

Destaques Principais
Pontos fortes do Llama 3.2 90B:
um modelo de linguagem grande multimodal (LLM) que se destaca no raciocínio e compreensão de imagens, além de ter um bom desempenho em tarefas baseadas em texto.
Pontos fortes do Qwen 2.5 72B:
um LLM baseado em texto, focado em forte desempenho em codificação, matemática, seguir instruções e lidar com texto longo.
Suporte a 29 idiomas
Se você está pensando em avaliar o Qwen 2.5 72B em seus próprios casos de uso — Após o registro, a Novita AI oferece um crédito de $0,5 para você começar!
No cenário em rápida evolução dos modelos de linguagem grandes (LLMs), dois concorrentes notáveis surgiram: o Llama 3.2 90B da Meta e o Qwen 2.5 72B da Qwen. Embora ambos os modelos representem avanços significativos em IA, eles atendem a diferentes necessidades e casos de uso. Este artigo fornece uma comparação prática, informativa e técnica desses modelos, examinando sua arquitetura, capacidades, desempenho e requisitos de recursos. Esta comparação visa ajudar desenvolvedores e pesquisadores a tomar decisões informadas sobre qual modelo melhor se adequa aos seus projetos específicos.
Introdução Básica do Modelo
Para iniciar nossa comparação, primeiro entendemos as características fundamentais de cada modelo.
Llama 3.2 90B
- Data de lançamento: 25 de setembro de 2024
- Outros modelos:
- Principais características:
- Modelo multimodal, suporta entradas de texto e imagem
- Suporta inglês, alemão, francês, italiano, português, hindi, espanhol e tailandês
Qwen 2.5 72B
- Data de lançamento: 19 de setembro de 2024 (série Qwen 2.5)
- Escala do modelo:
- Principais características:
- Desempenho melhorado em codificação e matemática
- Seguimento de instruções aprimorado
- Capacidade de geração de texto longo de até 8K tokens
- Forte suporte multilíngue para mais de 29 idiomas
Comparação de Modelos

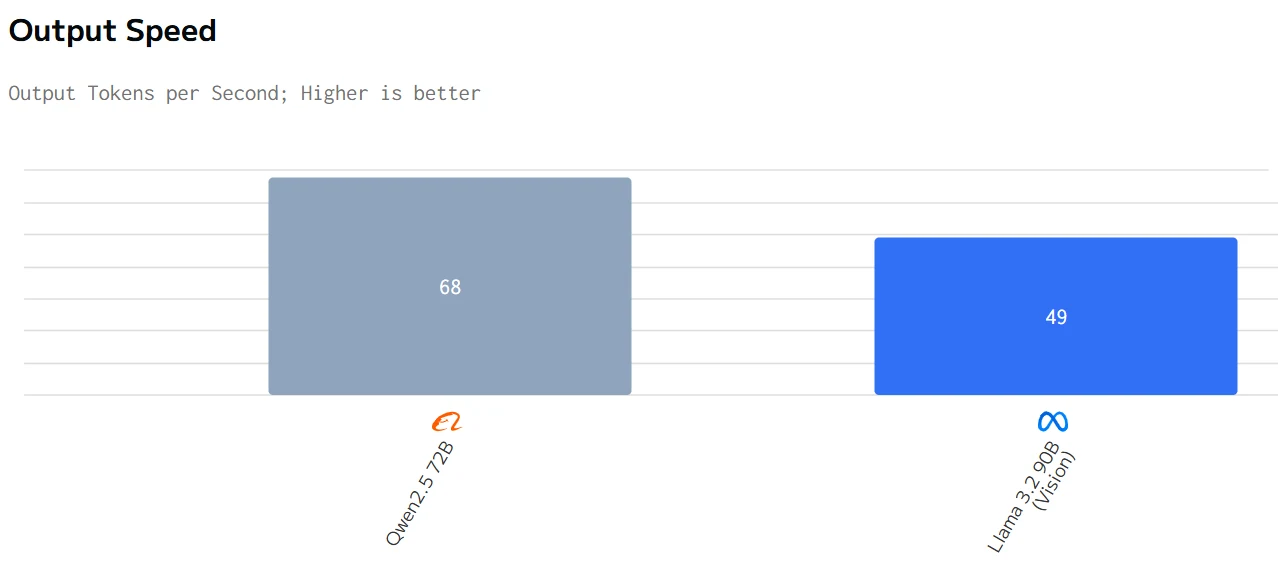
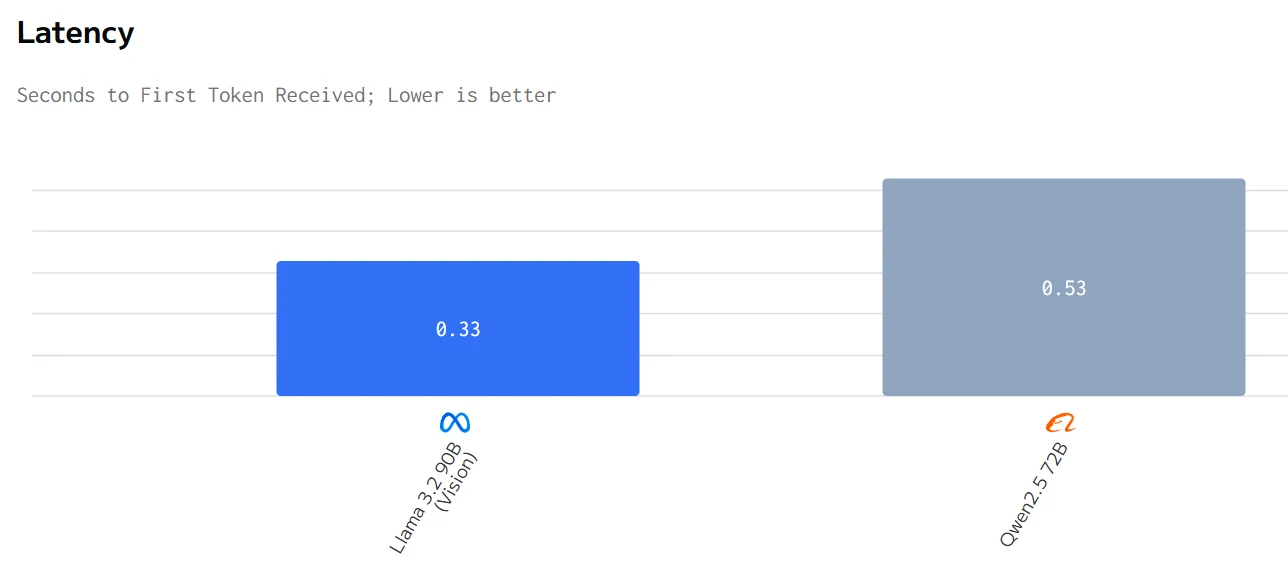
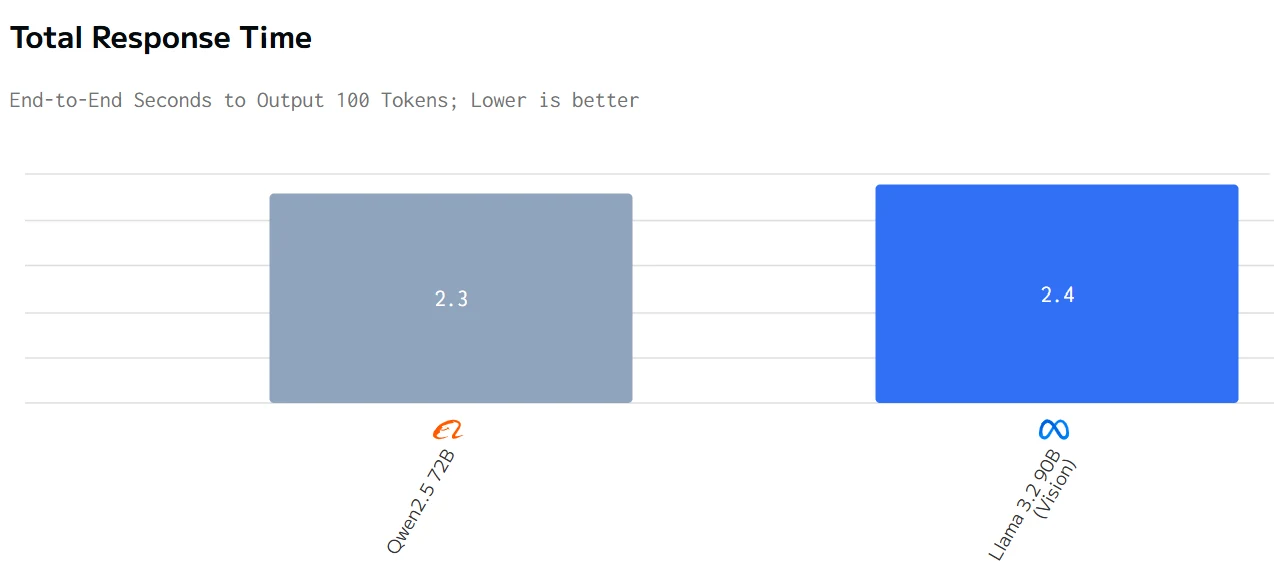
Comparação de Velocidade
Se você quiser testar por conta própria, pode iniciar um teste gratuito no site da Novita AI.
Comparação de Velocidade
fonte de artificialanalysis
Comparação de Custos
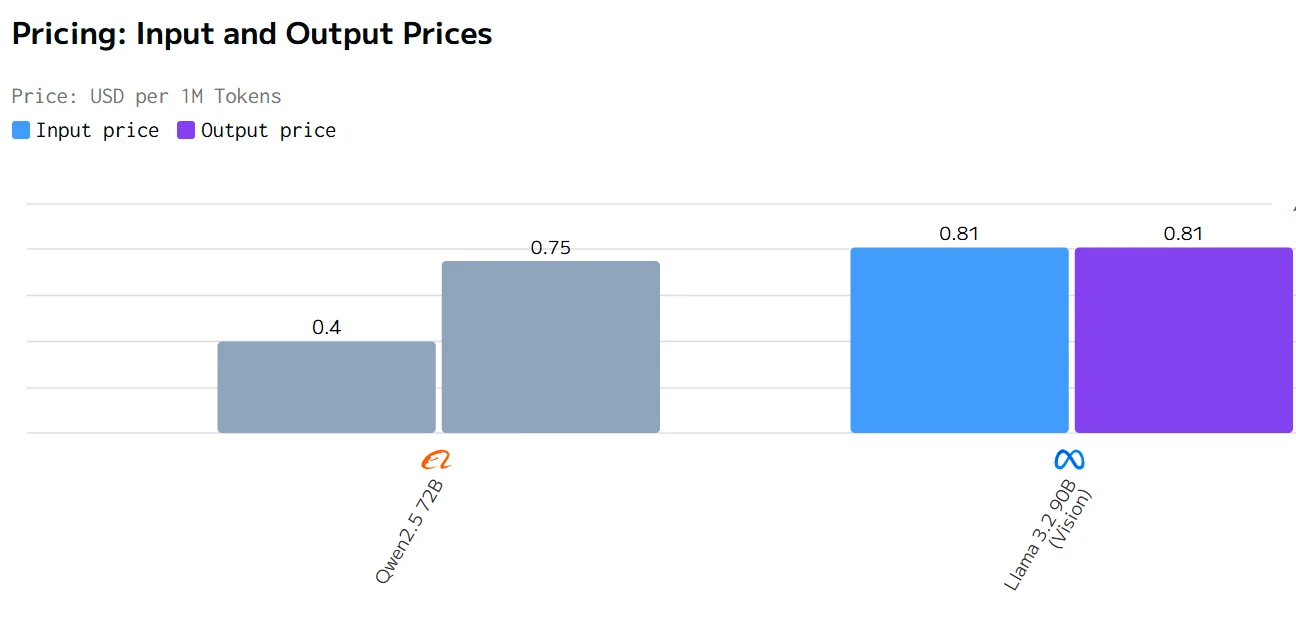
fonte de artificialanalysis
Em resumo, o Qwen2.5 72B tem melhor desempenho em termos de tempo total de resposta, preço e velocidade de saída, enquanto o Llama 3.2 90B tem melhor desempenho em termos de latência.
Comparação de Benchmarks
Agora que estabelecemos as características básicas de cada modelo, vamos nos aprofundar em seu desempenho em vários benchmarks. Esta comparação ajudará a ilustrar seus pontos fortes em diferentes áreas.
| Benchmark Metrics | Llama 3.2 90B (vision) | Qwen 2.5 72b |
|---|---|---|
| MMLU | 84 | 86,8 |
| HumanEval | 80 | 59,1 |
| MATH | 65 | 83,1 |
Em resumo, o Qwen 2.5 72b tem melhor desempenho nos benchmarks MMLU e MATH, enquanto o Llama 3.2 90B (vision) se destaca no HumanEval. Além disso, as versões especializadas do Qwen 2.5, nomeadamente Qwen 2.5-Coder e Qwen 2.5-Math, podem oferecer desempenho superior em tarefas relacionadas à programação e matemática, respectivamente. O desempenho de diferentes modelos varia significativamente em diferentes tarefas, portanto, a escolha do modelo deve ser baseada nos requisitos específicos da tarefa em questão.
Se você quiser saber mais sobre o conhecimento de benchmark do llama3.3, pode ver este artigo:
Se você quiser ver mais comparações entre o llama 3.3 e outros modelos, confira estes artigos:
- Qwen 2.5 72b vs Llama 3.3 70b: Which Model Suits Your Needs?
- Llama 3.1 70b vs. Llama 3.3 70b: Better Performance, Higher Price
- Is Llama 3.3 70B Really Comparable to Llama 3.1 405B?
Aplicações e Casos de Uso
Llama 3.2 90B:
- Compreensão e raciocínio de imagens
- Legendagem de imagens
- Compreensão em nível de documentos, incluindo gráficos e diagramas
- Tarefas de ancoragem visual
- Tradução em tempo real com entradas visuais
Qwen 2.5 72B:
- Chatbots e assistentes multilíngues
- Assistência em codificação e geração de código
- Geração de dados sintéticos
- Criação de conteúdo multilíngue e localização
- Aplicações baseadas em conhecimento, como perguntas e respostas
Acessibilidade e Implantação através da Novita AI
Passo 1: Faça login e acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Model Library.

Passo 2: Escolha seu modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.

Passo 3: Inicie seu teste gratuito
Inicie seu teste gratuito para explorar as capacidades do modelo selecionado.

Passo 4: Obtenha sua chave de API
Para autenticar com a API, forneceremos uma nova chave de API. Acesse a página “Settings”, você pode copiar a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico para sua linguagem de programação.

Após a instalação, importe as bibliotecas necessárias para seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o LLM da Novita AI. Este é um exemplo de uso da API de chat completions para usuários de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
# Get the Novita AI API Key by referring to: https://novita.ai/docs/get-started/quickstart.html#_2-manage-api-key.
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwen-2.5-72B"
stream = True # or False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Act like you are a helpful assistant.",
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "")
else:
print(chat_completion_res.choices[0].message.content)
Após o registro, a Novita AI oferece um crédito de $0,5 para você começar!
Se os créditos gratuitos acabarem, você pode pagar para continuar usando.
Tanto o Llama 3.3 70B quanto o Llama 3.2 90B oferecem vantagens exclusivas adaptadas a diferentes casos de uso. O Llama 3.3 se destaca em tarefas baseadas em texto que exigem fortes capacidades multilíngues e seguir instruções, com ênfase na eficiência, enquanto o Llama 3.2 brilha em aplicações multimodais que envolvem compreensão de imagens.
Perguntas Frequentes
Como o Llama 3.3 difere do Llama 3.2?
O Llama 3.3 é otimizado para tarefas de texto, destacando-se em capacidades multilíngues, enquanto o Llama 3.2 é multimodal, lidando tanto com imagens quanto com texto.
O Llama 3.3 pode ser executado em hardware de desenvolvedor padrão?**
Sim, ele é projetado para GPUs comuns e estações de trabalho de nível de desenvolvedor. Este artigo polido fornece uma comparação completa dos dois modelos, mantendo clareza no contexto e na estrutura.
Novita AI é a plataforma All-in-one em nuvem que impulsiona suas ambições de IA. APIs integradas, serverless, GPU Instance — as ferramentas econômicas que você precisa. Elimine a infraestrutura, comece gratuitamente e torne sua visão de IA realidade.



