

A série Qwen3 continua atraindo atenção com sua diversidade de modelos de linguagem grandes, cada um adaptado a diferentes necessidades. Entre eles, o Qwen3-Next-80B-A3B representa a camada de alto nível, equipado com parâmetros massivos e arquitetura avançada para lidar com tarefas de raciocínio e criatividade exigentes. Por outro lado, o Qwen3-32B se destaca como uma opção de porte médio, projetada para equilibrar capacidade e eficiência, permanecendo versátil em cenários práticos. Neste artigo, compararemos o Qwen3-Next-80B-A3B e o Qwen3-32B em várias dimensões importantes para desenvolvedores.
Qwen3-Next-80B-A3B vs Qwen3-32B: Noções Básicas e Benchmark
| Característica | Qwen3-Next-80B-A3B | Qwen3-32B |
| Parâmetros | 80B no total e 3B ativados | 32,8B |
| Arquitetura | Mixure-of-Experts | Densa |
| Janela de Contexto | 262.144 nativamente e extensível até 1.010.000 tokens | 32.768 nativamente e 131.072 tokens com YaRN |
| Variante | Thinking + Non-Thinking | Thinking + Non-Thinking |
| Multimodalidade | Apenas texto | Apenas texto |
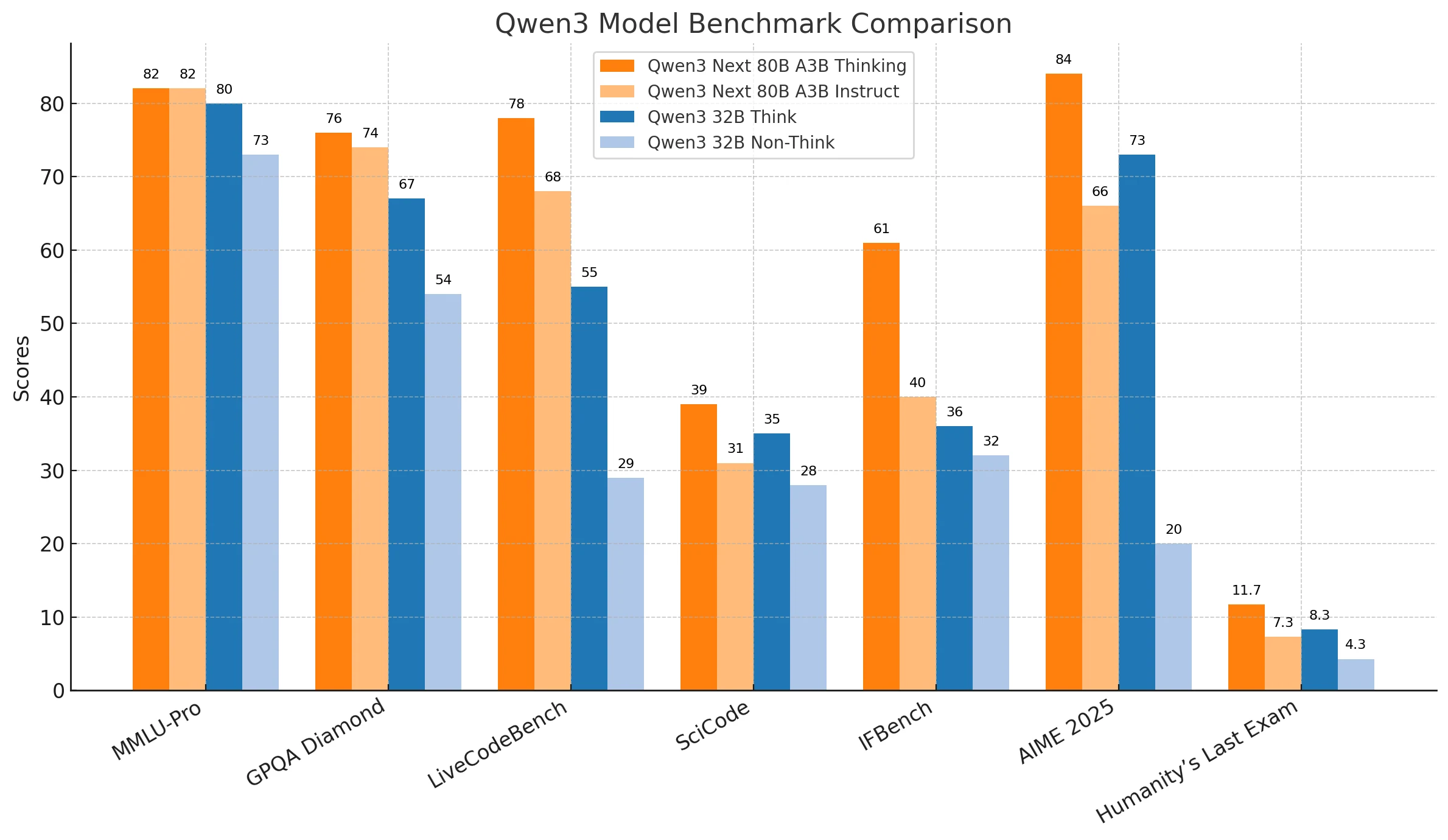
O Qwen3-Next-80B apresenta consistentemente desempenho mais forte em raciocínio complexo, resolução de problemas abstratos e tarefas de alto risco, sendo altamente adequado para aplicações empresariais como pesquisa avançada, tomada de decisão estratégica e implantações de missão crítica. Sua confiabilidade e escalabilidade fazem dele a opção ideal quando precisão e profundidade são inegociáveis.
O Qwen3-32B equilibra eficiência e acessibilidade, se destacando em codificação do dia a dia, automação prática e cenários onde a responsividade importa mais do que a precisão absoluta. É uma solução econômica para organizações que buscam resultados confiáveis sob restrições de recursos ou latência mais rigorosas.
Qwen3-Next-80B-A3B vs Qwen3-32B: Velocidade e Latência
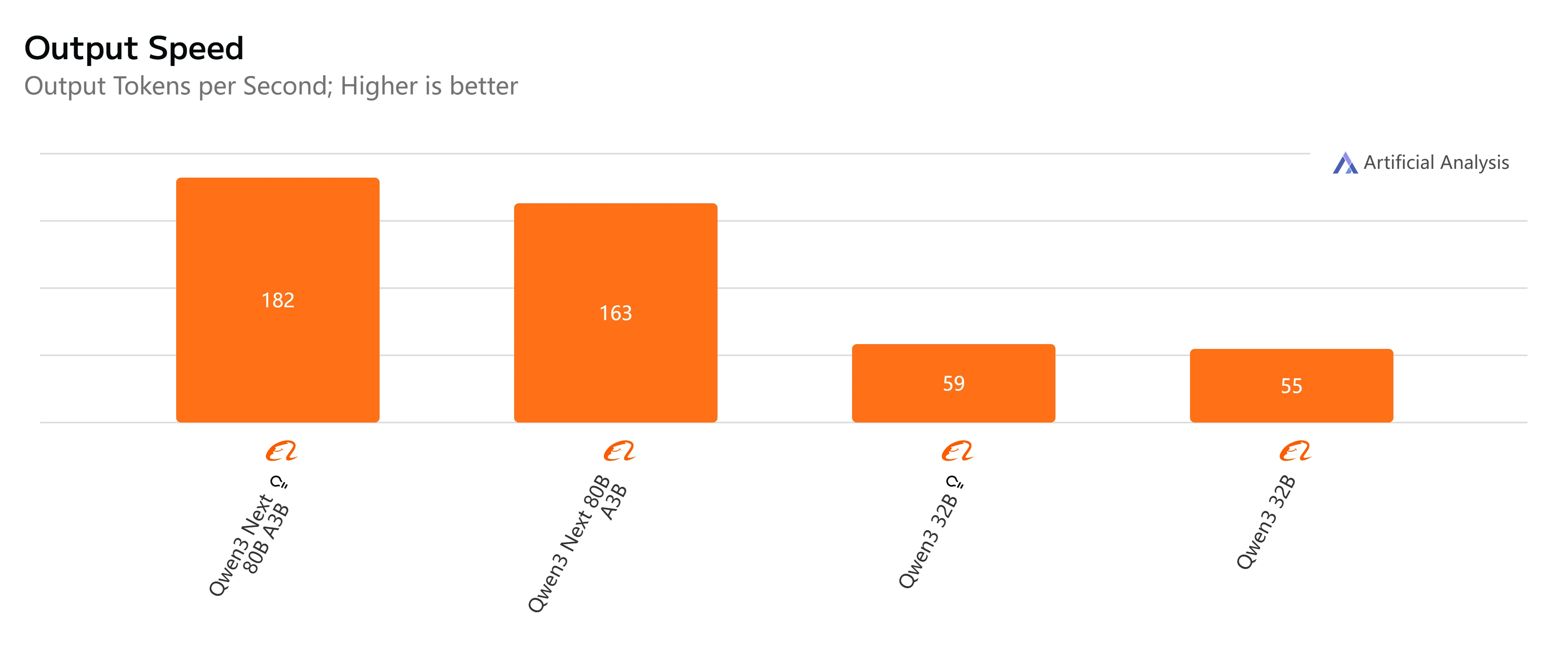
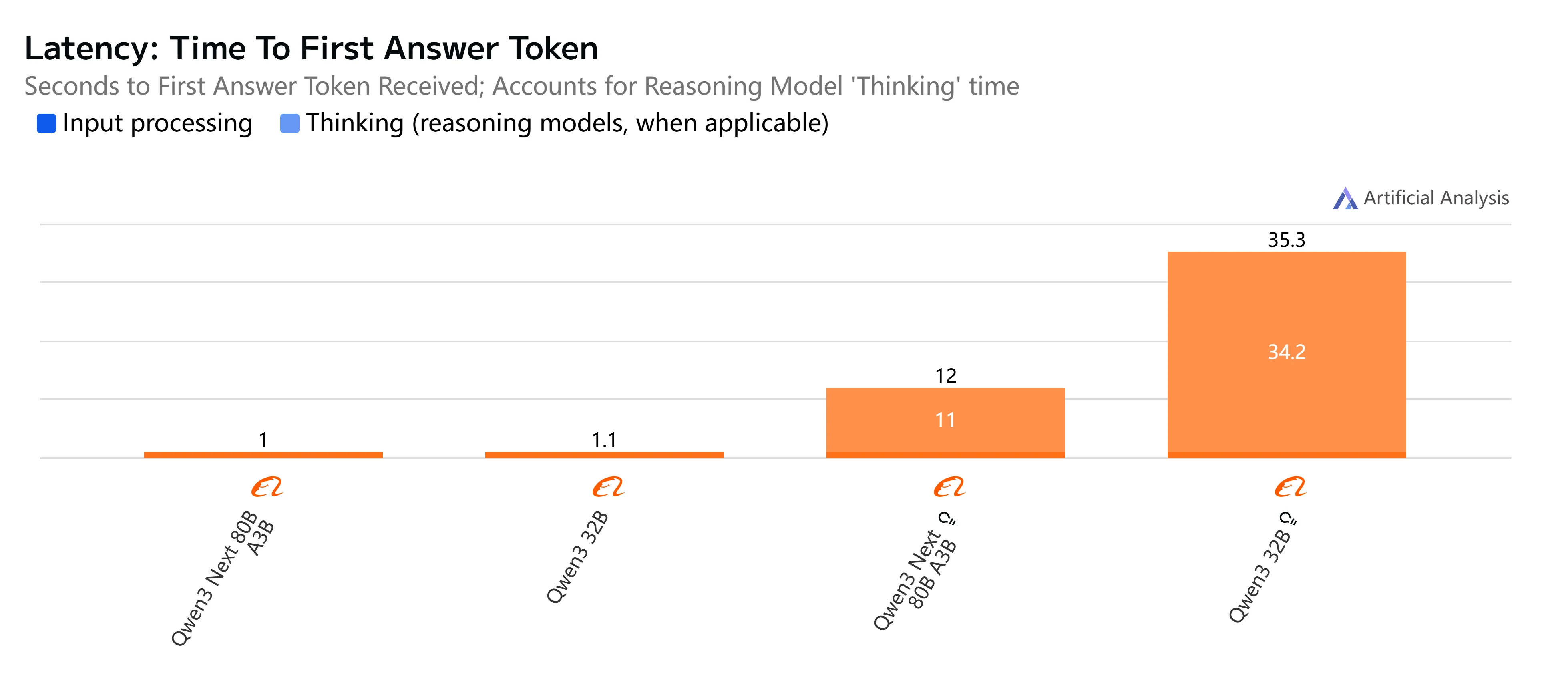
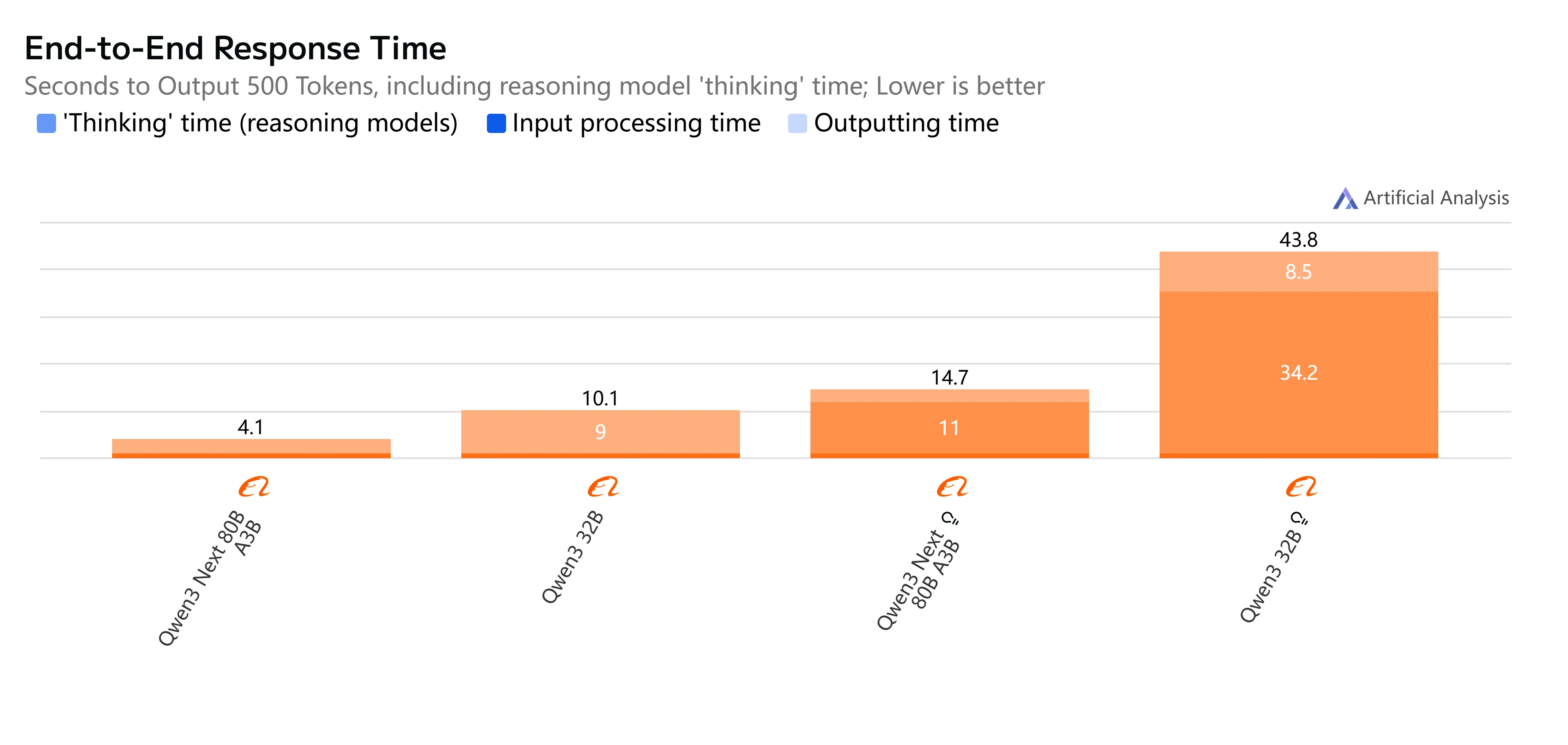
- Qwen3-Next-80B-A3B-Instruct: Resposta rápida e latência relativamente baixa, completando saídas de 500 tokens em pouco mais de 4 segundos com throughput suave, tornando-o prático para tarefas interativas e em tempo real.
- Qwen3-32B (Non-Thinking): Velocidade geral moderada, com latência mais alta por volta de 10 segundos e geração de tokens mais lenta, mas ainda adequado para cargas de trabalho balanceadas onde a eficiência importa.
- Qwen3-Next-80B-A3B-Thinking: Visivelmente mais lento devido ao overhead de raciocínio, levando quase 15 segundos ponta a ponta. No entanto, oferece maior profundidade de raciocínio, sendo melhor para resolução de problemas complexos.
- Qwen3-32B (Thinking): A opção mais lenta, com latência muito alta (mais de 35 segundos) e throughput limitado. Melhor reservado para pesquisa ou cenários onde o raciocínio avançado é priorizado em relação à velocidade.
Qwen3-Next-80B-A3B vs Qwen3-32B: Casos de Uso
Qwen3-32B
1. Eficiência Diária e Experiência de Assistente
- Respostas Concisas: Gera respostas diretas com menos tokens, tornando-o econômico.
- Brainstorming e Redação: Útil para rascunhos criativos, geração de ideias e tarefas de redação leves.
- Pensamento Flexível: Suporta modo de raciocínio alternável, permitindo respostas instantâneas quando a velocidade é mais importante que a profundidade.
2. Codificação e Tarefas Técnicas
- Suporte à Programação: Fornece geração de código e depuração confiáveis para o desenvolvimento do dia a dia.
- Seguimento de Instruções: Lida bem com prompts detalhados graças à sua arquitetura densa.
- Fluxos de Trabalho de Engenharia: Tem desempenho forte na resolução de problemas técnicos e codificação assistida por ferramentas.
3. Processamento de Texto e Trabalho com Linguagem
- Sumarização: Sumariza com precisão histórias e documentos, mesmo em níveis de quantização baixos.
- Reescrita e Reestilização: Transforma texto em novos formatos ou tons, preservando o significado.
- Classificação e Tradução: Se destaca na classificação de texto desorganizado e na produção de traduções naturais.
4. Limites a Observar
- Menos eficaz em tarefas de longo contexto (perde a coerência além de ~5K tokens).
- Taxa de alucinação mais alta em raciocínio baseado em fatos.
- Limitado em redação criativa estendida ou extração de dados estruturados.
Qwen3-Next-80B-A3B
1. Alta Eficiência
- Vantagem de Ativação Esparsa: Apenas ~3B parâmetros ativos por token, reduzindo custo e computação.
- Ganhos de Throughput: Alcança mais de 10× mais throughput de inferência em contextos com mais de 32K.
2. Manipulação de Comprimento Extremo de Contexto
- Otimização de Longo Contexto: Mantém a velocidade em comprimentos de contexto muito altos (testado até 262K).
- Design de Atenção Híbrida: Combina Gated DeltaNet, Gated Attention e atenção linear para escalonamento eficiente.
- Aplicações: Ideal para tarefas de longo formato, como tradução de romances, revisão de documentos jurídicos ou processamento de dados de pesquisa.
3. Raciocínio e Inteligência Geral
- LLM do Dia a Dia: Funciona como um “cérebro principal” forte para uso geral, com desempenho Instruct suave.
- Força de Raciocínio: Se aproxima do Qwen3-235B em lógica e dedução, especialmente na resolução de problemas de nicho.
- Modo Thinking: Eficaz para raciocínio de múltiplas etapas e orquestração de ferramentas.
4. Capacidades de Codificação e Agência
- Desenvolvimento de Software: Confiável para refatoração, geração de testes e construção de projetos.
- Tarefas Agênticas: Executa fluxos de trabalho complexos com chamadas de ferramentas e interações com API.
- Ferramentas para Desenvolvedores: Integra-se suavemente a IDEs com edição, controle de versão e suporte à automação.
5. RAG e Integração de Conhecimento
- Excelência em RAG: Tem desempenho forte em geração aumentada por recuperação, mesmo com fontes desorganizadas ou não estruturadas.
- Tarefas de Conhecimento: Gera respostas fundamentadas quando conectado a bancos de dados externos ou repositórios de documentos.
6. Sumarização e Criação de Conteúdo
- Sumarização de Múltiplas Fontes: Condensa notícias ou documentos longos enquanto adiciona comentários coerentes.
- Geração de Conteúdo: Versátil para reescrita e produção de narrativas estendidas.
Qwen3-Next-80B-A3B vs Qwen3-32B: Preço
| Modelo | Janela de Contexto | Saída Máxima | Preço de Entrada (/1M tokens) | Preço de Saída (/1M tokens) |
| Qwen3-Next-80B-A3B-Thinking/Instruct | 131K | 32,7K | $0,15 | $1,5 |
| Qwen3-32B (Thinking/Non-Thinking) | 40,9K | 20K | $0,1 | $0,45 |
Todos os preços de API estão listados conforme disponíveis na Novita AI
O Qwen3-Next-80B-A3B oferece uma janela de contexto muito maior e capacidade de saída mais alta, mas vem com custos de entrada e saída mais elevados. O Qwen3-32B é mais acessível e eficiente, embora seu comprimento de contexto e limite de geração sejam significativamente menores.
Como Acessar o Qwen3-Next-80B-A3B e o Qwen3-32B
A Novita AI oferece acesso flexível a ambos os modelos, Qwen3-Next-80B-A3B e Qwen3-32B, tornando-os adaptáveis para um amplo espectro de necessidades — de aplicações do dia a dia a desenvolvimento avançado — com as ferramentas certas para implantação sem problemas.
Opção 1: Usar o Playground (Disponível Agora – Sem Necessidade de Código)
- Acesso Instantâneo: Inscreva-se e comece a experimentar o Qwen3-Next-80B-A3B ou o Qwen3-32B em segundos.
- Interface Interativa: Teste prompts e visualize saídas em tempo real.
- Comparação de Modelos: Compare com outros modelos líderes para seu caso de uso específico.
O playground permite que você experimente prompts e visualize resultados instantaneamente, sem necessidade de configuração técnica. É ideal para prototipagem rápida, teste de novas ideias e exploração das capacidades do modelo antes da implementação em escala.
Experimente o Qwen3-Next-80B-A3B gratuitamente agora!
Opção 2: Acesso via API (Para Desenvolvedores)
Conecte o Qwen3-Next-80B-A3B ou o Qwen3-32B aos seus aplicativos por meio da API REST da Novita AI — aproveitando o throughput de inferência 10x maior do modelo em contextos longos, sem precisar gerenciar infraestrutura.
Passo 1: Faça login e acesse a Biblioteca de Modelos

Passo 2: Escolha Seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.
Passo 3: Inicie Seu Teste Gratuito
Comece seu teste gratuito para explorar as capacidades do modelo selecionado.
Passo 4: Obtenha Sua Chave de API
Para autenticar com a API, forneceremos uma nova chave de API. Acessando a página de “Configurações da Conta”, você pode copiar a chave de API conforme indicado na imagem.

Passo 5: Instale a API (Exemplo em Python para Qwen3-Next-80B-A3B-Thinking)
Instale a API usando o gerenciador de pacotes específico para sua linguagem de programação.
Após a instalação, importe as bibliotecas necessárias para seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o LLM da Novita AI. Este é um exemplo de uso da API de conclusão de chat para usuários de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="your_api_key_here",
)
model = "qwen/qwen3-next-80b-a3b-instruct"
stream = True # or False
max_tokens = 4096
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = {"type": "text"}
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Recursos da Plataforma:
- Endpoint compatível com OpenAI:
/v3/openaipara integração perfeita - Parâmetros flexíveis: Controle a geração com temperatura, top-p, penalidades e mais
- Suporte a streaming: Escolha entre respostas de streaming ou em lote
- Seleção de modelo: Acesse variantes instruct e thinking
Perguntas Frequentes
Qual é a principal diferença entre o Qwen3-Next-80B-A3B e o Qwen3-32B?
O Qwen3-Next-80B-A3B é um modelo MoE esparso de próxima geração otimizado para tarefas complexas e eficiência, enquanto o Qwen3-32B é um modelo denso projetado para desempenho equilibrado e uso do dia a dia.
Qual modelo, Qwen3-Next-80B-A3B ou Qwen3-32B, lida melhor com entradas de contexto longo?
O Qwen3-Next-80B-A3B é otimizado para comprimentos de contexto extremos (testado até 262K tokens) e mantém alta velocidade em escala.
Quanto custa usar o Qwen3-Next-80B-A3B em comparação com o Qwen3-32B?
Na Novita AI, o Qwen3-Next-80B-A3B é precificado em $0,15 por 1M de tokens de entrada e $1,5 por 1M de tokens de saída. Enquanto isso, o Qwen3-32B está disponível por $0,1 por 1M de tokens de entrada e $0,45 por 1M de tokens de saída, tornando-o uma opção mais acessível para tarefas de menor escala ou sensíveis a custos.
Novita AI é a plataforma cloud all-in-one que potencializa suas ambições de IA. APIs integradas, serverless, Instância de GPU — as ferramentas econômicas que você precisa. Elimine a infraestrutura, comece gratuitamente e torne sua visão de IA realidade.



