

تواصل سلسلة Qwen3 جذب الانتباه بمجموعتها المتنوعة من نماذج اللغة الكبيرة، كل منها مصمم خصيصًا لاحتياجات مختلفة. من بينها، يمثل Qwen3-Next-80B-A3B الفئة عالية الأداء، المجهز بمعلمات ضخمة وهندسة متقدمة للتعامل مع مهام التفكير المتطلبة والإبداعية. من ناحية أخرى، يعد Qwen3-32B خيارًا متوسط الحجم، مصمم لتحقيق التوازن بين القدرة والكفاءة مع الحفاظ على تعدد الاستخدامات عبر السيناريوهات العملية. في هذه المقالة، سنقارن بين Qwen3-Next-80B-A3B و Qwen3-32B عبر عدة أبعاد مهمة للمطورين.
Qwen3-Next-80B-A3B مقابل Qwen3-32B: الأساسيات ومعايير الأداء
| الميزة | Qwen3-Next-80B-A3B | Qwen3-32B |
| المعلمة | 80B إجمالاً و 3B مُفعلة | 32.8B |
| الهندسة المعمارية | خليط الخبراء (Mixture-of-Experts) | كثيف (Dense) |
| نافذة السياق | 262,144 رمزًا بشكل أصلي وقابلة للتوسيع حتى 1,010,000 رمز | 32,768 رمزًا بشكل أصلي و 131,072 رمزًا باستخدام YaRN |
| النسخ | تفكير + تعليم (Thinking + Instruct) | تفكير + بدون تفكير (Thinking + Non-Thinking) |
| تعدد الوسائط | نص فقط | نص فقط |
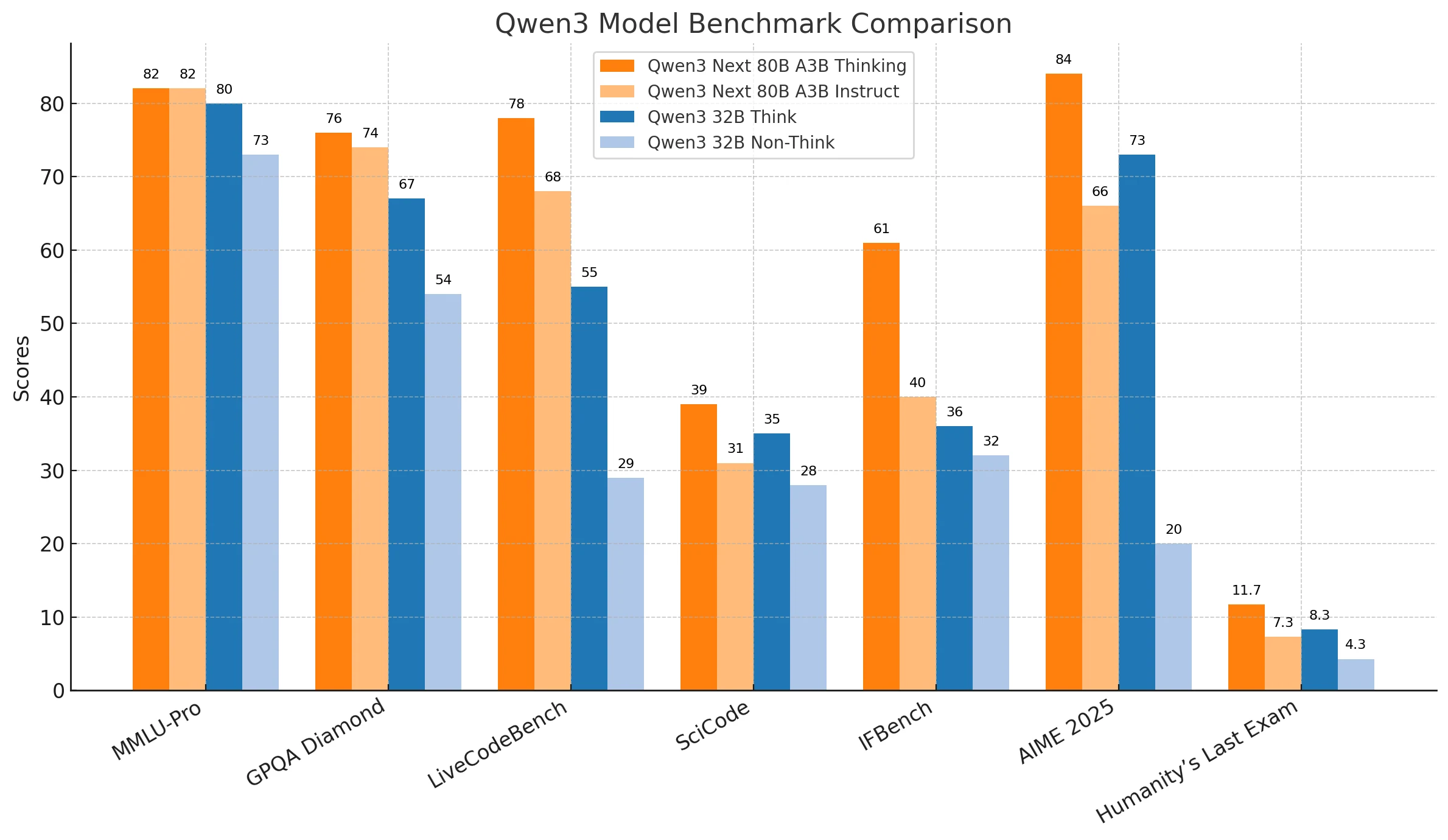
يظهر Qwen3-Next-80B أداءً أقوى باستمرار في التفكير المعقد وحل المشكلات المجردة والمهام عالية المخاطر، مما يجعله مناسبًا جدًا لتطبيقات المؤسسات مثل البحث المتقدم واتخاذ القرارات الاستراتيجية والنشرات الحرجة. تجعله موثوقيته وقابليته للتوسع الخيار الأمثل عندما تكون الدقة والعمق أمرًا لا يمكن التفاوض عليه.
يحقق Qwen3-32B توازنًا بين الكفاءة والتكلفة المعقولة، ويتفوق في البرمجة اليومية والأتمتة العملية والسيناريوهات التي تكون فيها الاستجابة أهم من الدقة المطلقة. إنه حل فعال من حيث التكلفة للمؤسسات التي تسعى إلى نتائج موثوقة تحت قيود أكثر صرامة على الموارد أو زمن الاستجابة.
Qwen3-Next-80B-A3B مقابل Qwen3-32B: السرعة وزمن الاستجابة
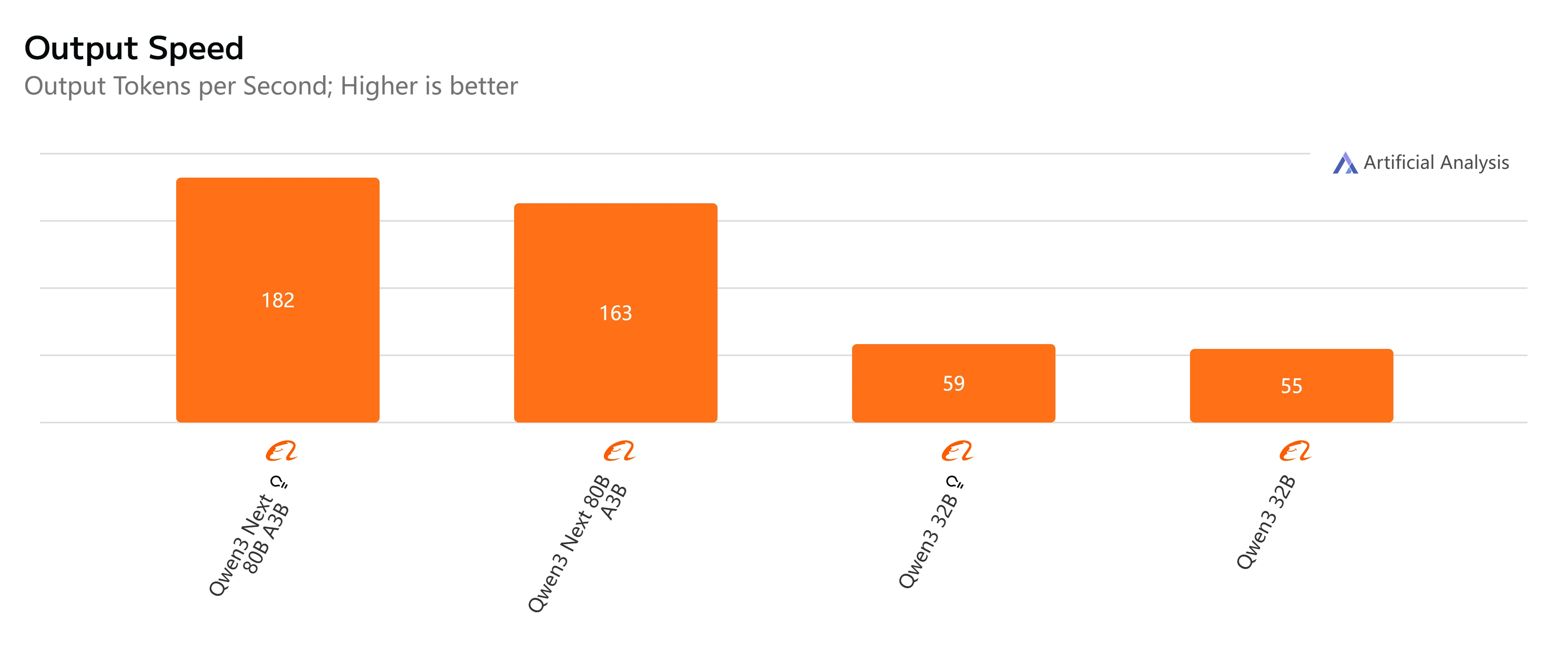
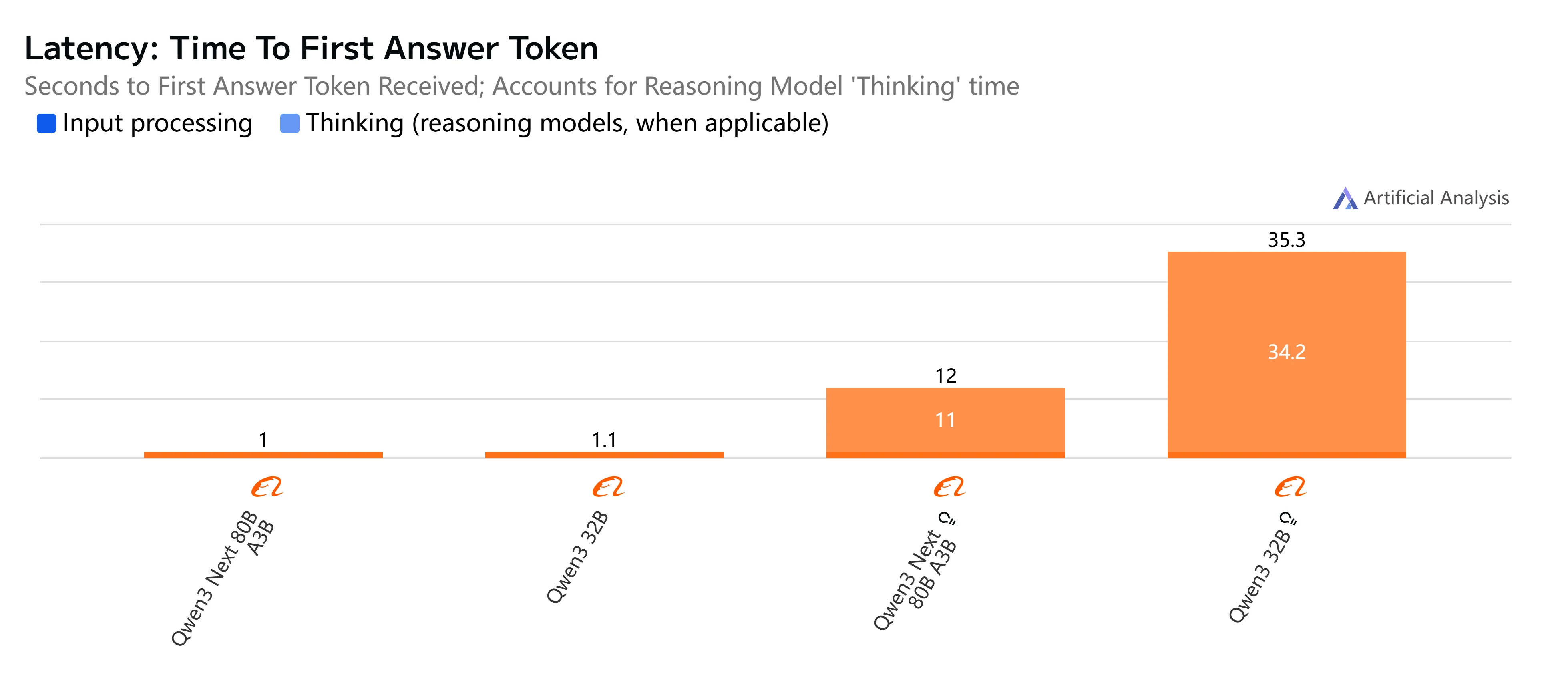
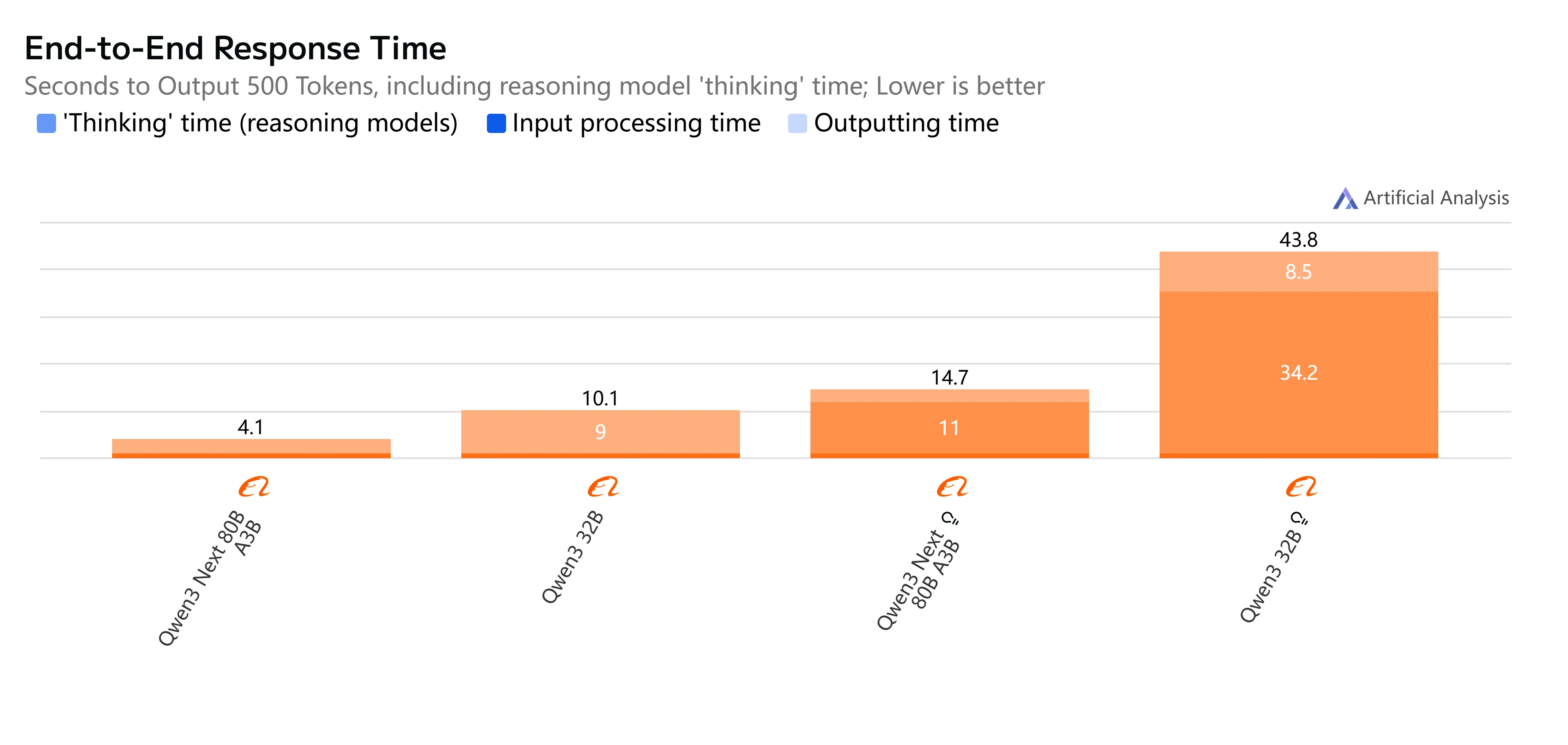
- Qwen3-Next-80B-A3B-Instruct: استجابة سريعة وزمن استجابة منخفض نسبيًا، حيث يكمل إخراج 500 رمز في ما يزيد قليلاً عن 4 ثوانٍ مع إنتاج سلس، مما يجعله عمليًا للمهام التفاعلية والفورية.
- Qwen3-32B (بدون تفكير): سرعة إجمالية متوسطة، مع زمن استجابة أعلى يبلغ حوالي 10 ثوانٍ وتوليد رموز أبطأ، ولكنه لا يزال مناسبًا لأحمال العمل المتوازنة التي تكون فيها الكفاءة مهمة.
- Qwen3-Next-80B-A3B-Thinking: أبطأ بشكل ملحوظ بسبب عبء التفكير، حيث يستغرق ما يقرب من 15 ثانية من البداية إلى النهاية. ومع ذلك، فإنه يقدم عمق تفكير أقوى، مما يجعله أفضل لحل المشكلات المعقدة.
- Qwen3-32B (مع تفكير): الخيار الأبطأ، مع زمن استجابة مرتفع جدًا (أكثر من 35 ثانية) وإنتاج محدود. الأفضل حجزه للبحث أو السيناريوهات التي يكون فيها التفكير المتقدم أولوية على السرعة.
Qwen3-Next-80B-A3B مقابل Qwen3-32B: حالات الاستخدام
Qwen3-32B
1. الكفاءة اليومية وتجربة المساعد
- استجابات موجزة: يقدم إجابات مباشرة بعدد أقل من الرموز، مما يجعله فعالاً من حيث التكلفة.
- العصف الذهني والكتابة: مفيد لصياغة المحتوى الإبداعي وتوليد الأفكار ومهام الكتابة الخفيفة.
- تفكير مرن: يدعم وضع التفكير القابل للتبديل، مما يسمح بإجابات فورية عندما تكون السرعة أهم من العمق.
2. البرمجة والمهام التقنية
- دعم البرمجة: يقدم توليد كود موثوق وتصحيح أخطاء للتطوير اليومي.
- اتباع التعليمات: يتعامل مع الأوامر التفصيلية جيدًا بفضل الهندسة المعمارية الكثيفة.
- سير عمل الهندسة: يؤدي أداءً قويًا في حل المشكلات التقنية والبرمجة بمساعدة الأدوات.
3. معالجة النصوص والعمل اللغوي
- التلخيص: يلخص القصص والمستندات بدقة، حتى عند مستويات التكميم المنخفضة.
- إعادة الصياغة وتغيير الأسلوب: يحول النص إلى تنسيقات أو نبرات جديدة مع الحفاظ على المعنى.
- التصنيف والترجمة: يتفوق في تصنيف النصوص الفوضوية وإنتاج ترجمات طبيعية.
4. حدود يجب ملاحظتها
- أقل فعالية في مهام السياق الطويل (يفقد التماسك بعد حوالي 5 آلاف رمز).
- معدل هلوسة أعلى في التفكير القائم على الحقائق.
- محدود في الكتابة الإبداعية الممتدة أو استخراج البيانات المنظمة.
Qwen3-Next-80B-A3B
1. كفاءة عالية
- ميزة التنشيط المتناثر: فقط حوالي 3 مليار معلمة نشطة لكل رمز، مما يقلل التكلفة والحسابات المطلوبة.
- مكاسب في الإنتاجية: يحقق إنتاجية استدلال أعلى بأكثر من 10 أضعاف في السياقات الأطول من 32 ألف رمز.
2. التعامل مع أطوال سياق متطرفة
- تحسين السياق الطويل: يحافظ على السرعة عند أطوال سياق مرتفعة جدًا (مختبرة حتى 262 ألف رمز).
- تصميم الانتباه الهجين: يجمع بين Gated DeltaNet والانتباه المحدود والانتباه الخطي لتوسيع نطاق فعال.
- التطبيقات: مثالي لمهام النصوص الطويلة مثل ترجمة الروايات ومراجعة المستندات القانونية أو معالجة بيانات البحث.
3. التفكير والذكاء العام
- نموذج لغة عام: يعمل كـ “عقل رئيسي” قوي للاستخدام العام، مع أداء سلس لوضع التعليم.
- قوة التفكير: يقترب من أداء Qwen3-235B في المنطق والاستنتاج، خاصة في حل المشكلات المتخصصة.
- وضع التفكير: فعال للتفكير متعدد الخطوات وتنسيق الأدوات.
4. قدرات البرمجة والوكلاء الذكيين
- تطوير البرمجيات: موثوق لإعادة هيكلة الكود وتوليد الاختبارات وبناء المشاريع.
- مهام الوكلاء الذكيين: ينفذ سير عمل معقد باستخدام استدعاءات الأدوات وتفاعلات API.
- أدوات المطورين: يتكامل بسلاسة مع بيئات التطوير المتكاملة (IDEs) مع دعم التحرير والتحكم في الإصدار والأتمتة.
5. RAG وتكامل المعرفة
- تميز في RAG: يؤدي أداءً قويًا في التوليد المعزز بالاسترجاع، حتى مع المصادر الفوضوية أو غير المنظمة.
- مهام المعرفة: يولد إجابات مبنية على أساس متصل بقواعد البيانات الخارجية أو مخازن المستندات.
6. التلخيص وإنشاء المحتوى
- التلخيص من مصادر متعددة: يختصر الأخبار أو المستندات الطويلة مع إضافة تعليقات متماسكة.
- إنشاء المحتوى: متعدد الاستخدامات لإعادة الصياغة وإنتاج روايات ممتدة.
Qwen3-Next-80B-A3B مقابل Qwen3-32B: التسعير
| النموذج | نافذة السياق | الحد الأقصى للإخراج | سعر الإدخال (لكل 1 مليون رمز) | سعر الإخراج (لكل 1 مليون رمز) |
| Qwen3-Next-80B-A3B-Thinking/Instruct | 131K | 32.7K | $0.15 | $1.5 |
| Qwen3-32B (Thinking/Non-Thinking) | 40.9K | 20K | $0.1 | $0.45 |
جميع أسعار API مدرجة كما هي متاحة على Novita AI
يقدم Qwen3-Next-80B-A3B نافذة سياق أكبر بكثير وقدرة إخراج أعلى، ولكن يأتي بتكاليف إدخال وإخراج أعلى. يعد Qwen3-32B أكثر فعالية من حيث التكلفة وكفاءة، على الرغم من أن طول السياق والحد الأقصى للتوليد لديه أصغر بكثير.
كيفية الوصول إلى Qwen3-Next-80B-A3B و Qwen3-32B
تقدم Novita AI وصولًا مرنًا إلى كل من Qwen3-Next-80B-A3B و Qwen3-32B، مما يجعلهما قابليين للتكيف لمجموعة واسعة من الاحتياجات - من التطبيقات اليومية إلى التطوير المتقدم - مدعومين بالأدوات المناسبة للنشر السلس.
الخيار 1: استخدام مساحة التجربة (متاح الآن - لا يتطلب برمجة)
- وصول فوري: سجل وابدأ في تجربة Qwen3-Next-80B-A3B أو Qwen3-32B في ثوانٍ.
- واجهة تفاعلية: اختبر الأوامر واعرض المخرجات في الوقت الفعلي.
- مقارنة النماذج: قارن مع النماذج الرائدة الأخرى لحالة الاستخدام المحددة الخاصة بك.
تتيح لك مساحة التجربة تجربة الأوامر وعرض النتائج فورًا، دون الحاجة إلى إعداد تقني. إنها مثالية للنماذج الأولية السريعة واختبار الأفكار الجديدة واستكشاف قدرات النموذج قبل التنفيذ على نطاق كامل.
جرب Qwen3-Next-80B-A3B مجانًا الآن!
الخيار 2: الوصول عبر API (للمطورين)
اتصل بـ Qwen3-Next-80B-A3B أو Qwen3-32B بتطبيقاتك عبر REST API الخاص بـ Novita AI - مع الاستفادة من إنتاجية الاستدلال 10 أضعاف للنموذج على السياقات الطويلة دون إدارة البنية التحتية.
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج

الخطوة 2: اختر النموذج الخاص بك
تصفح الخيارات المتاحة واختر النموذج الذي يناسب احتياجاتك.
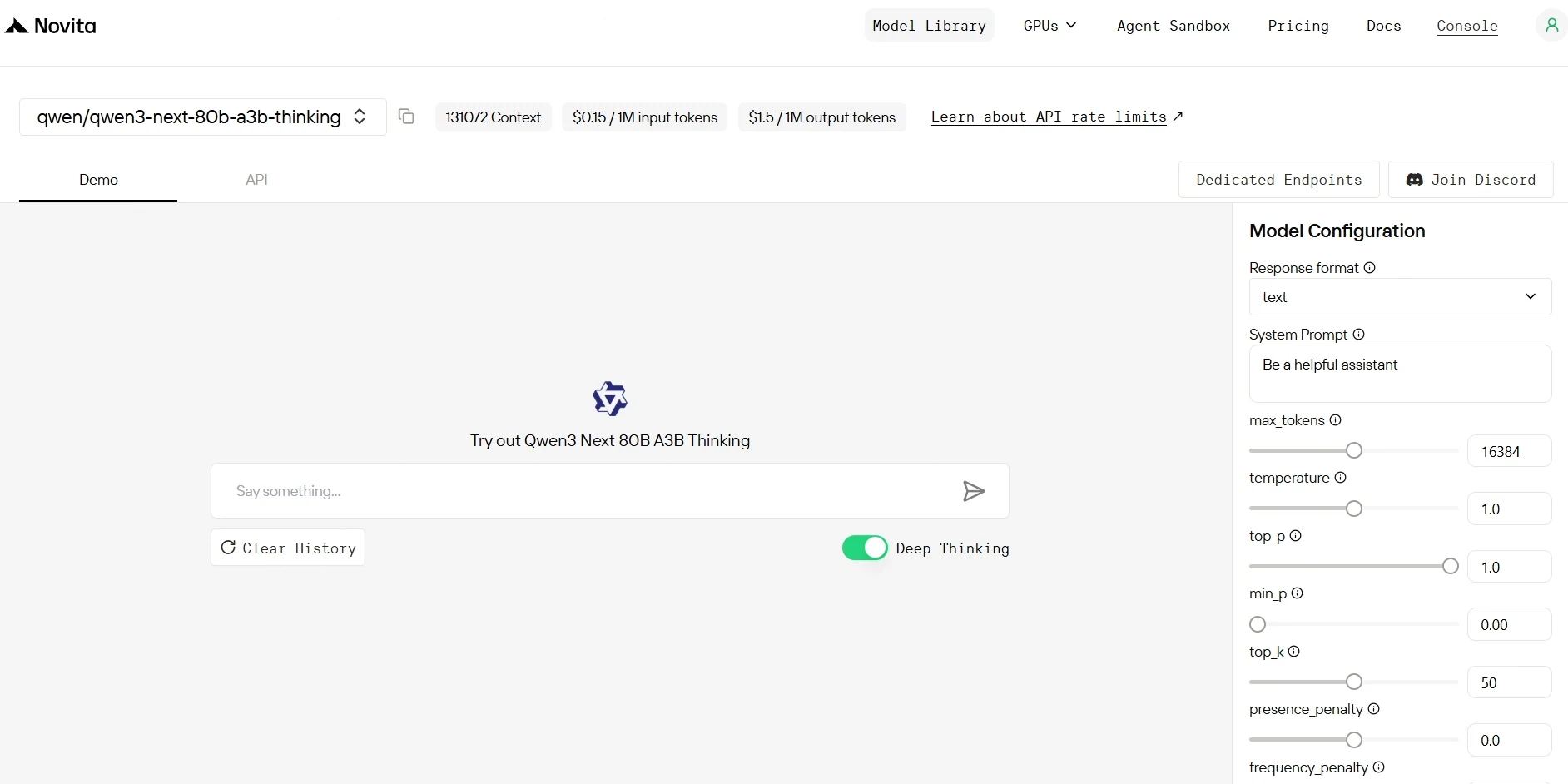
الخطوة 3: ابدأ تجربتك المجانية
ابدأ تجربتك المجانية لاستكشاف قدرات النموذج المحدد.
الخطوة 4: احصل على مفتاح API الخاص بك
للمصادقة مع API، سنزودك بمفتاح API جديد. عند الدخول إلى صفحة “إعدادات الحساب”، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

الخطوة 5: تثبيت API (مثال بلغة Python لـ Qwen3-Next-80B-A3B-Thinking) ثبت API باستخدام مدير الحزم الخاص بلغة البرمجة التي تستخدمها.
بعد التثبيت، استورد المكتبات الضرورية إلى بيئة التطوير الخاصة بك. قم بتهيئة API باستخدام مفتاح API الخاص بك لبدء التفاعل مع نماذج اللغة الكبيرة لـ Novita AI. هذا مثال على استخدام API لإكمال المحادثات لمستخدمي بايثون.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="your_api_key_here",
)
model = "qwen/qwen3-next-80b-a3b-instruct"
stream = True # or False
max_tokens = 4096
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = {"type": "text"}
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
ميزات المنصة:
- نقطة نهاية متوافقة مع OpenAI:
/v3/openaiللتكامل السلس - معلمات مرنة: تحكم في التوليد باستخدام درجة الحرارة وtop-p والجزاءات والمزيد
- دعم البث: اختر بين الاستجابات المتدفقة أو الدفعية
- اختيار النموذج: الوصول إلى كلا النسختين (وضع التعليم ووضع التفكير)
الأسئلة الشائعة
ما هو الفرق الرئيسي بين Qwen3-Next-80B-A3B و Qwen3-32B؟ يعد Qwen3-Next-80B-A3B نموذج MoE متناثر من الجيل التالي محسّن للمهام المعقدة والكفاءة، بينما يعد Qwen3-32B نموذجًا كثيفًا مصمم لأداء متوازن للاستخدام اليومي.
أي من النموذجين، Qwen3-Next-80B-A3B أو Qwen3-32B، يتعامل بشكل أفضل مع مدخلات السياق الطويل؟ يعد Qwen3-Next-80B-A3B محسّنًا لأطوال سياق متطرفة (مختبرة حتى 262 ألف رمز) ويحافظ على سرعة عالية عند التوسع.
كم تكلفة استخدام Qwen3-Next-80B-A3B مقابل Qwen3-32B؟ على Novita AI، يُسعّر Qwen3-Next-80B-A3B بـ 0.15 دولار لكل 1 مليون رمز إدخال و 1.5 دولار لكل 1 مليون رمز إخراج. بينما يتوفر Qwen3-32B بسعر 0.1 دولار لكل 1 مليون رمز إدخال و 0.45 دولار لكل 1 مليون رمز إخراج، مما يجعله خيارًا أكثر فعالية من حيث التكلفة للمهام ذات النطاق الأصغر أو الحساسة للتكلفة.
Novita AI هي منصة سحابية شاملة تمكّنك من تحقيق طموحاتك في الذكاء الاصطناعي. واجهات برمجة تطبيقات متكاملة، بدون خوادم، مثيلات GPU - الأدوات الفعالة من حيث التكلفة التي تحتاجها. تخلص من البنية التحتية، ابدأ مجانًا، وحقق رؤيتك في الذكاء الاصطناعي.



