

The Qwen3 series continues to attract attention with its diverse range of large language models, each tailored to different needs. Among them, Qwen3-Next-80B-A3B represents the high-end tier, equipped with massive parameters and advanced architecture to handle demanding reasoning and creative tasks. On the other hand, Qwen3-32B stands as a mid-sized option, designed to balance capability and efficiency while remaining versatile across practical scenarios. In this article, we’ll compare Qwen3-Next-80B-A3B and Qwen3-32B across several dimensions important to developers
Qwen3-Next-80B-A3B vs Qwen3-32B: Basics and Benchmark
| Feature | Qwen3-Next-80B-A3B | Qwen3-32B |
| Parameter | 80B in total and 3B activated | 32.8B |
| Architecture | Mixure-of-Experts | Dense |
| Context Window | 262,144 natively and extensible up to 1,010,000 tokens | 32,768 natively and 131,072 tokens with YaRN |
| Varient | Thinking + Instruct | Thinking + Non-Thinking |
| Multimodality | Text-only | Text-only |
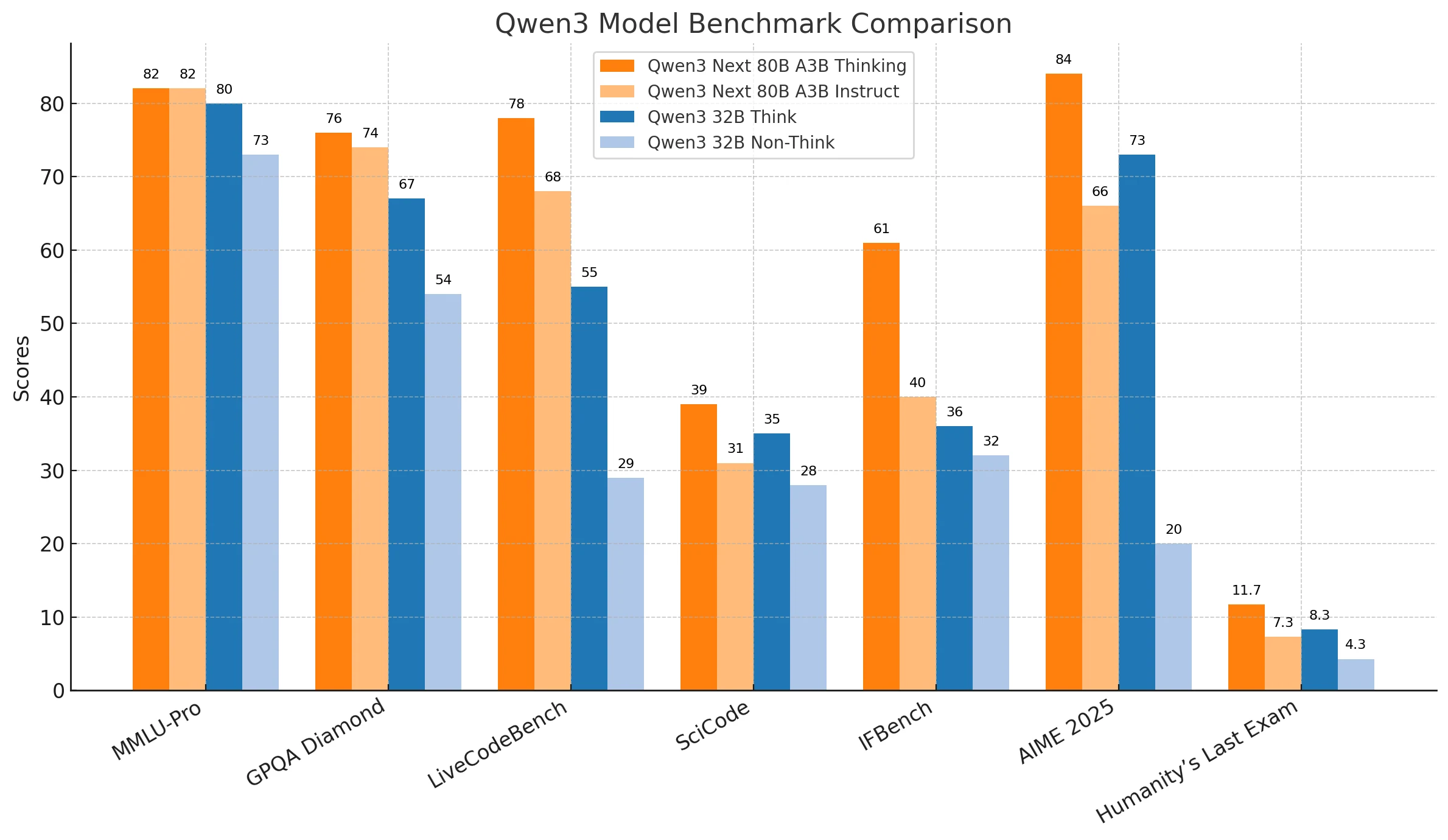
Qwen3-Next-80B consistently shows stronger performance in complex reasoning, abstract problem-solving, and high-stakes tasks, making it highly suitable for enterprise applications such as advanced research, strategic decision-making, and mission-critical deployments. Its reliability and scalability make it the go-to option when precision and depth are non-negotiable.
Qwen3-32B strikes a balance between efficiency and affordability, excelling in everyday coding, practical automation, and scenarios where responsiveness matters more than absolute accuracy. It is a cost-effective solution for organizations seeking reliable results under tighter resource or latency constraints.
Qwen3-Next-80B-A3B vs Qwen3-32B: Speed and Latency
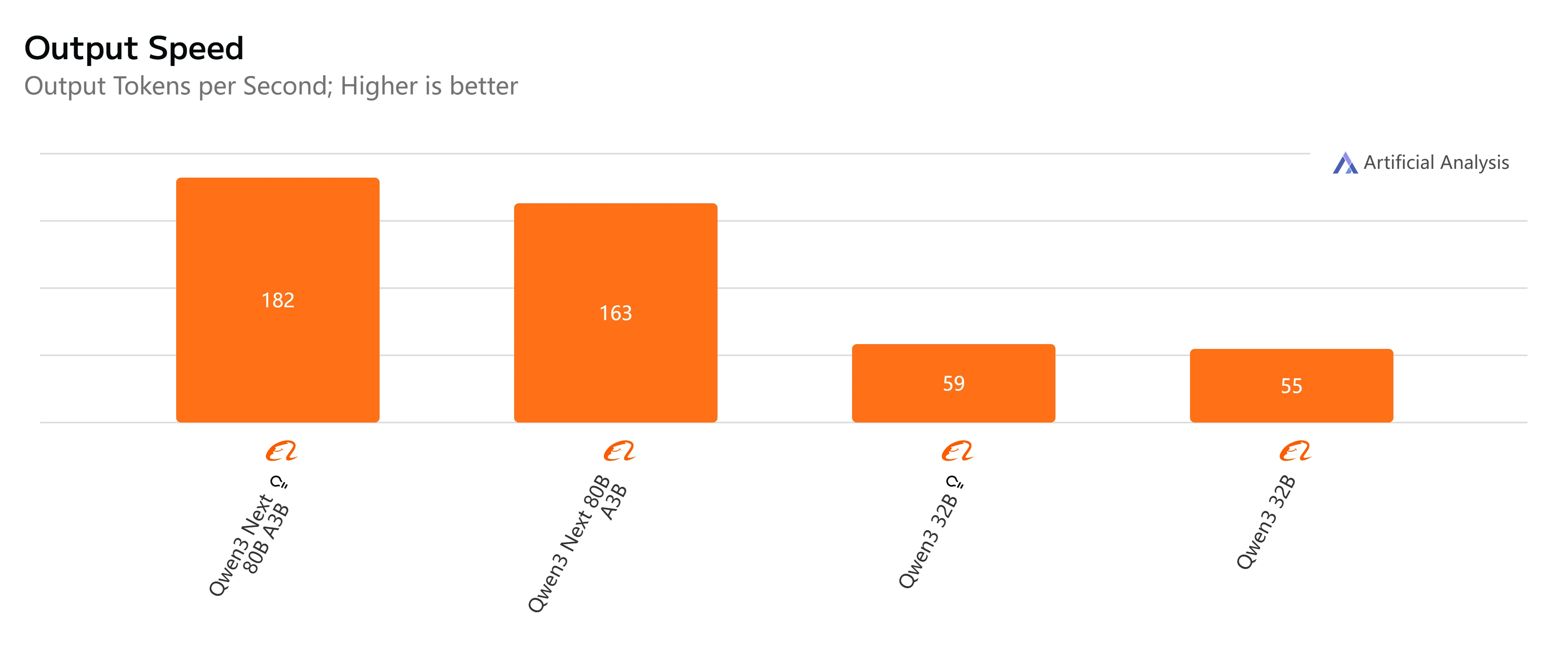
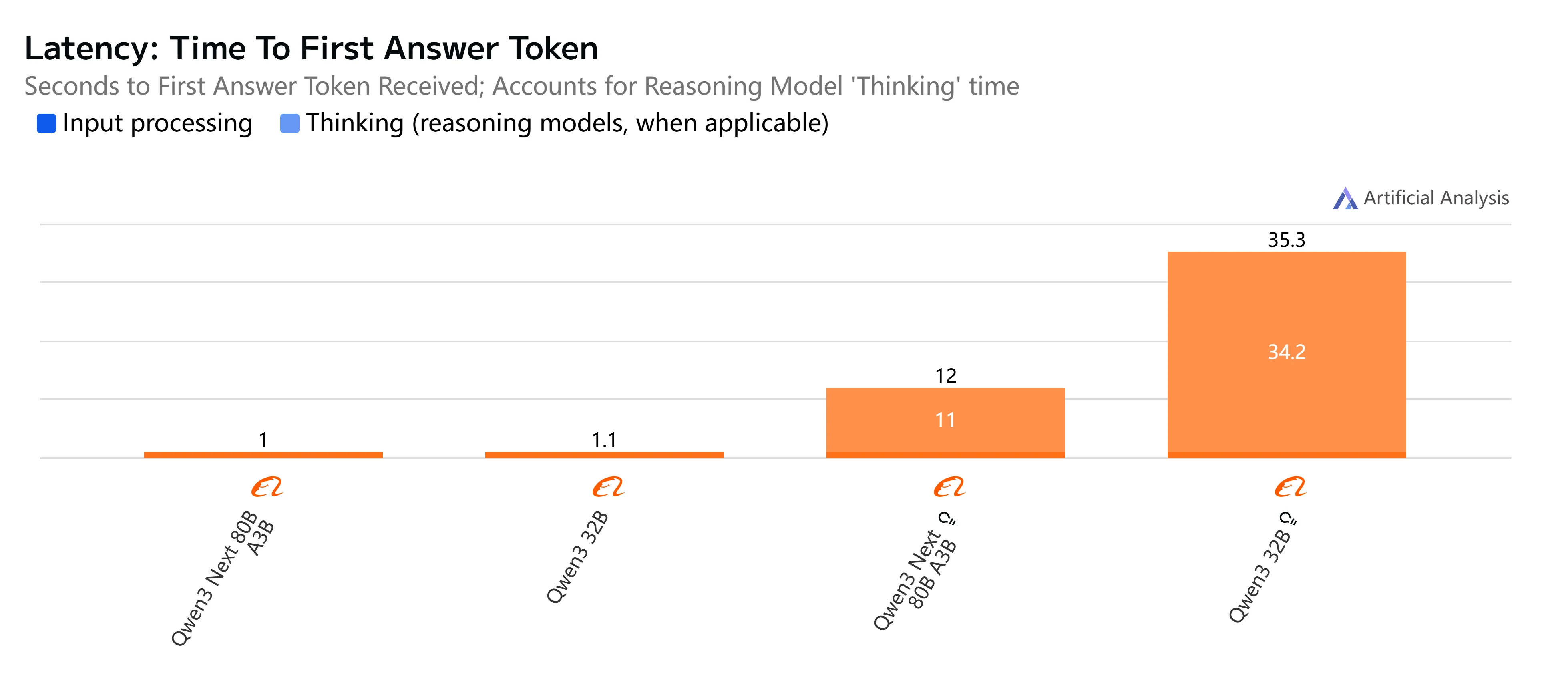
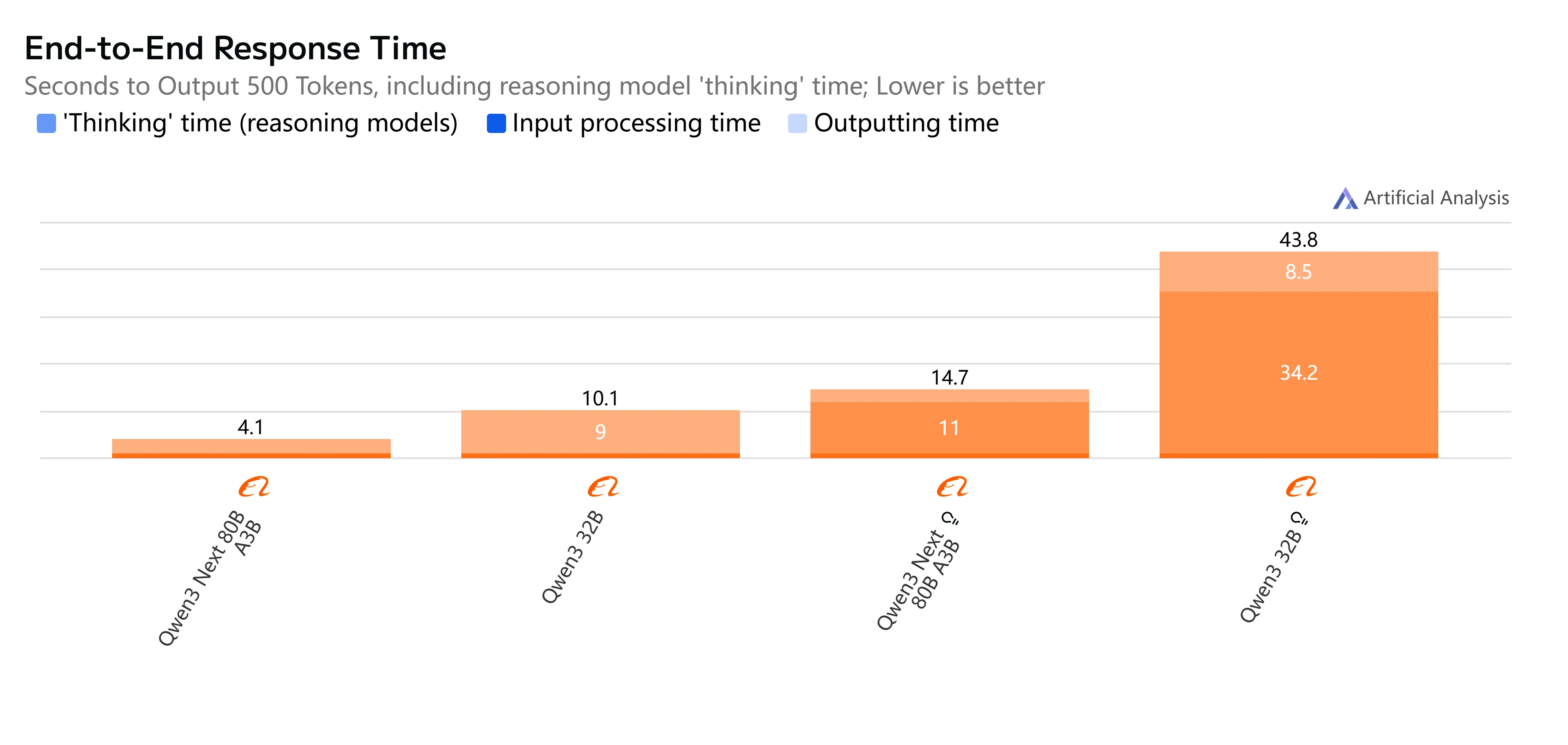
- Qwen3-Next-80B-A3B-Instruct: Fast response and relatively low latency, completing 500-token outputs in just over 4 seconds with smooth throughput, making it practical for interactive and real-time tasks.
- Qwen3-32B (Non-Thinking): Moderate overall speed, with higher latency around 10 seconds and slower token generation, but still suitable for balanced workloads where efficiency matters.
- Qwen3-Next-80B-A3B-Thinking: Noticeably slower due to reasoning overhead, taking nearly 15 seconds end-to-end. However, it delivers stronger reasoning depth, making it better for complex problem-solving.
- Qwen3-32B (Thinking): The slowest option, with very high latency (over 35 seconds) and limited throughput. Best reserved for research or scenarios where advanced reasoning is prioritized over speed.
Qwen3-Next-80B-A3B vs Qwen3-32B: Use Cases
Qwen3-32B
1. Daily Efficiency and Assistant Experience
- Concise Responses: Generates direct answers with fewer tokens, making it cost-effective.
- Brainstorming & Writing: Useful for creative drafting, idea generation, and lightweight writing tasks.
- Flexible Thinking: Supports toggleable reasoning mode, allowing instant answers when speed is more important than depth.
2. Coding and Technical Tasks
- Programming Support: Provides dependable code generation and debugging for everyday development.
- Instruction Following: Handles detailed prompts well thanks to dense architecture.
- Engineering Workflows: Performs strongly in technical problem solving and tool-assisted coding.
3. Text Processing and Language Work
- Summarization: Accurately summarizes stories and documents, even at low quantization levels.
- Rewriting & Restyling: Transforms text into new formats or tones while preserving meaning.
- Classification & Translation: Excels at classifying messy text and producing natural translations.
4. Boundaries to Note
- Less effective in long-context tasks (loses coherence beyond ~5K tokens).
- Higher hallucination rate in fact-based reasoning.
- Limited in extended creative writing or structured data extraction.
Qwen3-Next-80B-A3B
1. High-Efficiency
- Sparse Activation Advantage: Only ~3B active parameters per token, reducing cost and compute.
- Throughput Gains: Achieves >10× higher inference throughput on contexts longer than 32K.
2. Extreme Context Length Handling
- Long Context Optimization: Maintains speed at very high context lengths (tested up to 262K).
- Hybrid Attention Design: Combines Gated DeltaNet, Gated Attention, and linear attention for efficient scaling.
- Applications: Ideal for long-form tasks such as novel translation, legal document review, or research data processing.
3. Reasoning and General Intelligence
- Everyday LLM: Works as a strong “main brain” for general use, with smooth Instruct performance.
- Reasoning Strength: Approaches Qwen3-235B in logic and deduction, especially in niche problem-solving.
- Thinking Mode: Effective for multi-step reasoning and tool orchestration.
4. Coding and Agentic Capabilities
- Software Development: Reliable for refactoring, test generation, and project building.
- Agentic Tasks: Executes complex workflows with tool calls and API interactions.
- Developer Tools: Integrates smoothly into IDEs with editing, version control, and automation support.
5. RAG and Knowledge Integration
- RAG Excellence: Performs strongly in retrieval-augmented generation, even with messy or unstructured sources.
- Knowledge Tasks: Generates grounded answers when connected to external databases or document stores.
6. Summarization and Content Creation
- Multi-Source Summarization: Condenses news or long documents while adding coherent commentary.
- Content Generation: Versatile for rewriting and producing extended narratives.
Qwen3-Next-80B-A3B vs Qwen3-32B: Price
| Model | Context Window | Max Output | Input Price (/1M tokens) | Output Price (/1M tokens) |
| Qwen3-Next-80B-A3B-Thinking/Instruct | 131K | 32.7K | $0.15 | $1.5 |
| Qwen3-32B (Thinking/Non-Thinking) | 40.9K | 20K | $0.1 | $0.45 |
All API prices are listed as available on Novita AI
Qwen3-Next-80B-A3B offers a much larger context window and higher output capacity, but comes with higher input and output costs. Qwen3-32B is more affordable and efficient, though its context length and generation limit are significantly smaller.
How to Access Qwen3-Next-80B-A3B and Qwen3-32B
Novita AI offers flexible access to both Qwen3-Next-80B-A3B and Qwen3-32B, making them adaptable for a wide spectrum of needs—from everyday applications to advanced development—backed by the right tools for seamless deployment.
Option 1: Use the Playground (Available Now – No Coding Required)
- Instant Access: Sign up and start experimenting with Qwen3-Next-80B-A3B or Qwen3-32B in seconds.
- Interactive Interface: Test prompts and visualize outputs in real-time.
- Model Comparison: Compare with other leading models for your specific use case.
The playground lets you experiment with prompts and view results instantly, with no technical setup required. It’s ideal for rapid prototyping, testing new ideas, and exploring model capabilities before full-scale implementation.
Try Qwen3-Next-80B-A3B for Free Now !
Option 2: API Access (For Developers)
Connect Qwen3-Next-80B-A3B or Qwen3-32B to your applications through Novita AI’s REST API—benefiting from the model’s 10x inference throughput on long contexts without managing infrastructure.
Step 1: Log In and Access the Model Library

Step 2: Choose Your Model
Browse through the available options and select the model that suits your needs.
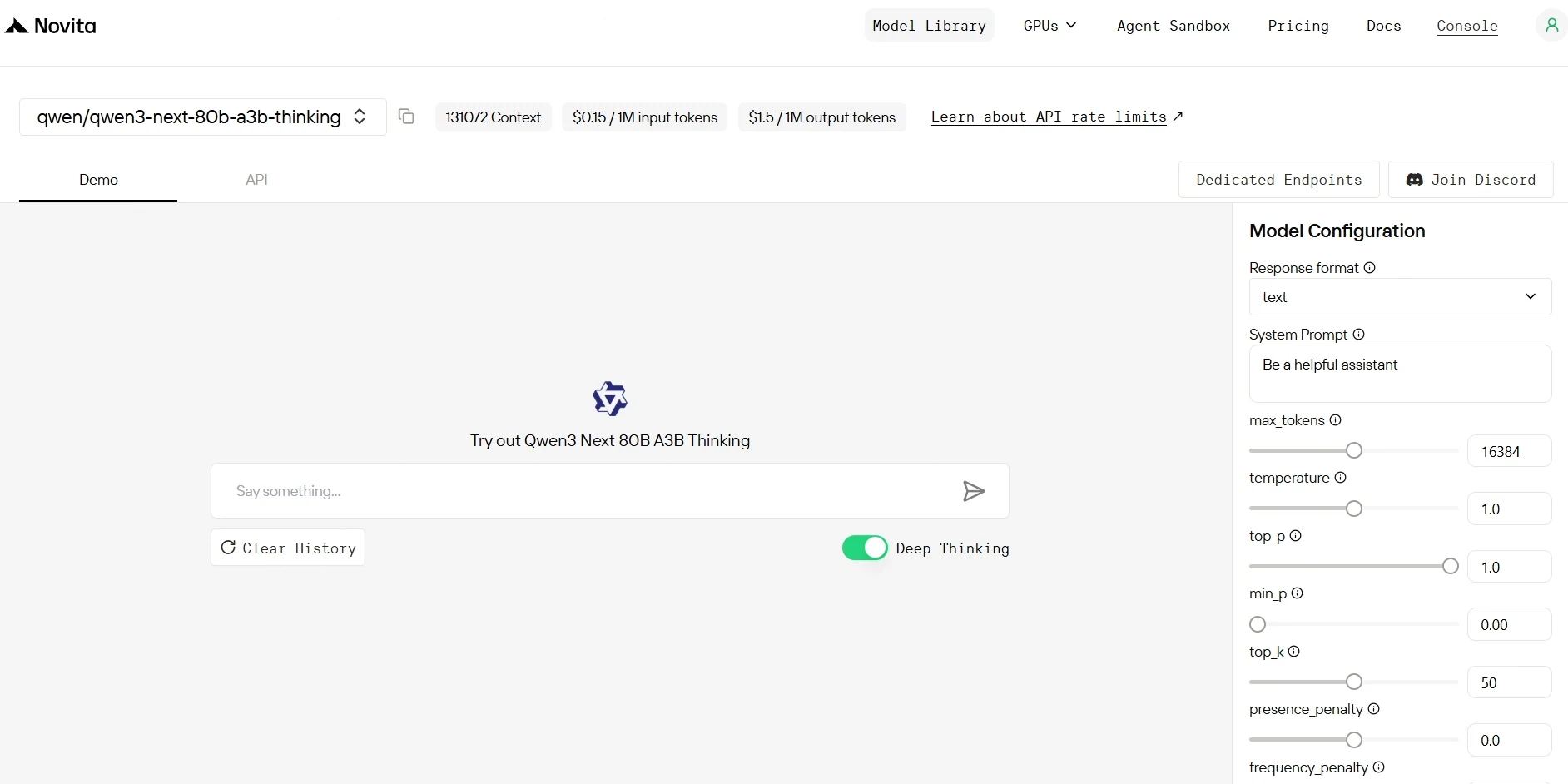
Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.
Step 4: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Account Settings” page, you can copy the API key as indicated in the image.

Step 5: Install the API (Python Example for Qwen3-Next-80B-A3B-Thinking)
Install API using the package manager specific to your programming language.
After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for python users.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="your_api_key_here",
)
model = "qwen/qwen3-next-80b-a3b-instruct"
stream = True # or False
max_tokens = 4096
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = {"type": "text"}
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)Platform Features:
- OpenAI-compatible endpoint:
/v3/openaifor seamless integration - Flexible parameters: Control generation with temperature, top-p, penalties, and more
- Streaming support: Choose between streaming or batch responses
- Model selection: Access both instruct and thinking variants
Frequently Asked Questions
What is the main difference between Qwen3-Next-80B-A3B and Qwen3-32B?
Qwen3-Next-80B-A3B is a next-generation sparse MoE model optimized for complex tasks and efficiency, while Qwen3-32B is a dense model designed for balanced performance and everyday use.
Which model, Qwen3-Next-80B-A3B or Qwen3-32B, handles long context inputs better?
Qwen3-Next-80B-A3B is optimized for extreme context lengths (tested up to 262K tokens) and maintains high speed at scale.
How much does it cost to use Qwen3-Next-80B-A3B vs Qwen3-32B?
On Novita AI, Qwen3-Next-80B-A3B is priced at $0.15 per 1M input tokens and $1.5 per 1M output tokens. Meanwhile, Qwen3-32B is available at $0.1 per 1M input tokens and $0.45 per 1M output tokens, making it a more affordable option for smaller-scale or cost-sensitive tasks.
Novita AI is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance — the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.



