

La série Qwen3 continue d’attirer l’attention grâce à sa gamme diversifiée de grands modèles linguistiques, chacun adapté à des besoins spécifiques. Parmi eux, Qwen3-Next-80B-A3B représente la gamme haut de gamme, équipé de paramètres massifs et d’une architecture avancée pour gérer des tâches de raisonnement et créatives exigeantes. D’un autre côté, Qwen3-32B est une option de taille moyenne, conçue pour équilibrer capacités et efficacité tout en restant polyvalente dans des scénarios pratiques. Dans cet article, nous comparerons Qwen3-Next-80B-A3B et Qwen3-32B sur plusieurs dimensions importantes pour les développeurs.
Qwen3-Next-80B-A3B vs Qwen3-32B : Bases et benchmarks
| Fonctionnalité | Qwen3-Next-80B-A3B | Qwen3-32B |
| Paramètres | 80B au total et 3B activés | 32,8B |
| Architecture | Mixure-of-Experts | Dense |
| Fenêtre de contexte | 262 144 tokens nativement et extensible jusqu’à 1 010 000 tokens | 32 768 tokens nativement et 131 072 tokens avec YaRN |
| Variantes | Thinking + Instruct | Thinking + Non-Thinking |
| Multimodalité | Texte uniquement | Texte uniquement |
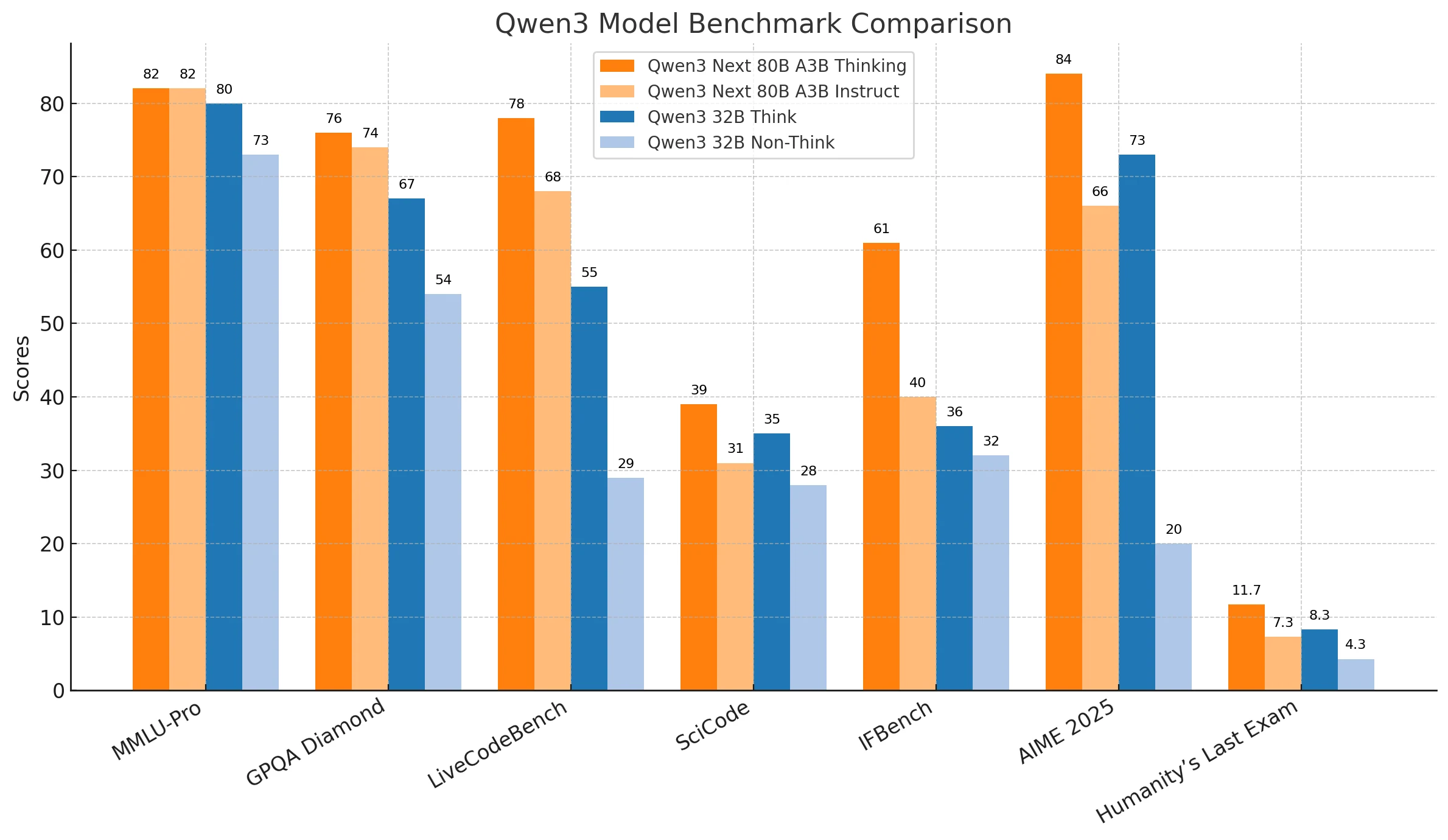
Qwen3-Next-80B affiche systématiquement des performances plus élevées pour les tâches de raisonnement complexes, la résolution de problèmes abstraits et les missions à haut risque, ce qui le rend particulièrement adapté aux applications professionnelles telles que la recherche avancée, la prise de décision stratégique et les déploiements critiques. Sa fiabilité et sa scalabilité en font l’option privilégiée lorsque la précision et la profondeur sont non négociables.
Qwen3-32B trouve un équilibre entre efficacité et abordabilité, excellant dans le codage quotidien, l’automatisation pratique et les scénarios où la réactivité compte plus que la précision absolue. C’est une solution rentable pour les organisations cherchant des résultats fiables dans des conditions de ressources ou de latence plus strictes.
Qwen3-Next-80B-A3B vs Qwen3-32B : Vitesse et latence
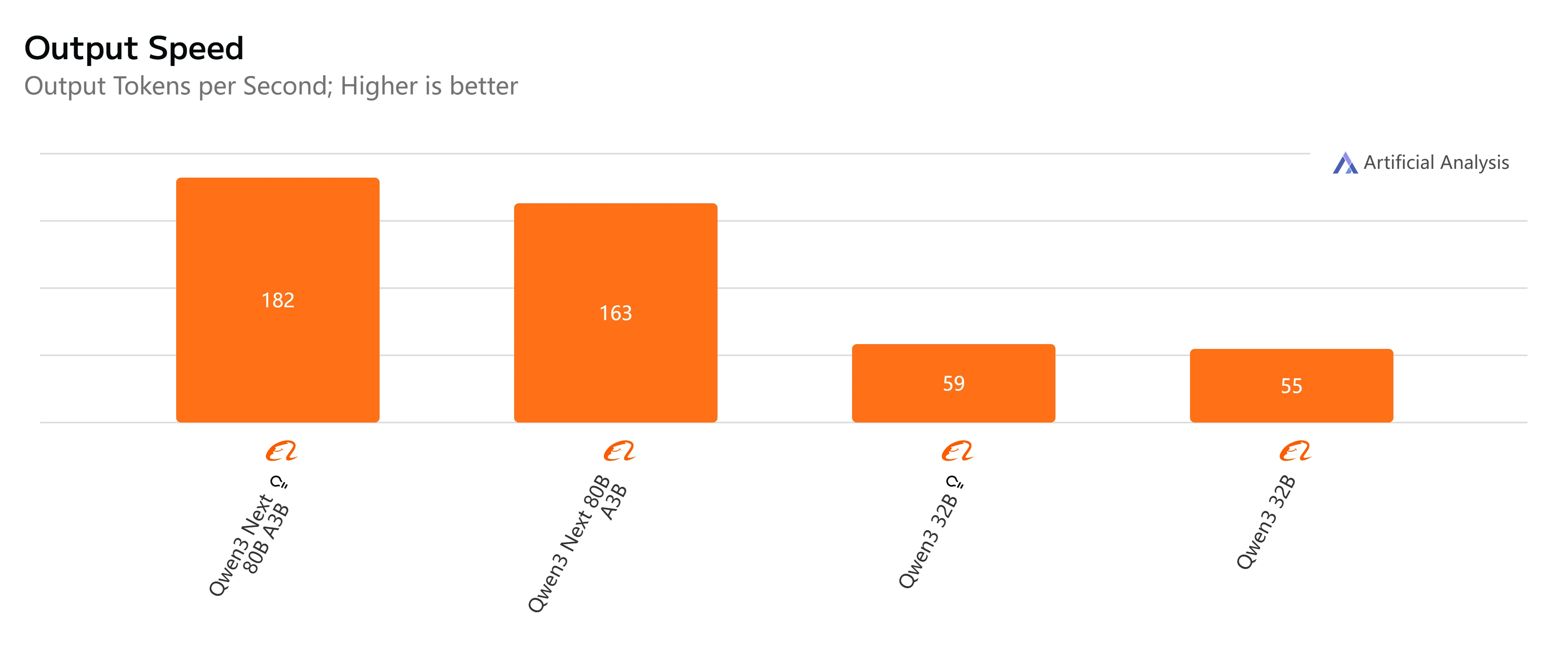
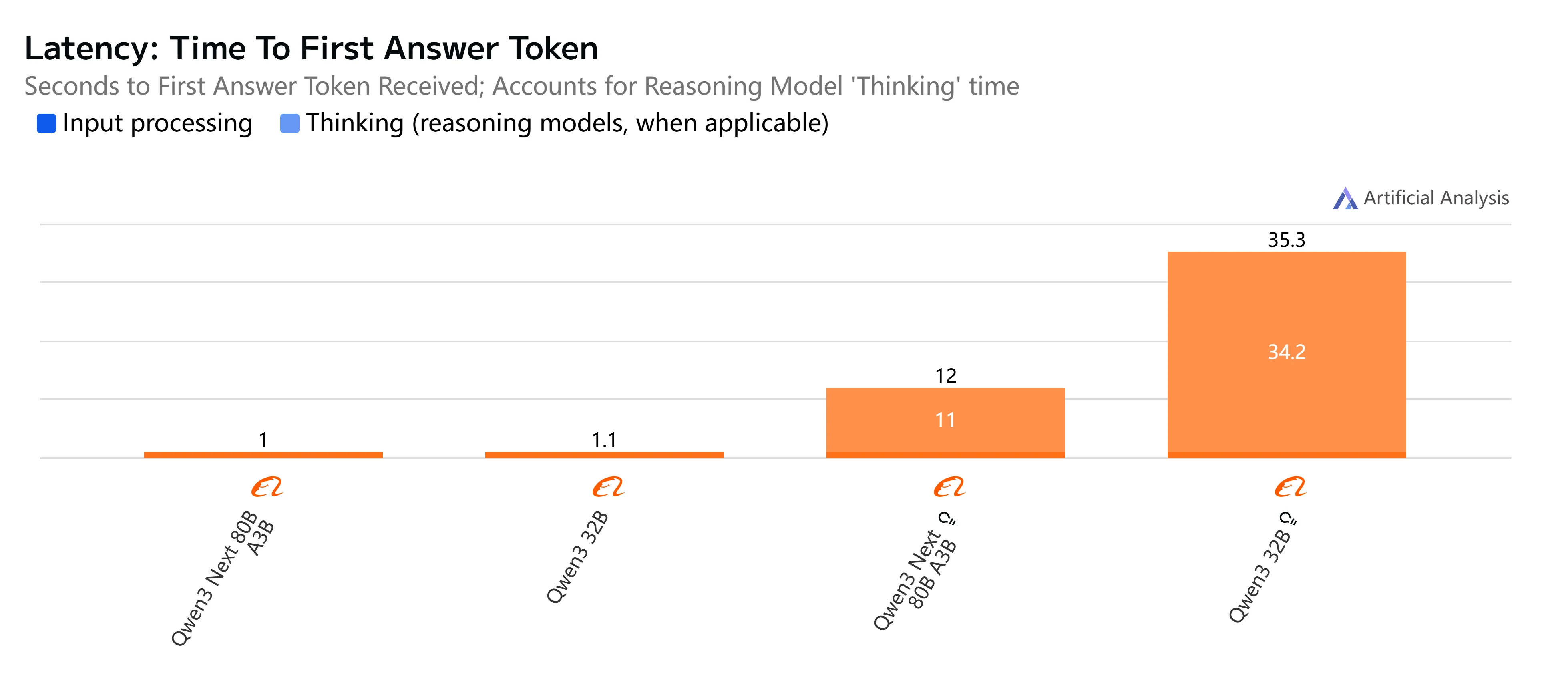
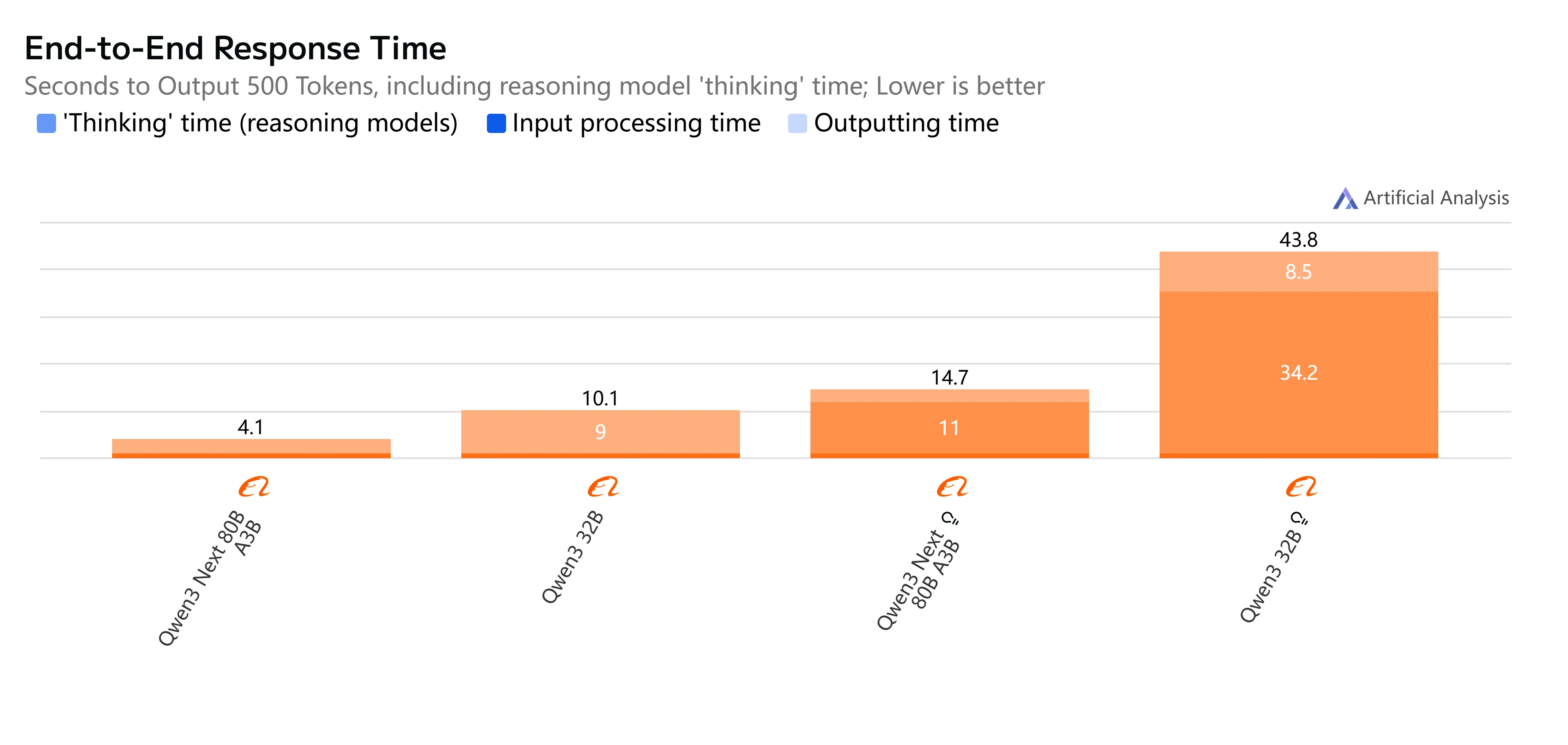
- Qwen3-Next-80B-A3B-Instruct : Réponse rapide et latence relativement faible, complétant des sorties de 500 tokens en un peu plus de 4 secondes avec un débit fluide, ce qui le rend pratique pour les tâches interactives et en temps réel.
- Qwen3-32B (Non-Thinking) : Vitesse globale modérée, avec une latence plus élevée d’environ 10 secondes et une génération de tokens plus lente, mais reste adapté aux charges de travail équilibrées où l’efficacité est importante.
- Qwen3-Next-80B-A3B-Thinking : Remarquablement plus lent en raison de la surcharge de raisonnement, prenant près de 15 secondes de bout en bout. Cependant, il offre une profondeur de raisonnement plus forte, ce qui le rend meilleur pour la résolution de problèmes complexes.
- Qwen3-32B (Thinking) : L’option la plus lente, avec une latence très élevée (plus de 35 secondes) et un débit limité. À réserver à la recherche ou aux scénarios où le raisonnement avancé est priorisé par rapport à la vitesse.
Qwen3-Next-80B-A3B vs Qwen3-32B : Cas d’usage
Qwen3-32B
1. Efficacité quotidienne et expérience assistant
- Réponses concises : Génère des réponses directes avec moins de tokens, ce qui le rend rentable.
- Brainstorming et rédaction : Utile pour la rédaction créative, la génération d’idées et les tâches de rédaction légères.
- Réflexion flexible : Prend en charge un mode de raisonnement basculable, permettant des réponses instantanées lorsque la vitesse est plus importante que la profondeur.
2. Codage et tâches techniques
- Support de programmation : Fournit une génération de code et un débogage fiables pour le développement quotidien.
- Respect des instructions : Gère bien les prompts détaillés grâce à son architecture dense.
- Flux de travail d’ingénierie : Performant dans la résolution de problèmes techniques et le codage assisté par outils.
3. Traitement de texte et travail linguistique
- Résumé : Résume précisément des histoires et des documents, même à des niveaux de quantification bas.
- Réécriture et reformulation : Transforme le texte dans de nouveaux formats ou tons tout en préservant le sens.
- Classification et traduction : Excelle dans la classification de texte désordonné et la production de traductions naturelles.
4. Limites à prendre en compte
- Moins efficace dans les tâches de contexte long (perd la cohérence au-delà de ~5K tokens).
- Taux d’hallucination plus élevé dans le raisonnement factuel.
- Limité pour la rédaction créative étendue ou l’extraction de données structurées.
Qwen3-Next-80B-A3B
1. Haute efficacité
- Avantage de l’activation sparse : Seulement ~3B de paramètres actifs par token, réduisant les coûts et la puissance de calcul.
- Gains de débit : Atteint un débit d’inférence plus de 10 fois supérieur sur des contextes de plus de 32K.
2. Gestion de longueur de contexte extrême
- Optimisation pour les contextes longs : Maintient la vitesse pour des longueurs de contexte très élevées (testé jusqu’à 262K).
- Architecture d’attention hybride : Combine Gated DeltaNet, Gated Attention et attention linéaire pour une mise à l’échelle efficace.
- Applications : Idéal pour les tâches de longue forme telles que la traduction de romans, la révision de documents juridiques ou le traitement de données de recherche.
3. Raisonnement et intelligence générale
- LLM quotidien : Fonctionne comme un “cerveau principal” solide pour un usage général, avec des performances Instruct fluides.
- Force de raisonnement : Approche les performances de Qwen3-235B en logique et déduction, notamment dans la résolution de problèmes de niche.
- Mode Thinking : Efficace pour le raisonnement multi-étapes et l’orchestration d’outils.
4. Codage et capacités agentiques
- Développement logiciel : Fiable pour la refactorisation, la génération de tests et la construction de projets.
- Tâches agentiques : Exécute des flux de travail complexes avec des appels d’outils et des interactions API.
- Outils pour développeurs : S’intègre parfaitement dans les IDE avec la prise en charge de l’édition, du contrôle de version et de l’automatisation.
5. RAG et intégration de connaissances
- Excellence RAG : Performant dans la génération augmentée par récupération, même avec des sources désordonnées ou non structurées.
- Tâches de connaissances : Génère des réponses fondées lorsqu’il est connecté à des bases de données externes ou des magasins de documents.
6. Résumé et création de contenu
- Résumé multi-sources : Condense des actualités ou des documents longs tout en ajoutant des commentaires cohérents.
- Génération de contenu : Polyvalent pour la réécriture et la production de récits étendus.
Qwen3-Next-80B-A3B vs Qwen3-32B : Tarification
| Modèle | Fenêtre de contexte | Sortie maximale | Prix d’entrée (/1M tokens) | Prix de sortie (/1M tokens) |
| Qwen3-Next-80B-A3B-Thinking/Instruct | 131K | 32,7K | 0,15 $ | 1,5 $ |
| Qwen3-32B (Thinking/Non-Thinking) | 40,9K | 20K | 0,1 $ | 0,45 $ |
Tous les prix d’API sont listés tels que disponibles sur Novita AI
Qwen3-Next-80B-A3B offre une fenêtre de contexte beaucoup plus grande et une capacité de sortie plus élevée, mais implique des coûts d’entrée et de sortie plus élevés. Qwen3-32B est plus abordable et efficace, même si sa longueur de contexte et sa limite de génération sont significativement plus petites.
Comment accéder à Qwen3-Next-80B-A3B et Qwen3-32B
Novita AI propose un accès flexible aux deux modèles Qwen3-Next-80B-A3B et Qwen3-32B, les rendant adaptables à un large spectre de besoins — des applications quotidiennes au développement avancé — soutenus par les outils adaptés pour un déploiement transparent.
Option 1 : Utiliser le Playground (Disponible maintenant – Aucun code requis)
- Accès instantané : Inscrivez-vous et commencez à expérimenter avec Qwen3-Next-80B-A3B ou Qwen3-32B en quelques secondes.
- Interface interactive : Testez des prompts et visualisez les sorties en temps réel.
- Comparaison de modèles : Comparez avec d’autres modèles leaders pour votre cas d’usage spécifique.
Le playground vous permet d’expérimenter avec des prompts et de visualiser les résultats instantanément, sans aucune configuration technique requise. Il est idéal pour le prototypage rapide, le test de nouvelles idées et l’exploration des capacités des modèles avant une mise en œuvre à grande échelle.
Essayez Qwen3-Next-80B-A3B gratuitement maintenant !
Option 2 : Accès API (Pour les développeurs)
Connectez Qwen3-Next-80B-A3B ou Qwen3-32B à vos applications via l’API REST de Novita AI — en bénéficiant d’un débit d’inférence 10x supérieur sur les contextes longs sans avoir à gérer d’infrastructure.
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles

Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.
Étape 3 : Commencez votre essai gratuit
Démarrez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Récupérez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En accédant à la page « Paramètres du compte », vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API (Exemple Python pour Qwen3-Next-80B-A3B-Thinking)
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation. Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec les LLM de Novita AI. Ceci est un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="your_api_key_here",
)
model = "qwen/qwen3-next-80b-a3b-instruct"
stream = True # or False
max_tokens = 4096
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = {"type": "text"}
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Fonctionnalités de la plateforme :
- Point de terminaison compatible OpenAI :
/v3/openaipour une intégration transparente - Paramètres flexibles : Contrôlez la génération avec la température, le top-p, les pénalités et plus encore
- Prise en charge du streaming : Choisissez entre des réponses en streaming ou par lots
- Sélection de modèle : Accédez aux variantes instruct et thinking
Foire aux questions
Quelle est la différence principale entre Qwen3-Next-80B-A3B et Qwen3-32B ?
Qwen3-Next-80B-A3B est un modèle MoE sparse nouvelle génération optimisé pour les tâches complexes et l’efficacité, tandis que Qwen3-32B est un modèle dense conçu pour des performances équilibrées et un usage quotidien.
Quel modèle, Qwen3-Next-80B-A3B ou Qwen3-32B, gère mieux les entrées de contexte long ?
Qwen3-Next-80B-A3B est optimisé pour des longueurs de contexte extrêmes (testé jusqu’à 262K tokens) et maintient une vitesse élevée à grande échelle.
Combien coûte l’utilisation de Qwen3-Next-80B-A3B par rapport à Qwen3-32B ?
Sur Novita AI, Qwen3-Next-80B-A3B est tarifé à 0,15 $ par 1M de tokens d’entrée et 1,5 $ par 1M de tokens de sortie. Par ailleurs, Qwen3-32B est disponible à 0,1 $ par 1M de tokens d’entrée et 0,45 $ par 1M de tokens de sortie, ce qui en fait une option plus abordable pour les tâches de petite échelle ou sensibles aux coûts.
Novita AI est la plateforme cloud tout-en-un qui concrétise vos ambitions en matière d’IA. API intégrées, serverless, instances GPU — les outils rentables dont vous avez besoin. Éliminez l’infrastructure, commencez gratuitement et donnez vie à votre vision de l’IA.



