

Puntos Clave
Fortalezas de Llama 3.2 90B:
Un modelo de lenguaje grande (LLM) multimodal que sobresale en razonamiento y comprensión de imágenes, además de rendir bien en tareas basadas en texto.
Fortalezas de Qwen 2.5 72B:
Un LLM basado en texto, centrado en un rendimiento sólido en codificación, matemáticas, seguimiento de instrucciones y manejo de textos largos.
Compatible con 29 idiomas.
Si deseas evaluar Qwen 2.5 72B en tus propios casos de uso — Al registrarte, Novita AI te proporciona un crédito de $0.5 para empezar.
En el panorama en rápida evolución de los modelos de lenguaje grandes (LLM), han surgido dos contendientes notables: Llama 3.2 90B de Meta y Qwen 2.5 72B de Qwen. Si bien ambos modelos representan avances significativos en IA, se adaptan a diferentes necesidades y casos de uso. Este artículo ofrece una comparación práctica, informativa y técnica de estos modelos, examinando su arquitectura, capacidades, rendimiento y requisitos de recursos. Esta comparación tiene como objetivo ayudar a desarrolladores e investigadores a tomar decisiones informadas sobre qué modelo se adapta mejor a sus proyectos específicos.
Introducción Básica de los Modelos
Para comenzar nuestra comparación, primero comprendemos las características fundamentales de cada modelo.
Llama 3.2 90B
- Fecha de lanzamiento: 25 de septiembre de 2024
- Otros modelos:
- Características clave:
- Modelo multimodal, admite entradas de texto e imagen
- Compatible con inglés, alemán, francés, italiano, portugués, hindi, español y tailandés
Qwen 2.5 72B
- Fecha de lanzamiento: 19 de septiembre de 2024 (serie Qwen 2.5)
- Escala del modelo:
- Características clave:
- Rendimiento mejorado en codificación y matemáticas
- Seguimiento de instrucciones mejorado
- Capacidades de generación de textos largos de hasta 8K tokens
- Fuerte soporte multilingüe para más de 29 idiomas
Comparación de Modelos

Comparación de Velocidad
Si deseas probarlo tú mismo, puedes iniciar una prueba gratuita en el sitio web de Novita AI.
Comparación de Velocidad
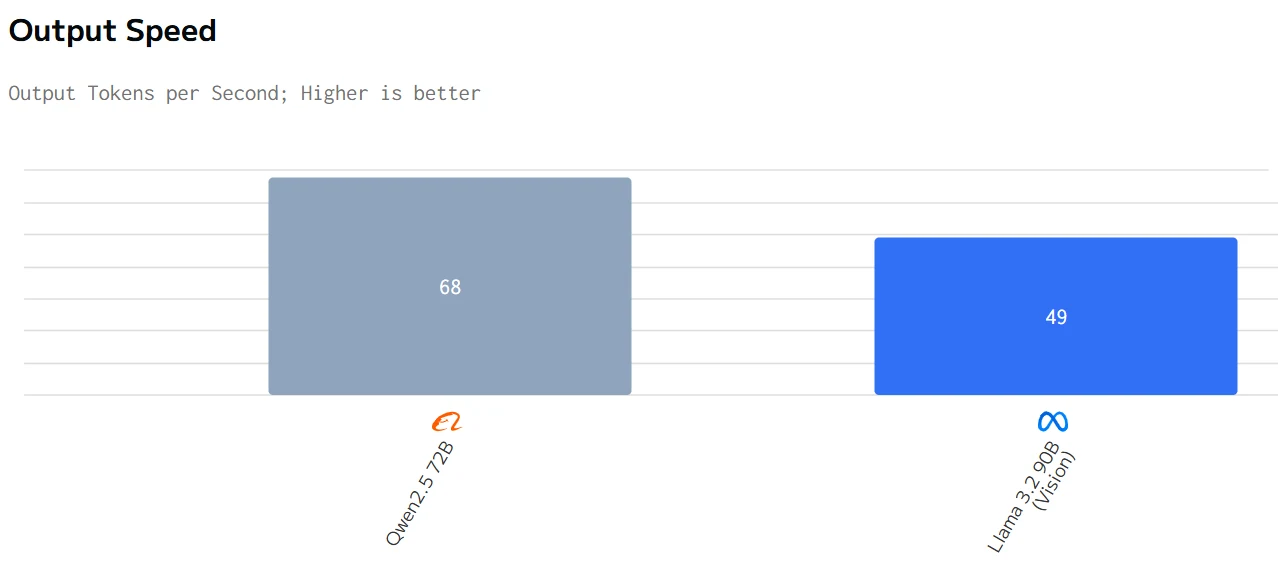
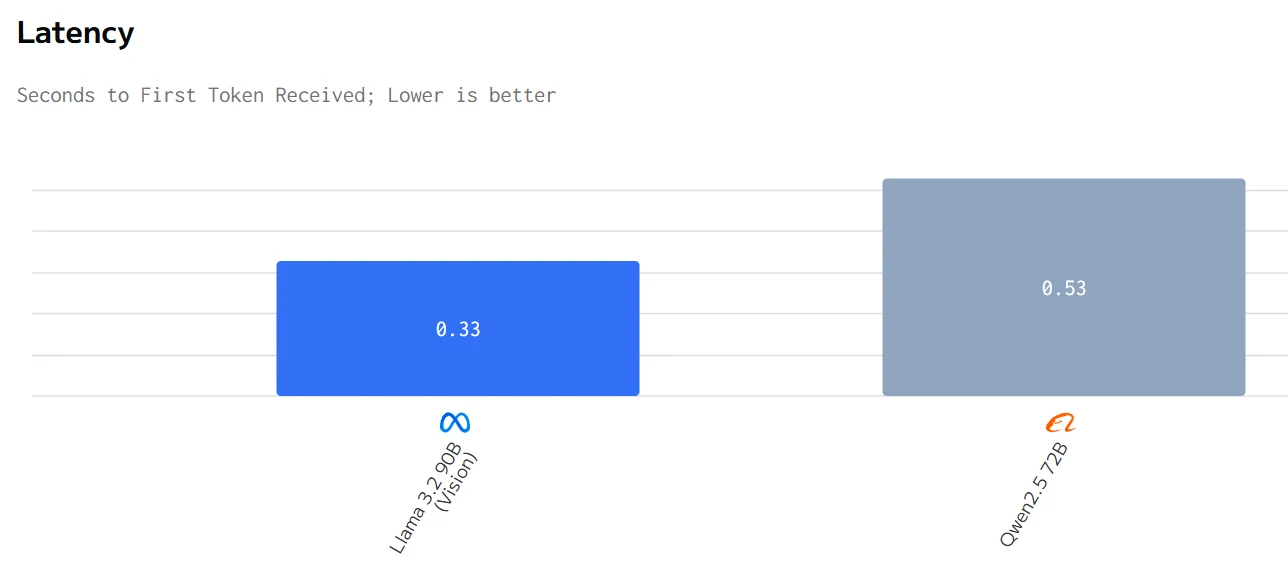
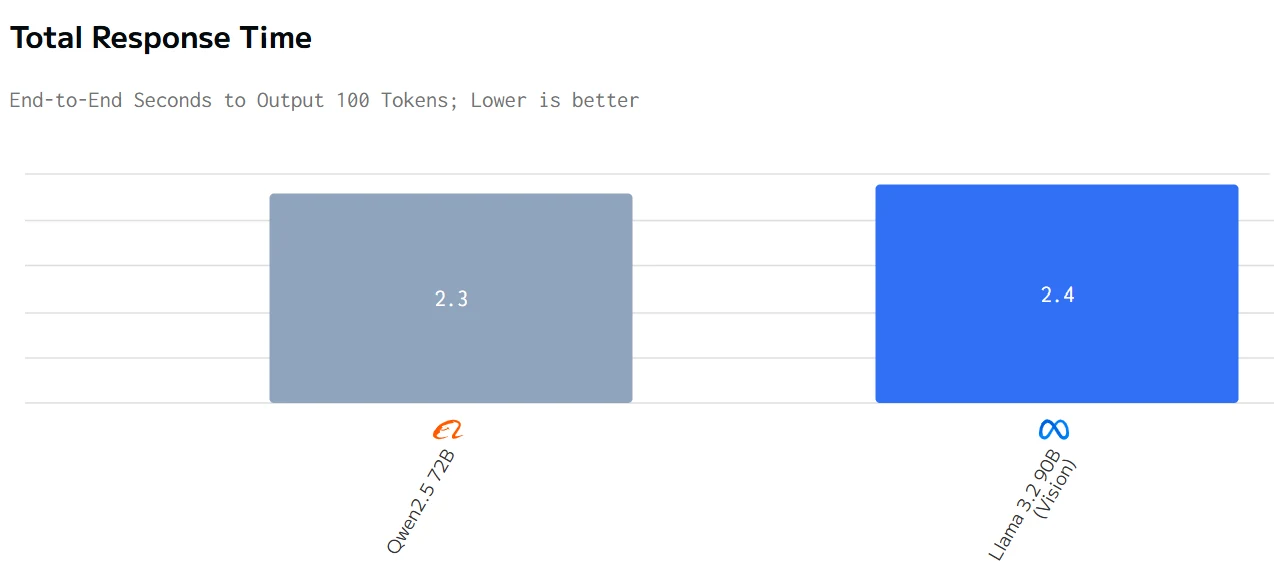
fuente de artificialanalysis
Comparación de Costos
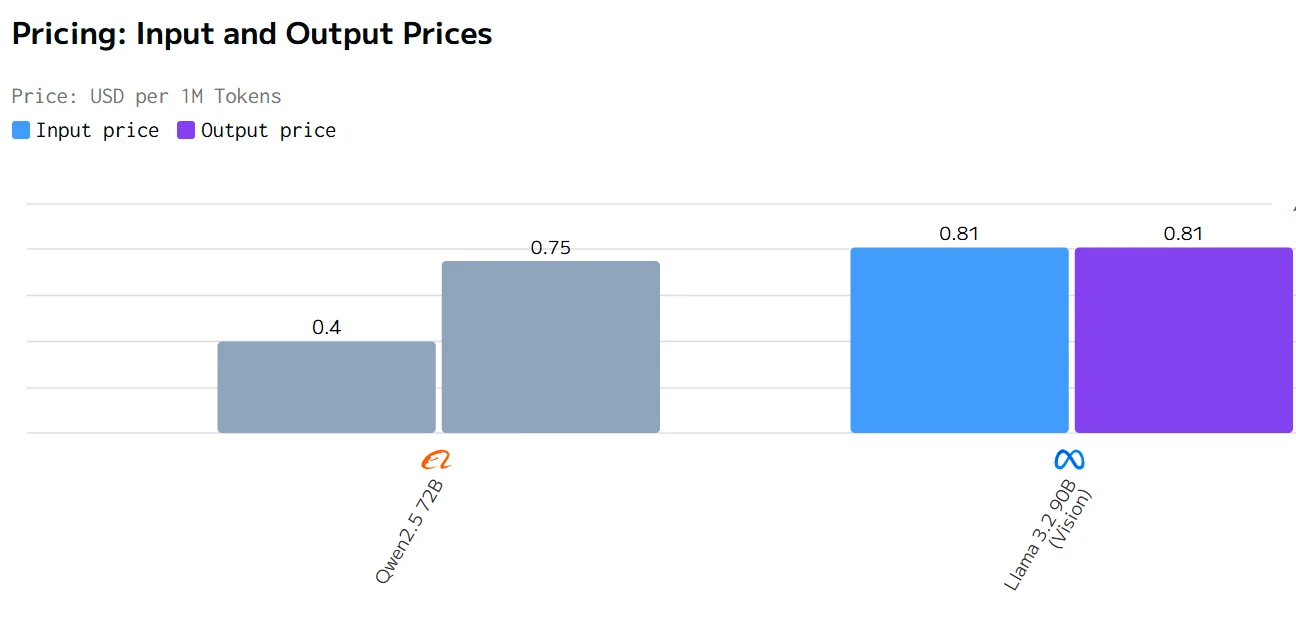
fuente de artificialanalysis
En resumen, Qwen2.5 72B tiene un mejor rendimiento en tiempo total de respuesta, precio y velocidad de salida, mientras que Llama 3.2 90B tiene un mejor rendimiento en latencia.
Comparación de Benchmarks
Ahora que hemos establecido las características básicas de cada modelo, profundicemos en su rendimiento en varios benchmarks. Esta comparación ayudará a ilustrar sus fortalezas en diferentes áreas.
| Métrica de Benchmark | Llama 3.2 90B (visión) | Qwen 2.5 72b |
|---|---|---|
| MMLU | 84 | 86.8 |
| HumanEval | 80 | 59.1 |
| MATH | 65 | 83.1 |
En resumen, Qwen 2.5 72b tiene un mejor rendimiento en los benchmarks MMLU y MATH, mientras que Llama 3.2 90B (visión) destaca en HumanEval. Además, las versiones especializadas de Qwen 2.5, llamadas Qwen 2.5-Coder y Qwen 2.5-Math, pueden ofrecer un rendimiento superior en tareas relacionadas con programación y matemáticas, respectivamente. El rendimiento de diferentes modelos varía significativamente según la tarea, por lo que la elección del modelo debe basarse en los requisitos específicos de la tarea en cuestión.
Si deseas conocer más sobre el conocimiento de los benchmarks de llama3.3, puedes consultar el siguiente artículo:
Si deseas ver más comparaciones entre llama 3.3 y otros modelos, puedes consultar estos artículos:
- Qwen 2.5 72b vs Llama 3.3 70b: ¿Qué Modelo se Adapta a tus Necesidades?
- Llama 3.1 70b vs. Llama 3.3 70b: Mejor Rendimiento, Precio Más Alto
- ¿Es Llama 3.3 70B Realmente Comparable a Llama 3.1 405B?
Aplicaciones y Casos de Uso
Llama 3.2 90B:
- Comprensión y razonamiento de imágenes
- Generación de descripciones de imágenes
- Comprensión a nivel de documentos, incluyendo gráficos y tablas
- Tareas de anclaje visual
- Traducción en tiempo real con entradas visuales
Qwen 2.5 72B:
- Chatbots y asistentes multilingües
- Asistencia en codificación y generación de código
- Generación de datos sintéticos
- Creación y localización de contenido multilingüe
- Aplicaciones basadas en conocimiento como respuesta a preguntas
Accesibilidad e Implementación a través de Novita AI
Paso 1: Inicia Sesión y Accede a la Biblioteca de Modelos
Inicia sesión en tu cuenta y haz clic en el botón Biblioteca de Modelos.

Paso 2: Elige tu Modelo
Navega por las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.

Paso 3: Inicia tu Prueba Gratuita
Comienza tu prueba gratuita para explorar las capacidades del modelo seleccionado.

Paso 4: Obtén tu Clave API
Para autenticarte con la API, te proporcionaremos una nueva clave API. Ingresa a la página “Configuración”, puedes copiar la clave API como se indica en la imagen.

Paso 5: Instala la API
Instala la API usando el administrador de paquetes específico para tu lenguaje de programación.

Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave API para comenzar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de chat completions para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
# Obtén la clave API de Novita AI consultando: https://novita.ai/docs/get-started/quickstart.html#_2-manage-api-key.
api_key="<TU CLAVE API DE Novita AI>",
)
model = "qwen/qwen-2.5-72B"
stream = True # o False
max_tokens = 512
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": "Actúa como un asistente útil.",
},
{
"role": "user",
"content": "¡Hola!",
}
],
stream=stream,
max_tokens=max_tokens,
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "")
else:
print(chat_completion_res.choices[0].message.content)
Al registrarte, Novita AI te proporciona un crédito de $0.5 para empezar.
Si los créditos gratuitos se agotan, puedes pagar para seguir usándolo.
Tanto Llama 3.3 70B como Llama 3.2 90B ofrecen ventajas únicas adaptadas a diferentes casos de uso. Llama 3.3 destaca en tareas basadas en texto que requieren fuertes capacidades multilingües y seguimiento de instrucciones con énfasis en eficiencia, mientras que Llama 3.2 brilla en aplicaciones multimodales que implican comprensión de imágenes.
Preguntas Frecuentes
¿En qué se diferencia Llama 3.3 de Llama 3.2?
Llama 3.3 está optimizado para tareas de texto, destacando en capacidades multilingües, mientras que Llama 3.2 es multimodal, manejando tanto imágenes como texto.
¿Puede Llama 3.3 ejecutarse en hardware de desarrollador estándar?
Sí, está diseñado para GPU comunes y estaciones de trabajo de nivel desarrollador.
Novita AI es la plataforma en la nube integral que impulsa tus ambiciones de IA. APIs integradas, sin servidor, instancia de GPU — las herramientas rentables que necesitas. Elimina la infraestructura, comienza gratis y haz realidad tu visión de IA.



