

GLM-4.5V es uno de los modelos de lenguaje-visión (VLM, por sus siglas en inglés) más potentes disponibles en la actualidad. Con 106B parámetros totales y 12B parámetros activos, combina la potencia de razonamiento de GLM-4.5 con codificadores visuales avanzados para imágenes, documentos y vídeos. Esta capacidad inigualable tiene un coste: la VRAM. ¿Cuánta memoria se necesita para ejecutar localmente el VLM más potente del mundo?
¿Cuánta VRAM necesita GLM 4.5V?
GLM-4.5V es la variante de lenguaje-visión de GLM-4.5, que cuenta con la misma arquitectura que el modelo «Air» con 106 000 millones de parámetros totales y 12 000 millones de parámetros activos, pero mejorada con codificadores visuales para procesar imágenes y vídeos. Este componente visual aumenta significativamente los requisitos de memoria.
| GLM 4.5V | 106B | 12B | 128K tokens | Multimodal: visión, texto, documentos, vídeos |
La VRAM óptima para ejecutar GLM-4.5V es de alrededor de 640 GB en 8 GPU H100, que es suficiente para manejar la inferencia en FP16, incluyendo los parámetros activos, el codificador visual y los tensores intermedios de imagen. Si bien 640 GB es suficiente para un uso habitual, imágenes de mayor resolución o contextos completos de 128k tokens pueden requerir memoria adicional o varias GPU para un rendimiento óptimo.
VRAM de GLM 4.5V comparado con otros VLM
| Modelo | Parámetros | Requisito de VRAM (Inferencia) |
|---|---|---|
| GLM‑4.1V‑Thinking (9B) | 9B activos | 22–24 GB |
| GLM‑4.5V | 106B totales / 12B activos | 48 GB |
| Gemma 3 27B | 27B | 70GB |
| Qwen 2.5‑VL (72B) | 72B | 384 GB |
| Kimi VL A3B Thinking 2506 | 16.4GB | 12GB |
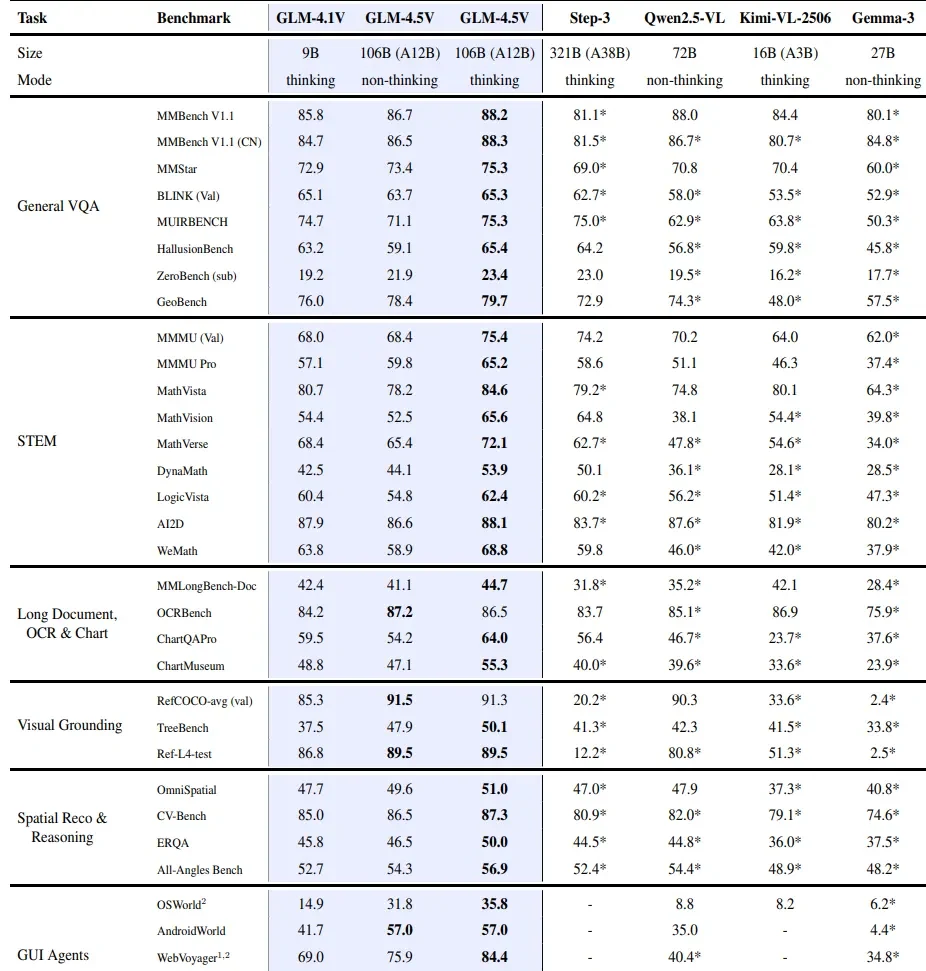
Rendimiento de GLM 4.5V frente a otros VLM
¿Qué GPU se recomienda para ejecutar GLM 4.5V?
1. A6000 / L40S (≈48 GB)
- Por qué es excelente: Coincide exactamente con el requisito de VRAM en FP16 de GLM‑4.5V (~48 GB), lo que permite que el modelo completo (parámetros activos + módulo de visión) quepa en una sola GPU.
- Ideal para: Implementaciones de una sola GPU rentables, sin la complejidad de varias GPU.
- Compromisos: Ancho de banda de memoria y rendimiento de cálculo inferiores en comparación con A100/H100. Limitado para contextos de 128K o cargas de trabajo de ajuste fino.
2. A100 80GB
- Por qué es fiable: Con 80 GB de memoria HBM2e, ejecuta cómodamente GLM‑4.5V y puede soportar ajuste fino ligero. Está ampliamente consolidado en entrenamiento e inferencia de LLM.
- Ideal para: Cargas de trabajo equilibradas de entrenamiento e inferencia, especialmente cuando no es esencial FP8.
- Compromisos: Inferencia más lenta en comparación con H100; carece de soporte nativo para FP8. Hardware de generación anterior.
3. H100 80GB
- Por qué destaca: Ofrece el mayor rendimiento y eficiencia. Soporta FP8 para reducir el uso de VRAM y una inferencia rápida, ideal para implementaciones de contexto largo (128K tokens) y alta demanda.
- Ideal para: Inferencia a gran escala y baja latencia en entornos de producción con entradas grandes o múltiples solicitudes concurrentes.
- Compromisos: Coste más elevado, disponibilidad limitada y requiere la pila de software más reciente (CUDA 12+, PyTorch nightly) para el soporte de FP8.
¡Prueba a desplegar GLM 4.5V ahora!
Solución de problemas de errores de VRAM en GLM 4.5V
1. Cuantización
- Usa pesos de 4 bits u 8 bits para reducir la VRAM (por ejemplo, 12B → ~6 GB).
- Herramientas:
GPTQ,LLAMA.cpp,Unsloth GGUF. - Cuantiza también la caché KV para mayor eficiencia en contextos largos.
2. Offloading de MoE
- Mantén los 12B activos en la GPU, descarga los expertos inactivos a la CPU.
- Necesita una interconexión rápida y mucha RAM de CPU (≥1 TB para el modelo completo).
- Usa
device_map="auto"con DeepSpeed o Accelerate.
3. Limitar la longitud del contexto
- Reducir de 128k a 32k/8k reduce la memoria entre 4 y 16 veces.
- Permite la inferencia en GPU de 12 a 16 GB.
- Transmite las entradas largas en fragmentos si es necesario.
4. Optimización de la caché KV
- Usa precisión float16 / int8 / int4.
- Mueve la caché KV a la CPU si la RAM de la GPU es limitada (más lento, pero funcional).
5. Usar componentes más pequeños
- Prefiere GLM-4.5-Air (solo texto).
- Descarga el codificador de visión o usa modelos de imagen externos (por ejemplo, CLIP).
- Air es casi 2 veces más rápido y válido para la mayoría de tareas de PLN.
6. Ajuste fino eficiente en memoria
- Aplica LoRA, QLoRA, comprobación de gradientes.
- Ajusta siempre Air a menos que se requiera visión.
- 4 GPU de 80 GB para Air frente a 16 GPU de 80 GB para el GLM completo.
7. Ajustes del motor de inferencia
- Usa motores eficientes:
vLLM,SGLang. - En H100: Divídelo en 2×40 GB mediante MIG para inferencia de múltiples instancias.
Optimización de GLM 4.5V para entornos con poca VRAM
Error OOM de CUDA al cargar: Usa modelos cuantizados + device_map="auto" + limpia la caché.
OOM durante la inferencia: Reduce max_new_tokens; recorta el contexto; descarga la caché.
Errores de FP8: Evítalos en GPU no compatibles; cambia a FP16/BF16.
Salida repetitiva o sin sentido: Puede deberse a una caché de baja precisión o sobrecarga.
Fragmentación de memoria: Reinicia el entorno; reduce el tamaño del lote; desactiva el ajuste automático.
OOM de RAM de CPU: Supervisa el uso; evita modelos grandes si la RAM es baja.
Errores de framework: Valida las configuraciones de memoria; lee los registros de errores para problemas de tensores o dispositivos.
Si prefieres una opción más cómoda, ¡puedes elegir la API!
La API de GLM-4.5V de Novita AI ofrece un contexto de 65,5K, con un precio de entrada de $0,60 por 1K tokens, salida de $1,80 por 1K tokens, y soporta llamadas a funciones y salidas estructuradas.
Paso 1: Inicia sesión y accede a la biblioteca de modelos
Inicia sesión en tu cuenta y haz clic en el botón Biblioteca de modelos.

Paso 2: Elige tu modelo
Explora las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.

Paso 3: Inicia tu prueba gratuita
Comienza tu prueba gratuita para explorar las capacidades del modelo seleccionado.

Paso 4: Obtén tu clave de API
Para autenticarte con la API, te proporcionaremos una nueva clave de API. Entrando en la página de «Ajustes», puedes copiar la clave de API como se indica en la imagen.

Paso 5: Instala la API
Instala la API usando el gestor de paquetes específico de tu lenguaje de programación.
Después de la instalación, importa las librerías necesarias en tu entorno de desarrollo. Inicializa la API con tu clave de API para empezar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de finalizaciones de chat para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_rDfpD7GWNXFvnoIbmYNFkVlStqevDItFJac__3tAuw3ZiENHe3wm498Kv9rZEc5JhZgEJ7c9To5Y3EmZZewMbw==",
)
model = "zai-org/glm-4.5v"
stream = True # or False
max_tokens = 32768
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
GLM-4.5V marca un nuevo hito en la IA multimodal, pero su despliegue local exige una potencia de GPU considerable. 48 GB de VRAM (A6000/L40S) es el mínimo para una inferencia estándar, mientras que 640 GB en 8 GPU H100 es lo recomendado para cargas de trabajo multimodales completas de contexto 128K y entradas de alta resolución.
En resumen: la VRAM determina el rendimiento. La API determina la comodidad.
¿Cuánta VRAM necesita GLM-4.5V para ejecutarse localmente?
Al menos 48 GB para una inferencia básica. Para cargas de trabajo a gran escala con contexto largo y entradas visuales pesadas, se necesitan 640 GB (8 GPU H100).
¿Y si no tengo tanta VRAM?
Usa cuantización (4 bits/8 bits), reduce la longitud del contexto, optimiza la caché KV o aplica offloading de MoE para reducir los requisitos de memoria.
¿Qué GPUs son las mejores para GLM-4.5V?
A6000 / L40S (48 GB): Inferencia de una sola GPU, rentable.
A100 (80 GB): Fiable para inferencia y ajuste fino ligero.
H100 (80 GB): Mejor rendimiento, soporte FP8, ideal para producción.
Novita AI es la plataforma cloud todo en uno que hace realidad tus ambiciones en IA. APIs integradas, sin servidor, instancias de GPU: las herramientas rentables que necesitas. Elimina la infraestructura, empieza gratis y convierte tu visión de IA en realidad.



