

- كم VRAM يحتاج إليه نموذج GLM 4.5V؟
- مقارنة بين VRAM لنموذج GLM 4.5V ونماذج VLM الأخرى
- ما هي وحدة المعالجة الرسومية (GPU) الموصى بها لتشغيل GLM 4.5V؟
- استكشاف أخطاء VRAM لنموذج GLM 4.5V وإصلاحها
- تحسين أداء GLM 4.5V لبيئات ذات VRAM منخفض
- إذا كنت تريد طريقة أكثر ملاءمة، يمكنك اختيار واجهة برمجة التطبيقات (API)!
GLM-4.5V هو أحد أقوى نماذج اللغة والرؤية (VLMs) المتاحة اليوم. بفضل 106 مليار معامل إجمالي و 12 مليار معامل نشط، فهو يجمع بين قوة الاستدلال الخاصة بـ GLM-4.5 مع مشفرات بصرية متقدمة للصور والمستندات والفيديو. تأتي هذه القدرات الفريدة بتكلفة: VRAM. كم ذاكرة مطلوبة لتشغيل أقوى VLM في العالم محليًا؟
كم VRAM يحتاج إليه نموذج GLM 4.5V؟
GLM-4.5V هو إصدار اللغة والرؤية من GLM-4.5، ويتميز بنفس بنية نموذج “Air” مع 106 مليار معامل إجمالي و 12 مليار معامل نشط، ولكنه معزز بمشفرات بصرية لمعالجة الصور والفيديوهات. تزيد هذه المكون البصري بشكل كبير من متطلبات الذاكرة.
| GLM 4.5V | 106B | 12B | 128K رمز | متعدد الوسائط: رؤية، نص، مستندات، فيديوهات |
أفضل ذاكرة VRAM لتشغيل GLM-4.5V تبلغ حوالي 640 جيجابايت على 8 وحدات معالجة رسومية من نوع H100، وهي كافية فقط للتعامل مع الاستدلال بتنسيق FP16، بما في ذلك المعاملات النشطة، والمشفر البصري، ومتوسطات الصور الوسيطة. على الرغم من أن 640 جيجابايت كافية للاستخدام النموذجي، فإن الصور عالية الدقة أو سياقات الرموز الكاملة 128k قد تتطلب ذاكرة إضافية أو وحدات معالجة رسومية متعددة لأداء مثالي.
مقارنة بين VRAM لنموذج GLM 4.5V ونماذج VLM الأخرى
| النموذج | المعاملات | متطلبات VRAM (الاستدلال) |
|---|---|---|
| GLM‑4.1V‑Thinking (9B) | 9B نشط | 22–24 جيجابايت |
| GLM‑4.5V | 106B إجمالي / 12B نشط | 48 جيجابايت |
| Gemma 3 27B | 27B | 70 جيجابايت |
| Qwen 2.5‑VL (72B) | 72B | 384 جيجابايت |
| Kimi VL A3B Thinking 2506 | 16.4 جيجابايت | 12 جيجابايت |
أداء GLM 4.5V مقارنة بنماذج VLM الأخرى
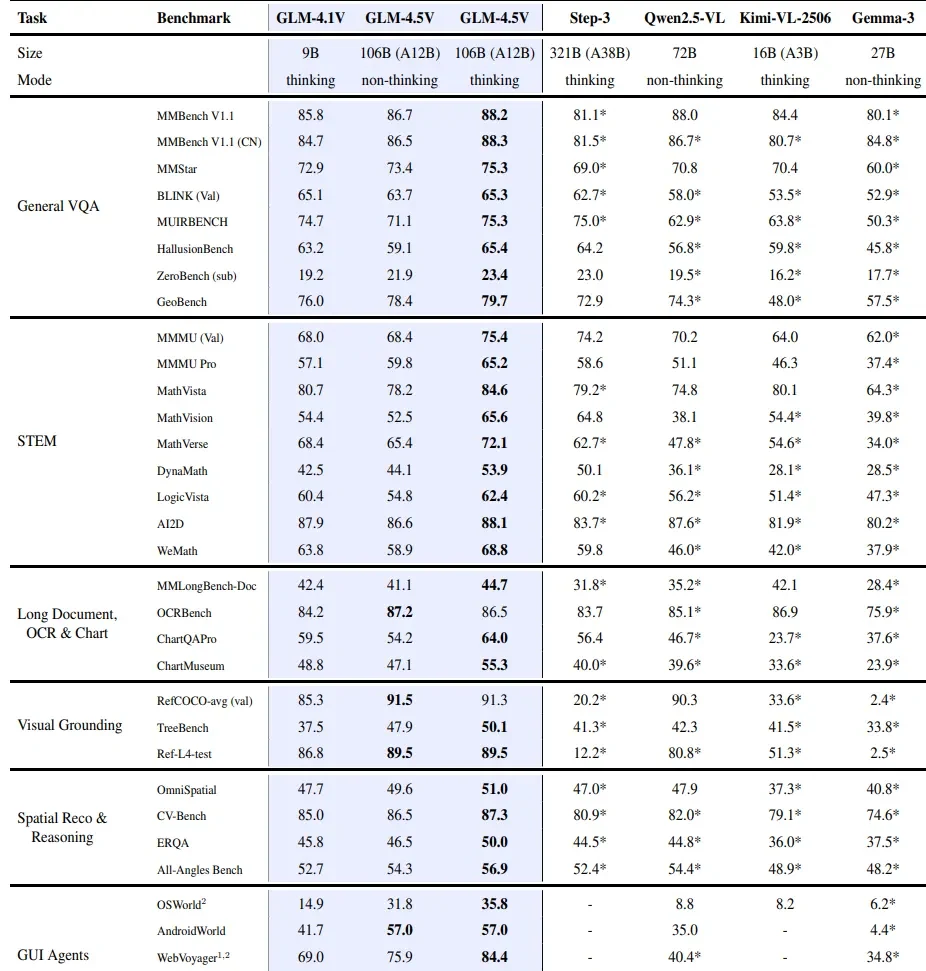
ما هي وحدة المعالجة الرسومية (GPU) الموصى بها لتشغيل GLM 4.5V؟
1. A6000 / L40S (≈48 GB)
- لماذا هو ممتاز: يطابق تمامًا متطلبات VRAM بتنسيق FP16 لنموذج GLM‑4.5V (≈ 48 جيجابايت)، مما يسمح للنموذج الكامل (المعاملات النشطة + الوحدة البصرية) بالاندماج على وحدة معالجة رسومية واحدة.
- الأفضل لعمليات: النشر على وحدة معالجة رسومية واحدة بتكلفة فعالة دون تعقيدات وحدات معالجة رسومية متعددة.
- التنازلات: عرض نطاق ذاكرة أقل وأداء حسابي أقل مقارنة بـ A100/H100. محدود لسياقات 128K أو أحمال عمل ضبط دقيق (fine-tuning).
2. A100 80GB
- لماذا هو موثوق: بذاكرة HBM2e سعة 80 جيجابايت، فإنه يشغل GLM‑4.5V بشكل مريح ويمكنه دعم ضبط دقيق خفيف. إنه راسخ جيدًا في تدريب والاستدلال لنماذج LLM.
- الأفضل لعمليات: أحمال عمل متوازنة للتدريب والاستدلال، خاصة عندما لا يكون تنسيق FP8 ضروريًا.
- التنازلات: استدلال أبطأ مقارنة بـ H100؛ يفتقر إلى دعم أصلي لتنسيق FP8. عتاد من جيل أقدم.
3. H100 80GB
- لماذا يتفوق: يقدم أعلى معدل نقل وكفاءة. يدعم تنسيق FP8 لتقليل استخدام VRAM واستدلال سريع - مثالي للسياقات الطويلة (128K رمز) والنشرات عالية الطلب.
- الأفضل لعمليات: استدلال على نطاق كامل ومنخفض التأخير في بيئات الإنتاج مع مدخلات كبيرة أو طلبات متزامنة متعددة.
- التنازلات: أعلى تكلفة، توفر محدود، ويتطلب أحدث مكدس برمجي (CUDA 12+، إصدارات ليلية من PyTorch) لدعم تنسيق FP8.
استكشاف أخطاء VRAM لنموذج GLM 4.5V وإصلاحها
1. التكميم (Quantization)
- استخدم أوزان 4 بت أو 8 بت لتقليل VRAM (مثال: 12B → ~6 جيجابايت).
- الأدوات:
GPTQ،LLAMA.cpp،Unsloth GGUF. - قم بتكميم ذاكرة التخزين المؤقت KV أيضًا لتحسين الكفاءة في السياقات الطويلة.
2. إلغاء تحميل MoE
- احتفظ بالمعاملات النشطة 12B على GPU، وألغِ تحميل الخبراء غير النشطين إلى وحدة المعالجة المركزية (CPU).
- يتطلب اتصال سريع وذاكرة RAM عالية لوحدة المعالجة المركزية (≥1 تيرابايت للنموذج الكامل).
- استخدم
device_map="auto"مع DeepSpeed أو Accelerate.
3. تحديد طول السياق
- تقليل 128k إلى 32k/8k يقلل الذاكرة بمقدار 4 إلى 16 ضعف.
- يتيح الاستدلال على وحدات معالجة رسومية سعة 12 إلى 16 جيجابايت.
4. تحسين ذاكرة التخزين المؤقت KV
- استخدم دقة float16 / int8 / int4.
- انقل ذاكرة التخزين المؤقت KV إلى وحدة المعالجة المركزية إذا كانت ذاكرة GPU ضيقة (أبطأ لكنها قابلة للاستخدام).
5. استخدام مكونات أصغر
- فضّل نموذج GLM-4.5-Air (نص فقط).
- ألغِ تحميل المشفر البصري أو استخدم نماذج صور خارجية (مثال: CLIP).
- نموذج Air أسرع بضعفين تقريبًا ومناسب لمعظم مهام معالجة اللغة الطبيعية (NLP).
6. ضبط دقيق فعال من حيث الذاكرة
- طبق LoRA، QLoRA، والتحقق من التدرج (gradient checkpointing).
- قم دائمًا بضبط النموذج الدقيق لنموذج Air ما لم تكن هناك حاجة إلى رؤية.
- 4 وحدات معالجة رسومية سعة 80 جيجابايت لنموذج Air مقابل 16 وحدة للنموذج الكامل من GLM.
7. تعديلات محرك الاستدلال
- استخدم محركات فعالة:
vLLM،SGLang. - على وحدات H100: قسّم إلى وحدتين سعة 40 جيجابايت لكل منهما عبر MIG لاستدلال متعدد النسخ.
تحسين أداء GLM 4.5V لبيئات ذات VRAM منخفض
- خطأ نفاد ذاكرة CUDA عند التحميل: استخدم النماذج المكمية +
device_map="auto"+ مسح الذاكرة المؤقتة. - خطأ نفاد الذاكرة أثناء الاستدلال: اخفض
max_new_tokens؛ قلل السياق؛ ألغِ تحميل الذاكرة المؤقتة. - أخطاء تنسيق FP8: تجنبها على وحدات المعالجة الرسومية غير المدعومة؛ تحول إلى تنسيقات FP16/BF16.
- مخرجات مكررة/غير صالحة: يمكن أن تنتج عن ذاكرة مؤقتة منخفضة الدقة أو حمولة زائدة.
- تجزئة الذاكرة: أعد تشغيل البيئة؛ قلل حجم الدفعة (batch size)؛ عطل الضبط التلقائي.
- خطأ نفاد ذاكرة RAM لوحدة المعالجة المركزية: راقب الاستخدام؛ تجنب النماذج الكبيرة إذا كانت ذاكرة RAM منخفضة.
- أخطاء الإطار البرمجي: تحقق من تكوينات الذاكرة؛ اقرأ سجلات الأخطاء للتعرف على مشاكل ال tensors أو الأجهزة.
إذا كنت تريد طريقة أكثر ملاءمة، يمكنك اختيار واجهة برمجة التطبيقات (API)!
توفر واجهة برمجة التطبيقات (API) لنموذج GLM-4.5V من Novita AI سياقًا سعة 65.5K رمز، مع تسعير المدخلات بقيمة 0.60 دولار لكل 1K رمز، والمخرجات بقيمة 1.80 دولار لكل 1K رمز، مع دعم استدعاء الدوال والمخرجات المنظمة.
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
سجل الدخول إلى حسابك وانقر على زر مكتبة النماذج.

الخطوة 2: اختر النموذج الخاص بك
تصفح الخيارات المتاحة واختر النموذج الذي يناسب احتياجاتك.

الخطوة 3: ابدأ تجربتك المجانية
ابدأ تجربتك المجانية لاستكشاف قدرات النموذج المحدد.

الخطوة 4: احصل على مفتاح API الخاص بك
للمصادقة مع واجهة برمجة التطبيقات، سنزودك بمفتاح API جديد. عند الدخول إلى صفحة “الإعدادات”، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

الخطوة 5: تثبيت واجهة برمجة التطبيقات
قم بتثبيت واجهة برمجة التطبيقات باستخدام مدير الحزم الخاص بلغة البرمجة التي تستخدمها.
بعد التثبيت، قم باستيراد المكتبات الضرورية إلى بيئة التطوير الخاصة بك. قم بتهيئة واجهة برمجة التطبيقات باستخدام مفتاح API الخاص بك لبدء التفاعل مع نماذج LLM من Novita AI. هذا مثال على استخدام واجهة برمجة التطبيقات لإكمال المحادثات لمستخدمي لغة بايثون.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="session_rDfpD7GWNXFvnoIbmYNFkVlStqevDItFJac__3tAuw3ZiENHe3wm498Kv9rZEc5JhZgEJ7c9To5Y3EmZZewMbw==",
)
model = "zai-org/glm-4.5v"
stream = True # or False
max_tokens = 32768
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
يضع نموذج GLM-4.5V معيارًا جديدًا للذكاء الاصطناعي متعدد الوسائط، لكن النشر المحلي يتطلب قوة GPU جادة. 48 جيجابايت VRAM (A6000/L40S) هو الحد الأدنى للاستدلال القياسي، بينما يُوصى بـ 640 جيجابايت عبر 8 وحدات H100 لأحمال العمل متعددة الوسائط كاملة السياق 128K وعالية الدقة.
باختصار: VRAM يحدد الأداء. واجهة برمجة التطبيقات (API) تحدد الملاءمة.
كم VRAM يحتاج إليه نموذج GLM-4.5V محليًا؟
ما لا يقل عن 48 جيجابايت للاستدلال الأساسي. لأحمال العمل كاملة النطاق مع سياقات طووية ومدخلات بصرية ثقيلة، توقع 640 جيجابايت (8 وحدات H100).
ماذا لو لم يكن لدي هذا القدر من VRAM؟
استخدم التكميم (4 بت/8 بت)، قلل طول السياق، حسن ذاكرة التخزين المؤقت KV، أو طبق إلغاء تحميل MoE لتقليل متطلبات الذاكرة.
ما هي أفضل وحدات المعالجة الرسومية لنموذج GLM-4.5V؟
A6000 / L40S (48 جيجابايت): استدلال على وحدة معالجة رسومية واحدة، فعال من حيث التكلفة.
A100 (80 جيجابايت): موثوق للاستدلال وضبط دقيق خفيف.
H100 (80 جيجابايت): أفضل معدل نقل، دعم لتنسيق FP8، مثالي للإنتاج.
Novita AI هي منصة سحابية شاملة تمكّنك من تحقيق طموحاتك في الذكاء الاصطناعي. واجهات برمجة تطبيقات متكاملة، بدون خوادم، مثيلات GPU - الأدوات الفعالة من حيث التكلفة التي تحتاجها. تخلص من البنية التحتية، ابدأ مجانًا، وحقق رؤيتك في الذكاء الاصطناعي.



