez le contexte ; déchargez le cache.
Erreurs FP8 : Évitez sur des GPU non pris en charge ; passez en FP16/BF16.
Sortie répétitive/sans sens : Peut résulter d’un cache basse précision ou d’une surcharge.
Fragmentation de la mémoire : Redémarrez l’environnement ; réduisez la taille de batch ; désactivez l’auto-tuning.
OOM RAM CPU : Surveillez l’utilisation ; évitez les gros modèles si la RAM est faible.
Erreurs de framework : Validez les configurations mémoire ; lisez les journaux d’erreur pour les problèmes de tenseur/périphérique.
Si vous voulez une solution plus pratique, vous pouvez choisir l’API !
L’API GLM-4.5V de Novita AI offre un contexte de 65,5K, avec un tarif de 0,60 $/1K tokens en entrée, 1,80 $/1K tokens en sortie, et prend en charge l’appel de fonctions et les sorties structurées.
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.

Étape 3 : Commencez votre essai gratuit
Démarrez votre essai gratuit pour explorer les capacités du modèle sélectionné.

Étape 4 : Récupérez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En accédant à la page « Paramètres », vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Ceci est un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_rDfpD7GWNXFvnoIbmYNFkVlStqevDItFJac__3tAuw3ZiENHe3wm498Kv9rZEc5JhZgEJ7c9To5Y3EmZZewMbw==",
)
model = "zai-org/glm-4.5v"
stream = True # or False
max_tokens = 32768
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
GLM-4.5V établit une nouvelle référence pour l’IA multimodale, mais le déploiement local demande une puissance GPU sérieuse. 48 Go de VRAM (A6000/L40S) est le minimum pour une inférence standard, tandis que 640 Go sur 8 GPU H100 est recommandé pour des charges de travail multimodales complètes avec contexte 128K et entrées à haute résolution.
En bref : La VRAM détermine les performances. L’API détermine la commodité.
Combien de VRAM GLM-4.5V nécessite-t-il localement ?
Au moins 48 Go pour une inférence de base. Pour des charges de travail à grande échelle avec un long contexte et des entrées visuelles importantes, prévoyez 640 Go (8 GPU H100).
Que faire si je n’ai pas autant de VRAM ?
Utilisez la quantification (4 bits/8 bits), réduisez la longueur du contexte, optimisez le cache KV ou appliquez le déchargement MoE pour réduire les exigences mémoire.
Quels sont les meilleurs GPU pour GLM-4.5V ?
A6000 / L40S (48 Go) : Inférence sur GPU unique, économique.
A100 (80 Go) : Fiable pour l’inférence et le fine-tuning léger.
H100 (80 Go) : Meilleur débit, prise en charge FP8, idéal pour la production.
Novita AI est la plateforme cloud tout-en-un qui concrétise vos ambitions en IA. API intégrées, serverless, instances GPU — les outils économiques dont vous avez besoin. Éliminez l’infrastructure, commencez gratuitement et faites de votre vision IA une réalité.



