

Os desenvolvedores hoje enfrentam dois problemas principais: benchmarks que não refletem a entrega real de aplicativos e modelos de fronteira cujos custos tornam o uso em grande escala inviável. Este artigo aborda ambos apresentando o VIBE, um benchmark em nível de runtime criado pela Minimax, e mostrando como o Minimax M2.1 oferece capacidade full-stack próxima à de fronteira a um preço drasticamente menor. Ele explica o que o VIBE mede, como o Minimax M2.1 se desempenha e como os desenvolvedores podem acessá-lo e implantá-lo em fluxos de trabalho Web, API, locais e baseados em agentes.
Benchmarking da Inteligência de Aplicativos Full-Stack do Minimax M2.1
A Minimax apresenta o VIBE, um benchmark desenvolvido propositalmente para medir a capacidade de um modelo de construir aplicativos completos e executáveis do zero. Ao contrário dos benchmarks de codificação tradicionais que avaliam trechos isolados, o VIBE executa o projeto gerado em ambientes de runtime reais e verifica tanto a correção funcional quanto o comportamento visual.
| Benchmark | MiniMax-M2.1 | MiniMax-M2 | Claude Sonnet 4.5 | Claude Opus 4.5 | Gemini 3 Pro |
|---|---|---|---|---|---|
| VIBE (Média) | 88.6 | 67.5 | 85.2 | 90.7 | 82.4 |
| VIBE-Web | 91.5 | 80.4 | 87.3 | 89.1 | 89.5 |
| VIBE-Simulação | 87.1 | 77.0 | 79.1 | 84.0 | 89.2 |
| VIBE-Android | 89.7 | 69.2 | 87.5 | 92.2 | 78.7 |
| VIBE-iOS | 88.0 | 39.5 | 81.2 | 90.0 | 75.8 |
| VIBE-Backend | 86.7 | 67.8 | 90.8 | 98.0 | 78.7 |
O que torna isso ainda mais interessante é o custo. O M2.1 oferece capacidade full-stack próxima à de fronteira a um preço significativamente menor do que modelos comparáveis. Na prática, isso muda a forma como as equipes podem usar LLMs.

Como Acessar o Minimax M2.1?
1. Interface Web do Minimax M2.1
Experimente o Minimax M2.1 Agora!
2. Acesso à API do Minimax M2.1 para Desenvolvedores
Passo 1: Faça login e acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Biblioteca de Modelos.

Passo 2: Escolha seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.

Passo 3: Inicie seu Teste Gratuito
Comece seu teste gratuito para explorar as capacidades do modelo selecionado.
Experimente o Minimax M2.1 Agora!
Passo 4: Obtenha sua Chave de API
Para autenticar com a API, forneceremos uma nova chave de API. Acessando a página de “Configurações“, você pode copiar a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico da sua linguagem de programação.
Após a instalação, importe as bibliotecas necessárias para o seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o LLM da Novita AI. Este é um exemplo de uso da API de conclusões de chat para usuários de Python.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.1",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
3. Implantação Local do Minimax M2.1 e Endpoints Dedicados
Requisitos:
| Configuração | Contexto Máximo | Caso de Uso |
|---|---|---|
| 4× A100 ou A800 (80 GB) | 400K tokens | Implantações padrão |
| 4× H200 ou H20 (96 GB+) | 400K tokens | Implantações padrão |
| 8× H200 (141 GB) | 3M tokens | Cargas de trabalho de contexto estendido |
Passos de Instalação:
- Baixe os pesos do modelo no HuggingFace ou no ModelScope
- Escolha o framework de inferência: vLLM ou SGLang são suportados
- Siga o guia de implantação no repositório oficial do GitHub
Você escolheria um endpoint dedicado quando precisar de inferência de alto desempenho estável, controle personalizado do modelo e custo menor em cargas de trabalho contínuas ou pesadas, em vez de manter GPUs e infraestrutura locais.
Teste o Endpoint Dedicado Agora!
4. Integração do Minimax M2.1 com Ferramentas de Agente de Código
O Minimax M2.1 foi desenvolvido para servir como uma espinha dorsal estável para fluxos de trabalho de Agentes de Código, integrando-se suavemente com Claude Code, Droid (Factory AI), Cline, Kilo Code e Roo Code, além de suportar sistemas de contexto estruturados como Skill.md, Claude.md, agent.md, cursorrule e Slash Commands. Ele mantém a coerência em planejamentos de longo prazo e execuções iterativas, permitindo tarefas como scaffolding de múltiplos arquivos, loops de refatoração e depuração autônoma.
Por meio da Novita AI, os desenvolvedores podem contornar restrições regionais e implantar o M2.1 diretamente em pipelines existentes com estabilidade de 99% de SLA, tornando-o adequado para geração de código de alta frequência e automação de CI. A mesma stack também oferece o Kimi-K2 e o Qwen3 Coder, entregando desempenho de codificação próximo ao do Claude Sonnet 4 a menos de um quinto do custo, permitindo que as equipes escalem o desenvolvimento orientado a agentes de forma econômica.
Primeiro: Obtenha sua Chave de API
Obtenha sua Chave de API Agora!
Minimax M2.1 no Cursor
Passo 1: Instale o Cursor
Baixe a versão mais recente em cursor.com, assine o plano Pro e conclua a configuração inicial.
Passo 2: Acesse as Configurações Avançadas de Modelo
No Cursor, abra Configurações, selecione Modelos no menu à esquerda e localize Configuração da API.
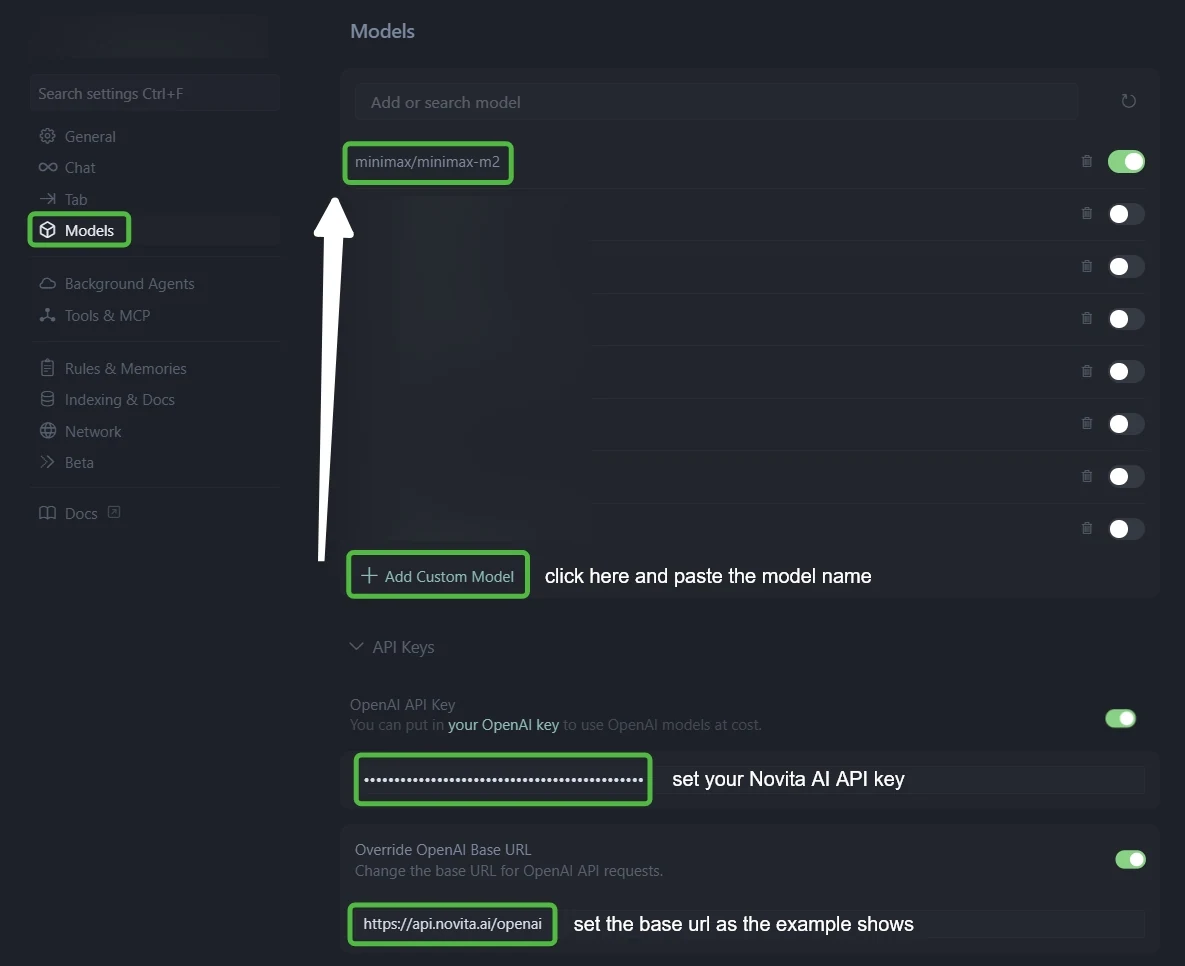
Passo 3: Configure a Integração com a Novita AI
- No campo “Chave de API do OpenAI”: Cole sua chave de API da Novita AI
- No campo “Substituir URL Base do OpenAI”: Substitua o padrão por:
https://api.novita.ai/openai
Passo 4: Adicione Vários Modelos de Codificação com IA
Clique em “+ Adicionar Modelo Personalizado” e adicione cada modelo:
- minimax/minimax m2.1
qwen/qwen3-vl-235b-a22b-thinkingzai-org/glm-4.6deepseek/deepseek-v3.1moonshotai/kimi-k2-0905openai/gpt-oss-120bgoogle/gemma-3-12b-it
Passo 5: Teste sua Integração
Inicie um novo chat no modo Perguntar ou Agente, alterne entre os modelos e confira se cada um responde corretamente.
Minimax M2.1 no Claude Code
Passo 1: Instale o Claude Code
Primeiro, verifique se o Node.js 18 ou superior está instalado no seu sistema:
node -v
# Saída esperada: v18.x.x ou superior (ex: v20.10.0)
Se o Node.js estiver ausente ou for anterior à v18, baixe e instale uma versão recente em [https://nodejs.org](https://nodejs.org)
- Comando de Instalação:
Instale o Claude Code globalmente usando o npm:
npm install -g @anthropic-ai/claude-code
- Verifique a Instalação:
claude --version
Passo 2: Configurando Variáveis de Ambiente
No Windows: Defina as variáveis para a sessão atual do CMD:
set ANTHROPIC_BASE_URL=https://api.novita.ai/anthropic
set ANTHROPIC_AUTH_TOKEN=<Your_Novita_API_Key>
set ANTHROPIC_MODEL=minimax/minimax-m2.1
set ANTHROPIC_SMALL_FAST_MODEL=minimax/minimax-m2.1
No macOS e Linux: Exporte as variáveis no seu shell:
export ANTHROPIC_BASE_URL="https://api.novita.ai/anthropic"
export ANTHROPIC_AUTH_TOKEN="<Your_Novita_API_Key>"
export ANTHROPIC_MODEL="minimax/minimax-m2.1"
export ANTHROPIC_SMALL_FAST_MODEL="minimax/minimax-m2.1"
Passo 3: Iniciando o Claude Code
- Navegue até o Diretório do seu Projeto
cd <path_to_your_project>
- Inicie o Claude Code
claude .
O ponto (.) informa ao Claude Code para operar no diretório atual, escaneando e trabalhando dentro deste projeto.
Após a inicialização, você verá um prompt interativo do Claude Code com acesso a comandos como /init, /model, /review e outros.
Comandos comuns de sessão incluem:
/init– Inicializa o Claude Code no diretório atual./login– Autentica com um provedor de API, se necessário./logout– Limpa as credenciais armazenadas./memory– Visualiza ou edita a memória persistente./model– Visualiza ou alterna o modelo atual./permissions– Gerencia permissões de arquivos e comandos./review– Revisa as alterações pendentes antes de aplicá-las./status– Mostra o status da sessão atual./terminal-setup– Configura a integração com o terminal./vim– Alterna os atalhos do Vim.
Minimax M2.1 no Trae
Passo 1: Abra o Trae e Acesse os Modelos
Inicie o aplicativo Trae. Clique na Barra Lateral de IA Alternável no canto superior direito para abrir a Barra Lateral de IA. Em seguida, vá para Gerenciamento de IA e selecione Modelos.

Passo 2: Adicione um Modelo Personalizado
Clique no botão Adicionar Modelo para criar uma entrada de modelo personalizado.

Passo 3: Escolha a Novita como Provedor
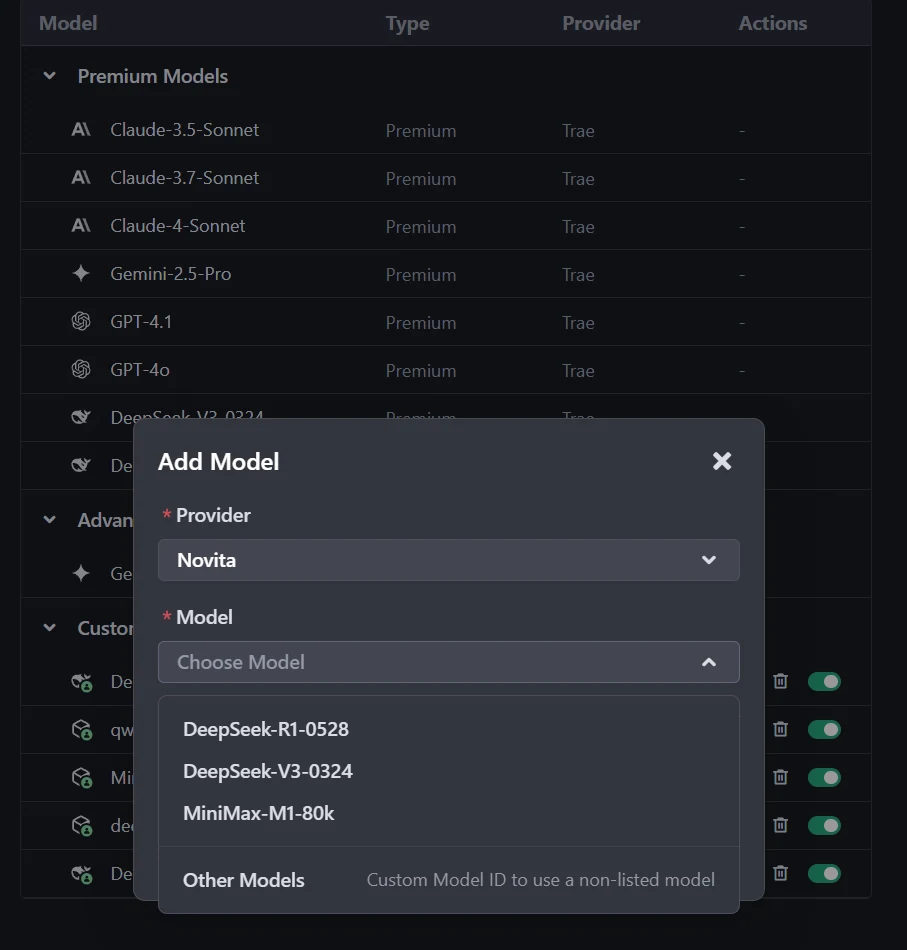
Na caixa de diálogo de adição de modelo, selecione Provedor = Novita no menu suspenso.

Passo 4: Selecione ou Insira o Modelo
No menu suspenso Modelo, selecione o modelo desejado (por exemplo, DeepSeek-R1-0528, DeepSeek-V3-0324 ou MiniMax-M1-80k). Se o modelo exato não estiver listado, basta digitar o ID do modelo que você anotou na biblioteca da Novita. Certifique-se de escolher a variante correta do modelo que deseja usar.
Passo 5: Insira sua Chave de API
Copie a chave de API da Novita AI no seu console da Novita e cole-a no campo Chave de API do Trae.
Passo 6: Salve a Configuração
Clique em Adicionar Modelo para salvar. O Trae validará a chave de API e a seleção do modelo em segundo plano.
Minimax M2.1 no Codex
Passo 1: Pré-requisitos
- Crie uma conta: Visite o site da Novita AI e cadastre-se.
- Gere sua Chave de API: Após fazer login, acesse a página de Gerenciamento de Chaves para gerar sua chave de API.
- Selecione um Nome de Modelo: Você precisará copiar o nome do modelo que deseja usar da Biblioteca de Modelos da Novita AI. Alguns modelos disponíveis incluem:
deepseek/deepseek-v3.1qwen/qwen3-coder-480b-a35b-instructmoonshotai/kimi-k2-0905openai/gpt-oss-120bzai-org/glm-4.5google/gemma-3-12b-it
- Salve-a com Segurança: você precisará dela para a configuração.
Passo 2: Instalação
# Instale via npm (Recomendado)
npm install -g @openai/codex
# Instale via Homebrew (macOS)
brew install codex
# Verifique a Instalação
codex --version
Passo 3: Configurando Modelos da Novita AI
Configurar o Arquivo de Configuração
O Codex CLI usa um arquivo de configuração TOML localizado em:
- macOS/Linux:
~/.codex/config.toml - Windows:
%USERPROFILE%\.codex\config.toml
Modelo de Configuração Básica
model = "MODEL_NAME"
model_provider = "novitaai"
[model_providers.novitaai]
name = "Novita AI"
base_url = "https://api.novita.ai/openai"
http_headers = {"Authorization" = "Bearer YOUR_NOVITA_API_KEY"}
wire_api = "chat"
5. Minimax M2.1 em Plataformas de Terceiros
- API Compatível com OpenAI: Aproveite uma migração e integração sem complicações com ferramentas como Cline, OpenCode e Cursor, projetadas para o padrão de API do OpenAI.
- Hugging Face: Use modelos nos Spaces, pipelines ou com a biblioteca Transformers por meio de endpoints da Novita AI.
- Frameworks de Agente e Orquestração: Conecte facilmente a Novita AI com plataformas parceiras como Continue, AnythingLLM,LangChain, Dify e Langflow por meio de conectores oficiais e guias de integração passo a passo.
O VIBE reformula a avaliação com base em software executável, e o Minimax M2.1 prova que a inteligência de aplicativos full-stack pode ser tanto de nível de execução quanto acessível. Com forte desempenho entre plataformas e caminhos de implantação flexíveis, o Minimax M2.1 permite que as equipes passem da codificação assistida por IA para a produção de software orientada a agentes e economicamente escalável.
Perguntas Frequentes
O que o VIBE mede para o Minimax M2.1?
O VIBE executa aplicativos gerados pelo Minimax M2.1 em runtimes reais, validando tanto o comportamento funcional quanto a saída visual nas plataformas Web, Simulação, Android, iOS e Backend.
Como o Minimax M2.1 se compara com o Claude Sonnet 4.5 e o Claude Opus 4.5?
O Minimax M2.1 obtém pontuações VIBE competitivas em relação ao Claude Sonnet 4.5 e ao Claude Opus 4.5, operando a um custo significativamente menor.
Como os desenvolvedores podem acessar o Minimax M2.1 via API?
Os desenvolvedores podem obter uma chave e chamar o Minimax M2.1 por meio da Novita AI usando um endpoint compatível com o OpenAI
A Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma forma fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construção e escalonamento.
Leitura Recomendada



