

Los desarrolladores se enfrentan hoy a dos problemas centrales: benchmarks que no reflejan la entrega real de aplicaciones y modelos de frontera cuyos costos hacen impracticable su uso a gran escala. Este artículo aborda ambos presentando VIBE, un benchmark a nivel de ejecución creado por Minimax, y mostrando cómo Minimax M2.1 ofrece capacidades full-stack casi de frontera a un precio drásticamente menor. Explica qué mide VIBE, cómo se desempeña Minimax M2.1 y cómo los desarrolladores pueden acceder e implementarlo en flujos de trabajo Web, API, local y basados en agentes.
Evaluación comparativa de la inteligencia de aplicaciones full-stack de Minimax M2.1
Minimax presenta VIBE, un benchmark diseñado específicamente para medir la capacidad de un modelo de construir aplicaciones completas y ejecutables desde cero. A diferencia de los benchmarks de codificación tradicionales que evalúan fragmentos aislados, VIBE ejecuta el proyecto generado en entornos de ejecución reales y verifica tanto la corrección funcional como el comportamiento visual.
| Benchmark | MiniMax-M2.1 | MiniMax-M2 | Claude Sonnet 4.5 | Claude Opus 4.5 | Gemini 3 Pro |
|---|---|---|---|---|---|
| VIBE (Promedio) | 88.6 | 67.5 | 85.2 | 90.7 | 82.4 |
| VIBE-Web | 91.5 | 80.4 | 87.3 | 89.1 | 89.5 |
| VIBE-Simulación | 87.1 | 77.0 | 79.1 | 84.0 | 89.2 |
| VIBE-Android | 89.7 | 69.2 | 87.5 | 92.2 | 78.7 |
| VIBE-iOS | 88.0 | 39.5 | 81.2 | 90.0 | 75.8 |
| VIBE-Backend | 86.7 | 67.8 | 90.8 | 98.0 | 78.7 |
Lo que hace esto aún más convincente es el costo. M2.1 ofrece capacidades full-stack casi de frontera a un precio significativamente más bajo que modelos comparables. En la práctica, esto cambia la forma en que los equipos pueden usar los LLM.

¿Cómo acceder a Minimax M2.1?
1. Interfaz web de Minimax M2.1
2. Acceso a la API de Minimax M2.1 para desarrolladores
Paso 1: Inicia sesión y accede a la biblioteca de modelos
Inicia sesión en tu cuenta y haz clic en el botón Biblioteca de modelos.

Paso 2: Elige tu modelo
Navega por las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.

Paso 3: Comienza tu prueba gratuita
Inicia tu prueba gratuita para explorar las capacidades del modelo seleccionado.
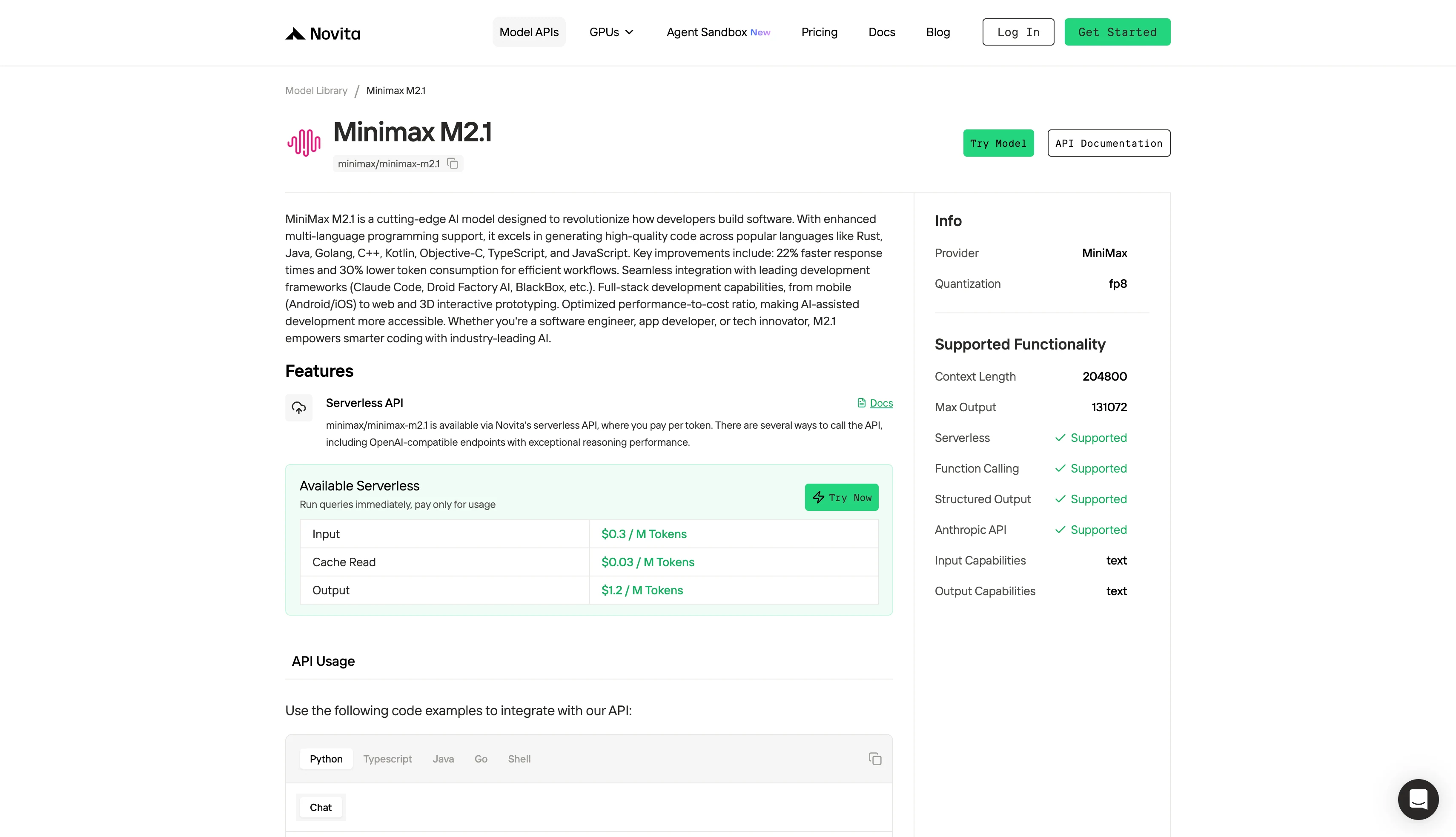
Paso 4: Obtén tu clave API
Para autenticarte con la API, te proporcionaremos una nueva clave API. Ingresa a la página de “Configuración” y copia la clave API como se indica en la imagen.

Paso 5: Instala la API
Instala la API usando el gestor de paquetes específico de tu lenguaje de programación.
Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave API para comenzar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de chat completions para usuarios de Python.
from openai import OpenAI
client = OpenAI(
api_key="<Tu Clave API>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.1",
messages=[
{"role": "system", "content": "Eres un asistente útil."},
{"role": "user", "content": "Hola, ¿cómo estás?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
3. Implementación local de Minimax M2.1 y endpoints dedicados
Requisitos:
| Configuración | Contexto máximo | Caso de uso |
|---|---|---|
| 4× A100 o A800 (80 GB) | 400K tokens | Implementaciones estándar |
| 4× H200 o H20 (96 GB+) | 400K tokens | Implementaciones estándar |
| 8× H200 (141 GB) | 3M tokens | Cargas de trabajo de contexto extendido |
Pasos de instalación:
- Descarga los pesos del modelo desde HuggingFace o ModelScope
- Elige el framework de inferencia: compatible con vLLM o SGLang
- Sigue la guía de implementación en el repositorio oficial de GitHub
Elegirías un endpoint dedicado cuando necesites inferencia estable de alto rendimiento, control personalizado del modelo y menor costo bajo cargas de trabajo continuas o pesadas, en lugar de mantener GPUs e infraestructura local.
¡Prueba el Endpoint Dedicado ahora!
4. Integración de Minimax M2.1 con herramientas de agente de código
Minimax M2.1 está diseñado para servir como un backbone estable para flujos de trabajo de Code Agent, integrándose fluidamente con Claude Code, Droid (Factory AI), Cline, Kilo Code y Roo Code, mientras admite sistemas de contexto estructurados como Skill.md, Claude.md, agent.md, cursorrule y Slash Commands. Se mantiene coherente bajo planificación a largo plazo y ejecución iterativa, permitiendo tareas como andamiaje multiarchivo, bucles de refactorización y depuración autónoma.
A través de Novita AI, los desarrolladores pueden evitar restricciones regionales e implementar M2.1 directamente en pipelines existentes con una estabilidad respaldada por SLA del 99%, lo que lo hace adecuado para generación de código de alta frecuencia y automatización de CI. El mismo stack también ofrece Kimi-K2 y Qwen3 Coder, brindando un rendimiento de codificación cercano a Claude Sonnet 4 a menos de una quinta parte del costo, permitiendo a los equipos escalar el desarrollo impulsado por agentes de manera económica.
Primero: Obtén la clave API
Minimax M2.1 en Cursor
Paso 1: Instala Cursor
Descarga la versión más reciente desde cursor.com, suscríbete al plan Pro y completa la configuración inicial.
Paso 2: Accede a la configuración de modelos avanzados
En Cursor, abre Configuración, selecciona Modelos en el menú izquierdo y localiza Configuración de API.
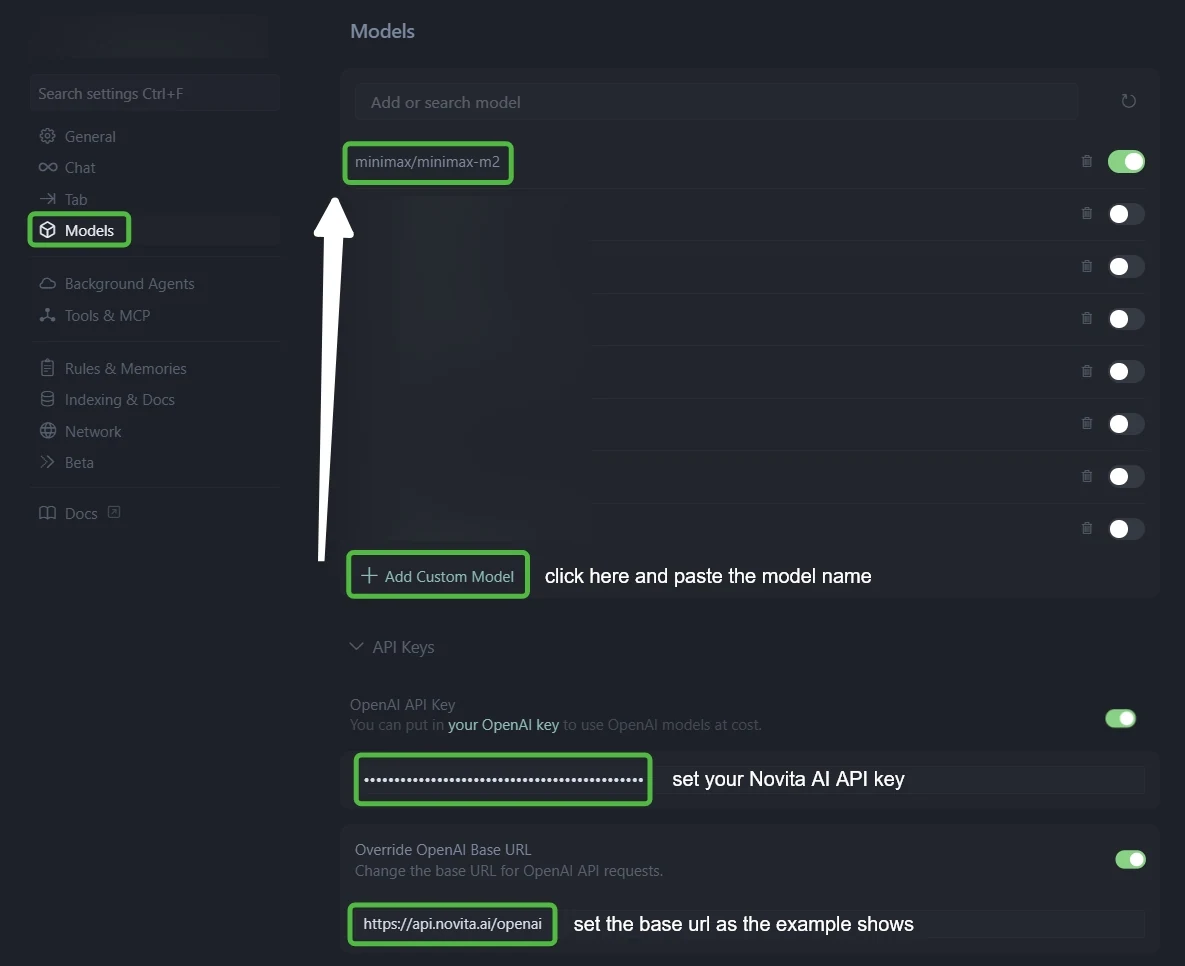
Paso 3: Configura la integración con Novita AI
- En el campo “OpenAI API Key”: pega tu clave API de Novita AI
- En el campo “Override OpenAI Base URL”: reemplaza el valor predeterminado por:
https://api.novita.ai/openai
Paso 4: Añade múltiples modelos de codificación AI
Haz clic en “+ Add Custom Model” y añade cada modelo:
- minimax/minimax m2.1
qwen/qwen3-vl-235b-a22b-thinkingzai-org/glm-4.6deepseek/deepseek-v3.1moonshotai/kimi-k2-0905openai/gpt-oss-120bgoogle/gemma-3-12b-it
Paso 5: Prueba tu integración
Inicia un nuevo chat en modo Ask o Agent, cambia entre modelos y confirma que cada uno responda correctamente.
Minimax M2.1 en Claude Code
Paso 1: Instala Claude Code
Primero, verifica que Node.js 18 o superior esté instalado en tu sistema:
node -v
# Salida esperada: v18.x.x o superior (ej. v20.10.0)
Si Node.js falta o es anterior a v18, descarga e instala una versión reciente desde [https://nodejs.org](https://nodejs.org)
- Comando de instalación:
Instala Claude Code globalmente usando npm:
npm install -g @anthropic-ai/claude-code
- Verifica la instalación:
claude --version
Paso 2: Configuración de variables de entorno
En Windows: Establece las variables para la sesión CMD actual:
set ANTHROPIC_BASE_URL=https://api.novita.ai/anthropic
set ANTHROPIC_AUTH_TOKEN=<Tu_Clave_API_Novita>
set ANTHROPIC_MODEL=minimax/minimax-m2.1
set ANTHROPIC_SMALL_FAST_MODEL=minimax/minimax-m2.1
En macOS y Linux: Exporta las variables en tu shell:
export ANTHROPIC_BASE_URL="https://api.novita.ai/anthropic"
export ANTHROPIC_AUTH_TOKEN="<Tu_Clave_API_Novita>"
export ANTHROPIC_MODEL="minimax/minimax-m2.1"
export ANTHROPIC_SMALL_FAST_MODEL="minimax/minimax-m2.1"
Paso 3: Iniciar Claude Code
- Navega a tu directorio de proyecto
cd <ruta_a_tu_proyecto>
- Lanza Claude Code
claude .
El punto (.) le indica a Claude Code que opere en el directorio actual, escaneando y trabajando dentro de este proyecto.
Después del inicio, verás un prompt interactivo de Claude Code con acceso a comandos como /init, /model, /review y más.
Los comandos comunes a nivel de sesión incluyen:
/init– Inicializa Claude Code en el directorio actual./login– Autentica con un proveedor de API si es necesario./logout– Limpia las credenciales almacenadas./memory– Ver o editar la memoria persistente./model– Ver o cambiar el modelo actual./permissions– Gestionar permisos de archivos y comandos./review– Revisar cambios pendientes antes de aplicarlos./status– Mostrar el estado actual de la sesión./terminal-setup– Configurar la integración de terminal./vim– Alternar las combinaciones de teclas de Vim.
Minimax M2.1 en Trae
Paso 1: Abre Trae y accede a los modelos
Inicia la aplicación Trae. Haz clic en el Toggle AI Side Bar en la esquina superior derecha para abrir la barra lateral de IA. Luego, ve a AI Management y selecciona Models.

Paso 2: Añade un modelo personalizado
Haz clic en el botón Add Model para crear una entrada de modelo personalizado.

Paso 3: Elige Novita como proveedor
En el diálogo de añadir modelo, selecciona Provider = Novita en el menú desplegable.

Paso 4: Selecciona o ingresa el modelo
En el menú desplegable Model, elige el modelo deseado (por ejemplo, DeepSeek-R1-0528, DeepSeek-V3-0324 o MiniMax-M1-80k). Si el modelo exacto no está listado, simplemente escribe el ID del modelo que anotaste de la biblioteca de Novita. Asegúrate de elegir la variante correcta del modelo que deseas usar.
Paso 5: Ingresa tu clave API
Copia la clave API de Novita AI desde tu consola de Novita y pégala en el campo API Key en Trae.
Paso 6: Guarda la configuración
Haz clic en Add Model para guardar. Trae validará la clave API y la selección del modelo en segundo plano.
Minimax M2.1 en Codex
Paso 1: Requisitos previos
- Crea una cuenta: Visita el sitio web de Novita AI y regístrate para crear una cuenta.
- Genera tu clave API: Después de iniciar sesión, navega a la página de Key Management para generar tu clave API.
- Selecciona un nombre de modelo: Necesitarás copiar el nombre del modelo que deseas usar desde la Model Library de Novita AI. Algunos modelos disponibles incluyen:
deepseek/deepseek-v3.1qwen/qwen3-coder-480b-a35b-instructmoonshotai/kimi-k2-0905openai/gpt-oss-120bzai-org/glm-4.5google/gemma-3-12b-it
- Guárdalo de forma segura: lo necesitarás para la configuración.
Paso 2: Instalación
#Instalar vía npm (Recomendado)
npm install -g @openai/codex
#Instalar vía Homebrew (macOS)
brew install codex
#Verificar instalación
codex --version
Paso 3: Configuración de modelos de Novita AI
Configuración del archivo de configuración
Codex CLI usa un archivo de configuración TOML ubicado en:
- macOS/Linux:
~/.codex/config.toml - Windows:
%USERPROFILE%\.codex\config.toml
Plantilla de configuración básica
model = "MODEL_NAME"
model_provider = "novitaai"
[model_providers.novitaai]
name = "Novita AI"
base_url = "https://api.novita.ai/openai"
http_headers = {"Authorization" = "Bearer TU_CLAVE_API_NOVITA"}
wire_api = "chat"
5. Minimax M2.1 en plataformas de terceros
- API compatible con OpenAI: Disfruta de una migración e integración sin problemas con herramientas como Cline, OpenCode y Cursor, diseñadas para el estándar de API de OpenAI.
- Hugging Face: Usa modelos en Spaces, pipelines o con la biblioteca Transformers a través de los endpoints de Novita AI.
- Frameworks de agentes y orquestación: Conecta fácilmente Novita AI con plataformas asociadas como Continue, AnythingLLM,LangChain, Dify y Langflow a través de conectores oficiales y guías de integración paso a paso.
VIBE redefine la evaluación en torno al software ejecutable, y Minimax M2.1 demuestra que la inteligencia de aplicaciones full-stack puede ser tanto de grado de ejecución como asequible. Con un sólido rendimiento multiplataforma y rutas de implementación flexibles, Minimax M2.1 permite a los equipos pasar de la codificación asistida por IA a la producción de software impulsada por agentes, escalable y económicamente viable.
Preguntas frecuentes
¿Qué mide VIBE para Minimax M2.1?
VIBE ejecuta aplicaciones generadas por Minimax M2.1 en entornos de ejecución reales, validando tanto el comportamiento funcional como la salida visual en Web, Simulación, Android, iOS y Backend.
¿Cómo se compara Minimax M2.1 con Claude Sonnet 4.5 y Claude Opus 4.5?
Minimax M2.1 alcanza puntuaciones VIBE competitivas frente a Claude Sonnet 4.5 y Claude Opus 4.5 mientras opera a un costo significativamente menor.
¿Cómo pueden los desarrolladores acceder a Minimax M2.1 a través de la API?
Los desarrolladores pueden obtener una clave y llamar a Minimax M2.1 a través de Novita AI usando un endpoint compatible con OpenAI.
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA usando nuestra API simple, al tiempo que proporciona una GPU en la nube asequible y confiable para construir y escalar.
Lectura recomendada



