

Qwen3 시리즈는 각기 다른 필요에 맞게 조정된 다양한 대규모 언어 모델로 계속해서 주목을 받고 있습니다. 그중에서 Qwen3-Next-80B-A3B는 고급 계층을 대표하며, 방대한 매개변수와 고급 아키텍처를 갖추고 까다로운 추론 및 창의적 작업을 처리합니다. 반면 Qwen3-32B는 중간 크기 옵션으로, 실제 시나리오에서 다양성을 유지하면서 능력과 효율성의 균형을 맞추도록 설계되었습니다. 이 글에서는 개발자에게 중요한 여러 차원에서 Qwen3-Next-80B-A3B와 Qwen3-32B를 비교합니다.
Qwen3-Next-80B-A3B vs Qwen3-32B: 기본 사양 및 벤치마크
| 특징 | Qwen3-Next-80B-A3B | Qwen3-32B |
|---|---|---|
| 매개변수 | 총 80B, 활성화 3B | 32.8B |
| 아키텍처 | 혼합 전문가(MoE) | 밀집 |
| 컨텍스트 창 | 기본 262,144, 최대 1,010,000 토큰까지 확장 가능 | 기본 32,768, YaRN 사용 시 131,072 토큰 |
| 변형 | Thinking + Instruct | Thinking + Non-Thinking |
| 멀티모달 | 텍스트 전용 | 텍스트 전용 |
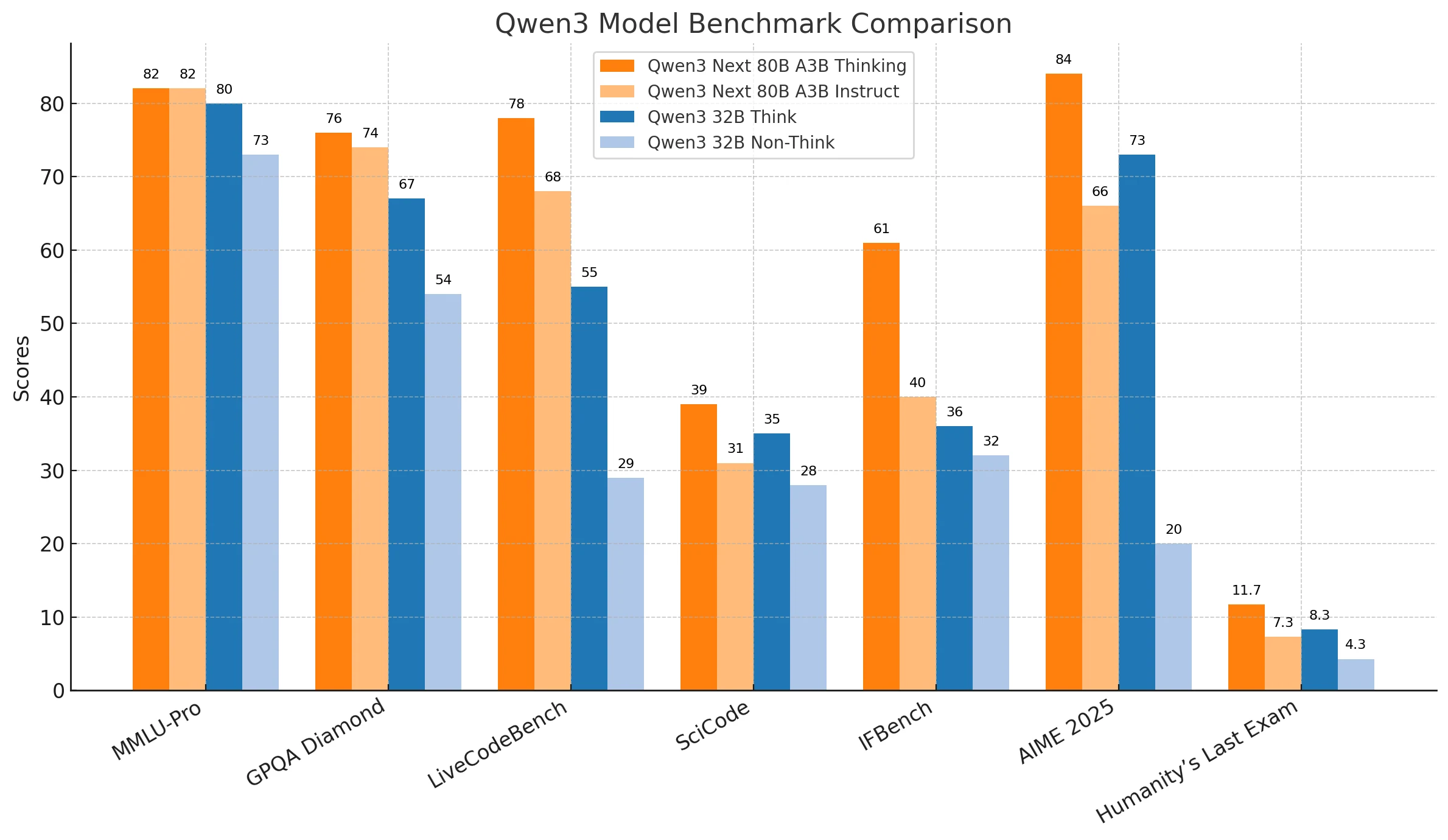
Qwen3-Next-80B는 복잡한 추론, 추상적인 문제 해결 및 고부담 작업에서 지속적으로 더 강력한 성능을 보여주며, 고급 연구, 전략적 의사 결정 및 미션 크리티컬 배포와 같은 엔터프라이즈 애플리케이션에 매우 적합합니다. 정밀성과 깊이가 필수적인 경우 신뢰성과 확장성 덕분에 가장 선호되는 옵션입니다.
Qwen3-32B는 효율성과 경제성 사이의 균형을 유지하며, 일상적인 코딩, 실용적인 자동화 및 절대적인 정확성보다 응답성이 중요한 시나리오에서 탁월합니다. 자원이나 지연 시간 제약이 더 엄격한 상황에서 신뢰할 수 있는 결과를 원하는 조직에게 비용 효율적인 솔루션입니다.
Qwen3-Next-80B-A3B vs Qwen3-32B: 속도 및 지연 시간
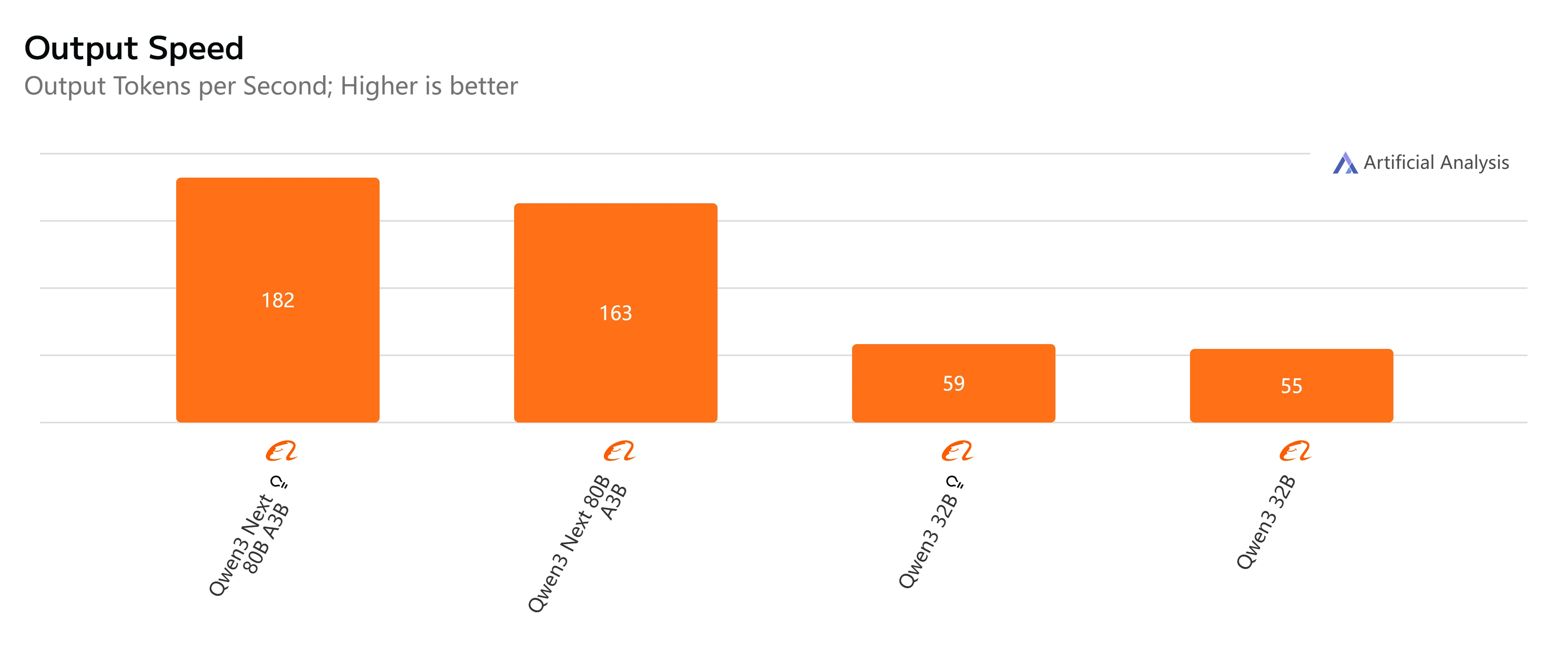
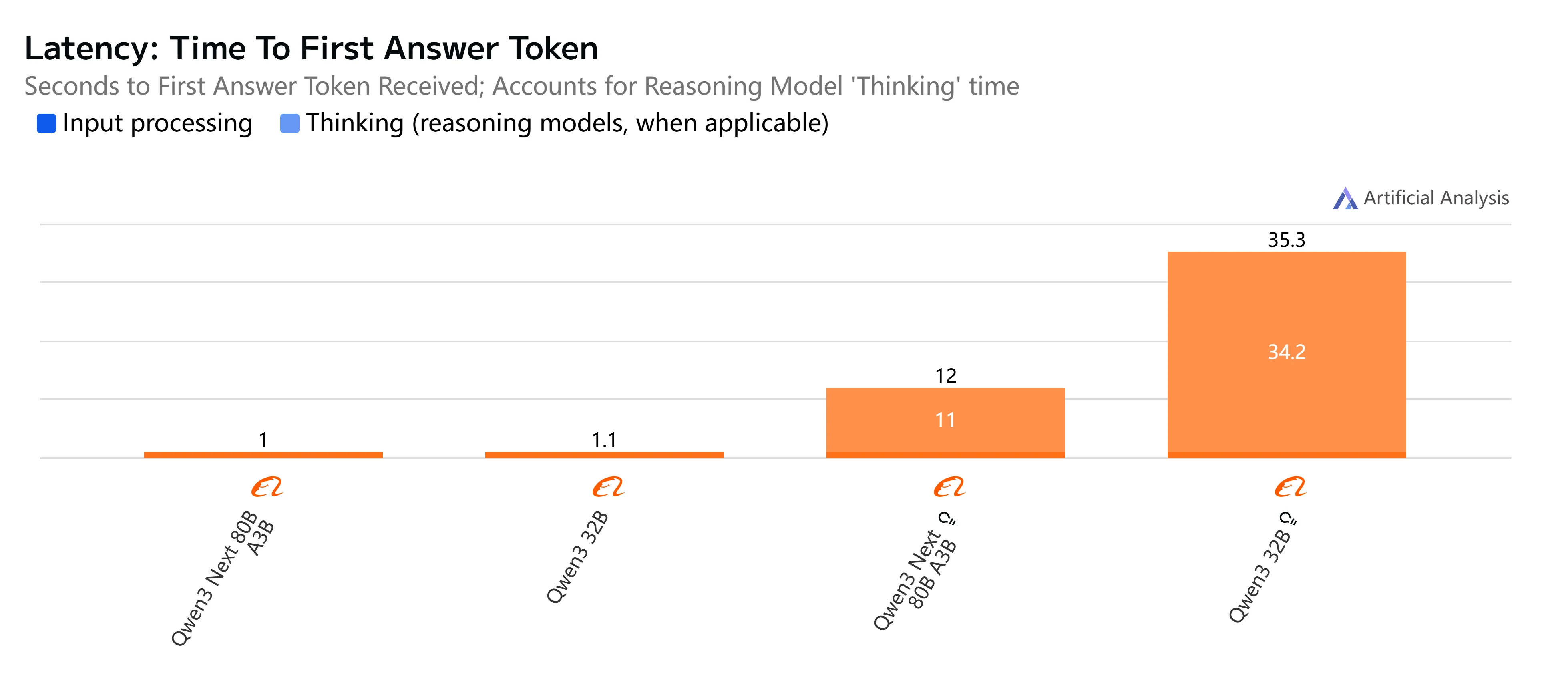
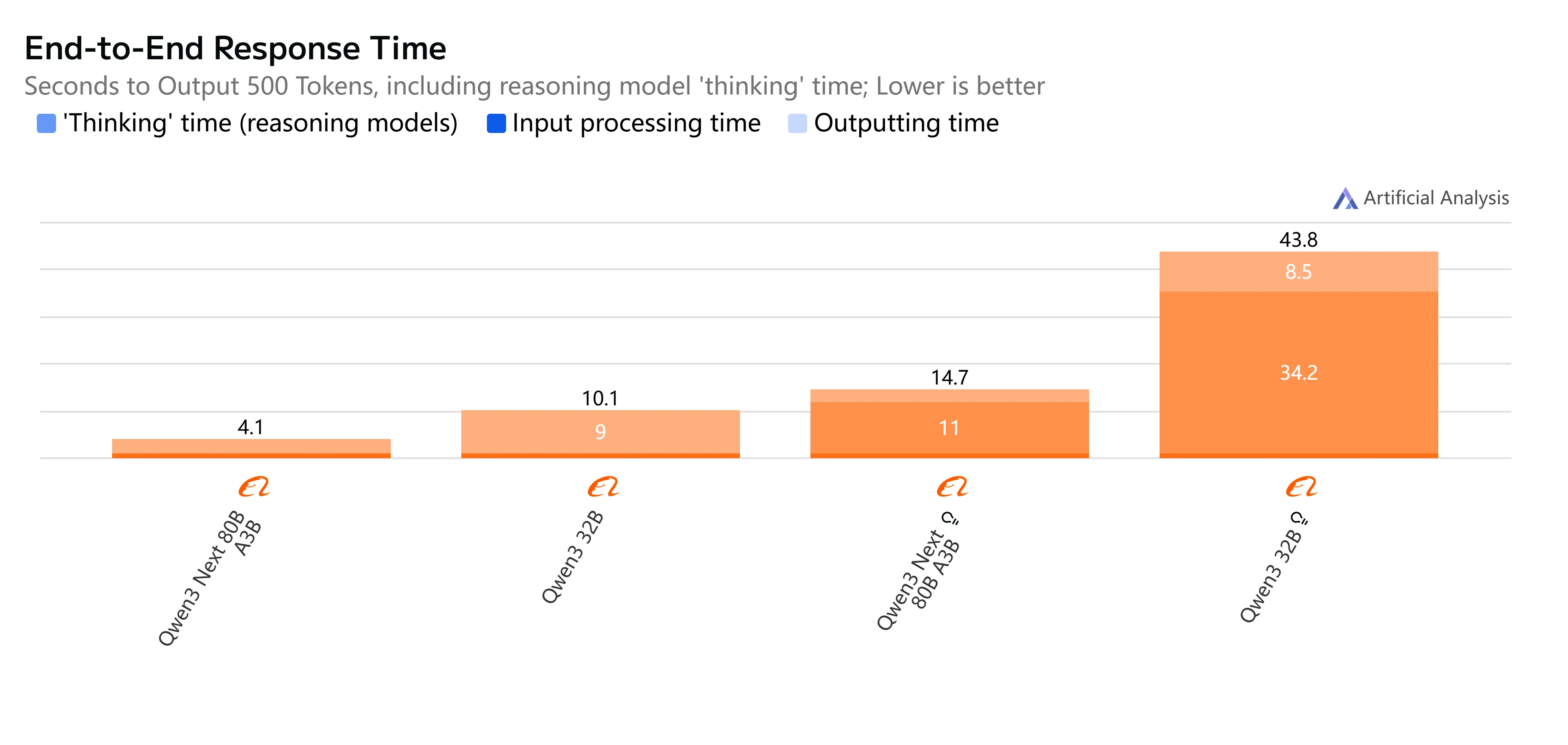
- Qwen3-Next-80B-A3B-Instruct: 빠른 응답과 상대적으로 낮은 지연 시간으로 500토큰 출력을 4초 조금 넘게 완료하며 원활한 처리량을 제공하여 대화형 및 실시간 작업에 실용적입니다.
- Qwen3-32B (Non-Thinking): 전반적으로 적당한 속도로 약 10초의 더 높은 지연 시간과 느린 토큰 생성을 보이지만, 효율성이 중요한 균형 잡힌 워크로드에 여전히 적합합니다.
- Qwen3-Next-80B-A3B-Thinking: 추론 오버헤드로 인해 눈에 띄게 느리며 종단 간 거의 15초가 소요됩니다. 그러나 더 강력한 추론 깊이를 제공하여 복잡한 문제 해결에 더 적합합니다.
- Qwen3-32B (Thinking): 가장 느린 옵션으로 매우 높은 지연 시간(35초 초과)과 제한된 처리량을 가집니다. 연구나 속도보다 고급 추론이 우선시되는 시나리오에 가장 적합합니다.
Qwen3-Next-80B-A3B vs Qwen3-32B: 사용 사례
Qwen3-32B
1. 일상 효율성 및 어시스턴트 경험
- 간결한 응답: 적은 토큰으로 직접적인 답변을 생성하여 비용 효율적입니다.
- 브레인스토밍 및 글쓰기: 창의적인 초안 작성, 아이디어 생성 및 가벼운 글쓰기 작업에 유용합니다.
- 유연한 사고: 전환 가능한 추론 모드를 지원하여 속도가 깊이보다 중요할 때 즉각적인 답변을 제공합니다.
2. 코딩 및 기술 작업
- 프로그래밍 지원: 일상적인 개발을 위한 신뢰할 수 있는 코드 생성 및 디버깅을 제공합니다.
- 지시 따르기: 밀집 아키텍처 덕분에 상세한 프롬프트를 잘 처리합니다.
- 엔지니어링 워크플로우: 기술 문제 해결 및 도구 지원 코딩에서 강력한 성능을 보입니다.
3. 텍스트 처리 및 언어 작업
- 요약: 낮은 양자화 수준에서도 이야기와 문서를 정확하게 요약합니다.
- 재작성 및 스타일 변경: 의미를 유지하면서 텍스트를 새로운 형식이나 어조로 변환합니다.
- 분류 및 번역: 지저분한 텍스트 분류와 자연스러운 번역 생성에 탁월합니다.
4. 주의할 점
- 긴 컨텍스트 작업에서 덜 효과적입니다(~5K 토큰 이상에서 일관성이 떨어짐).
- 사실 기반 추론에서 환각률이 더 높습니다.
- 확장된 창의적 글쓰기나 구조화된 데이터 추출에 제한적입니다.
Qwen3-Next-80B-A3B
1. 높은 효율성
- 희소 활성화 장점: 토큰당 약 3B의 활성 매개변수만 있어 비용과 계산량을 줄입니다.
- 처리량 이점: 32K보다 긴 컨텍스트에서 10배 이상 높은 추론 처리량을 달성합니다.
2. 극한 컨텍스트 길이 처리
- 긴 컨텍스트 최적화: 매우 높은 컨텍스트 길이(최대 262K 테스트)에서 속도를 유지합니다.
- 하이브리드 어텐션 설계: Gated DeltaNet, Gated Attention 및 선형 어텐션을 결합하여 효율적인 확장을 제공합니다.
- 응용 분야: 소설 번역, 법률 문서 검토, 연구 데이터 처리와 같은 긴 형식 작업에 이상적입니다.
3. 추론 및 일반 지능
- 일상 LLM: 부드러운 Instruct 성능으로 일반 용도의 강력한 ‘두뇌’ 역할을 합니다.
- 추론 강점: 특히 틈새 문제 해결에서 논리와 추론 측면에서 Qwen3-235B에 근접합니다.
- Thinking 모드: 다단계 추론 및 도구 오케스트레이션에 효과적입니다.
4. 코딩 및 에이전트 기능
- 소프트웨어 개발: 리팩토링, 테스트 생성 및 프로젝트 구축에 신뢰할 수 있습니다.
- 에이전트 작업: 도구 호출 및 API 상호 작용을 통해 복잡한 워크플로우를 실행합니다.
- 개발자 도구: 편집, 버전 제어 및 자동화 지원을 통해 IDE에 원활하게 통합됩니다.
5. RAG 및 지식 통합
- RAG 우수성: 지저분하거나 구조화되지 않은 소스에서도 검색 증강 생성에서 강력한 성능을 보입니다.
- 지식 작업: 외부 데이터베이스나 문서 저장소에 연결될 때 근거 있는 답변을 생성합니다.
6. 요약 및 콘텐츠 생성
- 다중 소스 요약: 일관된 설명을 추가하면서 뉴스나 긴 문서를 요약합니다.
- 콘텐츠 생성: 재작성 및 확장된 내러티브 생성에 다재다능합니다.
Qwen3-Next-80B-A3B vs Qwen3-32B: 가격
| 모델 | 컨텍스트 창 | 최대 출력 | 입력 가격 (/100만 토큰) | 출력 가격 (/100만 토큰) |
|---|---|---|---|---|
| Qwen3-Next-80B-A3B-Thinking/Instruct | 131K | 32.7K | $0.15 | $1.5 |
| Qwen3-32B (Thinking/Non-Thinking) | 40.9K | 20K | $0.1 | $0.45 |
모든 API 가격은 Novita AI에서 제공되는 기준입니다.
Qwen3-Next-80B-A3B는 훨씬 더 큰 컨텍스트 창과 더 높은 출력 용량을 제공하지만, 더 높은 입력 및 출력 비용이 발생합니다. Qwen3-32B는 더 저렴하고 효율적이지만, 컨텍스트 길이와 생성 제한이 상당히 작습니다.
Qwen3-Next-80B-A3B 및 Qwen3-32B에 액세스하는 방법
Novita AI는 Qwen3-Next-80B-A3B와 Qwen3-32B 모두에 대한 유연한 액세스를 제공하여 일상적인 애플리케이션부터 고급 개발까지 광범위한 요구에 적응할 수 있도록 하며, 원활한 배포를 위한 적절한 도구로 뒷받침됩니다.
옵션 1: 플레이그라운드 사용 (지금 이용 가능 – 코딩 불필요)
- 즉시 액세스: 가입하고 몇 초 만에 Qwen3-Next-80B-A3B 또는 Qwen3-32B 실험을 시작하세요.
- 대화형 인터페이스: 프롬프트를 테스트하고 출력을 실시간으로 시각화합니다.
- 모델 비교: 특정 사용 사례에 대해 다른 주요 모델과 비교합니다.
플레이그라운드를 사용하면 기술 설정 없이 프롬프트를 실험하고 결과를 즉시 확인할 수 있습니다. 신속한 프로토타이핑, 새로운 아이디어 테스트, 본격적인 구현 전 모델 기능 탐색에 이상적입니다.
지금 Qwen3-Next-80B-A3B를 무료로 사용해보세요!
옵션 2: API 액세스 (개발자용)
Novita AI의 REST API를 통해 Qwen3-Next-80B-A3B 또는 Qwen3-32B를 애플리케이션에 연결하세요. 인프라를 관리하지 않고도 긴 컨텍스트에서 모델의 10배 추론 처리량을 활용할 수 있습니다.
1단계: 로그인 및 모델 라이브러리 액세스

2단계: 모델 선택
사용 가능한 옵션을 살펴보고 필요에 맞는 모델을 선택하세요.
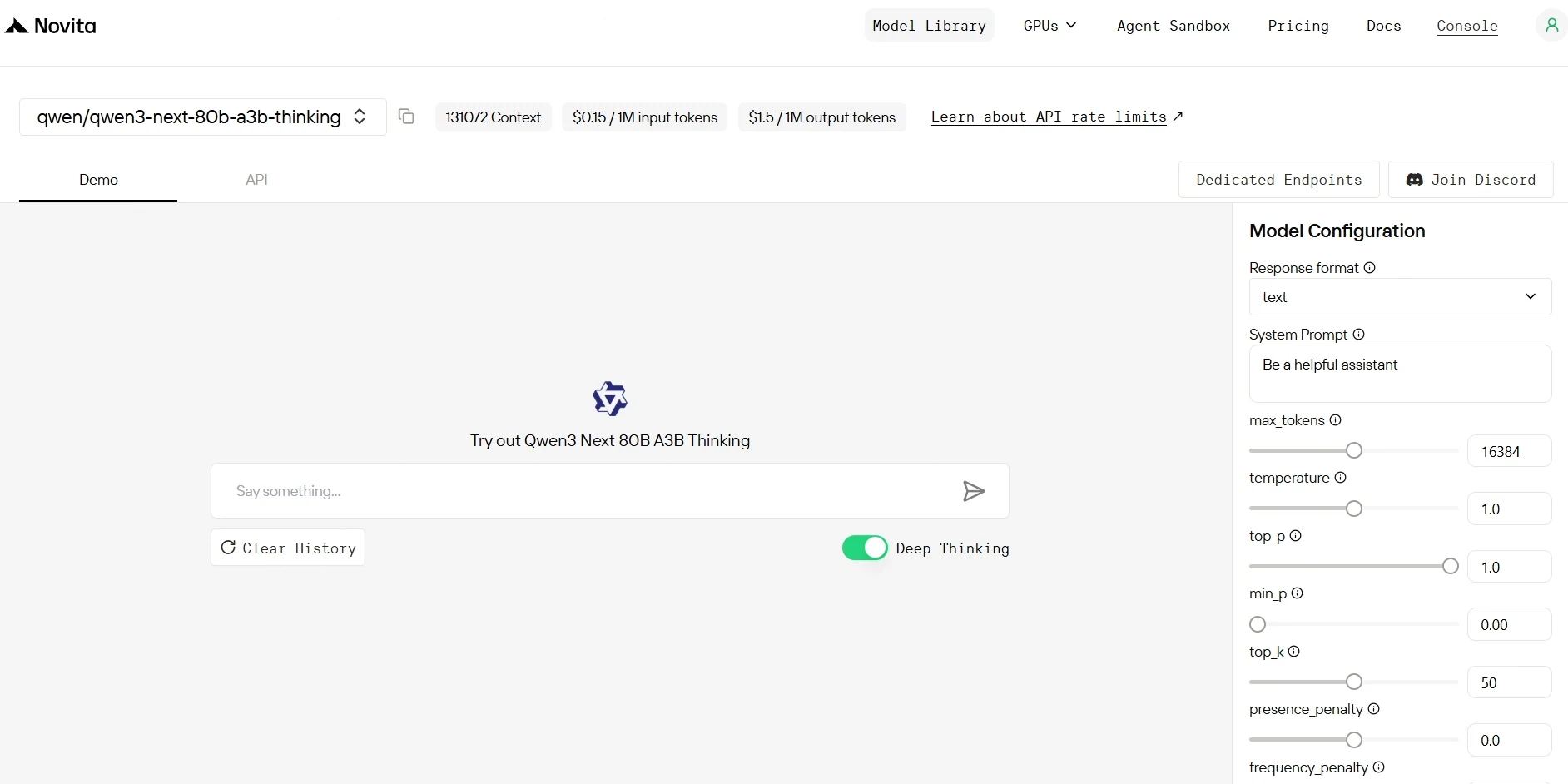
3단계: 무료 체험 시작
선택한 모델의 기능을 탐색하기 위해 무료 체험을 시작하세요.
4단계: API 키 받기
API 인증을 위해 새로운 API 키를 제공해 드립니다. “계정 설정” 페이지로 이동하여 이미지에 표시된 대로 API 키를 복사할 수 있습니다.

5단계: API 설치 (Qwen3-Next-80B-A3B-Thinking용 Python 예제)
프로그래밍 언어에 맞는 패키지 관리자를 사용하여 API를 설치합니다.
설치 후 필요한 라이브러리를 개발 환경에 가져옵니다. API 키로 API를 초기화하여 Novita AI LLM과 상호 작용을 시작합니다. 다음은 Python 사용자를 위한 채팅 완료 API 사용 예제입니다.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="your_api_key_here",
)
model = "qwen/qwen3-next-80b-a3b-instruct"
stream = True # or False
max_tokens = 4096
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = {"type": "text"}
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
플랫폼 기능:
- OpenAI 호환 엔드포인트: 원활한 통합을 위한
/v3/openai - 유연한 매개변수: temperature, top-p, 페널티 등으로 생성 제어
- 스트리밍 지원: 스트리밍 또는 배치 응답 중 선택
- 모델 선택: instruct 및 thinking 변형 모두 액세스
자주 묻는 질문
Qwen3-Next-80B-A3B와 Qwen3-32B의 주요 차이점은 무엇인가요?
Qwen3-Next-80B-A3B는 복잡한 작업과 효율성에 최적화된 차세대 희소 MoE 모델인 반면, Qwen3-32B는 균형 잡힌 성능과 일상적인 사용을 위해 설계된 밀집 모델입니다.
긴 컨텍스트 입력을 더 잘 처리하는 모델은 Qwen3-Next-80B-A3B와 Qwen3-32B 중 어떤 것인가요?
Qwen3-Next-80B-A3B는 극한의 컨텍스트 길이(최대 262K 토큰 테스트)에 최적화되어 있으며 대규모에서도 높은 속도를 유지합니다.
Qwen3-Next-80B-A3B와 Qwen3-32B 사용 비용은 얼마인가요?
Novita AI에서 Qwen3-Next-80B-A3B는 입력 토큰 100만 개당 $0.15, 출력 토큰 100만 개당 $1.5에 제공됩니다. 반면 Qwen3-32B는 입력 토큰 100만 개당 $0.1, 출력 토큰 100만 개당 $0.45에 이용 가능하여 소규모 또는 비용에 민감한 작업에 더 저렴한 옵션입니다.
Novita AI는 AI 야망을 실현하는 올인원 클라우드 플랫폼입니다. 통합 API, 서버리스, GPU 인스턴스 — 필요한 비용 효율적인 도구. 인프라를 없애고 무료로 시작하여 AI 비전을 현실로 만드세요.



