

Серия Qwen3 продолжает привлекать внимание своим разнообразием больших языковых моделей, каждая из которых адаптирована под разные потребности. Среди них Qwen3-Next-80B-A3B представляет собой флагманский вариант, оснащенный огромным количеством параметров и продвинутой архитектурой для решения сложных задач на рассуждение и креативные задачи. С другой стороны, Qwen3-32B является моделью среднего размера, разработанной для баланса производительности и эффективности, оставаясь универсальной в практических сценариях. В этой статье мы сравним Qwen3-Next-80B-A3B и Qwen3-32B по нескольким параметрам, важным для разработчиков
Qwen3-Next-80B-A3B vs Qwen3-32B: Основы и бенчмарки
| Параметр | Qwen3-Next-80B-A3B | Qwen3-32B |
| Параметры | 80B всего и 3B активированных | 32.8B |
| Архитектура | Mixure-of-Experts | Dense |
| Контекстное окно | 262 144 токена нативно, расширяется до 1 010 000 токенов | 32 768 токенов нативно и 131 072 токенов с YaRN |
| Варианты | Thinking + Instruct | Thinking + Non-Thinking |
| Мультимодальность | Только текст | Только текст |
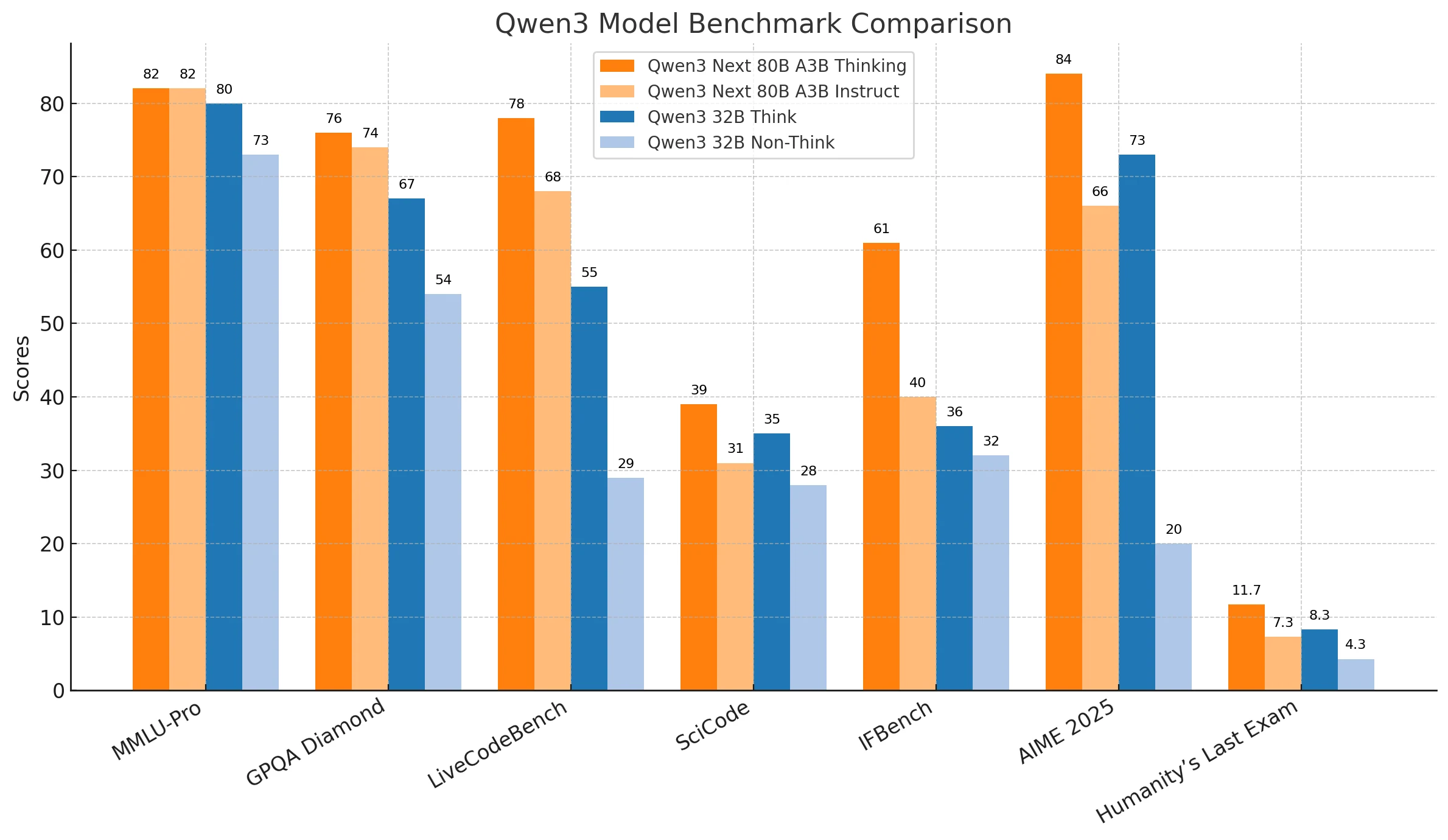
Qwen3-Next-80B последовательно показывает более высокую производительность в сложных рассуждениях, решении абстрактных задач и критически важных задачах, что делает его идеальным вариантом для корпоративных приложений, таких как передовые исследования, стратегическое принятие решений и развертывания критически важных систем. Его надежность и масштабируемость делают его оптимальным выбором, когда точность и глубина анализа являются обязательными.
Qwen3-32B сочетает в себе эффективность и доступность, показывая лучшие результаты в повседневном программировании, практической автоматизации и сценариях, где скорость ответа важнее абсолютной точности. Это экономически эффективное решение для организаций, которым нужны надежные результаты при ограниченных ресурсах или требованиях к задержкам.
Qwen3-Next-80B-A3B vs Qwen3-32B: Скорость и задержка
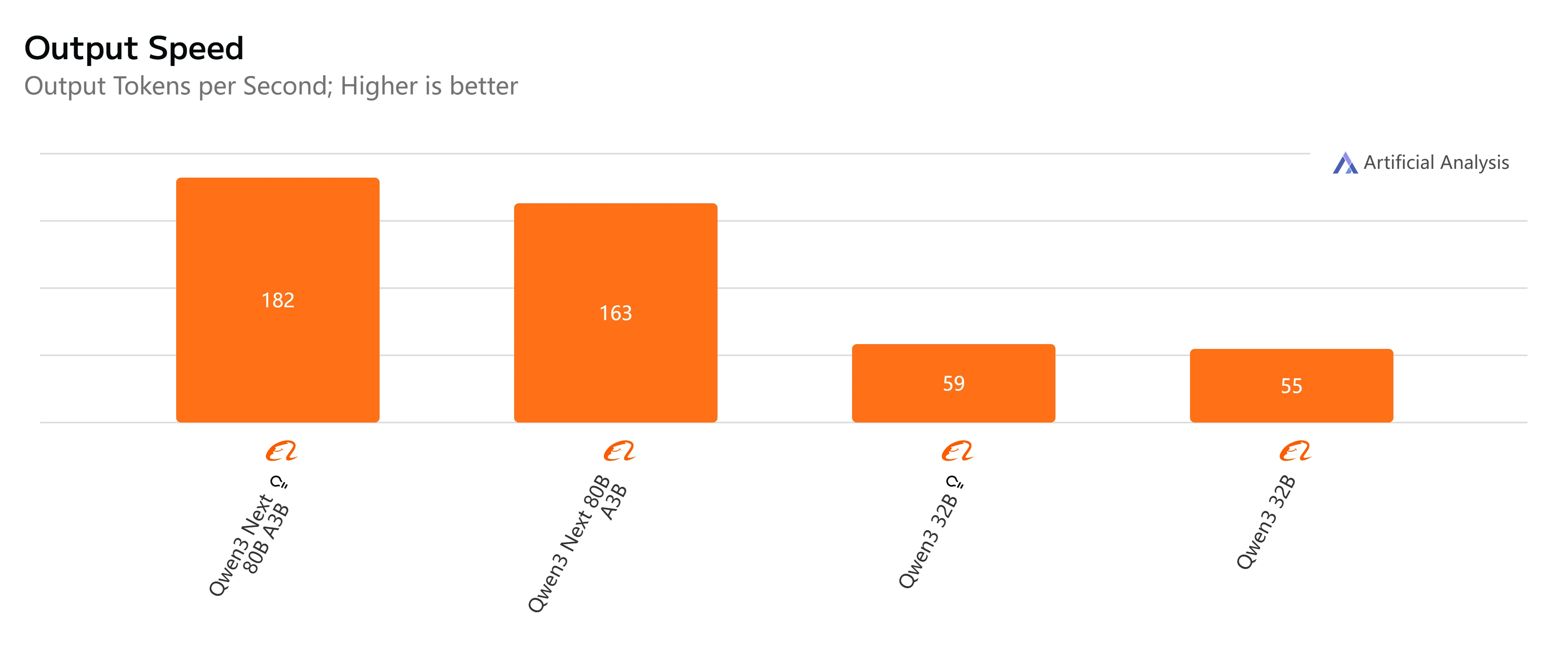
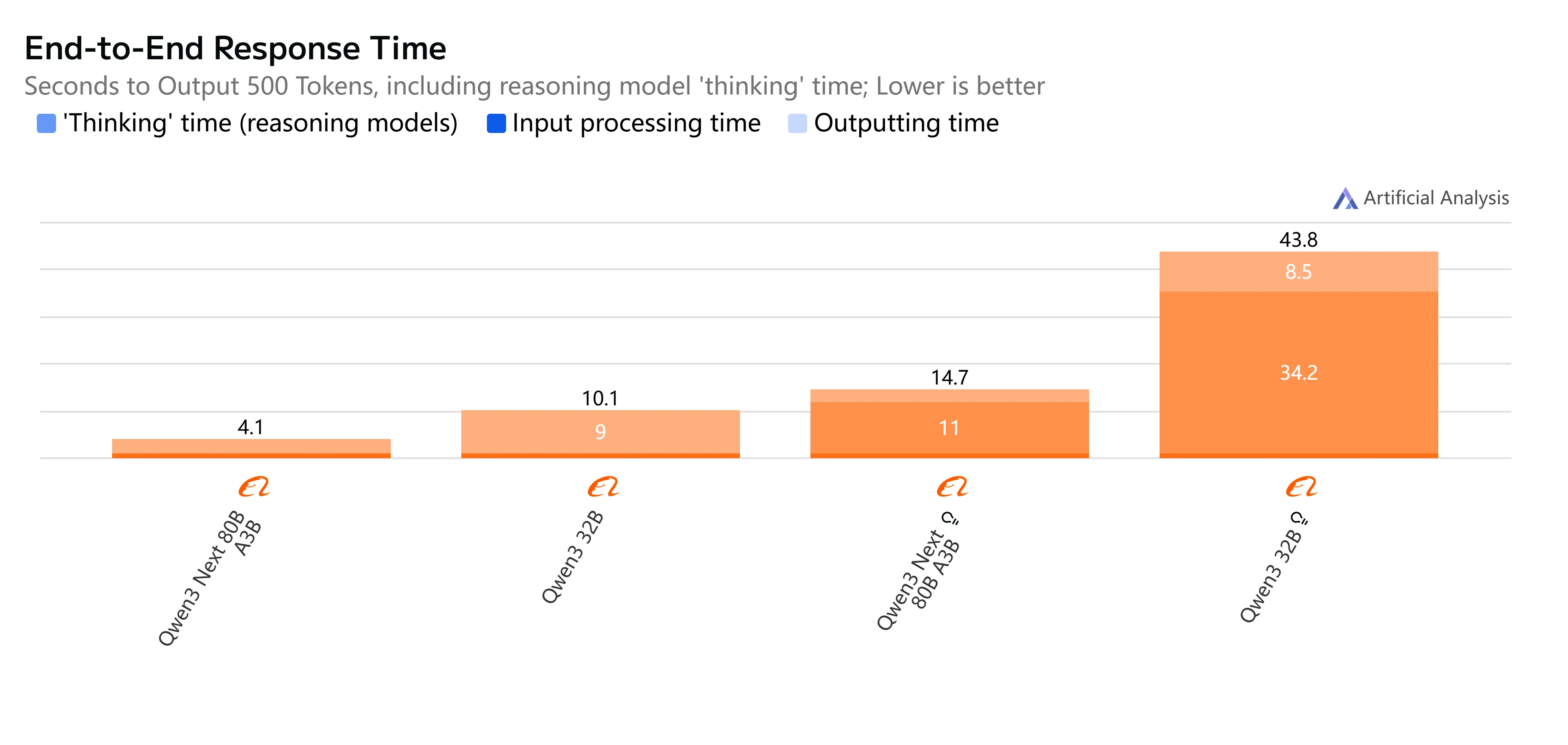
- Qwen3-Next-80B-A3B-Instruct: Быстрый ответ и относительно низкая задержка, генерация 500 токенов вывода занимает чуть более 4 секунд с плавной пропускной способностью, что делает его практичным для интерактивных и задач в реальном времени.
- Qwen3-32B (Non-Thinking): Умеренная общая скорость, с более высокой задержкой около 10 секунд и более медленной генерацией токенов, но все еще подходит для сбалансированных рабочих нагрузок, где важна эффективность.
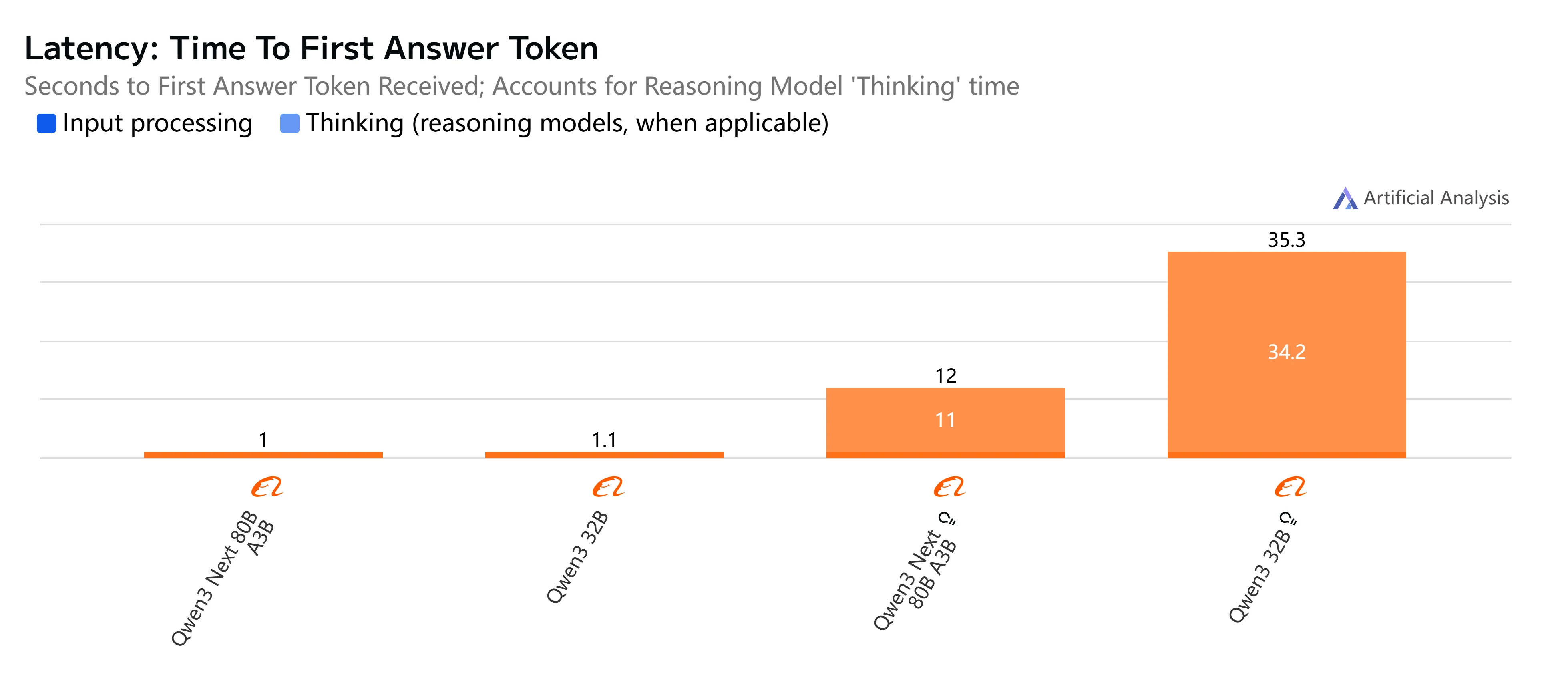
- Qwen3-Next-80B-A3B-Thinking: Заметно медленнее из-за накладных расходов на рассуждение, время end-to-end занимает почти 15 секунд. Однако он обеспечивает большую глубину рассуждений, что делает его более подходящим для решения сложных задач.
- Qwen3-32B (Thinking): Самый медленный вариант, с очень высокой задержкой (более 35 секунд) и ограниченной пропускной способностью. Лучше всего зарезервировать для исследований или сценариев, где продвинутые рассуждения приоритетнее скорости.
Qwen3-Next-80B-A3B vs Qwen3-32B: Варианты использования
Qwen3-32B
1. Повседневная эффективность и опыт работы с ассистентом
- Краткие ответы: Генерирует прямые ответы с меньшим количеством токенов, что делает его экономически эффективным.
- Мозговой штурм и написание текстов: Полезен для креативного черновирования, генерации идей и легких задач по написанию текстов.
- Гибкое рассуждение: Поддерживает переключаемый режим рассуждений, позволяющий получать мгновенные ответы, когда скорость важнее глубины.
2. Программирование и технические задачи
- Поддержка программирования: Обеспечивает надежную генерацию кода и отладку для повседневной разработки.
- Следование инструкциям: Хорошо обрабатывает детализированные запросы благодаря плотной архитектуре.
- Инженерные рабочие процессы: Показывает сильные результаты в решении технических задач и программировании с помощью инструментов.
3. Обработка текста и языковая работа
- Саммаризация: Точно суммирует рассказы и документы, даже на низких уровнях квантования.
- Переписывание и изменение стиля: Преобразует текст в новые форматы или тона, сохраняя исходный смысл.
- Классификация и перевод: Отлично справляется с классификацией неочищенного текста и созданием естественных переводов.
4. Ограничения, о которых стоит знать
- Менее эффективен в задачах с длинным контекстом (теряет связность после ~5K токенов).
- Более высокий уровень галлюцинаций в задачах на рассуждение на основе фактов.
- Ограничен в расширенном креативном написании или извлечении структурированных данных.
Qwen3-Next-80B-A3B
1. Высокая эффективность
- Преимущество разреженной активации: Всего ~3B активных параметров на токен, что снижает затраты и вычислительные ресурсы.
- Прирост пропускной способности: Достигает >10× более высокой пропускной способности вывода на контекстах длиннее 32K.
2. Обработка экстремальных длин контекста
- Оптимизация под длинный контекст: Сохраняет скорость при очень больших длинах контекста (тестировалось до 262K).
- Гибридный дизайн внимания: Сочетает Gated DeltaNet, Gated Attention и линейное внимание для эффективного масштабирования.
- Применения: Идеально подходит для задач с длинными форматами, таких как перевод романов, проверка юридических документов или обработка исследовательских данных.
3. Рассуждение и общий интеллект
- Повседневный LLM: Работает как сильный “главный мозг” для общего использования, с плавной производительностью в режиме Instruct.
- Сила рассуждений: Приближается к Qwen3-235B по логике и дедукции, особенно в узкоспециализированных задачах на решение проблем.
- Режим Thinking: Эффективен для многошаговых рассуждений и оркестрации инструментов.
4. Возможности в программировании и агентных задачах
- Разработка программного обеспечения: Надежен для рефакторинга, генерации тестов и сборки проектов.
- Агентные задачи: Выполняет сложные рабочие процессы с вызовами инструментов и взаимодействием с API.
- Инструменты для разработчиков: Бесшовно интегрируется в IDE с поддержкой редактирования, контроля версий и автоматизации.
5. RAG и интеграция знаний
- Экспертность в RAG: Показывает сильные результаты в задачах RAG, даже с неочищенными или неструктурированными источниками.
- Задачи на знания: Генерирует обоснованные ответы при подключении к внешним базам данных или хранилищам документов.
6. Саммаризация и создание контента
- Саммаризация из нескольких источников: Сокращает новости или длинные документы, добавляя связные комментарии.
- Генерация контента: Универсальна для переписывания и создания расширенных нарративов.
Qwen3-Next-80B-A3B vs Qwen3-32B: Цена
| Модель | Контекстное окно | Максимальный вывод | Цена на вход (/1M токенов) | Цена на вывод (/1M токенов) |
| Qwen3-Next-80B-A3B-Thinking/Instruct | 131K | 32.7K | $0.15 | $1.5 |
| Qwen3-32B (Thinking/Non-Thinking) | 40.9K | 20K | $0.1 | $0.45 |
Все цены на API указаны как доступные на Novita AI
Qwen3-Next-80B-A3B предлагает значительно большее контекстное окно и более высокую пропускную способность вывода, но имеет более высокие затраты на вход и вывод. Qwen3-32B более доступный и эффективный, хотя его длина контекста и лимит генерации значительно меньше.
Как получить доступ к Qwen3-Next-80B-A3B и Qwen3-32B
Novita AI предлагает гибкий доступ к обеим моделям Qwen3-Next-80B-A3B и Qwen3-32B, делая их адаптируемыми для широкого спектра потребностей — от повседневных приложений до продвинутой разработки — с поддержкой нужных инструментов для бесшовного развертывания.
Вариант 1: Использование Playground (Доступно сейчас — не требуется написание кода)
- Моментальный доступ: Зарегистрируйтесь и начните экспериментировать с Qwen3-Next-80B-A3B или Qwen3-32B за несколько секунд.
- Интерактивный интерфейс: Тестируйте запросы и визуализируйте выводы в реальном времени.
- Сравнение моделей: Сравнивайте с другими ведущими моделями для вашего конкретного варианта использования.
Playground позволяет экспериментировать с запросами и просматривать результаты мгновенно, без необходимости технической настройки. Идеально подходит для быстрого прототипирования, тестирования новых идей и изучения возможностей моделей перед полноценным внедрением.
Попробуйте Qwen3-Next-80B-A3B бесплатно сейчас!
Вариант 2: Доступ по API (Для разработчиков)
Подключите Qwen3-Next-80B-A3B или Qwen3-32B к вашим приложениям через REST API Novita AI — получая преимущество 10-кратного увеличения пропускной способности вывода на длинных контекстах без управления инфраструктурой.
Шаг 1: Войдите в систему и получите доступ к библиотеке моделей

Шаг 2: Выберите вашу модель
Просмотрите доступные варианты и выберите модель, подходящую для ваших потребностей.
Шаг 3: Начните бесплатный пробный период
Начните бесплатный пробный период, чтобы изучить возможности выбранной модели.
Шаг 4: Получите ваш API-ключ
Для аутентификации через API мы предоставим вам новый API-ключ. Перейдя на страницу “Настройки аккаунта”, вы можете скопировать API-ключ, как показано на изображении.

Шаг 5: Установите API (Пример на Python для Qwen3-Next-80B-A3B-Thinking) Установите API с помощью менеджера пакетов, соответствующего вашему языку программирования.
После установки импортируйте необходимые библиотеки в вашу среду разработки. Инициализируйте API с вашим API-ключом, чтобы начать взаимодействие с Novita AI LLM. Это пример использования API завершения чата для пользователей Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="your_api_key_here",
)
model = "qwen/qwen3-next-80b-a3b-instruct"
stream = True # or False
max_tokens = 4096
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = {"type": "text"}
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Особенности платформы:
- Совместимый с OpenAI endpoint:
/v3/openaiдля бесшовной интеграции - Гибкие параметры: Управляйте генерацией с помощью температуры, top-p, штрафов и других параметров
- Поддержка потоковой передачи: Выбирайте между потоковыми или пакетными ответами
- Выбор модели: Доступны варианты instruct и thinking
Часто задаваемые вопросы
В чем основная разница между Qwen3-Next-80B-A3B и Qwen3-32B?
Qwen3-Next-80B-A3B — это следующее поколение разреженной модели MoE, оптимизированной для сложных задач и эффективности, в то время как Qwen3-32B — плотная модель, разработанная для сбалансированной производительности и повседневного использования.
Какая из моделей, Qwen3-Next-80B-A3B или Qwen3-32B, лучше обрабатывает входные данные с длинным контекстом?
Qwen3-Next-80B-A3B оптимизирована для экстремальных длин контекста (тестировалось до 262K токенов) и сохраняет высокую скорость при больших масштабах.
Сколько стоит использование Qwen3-Next-80B-A3B по сравнению с Qwen3-32B?
На Novita AI Qwen3-Next-80B-A3B стоит $0.15 за 1M входных токенов и $1.5 за 1M выходных токенов. Между тем Qwen3-32B доступна по цене $0.1 за 1M входных токенов и $0.45 за 1M выходных токенов, что делает ее более доступным вариантом для небольших или чувствительных к стоимости задач.
Novita AI — это универсальная облачная платформа, которая помогает реализовать ваши амбиции в области ИИ. Интегрированные API, бессерверные решения, GPU-инстансы — доступные инструменты, которые вам нужны. Избавьтесь от необходимости управления инфраструктурой, начните бесплатно и воплотите ваше видение ИИ в реальность.



