

Les développeurs sont aujourd’hui confrontés à deux problèmes majeurs : des benchmarks qui ne reflètent pas la livraison réelle d’applications, et des modèles de pointe dont les coûts rendent l’utilisation à grande échelle peu pratique. Cet article répond à ces deux problématiques en présentant VIBE, un benchmark au niveau de l’exécution créé par Minimax, et en montrant comment Minimax M2.1 offre des capacités full-stack quasi équivalentes à celles des modèles de pointe à un prix nettement inférieur. Il explique ce que mesure VIBE, les performances de Minimax M2.1, et comment les développeurs peuvent y accéder et le déployer dans des workflows Web, API, locaux et basés sur des agents.
Évaluation de l’intelligence full-stack applicative de Minimax M2.1
Minimax présente VIBE, un benchmark spécialement conçu pour mesurer la capacité d’un modèle à construire des applications complètes et exécutables de A à Z. Contrairement aux benchmarks de codage traditionnels qui évaluent des extraits de code isolés, VIBE exécute le projet généré dans des environnements d’exécution réels et vérifie à la fois l’exactitude fonctionnelle et le comportement visuel.
| Benchmark | MiniMax-M2.1 | MiniMax-M2 | Claude Sonnet 4.5 | Claude Opus 4.5 | Gemini 3 Pro |
|---|---|---|---|---|---|
| VIBE (Average) | 88.6 | 67.5 | 85.2 | 90.7 | 82.4 |
| VIBE-Web | 91.5 | 80.4 | 87.3 | 89.1 | 89.5 |
| VIBE-Simulation | 87.1 | 77.0 | 79.1 | 84.0 | 89.2 |
| VIBE-Android | 89.7 | 69.2 | 87.5 | 92.2 | 78.7 |
| VIBE-iOS | 88.0 | 39.5 | 81.2 | 90.0 | 75.8 |
| VIBE-Backend | 86.7 | 67.8 | 90.8 | 98.0 | 78.7 |
Ce qui rend cela encore plus convaincant, c’est le coût. M2.1 offre des capacités full-stack quasi équivalentes à celles des modèles de pointe à un prix nettement inférieur à celui des modèles comparables. Dans la pratique, cela change la façon dont les équipes peuvent utiliser les LLM.

Comment accéder à Minimax M2.1 ?
1. Interface Web de Minimax M2.1
Essayez Minimax M2.1 dès maintenant !
2. Accès API de Minimax M2.1 pour les développeurs
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.

Étape 3 : Démarrez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Essayez Minimax M2.1 dès maintenant !
Étape 4 : Récupérez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En accédant à la page « Paramètres », vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec le LLM de Novita AI. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="minimax/minimax-m2.1",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
3. Déploiement local de Minimax M2.1 et points de terminaison dédiés
Prérequis :
| Configuration | Contexte max | Cas d’usage |
|---|---|---|
| 4× A100 ou A800 (80 GB) | 400K tokens | Déploiements standards |
| 4× H200 ou H20 (96 GB et plus) | 400K tokens | Déploiements standards |
| 8× H200 (141 GB) | 3M tokens | Charges de travail à contexte étendu |
Étapes d’installation :
- Téléchargez les poids du modèle depuis HuggingFace ou ModelScope
- Choisissez le framework d’inférence : vLLM ou SGLang sont pris en charge
- Suivez le guide de déploiement dans le dépôt GitHub officiel
Vous opterez pour un point de terminaison dédié lorsque vous avez besoin d’une inférence stable et haute performance, d’un contrôle personnalisé du modèle, et d’un coût réduit pour des charges de travail continues ou importantes, plutôt que de maintenir des GPU et une infrastructure locaux.
Essayez le point de terminaison dédié dès maintenant !
4. Intégration de Minimax M2.1 avec les outils d’agents de code
Minimax M2.1 est conçu pour servir de colonne vertébrale stable pour les workflows d’agents de code, s’intégrant parfaitement avec Claude Code, Droid (Factory AI), Cline, Kilo Code et Roo Code, tout en prenant en charge des systèmes de contexte structurés tels que Skill.md, Claude.md, agent.md, cursorrule et les commandes slash. Il reste cohérent lors de la planification à long terme et de l’exécution itérative, permettant des tâches telles que l’échafaudage multi-fichiers, les boucles de refactorisation et le débogage autonome.
Via Novita AI, les développeurs peuvent contourner les restrictions régionales et déployer M2.1 directement dans des pipelines existants avec une stabilité de 99 % garantie par le SLA, ce qui le rend adapté à la génération de code haute fréquence et à l’automatisation CI. La même pile propose également Kimi-K2 et Qwen3 Coder, offrant des performances de codage quasi équivalentes à celles de Claude Sonnet 4 à moins d’un cinquième du coût, permettant aux équipes de mettre à l’échelle le développement piloté par des agents de manière économique.
Première étape : Récupérez votre clé API
Récupérez votre clé API dès maintenant !
Minimax M2.1 dans Cursor
Étape 1 : Installez Cursor
Téléchargez la dernière version depuis cursor.com, abonnez-vous au plan Pro et terminez la configuration initiale.
Étape 2 : Accédez aux paramètres avancés des modèles
Dans Cursor, ouvrez Paramètres, sélectionnez Modèles dans le menu de gauche, et trouvez Configuration API.
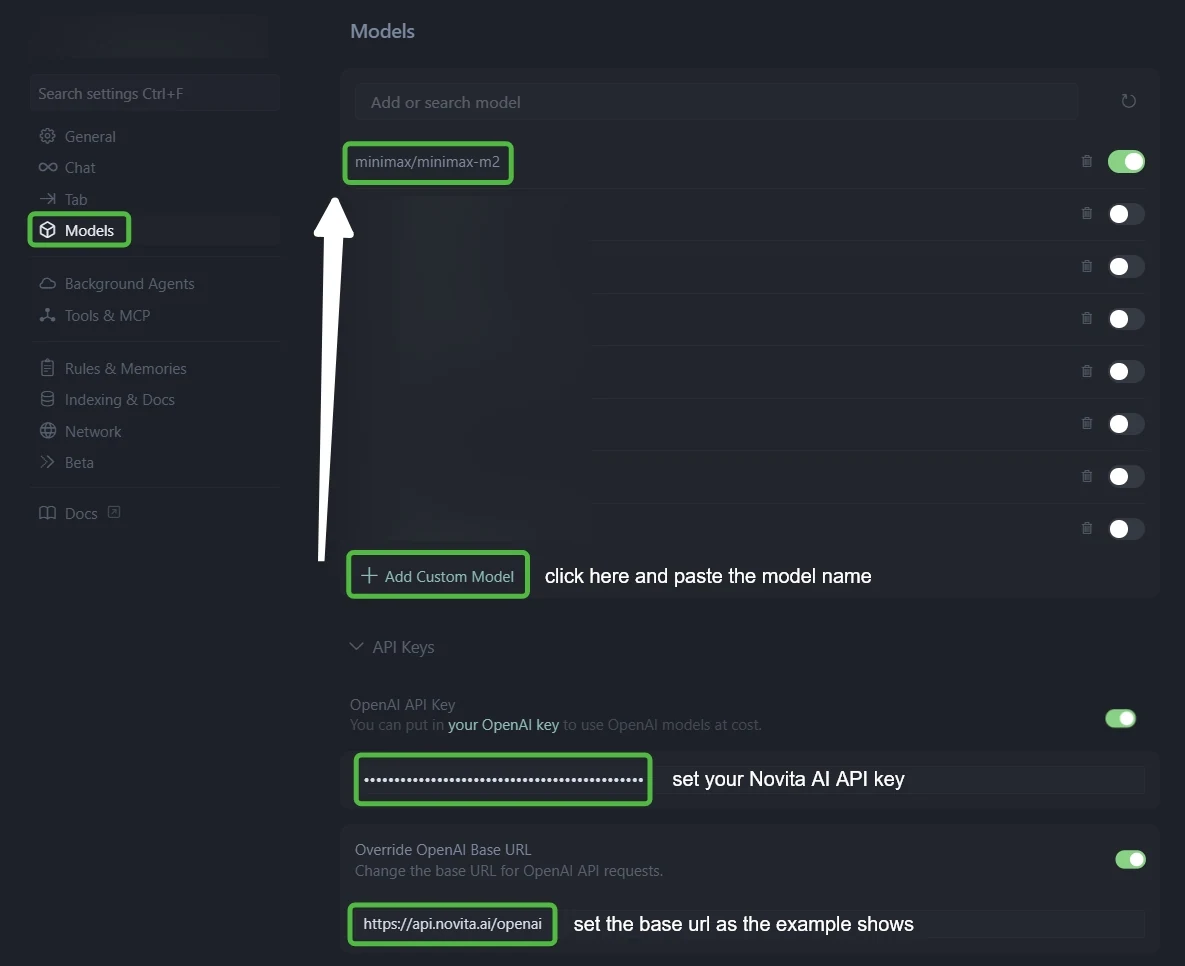
Étape 3 : Configurez l’intégration Novita AI
- Dans le champ « Clé API OpenAI » : collez votre clé API Novita AI
- Dans le champ « Remplacer l’URL de base OpenAI » : remplacez la valeur par défaut par :
https://api.novita.ai/openai
Étape 4 : Ajoutez plusieurs modèles de codage IA
Cliquez sur « + Ajouter un modèle personnalisé » et ajoutez chaque modèle :
- minimax/minimax m2.1
qwen/qwen3-vl-235b-a22b-thinkingzai-org/glm-4.6deepseek/deepseek-v3.1moonshotai/kimi-k2-0905openai/gpt-oss-120bgoogle/gemma-3-12b-it
Étape 5 : Testez votre intégration
Démarrez une nouvelle discussion en mode Demande ou Agent, basculez entre les modèles et vérifiez que chacun répond correctement.
Minimax M2.1 dans Claude Code
Étape 1 : Installez Claude Code
Tout d’abord, vérifiez que Node.js 18 ou une version supérieure est installé sur votre système :
node -v
# Expected output: v18.x.x or higher (e.g.v20.10.0)
Si Node.js est manquant ou plus ancien que v18, téléchargez et installez une version récente depuis [https://nodejs.org](https://nodejs.org)
- Commande d’installation :
Installez Claude Code globalement via npm :
npm install -g @anthropic-ai/claude-code
- Vérifiez l’installation :
claude --version
Étape 2 : Configuration des variables d’environnement
Sous Windows:Définissez les variables pour la session CMD actuelle :
set ANTHROPIC_BASE_URL=https://api.novita.ai/anthropic
set ANTHROPIC_AUTH_TOKEN=<Your_Novita_API_Key>
set ANTHROPIC_MODEL=minimax/minimax-m2.1
set ANTHROPIC_SMALL_FAST_MODEL=minimax/minimax-m2.1
Sous macOS et Linux:Exportez les variables dans votre shell :
export ANTHROPIC_BASE_URL="https://api.novita.ai/anthropic"
export ANTHROPIC_AUTH_TOKEN="<Your_Novita_API_Key>"
export ANTHROPIC_MODEL="minimax/minimax-m2.1"
export ANTHROPIC_SMALL_FAST_MODEL="minimax/minimax-m2.1"
Étape 3 : Démarrage de Claude Code
- Accédez au répertoire de votre projet
cd <path_to_your_project>
- Lancez Claude Code
claude .
Le point (.) indique à Claude Code d’opérer sur le répertoire actuel, en analysant et en travaillant dans ce projet.
Après le démarrage, vous verrez une invite interactive de Claude Code avec accès à des commandes telles que /init, /model, /review, et plus encore.
Les commandes courantes au niveau de la session incluent :
/init– Initialise Claude Code dans le répertoire actuel./login– Authentifiez-vous auprès d’un fournisseur d’API si nécessaire./logout– Effacez les identifiants stockés./memory– Affichez ou modifiez la mémoire persistante./model– Affichez ou changez le modèle actuel./permissions– Gérez les autorisations de fichiers et de commandes./review– Examinez les modifications en attente avant de les appliquer./status– Affichez l’état de la session actuelle./terminal-setup– Configurez l’intégration du terminal./vim– Activez/désactivez les raccourcis clavier Vim.
Minimax M2.1 dans Trae
Étape 1 : Ouvrez Trae et accédez aux modèles
Lancez l’application Trae. Cliquez sur le bouton de bascule de la barre latérale IA dans le coin supérieur droit pour ouvrir la barre latérale IA. Ensuite, accédez à la gestion de l’IA et sélectionnez Modèles.

Étape 2 : Ajoutez un modèle personnalisé
Cliquez sur le bouton Ajouter un modèle pour créer une entrée de modèle personnalisé.

Étape 3 : Choisissez Novita comme fournisseur
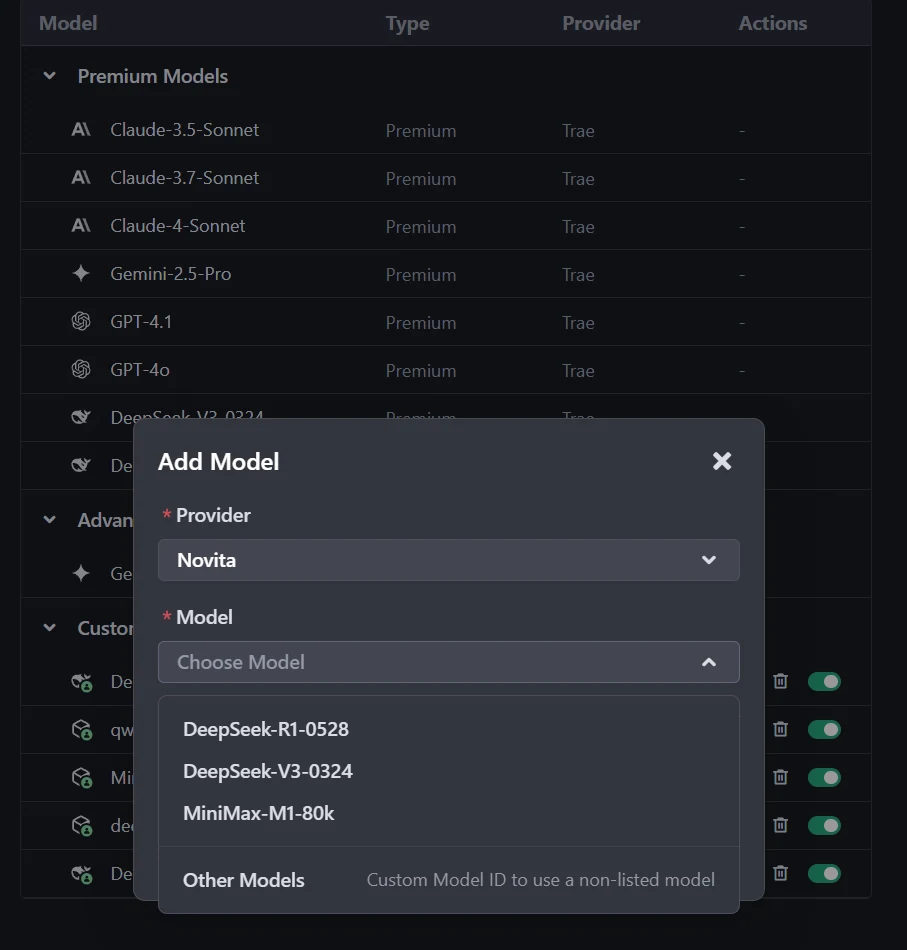
Dans la boîte de dialogue d’ajout de modèle, sélectionnez Fournisseur = Novita dans le menu déroulant.

Étape 4 : Sélectionnez ou saisissez le modèle
Dans le menu déroulant Modèle, choisissez le modèle souhaité (par exemple DeepSeek-R1-0528, DeepSeek-V3-0324 ou MiniMax-M1-80k). Si le modèle exact n’est pas listé, saisissez simplement l’ID du modèle que vous avez noté depuis la bibliothèque Novita. Assurez-vous de choisir la variante correcte du modèle que vous souhaitez utiliser.
Étape 5 : Saisissez votre clé API
Copiez la clé API Novita AI depuis votre console Novita et collez-la dans le champ Clé API de Trae.
Étape 6 : Enregistrez la configuration
Cliquez sur Ajouter un modèle pour enregistrer. Trae validera la clé API et la sélection du modèle en arrière-plan.
Minimax M2.1 dans Codex
Étape1:Prérequis
- Créez un compte : visitez le site Web de Novita AI et inscrivez-vous.
- Générez votre clé API : après vous être connecté, accédez à la page Gestion des clés pour générer votre clé API.
- Sélectionnez un nom de modèle : vous devrez copier le nom du modèle que vous souhaitez utiliser depuis la bibliothèque de modèles de Novita AI. Certains modèles disponibles incluent :
deepseek/deepseek-v3.1qwen/qwen3-coder-480b-a35b-instructmoonshotai/kimi-k2-0905openai/gpt-oss-120bzai-org/glm-4.5google/gemma-3-12b-it
- Enregistrez-la en toute sécurité : vous en aurez besoin pour la configuration.
Étape2:Installation
# Installez via npm (Recommandé)
npm install -g @openai/codex
# Installez via Homebrew (macOS)
brew install codex
# Vérifiez l'installation
codex --version
Étape3:Configuration des modèles Novita AI
Configuration du fichier de configuration
L’interface CLI de Codex utilise un fichier de configuration TOML situé à :
- macOS/Linux :
~/.codex/config.toml - Windows :
%USERPROFILE%\.codex\config.toml
Modèle de configuration de base
model = "MODEL_NAME"
model_provider = "novitaai"
[model_providers.novitaai]
name = "Novita AI"
base_url = "https://api.novita.ai/openai"
http_headers = {"Authorization" = "Bearer YOUR_NOVITA_API_KEY"}
wire_api = "chat"
5. Minimax M2.1 sur des plateformes tierces
- API compatible OpenAI : profitez d’une migration et d’une intégration sans problème avec des outils tels que Cline, OpenCode et Cursor, conçus pour le standard d’API OpenAI.
- Hugging Face : utilisez des modèles dans Spaces, des pipelines ou avec la bibliothèque Transformers via les points de terminaison Novita AI.
- Frameworks d’agents et d’orchestration : connectez facilement Novita AI à des plateformes partenaires comme Continue, AnythingLLM,LangChain, Dify et Langflow via des connecteurs officiels et des guides d’intégration étape par étape.
VIBE recentre l’évaluation sur les logiciels exécutables, et Minimax M2.1 prouve que l’intelligence applicative full-stack peut être à la fois de niveau exécution et abordable. Avec de solides performances inter-plateformes et des chemins de déploiement flexibles, Minimax M2.1 permet aux équipes de passer du codage assisté par IA à une production logicielle pilotée par des agents et économiquement scalable.
Questions fréquemment posées
Que mesure VIBE pour Minimax M2.1 ?
VIBE exécute des applications générées par Minimax M2.1 dans des environnements d’exécution réels, validant à la fois le comportement fonctionnel et la sortie visuelle sur Web, Simulation, Android, iOS et Backend.
Comment Minimax M2.1 se compare-t-il à Claude Sonnet 4.5 et Claude Opus 4.5 ?
Minimax M2.1 obtient des scores VIBE compétitifs par rapport à Claude Sonnet 4.5 et Claude Opus 4.5 tout en fonctionnant à un coût nettement inférieur.
Comment les développeurs peuvent-ils accéder à Minimax M2.1 via l’API ?
Les développeurs peuvent obtenir une clé et appeler Minimax M2.1 via Novita AI en utilisant un point de terminaison compatible OpenAI.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API intuitive, tout en fournissant un cloud GPU abordable et fiable pour la construction et la mise à l’échelle.
Lectures recommandées



