

Entwickler stehen heute vor zwei zentralen Problemen: Benchmarks, die die tatsächliche Anwendungsbereitstellung nicht widerspiegeln, sowie Spitzenmodelle, deren Kosten eine großflächige Nutzung unpraktisch machen. Dieser Artikel adressiert beide Punkte, indem er VIBE vorstellt, einen von Minimax entwickelten Laufzeit-Benchmark, und zeigt, wie Minimax M2.1 nahezu spitzenmäßige Full-Stack-Fähigkeiten zu deutlich niedrigeren Kosten bietet. Es wird erläutert, was VIBE misst, wie Minimax M2.1 abschneidet und wie Entwickler es über Web, API, lokal und agentenbasierte Workflows zugreifen und bereitstellen können.
Benchmark der Full-Stack-Anwendungsintelligenz von Minimax M2.1
Minimax stellt VIBE vor, einen speziell entwickelten Benchmark, der die Fähigkeit eines Modells misst, vollständige, ausführbare Anwendungen von Grund auf zu erstellen. Im Gegensatz zu herkömmlichen Code-Benchmarks, die isolierte Code-Snippets bewerten, führt VIBE das generierte Projekt in echten Laufzeitumgebungen aus und überprüft sowohl die funktionale Korrektheit als auch das visuelle Verhalten.
| Benchmark | MiniMax-M2.1 | MiniMax-M2 | Claude Sonnet 4.5 | Claude Opus 4.5 | Gemini 3 Pro |
|---|---|---|---|---|---|
| VIBE (Average) | 88.6 | 67.5 | 85.2 | 90.7 | 82.4 |
| VIBE-Web | 91.5 | 80.4 | 87.3 | 89.1 | 89.5 |
| VIBE-Simulation | 87.1 | 77.0 | 79.1 | 84.0 | 89.2 |
| VIBE-Android | 89.7 | 69.2 | 87.5 | 92.2 | 78.7 |
| VIBE-iOS | 88.0 | 39.5 | 81.2 | 90.0 | 75.8 |
| VIBE-Backend | 86.7 | 67.8 | 90.8 | 98.0 | 78.7 |
Was dies noch überzeugender macht, ist der Preis. M2.1 bietet nahezu spitzenmäßige Full-Stack-Fähigkeiten zu einem deutlich niedrigeren Preis als vergleichbare Modelle. In der Praxis verändert dies, wie Teams LLMs nutzen können.

So greifen Sie auf Minimax M2.1 zu?
1. Minimax M2.1 Web-Oberfläche
Probieren Sie Minimax M2.1 jetzt aus!
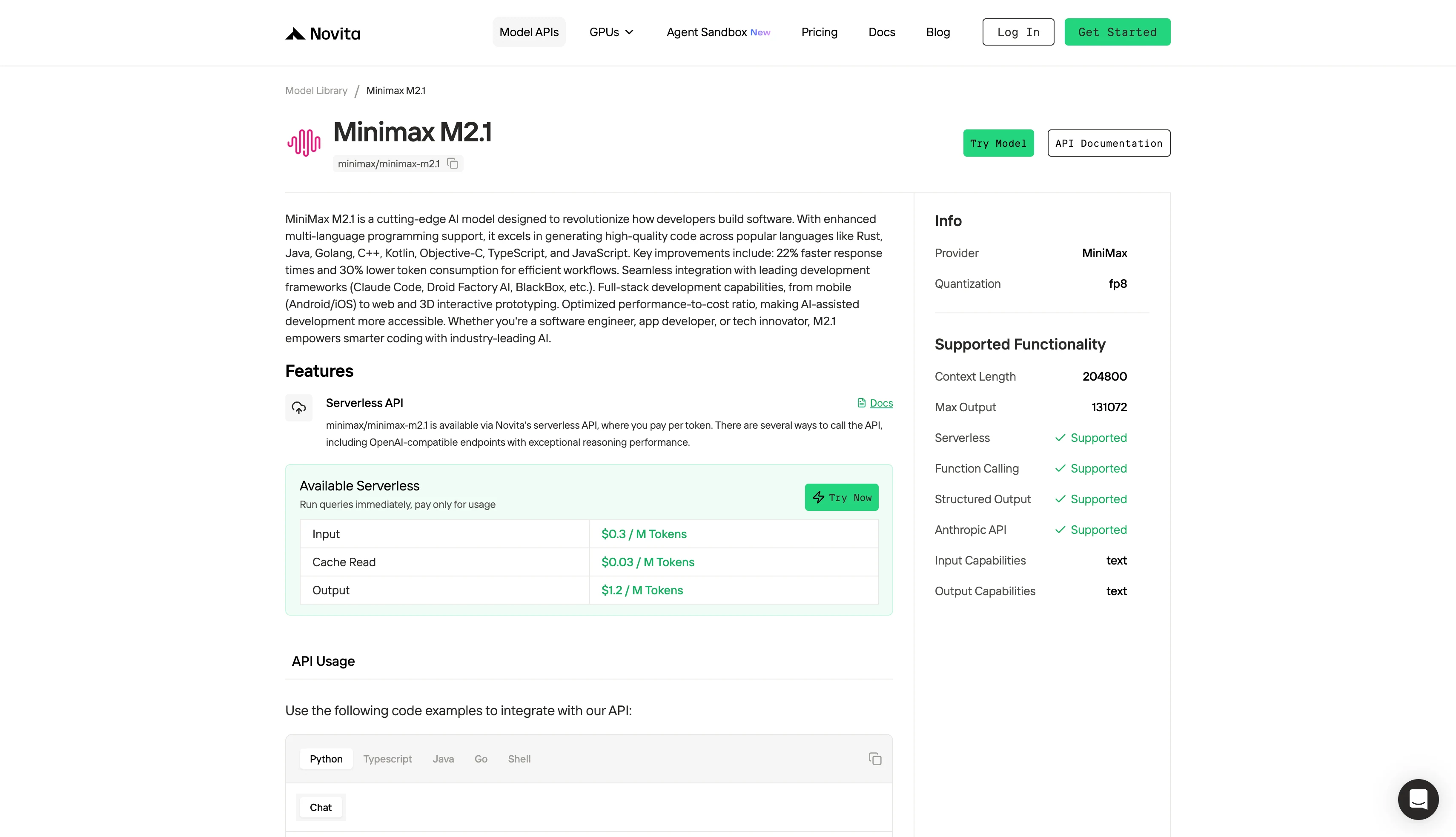
2. API-Zugriff auf Minimax M2.1 für Entwickler
Schritt 1: Melden Sie sich an und greifen Sie auf die Modellbibliothek zu
Loggen Sie sich in Ihr Konto ein und klicken Sie auf die Schaltfläche Modellbibliothek.

Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell, das Ihren Anforderungen entspricht.

Schritt 3: Starten Sie Ihre kostenlose Testversion
Starten Sie Ihre kostenlose Testversion, um die Funktionen des ausgewählten Modells kennenzulernen.
Probieren Sie Minimax M2.1 jetzt aus!
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung über die API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Auf der Seite „Einstellungen“ können Sie den API-Schlüssel wie in der Abbildung gezeigt kopieren.

Schritt 5: Installieren Sie die API
Installieren Sie die API über den für Ihre Programmiersprache spezifischen Paketmanager.
Importieren Sie nach der Installation die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit dem Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Nutzung der Chat-Completions-API für Python-Nutzer.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.1",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
3. Lokale Bereitstellung von Minimax M2.1 und dedizierte Endpunkte
Anforderungen:
| Konfiguration | Maximale Kontextlänge | Anwendungsfall |
|---|---|---|
| 4× A100 oder A800 (80 GB) | 400K Token | Standardbereitstellungen |
| 4× H200 oder H20 (96 GB+) | 400K Token | Standardbereitstellungen |
| 8× H200 (141 GB) | 3M Token | Arbeitslasten mit erweitertem Kontext |
Installationsschritte:
- Laden Sie die Modellgewichte von HuggingFace oder ModelScope herunter
- Wählen Sie das Inferenz-Framework: vLLM oder SGLang werden unterstützt
- Befolgen Sie den Bereitstellungsleitfaden im offiziellen GitHub-Repository
Sie wählen einen dedizierten Endpunkt, wenn Sie stabile leistungsstarke Inferenz, benutzerdefinierte Modellsteuerung und niedrigere Kosten bei kontinuierlichen oder schweren Arbeitslasten benötigen, anstatt lokale GPUs und Infrastruktur zu warten.
Probieren Sie jetzt den dedizierten Endpunkt aus!
4. Integration von Minimax M2.1 in Code-Agent-Tools
Minimax M2.1 wurde als stabile Grundlage für Code-Agent-Workflows entwickelt, integriert sich reibungslos mit Claude Code, Droid (Factory AI), Cline, Kilo Code und Roo Code und unterstützt strukturierte Kontextsysteme wie Skill.md, Claude.md, agent.md, cursorrule und Slash-Befehle. Es bleibt auch bei langfristiger Planung und iterativer Ausführung konsistent und ermöglicht Aufgaben wie Multi-Datei-Scaffolding, Refaktorierungsschleifen und autonomes Debugging.
Über Novita AI können Entwickler regionale Einschränkungen umgehen und M2.1 direkt in bestehenden Pipelines mit einer von SLA gestützten Stabilität von 99 % bereitstellen, was es für hochfrequente Codegenerierung und CI-Automatisierung geeignet macht. Der gleiche Stack bietet zudem Kimi-K2 und Qwen3 Coder, die eine nahezu mit Claude Sonnet 4 vergleichbare Codeleistung zu weniger als einem Fünftel der Kosten liefern, sodass Teams agentengesteuerte Entwicklung wirtschaftlich skalieren können.
Zuerst: Holen Sie sich Ihren API-Schlüssel
Holen Sie sich jetzt Ihren API-Schlüssel!
Minimax M2.1 in Cursor
Schritt 1: Installieren Sie Cursor
Laden Sie die neueste Version von cursor.com herunter, abonnieren Sie den Pro-Plan und schließen Sie die Ersteinrichtung ab.
Schritt 2: Greifen Sie auf die erweiterten Modelleinstellungen zu
Öffnen Sie in Cursor Einstellungen, wählen Sie Modelle im linken Menü und suchen Sie API-Konfiguration.
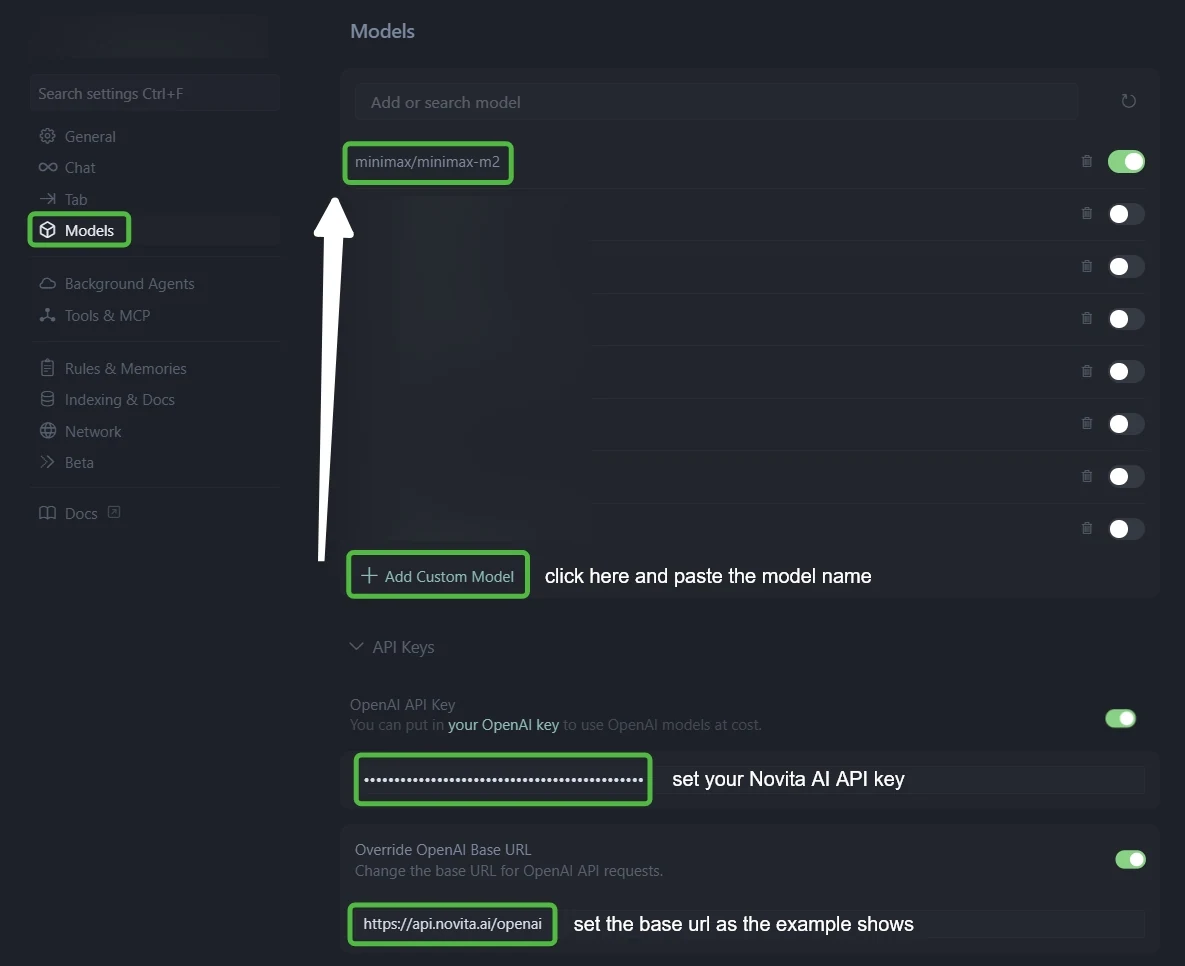
Schritt 3: Konfigurieren Sie die Novita AI-Integration
- Im Feld „OpenAI API-Schlüssel“: Fügen Sie Ihren Novita AI API-Schlüssel ein
- Im Feld „OpenAI-Basis-URL überschreiben“: Ersetzen Sie die Standard-URL durch:
https://api.novita.ai/openai
Holen Sie sich einen API-Schlüssel
Schritt 4: Fügen Sie mehrere KI-Coding-Modelle hinzu
Klicken Sie auf „+ Benutzerdefiniertes Modell hinzufügen“ und fügen Sie jedes Modell hinzu:
- minimax/minimax m2.1
qwen/qwen3-vl-235b-a22b-thinkingzai-org/glm-4.6deepseek/deepseek-v3.1moonshotai/kimi-k2-0905openai/gpt-oss-120bgoogle/gemma-3-12b-it
Schritt 5: Testen Sie Ihre Integration
Starten Sie einen neuen Chat im Ask- oder Agent-Modus, wechseln Sie zwischen den Modellen und bestätigen Sie, dass jedes korrekt antwortet.
Minimax M2.1 in Claude Code
Schritt 1: Installieren Sie Claude Code
Überprüfen Sie zuerst, ob Node.js 18 oder höher auf Ihrem System installiert ist:
node -v
# Erwartete Ausgabe: v18.x.x oder höher (z. B. v20.10.0)
Wenn Node.js fehlt oder älter als v18 ist, laden Sie eine aktuelle Version von [https://nodejs.org](https://nodejs.org) herunter und installieren Sie sie.
- Installationsbefehl:
Installieren Sie Claude Code global über npm:
npm install -g @anthropic-ai/claude-code
- Überprüfen Sie die Installation:
claude --version
Schritt 2: Einrichten von Umgebungsvariablen
Unter Windows:Legen Sie die Variablen für die aktuelle CMD-Sitzung fest:
set ANTHROPIC_BASE_URL=https://api.novita.ai/anthropic
set ANTHROPIC_AUTH_TOKEN=<Your_Novita_API_Key>
set ANTHROPIC_MODEL=minimax/minimax-m2.1
set ANTHROPIC_SMALL_FAST_MODEL=minimax/minimax-m2.1
Unter macOS und Linux:Exportieren Sie die Variablen in Ihrer Shell:
export ANTHROPIC_BASE_URL="https://api.novita.ai/anthropic"
export ANTHROPIC_AUTH_TOKEN="<Your_Novita_API_Key>"
export ANTHROPIC_MODEL="minimax/minimax-m2.1"
export ANTHROPIC_SMALL_FAST_MODEL="minimax/minimax-m2.1"
Holen Sie sich einen API-Schlüssel
Schritt 3: Starten von Claude Code
- Navigieren Sie zu Ihrem Projektverzeichnis
cd <path_to_your_project>
- Starten Sie Claude Code
claude .
Der Punkt (.) weist Claude Code an, im aktuellen Verzeichnis zu arbeiten, dieses Projekt zu scannen und darin zu arbeiten.
Nach dem Start sehen Sie eine interaktive Claude Code-Eingabeaufforderung mit Zugriff auf Befehle wie /init, /model, /review und mehr.
Häufige Befehle auf Sitzungsebene sind:
/init– Initialisiert Claude Code im aktuellen Verzeichnis./login– Authentifiziert sich bei einem API-Anbieter, falls erforderlich./logout– Löscht gespeicherte Anmeldedaten./memory– Zeigt persistenten Speicher an oder bearbeitet ihn./model– Zeigt das aktuelle Modell an oder wechselt es./permissions– Verwaltet Datei- und Befehlsberechtigungen./review– Überprüft ausstehende Änderungen vor der Anwendung./status– Zeigt den aktuellen Sitzungsstatus an./terminal-setup– Konfiguriert die Terminal-Integration./vim– Schaltet Vim-Tastenkürzel um.
Minimax M2.1 in Codex
Schritt1:Voraussetzungen
- Konto erstellen: Besuchen Sie Novita AI’s website und registrieren Sie sich für ein Konto.
- Generieren Sie Ihren API-Schlüssel: Nach der Anmeldung navigieren Sie zur Seite Key Management, um Ihren API-Schlüssel zu generieren.
- Wählen Sie einen Modellnamen: Sie müssen den Modellnamen, den Sie verwenden möchten, aus Novita AIs Modellbibliothek kopieren. Einige verfügbare Modelle sind:
deepseek/deepseek-v3.1qwen/qwen3-coder-480b-a35b-instructmoonshotai/kimi-k2-0905openai/gpt-oss-120bzai-org/glm-4.5google/gemma-3-12b-it
- Sichern Sie es sicher ab: Sie benötigen es für die Konfiguration.
Schritt2:Installation
#Installation über npm (Empfohlen)
npm install -g @openai/codex
#Installation über Homebrew (macOS)
brew install codex
#Überprüfen der Installation
codex --version
Schritt3:Konfiguration von Novita AI-Modellen
Einrichtung der Konfigurationsdatei
Codex CLI verwendet eine TOML-Konfigurationsdatei, die sich unter folgenden Pfaden befindet:
- macOS/Linux:
~/.codex/config.toml - Windows:
%USERPROFILE%\.codex\config.toml
Grundlegende Konfigurationsvorlage
model = "MODEL_NAME"
model_provider = "novitaai"
[model_providers.novitaai]
name = "Novita AI"
base_url = "https://api.novita.ai/openai"
http_headers = {"Authorization" = "Bearer YOUR_NOVITA_API_KEY"}
wire_api = "chat"
Holen Sie sich einen API-Schlüssel
5. Minimax M2.1 auf Drittanbieterplattformen
- OpenAI-kompatible API: Genießen Sie problemlose Migration und Integration mit Tools wie Cline, OpenCode und Cursor, die für den OpenAI-API-Standard entwickelt wurden.
- Hugging Face: Nutzen Sie Modelle in Spaces, Pipelines oder mit der Transformers-Bibliothek über Novita AI-Endpunkte.
- Agenten- und Orchestrierungs-Frameworks: Verbinden Sie Novita AI einfach mit Partnerplattformen wie Continue, AnythingLLM,LangChain, Dify und Langflow über offizielle Connectors und Schritt-für-Schritt-Integrationsleitfäden.
VIBE stellt die Bewertung auf lauffähige Software um, und Minimax M2.1 beweist, dass Full-Stack-Anwendungsintelligenz sowohl ausführungsreif als auch erschwinglich sein kann. Mit starker plattformübergreifender Leistung und flexiblen Bereitstellungspfaden ermöglicht Minimax M2.1 Teams, von KI-gestütztem Coding zu wirtschaftlich skalierbarer, agentengesteuerter Softwareproduktion überzugehen.
Häufig gestellte Fragen
Was misst VIBE für Minimax M2.1?
VIBE führt von Minimax M2.1 generierte Apps in echten Laufzeitumgebungen aus und validiert sowohl das funktionale Verhalten als auch die visuelle Ausgabe über Web, Simulation, Android, iOS und Backend.
Wie schneidet Minimax M2.1 im Vergleich zu Claude Sonnet 4.5 und Claude Opus 4.5 ab?
Minimax M2.1 erzielt wettbewerbsfähige VIBE-Punktzahlen im Vergleich zu Claude Sonnet 4.5 und Claude Opus 4.5, und das bei deutlich niedrigeren Kosten.
Wie können Entwickler über die API auf Minimax M2.1 zugreifen?
Entwickler können einen Schlüssel erhalten und Minimax M2.1 über Novita AI unter Verwendung eines OpenAI-kompatiblen Endpunkts aufrufen.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Erstellen und Skalieren bereitstellt.
Empfohlene Lektüre



