

Die Qwen3-Serie zieht weiterhin Aufmerksamkeit auf sich mit ihrer vielfältigen Auswahl an großen Sprachmodellen, die jeweils auf unterschiedliche Anforderungen zugeschnitten sind. Darunter repräsentiert Qwen3-Next-80B-A3B die High-End-Klasse, ausgestattet mit massiven Parametern und fortschrittlicher Architektur für anspruchsvolle Reasoning- und kreative Aufgaben. Andererseits steht Qwen3-32B als mittelgroße Option zur Verfügung, die darauf ausgelegt ist, Leistung und Effizienz in Einklang zu bringen und gleichzeitig vielseitig in praktischen Szenarien einsetzbar zu sein. In diesem Artikel vergleichen wir Qwen3-Next-80B-A3B und Qwen3-32B in mehreren für Entwickler relevanten Dimensionen.
Qwen3-Next-80B-A3B vs Qwen3-32B: Grundlagen und Benchmarks
| Merkmal | Qwen3-Next-80B-A3B | Qwen3-32B |
| Parameter | 80B insgesamt und 3B aktiviert | 32,8B |
| Architektur | Mixure-of-Experts | Dense |
| Kontextfenster | 262.144 nativ und erweiterbar auf bis zu 1.010.000 Token | 32.768 nativ und 131.072 Token mit YaRN |
| Variante | Thinking + Instruct | Thinking + Non-Thinking |
| Multimodalität | Nur Text | Nur Text |
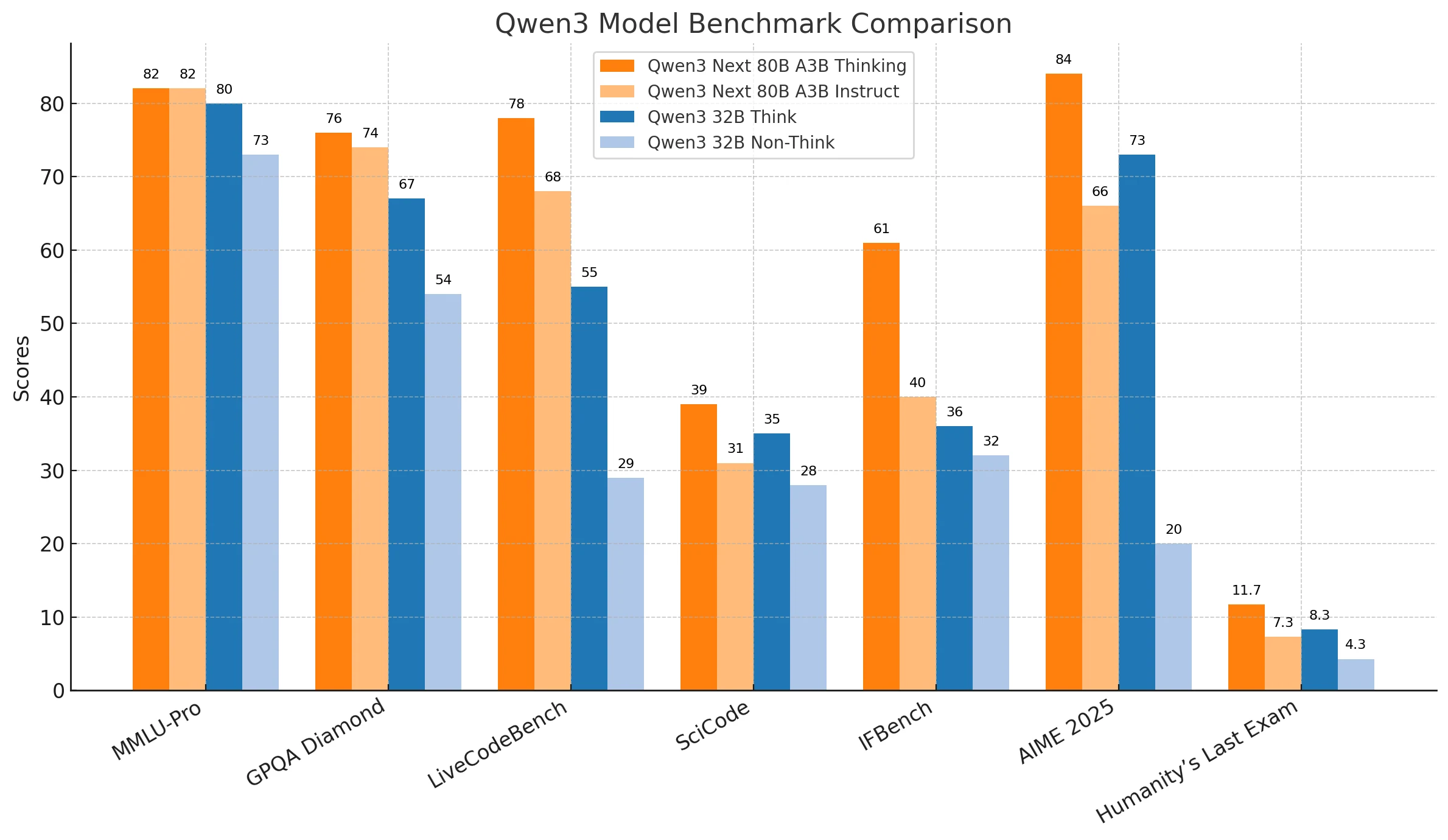
Qwen3-Next-80B zeigt durchgehend stärkere Leistung bei komplexen Reasoning-Aufgaben, abstrakter Problemlösung und kritischen Aufgaben, was es besonders geeignet für Unternehmensanwendungen wie fortgeschrittene Forschung, strategische Entscheidungsfindung und missionskritische Bereitstellungen macht. Seine Zuverlässigkeit und Skalierbarkeit machen es zur ersten Wahl, wenn Präzision und Tiefe unabdingbar sind.
Qwen3-32B schafft eine Balance zwischen Effizienz und Erschwinglichkeit, glänzt bei alltäglichen Programmieraufgaben, praktischer Automatisierung und Szenarien, in denen Reaktionsfähigkeit wichtiger ist als absolute Genauigkeit. Es ist eine kosteneffektive Lösung für Organisationen, die zuverlässige Ergebnisse unter engeren Ressourcen- oder Latenzbeschränkungen suchen.
Qwen3-Next-80B-A3B vs Qwen3-32B: Geschwindigkeit und Latenz
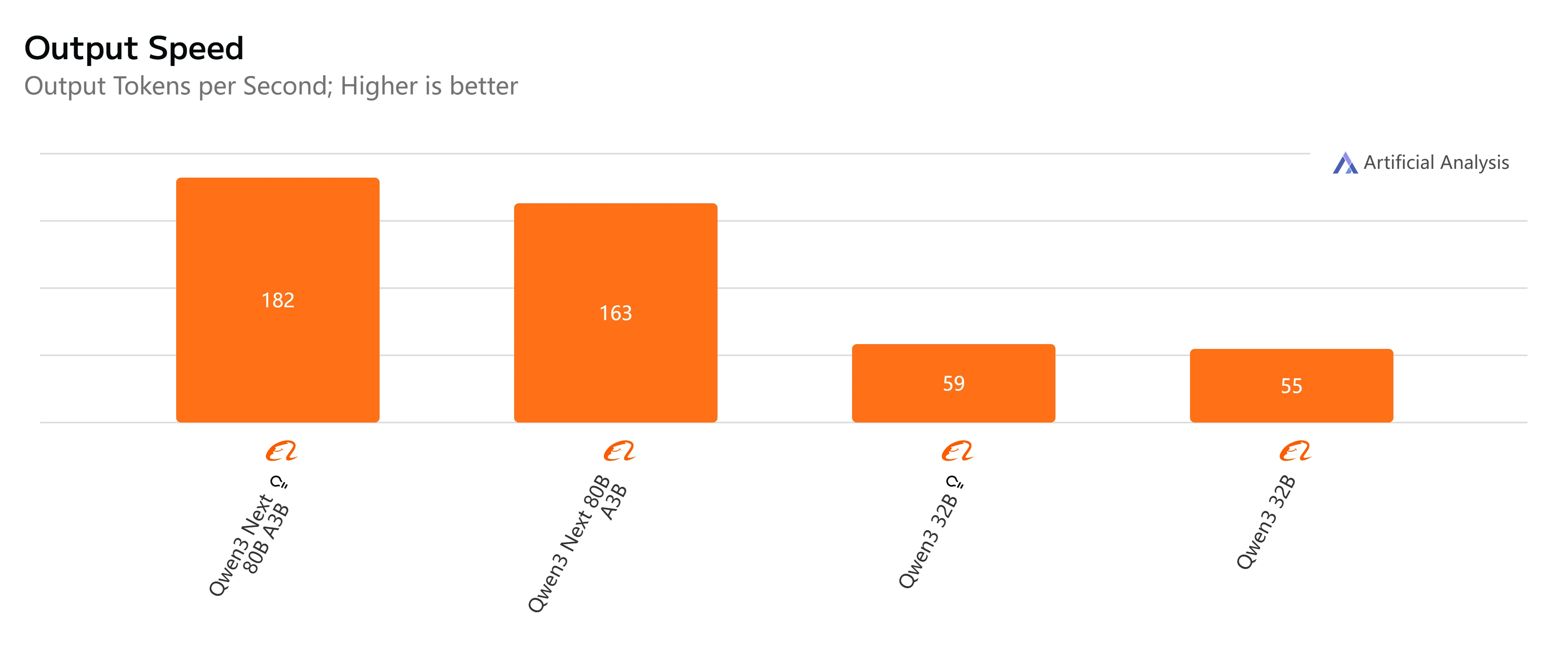
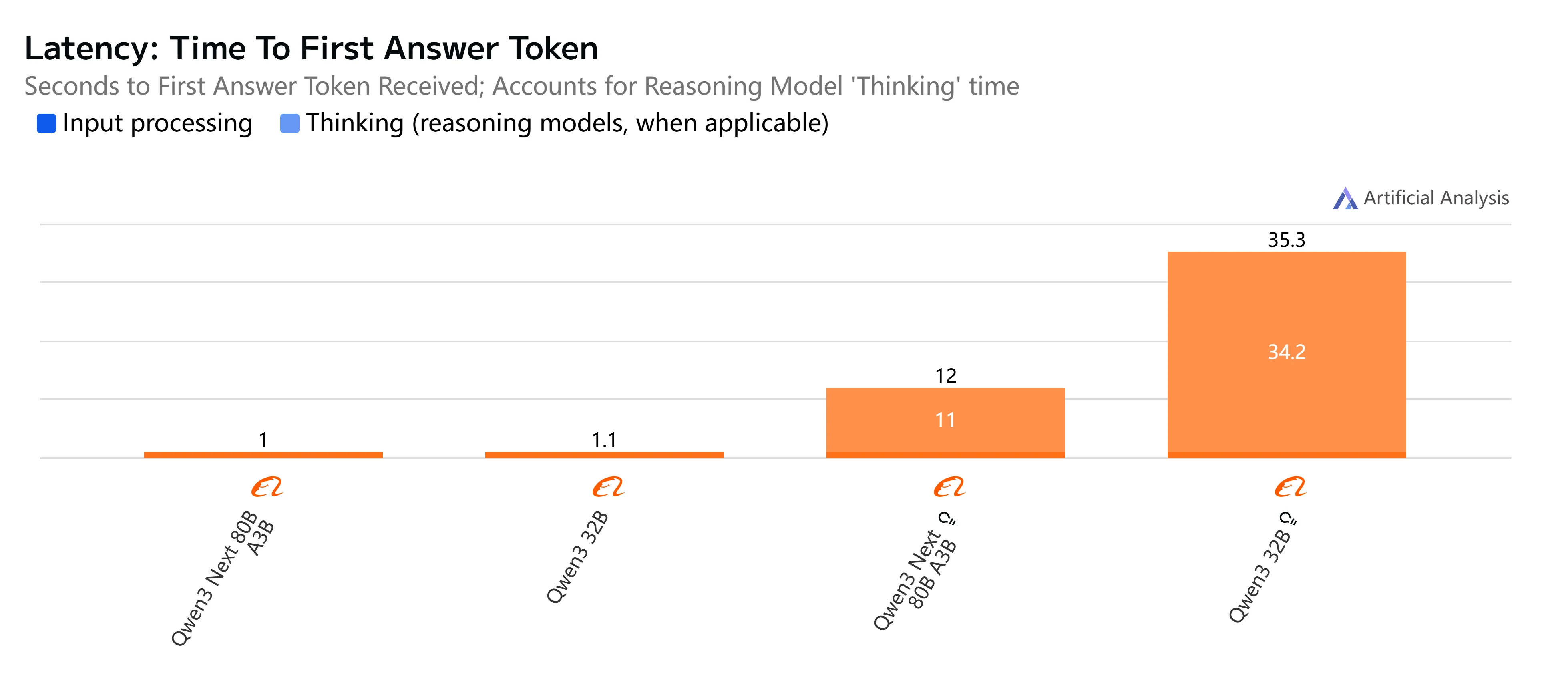
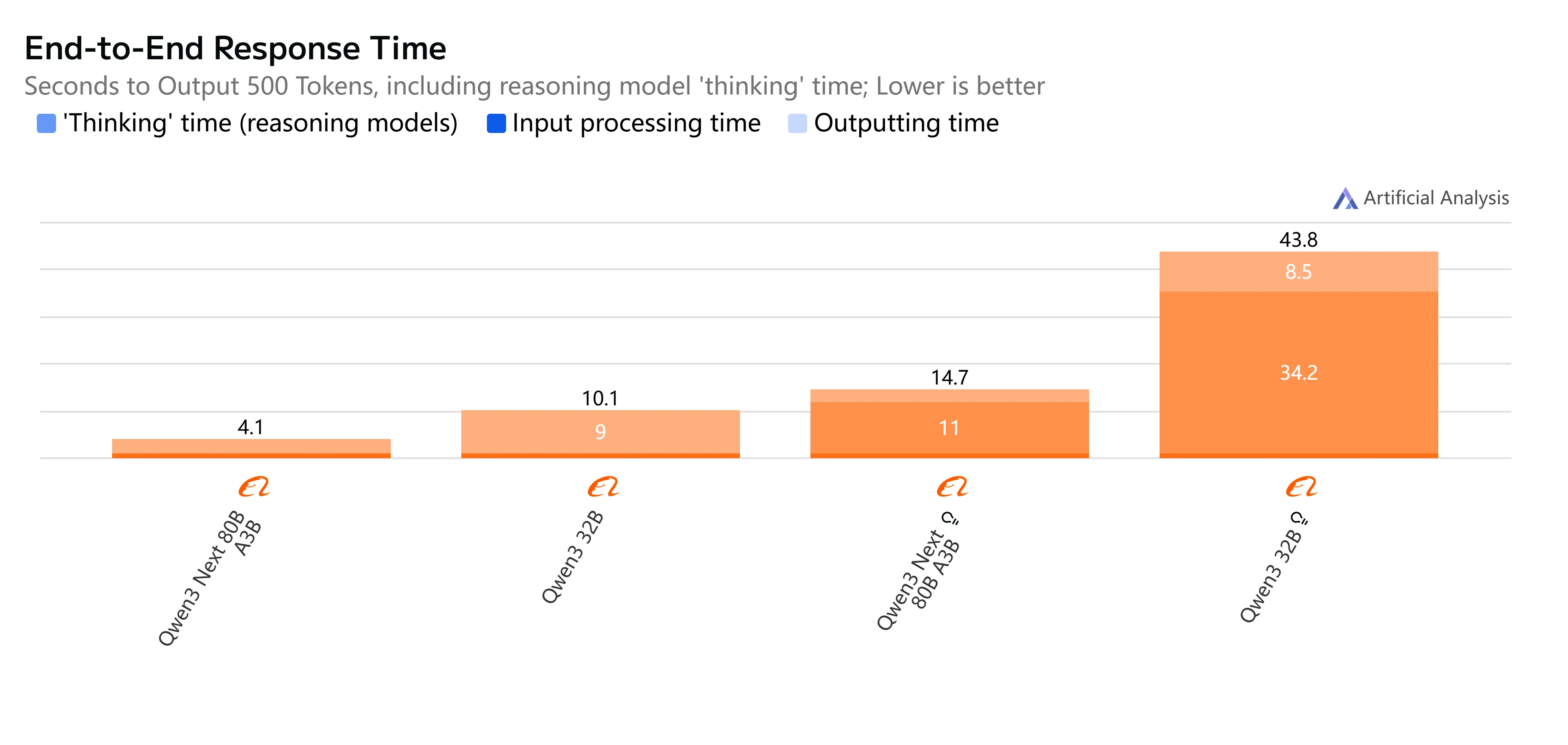
- Qwen3-Next-80B-A3B-Instruct: Schnelle Antwort und relativ niedrige Latenz, generiert 500-Token-Ausgaben in etwas über 4 Sekunden mit gleichmäßigem Durchsatz, was es praktisch für interaktive und Echtzeitaufgaben macht.
- Qwen3-32B (Non-Thinking): Moderate Gesamtgeschwindigkeit, mit höherer Latenz von etwa 10 Sekunden und langsamerer Token-Generierung, aber dennoch geeignet für ausgewogene Arbeitslasten, bei denen Effizienz wichtig ist.
- Qwen3-Next-80B-A3B-Thinking: Deutlich langsamer aufgrund von Reasoning-Overhead, benötigt fast 15 Sekunden End-to-End. Liefert jedoch eine stärkere Reasoning-Tiefe, was es besser für komplexe Problemlösungen macht.
- Qwen3-32B (Thinking): Die langsamste Option, mit sehr hoher Latenz (über 35 Sekunden) und begrenztem Durchsatz. Am besten für Forschung oder Szenarien reserviert, in denen fortgeschrittenes Reasoning Vorrang vor Geschwindigkeit hat.
Qwen3-Next-80B-A3B vs Qwen3-32B: Anwendungsfälle
Qwen3-32B
1. Tägliche Effizienz und Assistenz-Erlebnis
- Präzise Antworten: Generiert direkte Antworten mit weniger Token, was es kosteneffektiv macht.
- Brainstorming & Schreiben: Nützlich für kreative Entwürfe, Ideengenerierung und leichte Schreibaufgaben.
- Flexibles Reasoning: Unterstützt einen umschaltbaren Reasoning-Modus, der sofortige Antworten ermöglicht, wenn Geschwindigkeit wichtiger ist als Tiefe.
2. Programmierung und technische Aufgaben
- Programmierunterstützung: Bietet zuverlässige Codegenerierung und Debugging für die alltägliche Entwicklung.
- Anweisungsbefolgung: Verarbeitet detaillierte Prompts gut dank der dichten Architektur.
- Entwicklungsworkflows: Leistet stark bei technischer Problemlösung und toolgestützter Programmierung.
3. Textverarbeitung und Sprachaufgaben
- Zusammenfassung: Fasst Geschichten und Dokumente genau zusammen, selbst bei niedrigen Quantisierungsstufen.
- Umschreiben & Neugestaltung: Transformiert Text in neue Formate oder Töne, während die Bedeutung erhalten bleibt.
- Klassifizierung & Übersetzung: Glänzt bei der Klassifizierung von unstrukturiertem Text und der Erstellung natürlicher Übersetzungen.
4. Zu beachtende Grenzen
- Weniger effektiv bei Langkontext-Aufgaben (verliert den Zusammenhang ab ~5K Token).
- Höhere Halluzinationsrate bei faktengestütztem Reasoning.
- Begrenzt bei langem kreativem Schreiben oder Extraktion strukturierter Daten.
Qwen3-Next-80B-A3B
1. Hohe Effizienz
- Vorteil der Sparse-Aktivierung: Nur ~3B aktive Parameter pro Token, was Kosten und Rechenleistung reduziert.
- Durchsatzsteigerungen: Erzielt einen >10-fach höheren Inferenz-Durchsatz bei Kontexten länger als 32K.
2. Verarbeitung extrem langer Kontextlängen
- Langkontext-Optimierung: Behält die Geschwindigkeit bei sehr hohen Kontextlängen (getestet bis 262K).
- Hybrides Aufmerksamkeitsdesign: Kombiniert Gated DeltaNet, Gated Attention und lineare Aufmerksamkeit für effiziente Skalierung.
- Anwendungen: Ideal für langformatige Aufgaben wie Romanübersetzung, Prüfung von Rechtsdokumenten oder Verarbeitung von Forschungsdaten.
3. Reasoning und allgemeine Intelligenz
- Alltags-LLM: Dient als leistungsstarkes „Hauptgehirn" für den allgemeinen Einsatz, mit reibungsloser Instruct-Leistung.
- Reasoning-Stärke: Kommt Qwen3-235B in Logik und Deduktion nahe, insbesondere bei der Problemlösung in Nischenbereichen.
- Thinking-Modus: Effektiv für mehrstufiges Reasoning und Tool-Orchestrierung.
4. Programmier- und Agentenfähigkeiten
- Softwareentwicklung: Zuverlässig für Refactoring, Testgenerierung und Projektaufbau.
- Agentenaufgaben: Führt komplexe Workflows mit Tool-Aufrufen und API-Interaktionen aus.
- Entwicklertools: Integriert sich reibungslos in IDEs mit Bearbeitung, Versionskontrolle und Automatisierungsunterstützung.
5. RAG und Wissensintegration
- RAG-Exzellenz: Leistet stark bei der Retrieval-Augmented Generation, selbst mit unstrukturierten oder unsauberen Quellen.
- Wissensaufgaben: Generiert fundierte Antworten, wenn es mit externen Datenbanken oder Dokumentenspeichern verbunden ist.
6. Zusammenfassung und Content-Erstellung
- Mehrquellen-Zusammenfassung: Fasst Nachrichten oder lange Dokumente zusammen und fügt kohärente Kommentare hinzu.
- Content-Generierung: Vielseitig zum Umschreiben und Erstellen von erweiterten Erzählungen.
Qwen3-Next-80B-A3B vs Qwen3-32B: Preis
| Modell | Kontextfenster | Maximale Ausgabe | Eingabepreis (/1M Token) | Ausgabepreis (/1M Token) |
| Qwen3-Next-80B-A3B-Thinking/Instruct | 131K | 32,7K | 0,15 $ | 1,5 $ |
| Qwen3-32B (Thinking/Non-Thinking) | 40,9K | 20K | 0,1 $ | 0,45 $ |
Alle API-Preise sind wie auf Novita AI verfügbar aufgelistet.
Qwen3-Next-80B-A3B bietet ein deutlich größeres Kontextfenster und eine höhere Ausgabekapazität, ist aber mit höheren Eingabe- und Ausgabekosten verbunden. Qwen3-32B ist erschwinglicher und effizienter, obwohl seine Kontextlänge und Generierungsbegrenzung deutlich kleiner sind.
Zugriff auf Qwen3-Next-80B-A3B und Qwen3-32B
Novita AI bietet flexiblen Zugriff auf sowohl Qwen3-Next-80B-A3B als auch Qwen3-32B, sodass sie für ein breites Spektrum an Anforderungen angepasst werden können – von alltäglichen Anwendungen bis hin zu fortgeschrittener Entwicklung – unterstützt durch die richtigen Tools für nahtlose Bereitstellung.
Option 1: Nutzung des Playgrounds (Jetzt verfügbar – Keine Programmierung erforderlich)
- Sofortiger Zugriff: Registrieren Sie sich und beginnen Sie innerhalb von Sekunden mit dem Experimentieren mit Qwen3-Next-80B-A3B oder Qwen3-32B.
- Interaktive Oberfläche: Testen Sie Prompts und visualisieren Sie Ausgaben in Echtzeit.
- Modellvergleich: Vergleichen Sie es mit anderen führenden Modellen für Ihren spezifischen Anwendungsfall.
Der Playground ermöglicht es Ihnen, mit Prompts zu experimentieren und Ergebnisse sofort anzusehen, ohne dass eine technische Einrichtung erforderlich ist. Er ist ideal für schnelles Prototyping, das Testen neuer Ideen und das Erkunden der Modellfunktionen vor der vollständigen Implementierung.
Probieren Sie Qwen3-Next-80B-A3B jetzt kostenlos aus!
Option 2: API-Zugriff (Für Entwickler)
Verbinden Sie Qwen3-Next-80B-A3B oder Qwen3-32B über die REST-API von Novita AI mit Ihren Anwendungen – profitieren Sie von dem 10-fachen Inferenz-Durchsatz des Modells bei langen Kontexten, ohne Infrastruktur verwalten zu müssen.
Schritt 1: Anmelden und auf die Modellbibliothek zugreifen

Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell, das Ihren Anforderungen entspricht.
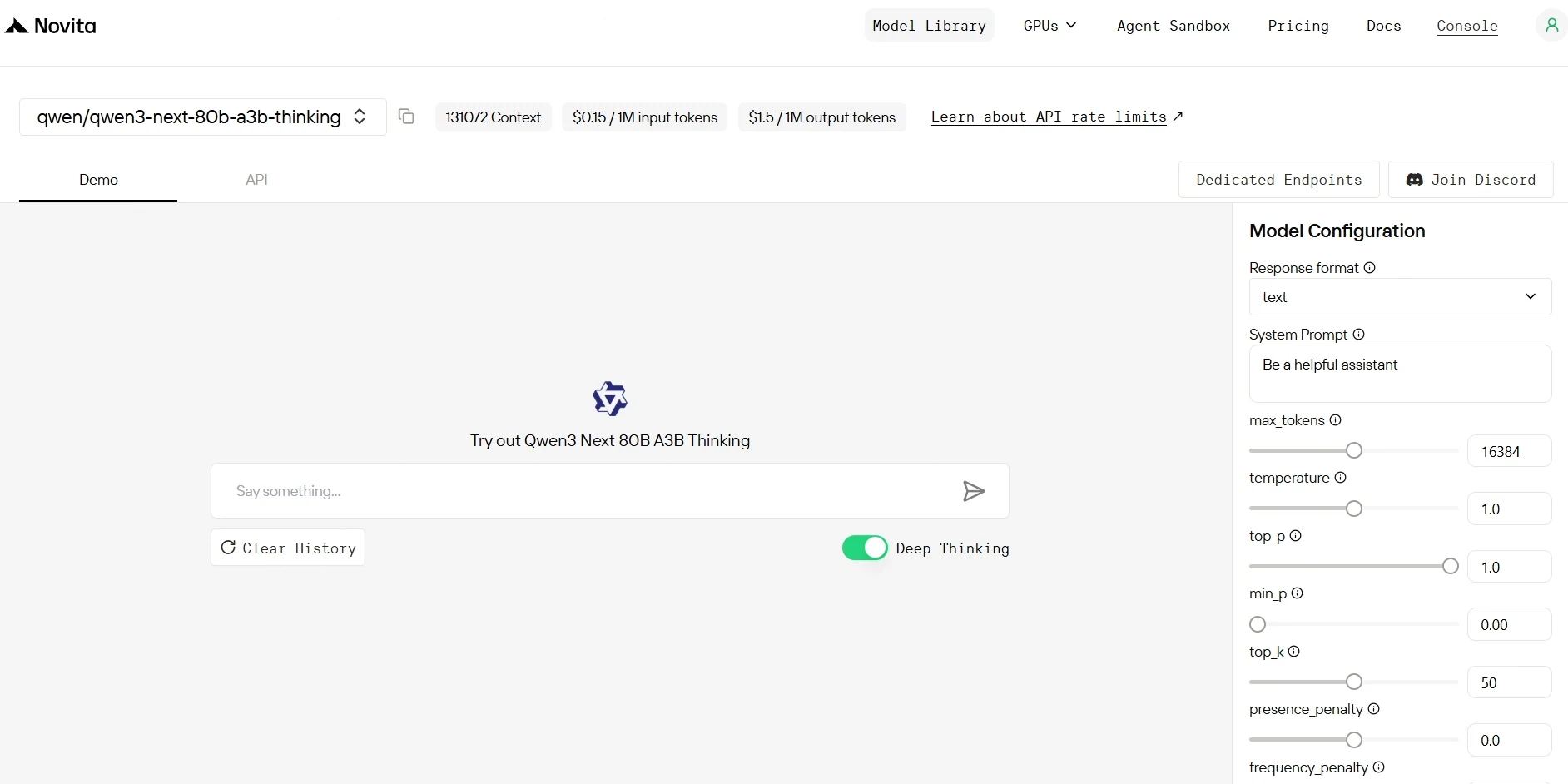
Schritt 3: Starten Sie Ihre kostenlose Testversion
Starten Sie Ihre kostenlose Testversion, um die Funktionen des ausgewählten Modells zu erkunden.
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung bei der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Auf der Seite „Kontoeinstellungen" können Sie den API-Schlüssel wie in der Abbildung gezeigt kopieren.

Schritt 5: Installieren Sie die API (Python-Beispiel für Qwen3-Next-80B-A3B-Thinking)
Installieren Sie die API über den für Ihre Programmiersprache spezifischen Paketmanager.
Nach der Installation importieren Sie die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit dem Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Nutzung der Chat-Completions-API für Python-Nutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="your_api_key_here",
)
model = "qwen/qwen3-next-80b-a3b-instruct"
stream = True # or False
max_tokens = 4096
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = {"type": "text"}
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Plattformfunktionen:
- OpenAI-kompatibler Endpunkt:
/v3/openaifür nahtlose Integration - Flexible Parameter: Steuern Sie die Generierung mit Temperatur, Top-p, Strafen und mehr
- Streaming-Unterstützung: Wählen Sie zwischen Streaming- oder Batch-Antworten
- Modellauswahl: Greifen Sie auf sowohl Instruct- als auch Thinking-Varianten zu.
Häufig gestellte Fragen
Was ist der Hauptunterschied zwischen Qwen3-Next-80B-A3B und Qwen3-32B?
Qwen3-Next-80B-A3B ist ein Next-Generation-Sparse-MoE-Modell, das für komplexe Aufgaben und Effizienz optimiert ist, während Qwen3-32B ein dichtes Modell ist, das für ausgewogene Leistung und den Alltagseinsatz entwickelt wurde.
Welches Modell, Qwen3-Next-80B-A3B oder Qwen3-32B, verarbeitet Langkontext-Eingaben besser?
Qwen3-Next-80B-A3B ist für extreme Kontextlängen optimiert (getestet bis 262K Token) und behält hohe Geschwindigkeit auch im großen Maßstab bei.
Wie hoch sind die Kosten für die Nutzung von Qwen3-Next-80B-A3B im Vergleich zu Qwen3-32B?
Auf Novita AI kostet Qwen3-Next-80B-A3B 0,15 $ pro 1M Eingabe-Token und 1,5 $ pro 1M Ausgabe-Token. Qwen3-32B ist hingegen für 0,1 $ pro 1M Eingabe-Token und 0,45 $ pro 1M Ausgabe-Token verfügbar, was es zu einer erschwinglicheren Option für kleinere oder kostensensitive Aufgaben macht.
Novita AI ist die All-in-One-Cloud-Plattform, die Ihre KI-Ambitionen verwirklicht. Integrierte APIs, Serverless, GPU-Instanzen – die kosteneffektiven Tools, die Sie brauchen. Eliminieren Sie Infrastruktur, starten Sie kostenlos und machen Sie Ihre KI-Vision zur Realität.



