

로컬에 GLM-4.5를 배포하려고 고려 중이지만 필요한 막대한 GPU 리소스가 걱정되시나요? 전체 GLM-4.5 모델은 FP8 정밀도로 16개의 NVIDIA H100 GPU 또는 8개의 H200 GPU 구성을 요구하는 반면, 리소스 효율성이 더 높은 GLM-4.5-Air 변형은 FP8 정밀도로 2개의 H100 GPU 또는 1개의 H200 GPU에서 실행됩니다. 이러한 구성은 최적 성능을 보장하며 모델의 최대 128K 토큰에 달하는 광범위한 컨텍스트 길이를 지원합니다.
이 글에서는 GLM-4.5의 VRAM 요구사항을 살펴보고, 로컬 배포의 가능성을 논의하며, 이 강력한 언어 모델을 효과적으로 활용할 수 있는 대체 방법을 검토할 것입니다.
GLM 4.5 VRAM 요구사항
GLM-4.5는 GLM 제품군의 최신 발전 버전으로, 정교한 Mixture-of-Experts(MoE) 아키텍처와 에이전트 애플리케이션 최적화가 특징입니다. 이 모델은 두 가지 변형으로 제공됩니다: 총 3550억 개의 매개변수(활성 320억 개)를 가진 플래그십 GLM-4.5와, 총 1060억 개의 매개변수(활성 120억 개)를 가진 효율적인 GLM-4.5-Air입니다.
주요 아키텍처 혁신으로는 향상된 추론을 위해 폭은 줄이고 깊이는 늘린 더 깊은 모델 구조, 포괄적인 지식을 위해 15조 토큰 규모의 대규모 말뭉치로 사전 학습된 모델, 그리고 확장 가능한 대규모 에이전트 강화 학습을 위해 설계된 오픈소스 “slime” RL 인프라가 있습니다.
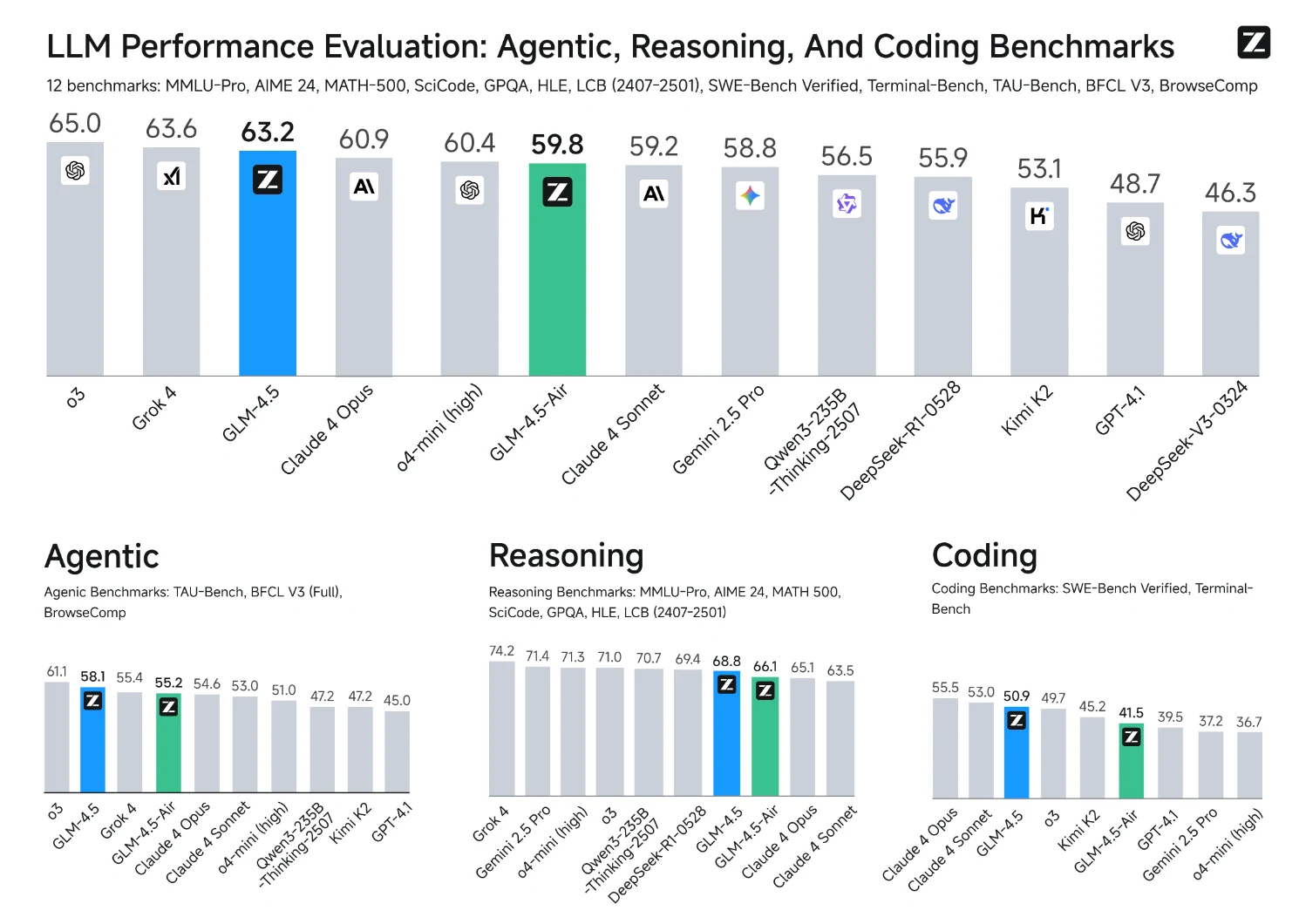
출처: Z.AI
GLM 4.5 추론에 필요한 VRAM은 얼마인가요?
아래 표의 구성에서 모델을 실행할 수 있습니다:
| 모델 | 정밀도 | GPU 유형 및 수량 | 테스트 프레임워크 |
|---|---|---|---|
| GLM-4.5 | BF16 | H100 x 16 / H200 x 8 | sglang |
| GLM-4.5 | FP8 | H100 x 8 / H200 x 4 | sglang |
| GLM-4.5-Air | BF16 | H100 x 4 / H200 x 2 | sglang |
| GLM-4.5-Air | FP8 | H100 x 2 / H200 x 1 | sglang |
아래 표의 구성에서는 모델이 전체 128K 컨텍스트 길이를 활용할 수 있습니다:
| 모델 | 정밀도 | GPU 유형 및 수량 | 테스트 프레임워크 |
|---|---|---|---|
| GLM-4.5 | BF16 | H100 x 32 / H200 x 16 | sglang |
| GLM-4.5 | FP8 | H100 x 16 / H200 x 8 | sglang |
| GLM-4.5-Air | BF16 | H100 x 8 / H200 x 4 | sglang |
| GLM-4.5-Air | FP8 | H100 x 4 / H200 x 2 | sglang |
GLM 4.5 미세 조정에 필요한 VRAM은 얼마인가요?
아래 표의 구성을 사용하여 Llama Factory로 코드를 실행할 수 있습니다:
| 모델 | GPU 유형 및 수량 | 전략 | GPU당 배치 크기 |
|---|---|---|---|
| GLM-4.5 | H100 x 16 | Lora | 1 |
| GLM-4.5-Air | H100 x 4 | Lora | 1 |
아래 표의 구성을 사용하여 Swift로 코드를 실행할 수 있습니다:
| 모델 | GPU 유형 및 수량 | 전략 | GPU당 배치 크기 |
|---|---|---|---|
| GLM-4.5 | H20 (96GiB) x 16 | Lora | 1 |
| GLM-4.5-Air | H20 (96GiB) x 4 | Lora | 1 |
| GLM-4.5 | H20 (96GiB) x 128 | SFT | 1 |
| GLM-4.5-Air | H20 (96GiB) x 32 | SFT | 1 |
| GLM-4.5 | H20 (96GiB) x 128 | RL | 1 |
| GLM-4.5-Air | H20 (96GiB) x 32 | RL | 1 |
배치 크기별 GLM 4.5 VRAM 사용량
| 모델 | 정밀도 | GPU당 배치 크기 | VRAM |
|---|---|---|---|
| GLM-4.5 | FP16 | 1 | 945.36GB |
| GLM-4.5 | FP16 | 8 | 1128.49GB |
| GLM-4.5 | FP16 | 16 | 1137.79GB |
| GLM-4.5 | FP16 | 32 | 1756.38GB |
| GLM-4.5-Air | FP16 | 1 | 288.68GB |
| GLM-4.5-Air | FP16 | 8 | 343.58GB |
| GLM-4.5-Air | FP16 | 16 | 406.33GB |
| GLM-4.5-Air | FP16 | 32 | 531.83GB |
GLM 4.5의 하드웨어 요구사항은 무엇인가요?
https://www.youtube.com/watch?v=grAXN76\_-Ig
- GPU:
- 추론: 전체 모델의 경우 FP8 정밀도로 H100 8개/H200 4개, 또는 BF16 정밀도로 H100 16개/H200 8개; Air 변형의 경우 절반 수준입니다.
- 미세 조정: ≥ 80GB VRAM을 가진 GPU가 필요합니다.
- CPU 및 시스템:
- 모델 로드 및 오프로드 버퍼 관리를 위해 ≥ 1TB RAM이 필요합니다.
- 다중 GPU 텐서 병렬 처리를 위해 고대역폭 상호 연결(NVLink/HPC 스위치)이 필요합니다.
- 정밀도:
- 최소 VRAM 사용을 위해 FP8을 사용합니다(네이티브 FP8을 지원하는 GPU가 필요합니다).
- FP8을 지원하지 않는 GPU의 경우 대안으로 BF16을 사용할 수 있습니다.
- 소프트웨어:
- 추론에는 vLLM 또는 Llama Factory를 사용합니다; 추측 디코딩 및 CPU 오프로드를 지원합니다.
GLM 4.5의 VRAM 사용량 낮추기를 위한 최적화
- 모델 변형 선택: 32~64GB GPU 환경에서는 GLM 4.5-Air(총 1060억 개/활성 120억 개)를 선택하세요.
- GLM-4.5-Air를 선택해야 하는 경우:
- 현저히 빠른 생성 속도:
- GLM-4.5-Air는 초당 약 160토큰의 출력 속도를 달성하며, 이는 전체 크기 모델(초당 약 88토큰)보다 거의 두 배 빠른 속도입니다. 따라서 Air는 지연 시간에 민감한 애플리케이션에 이상적입니다.
- 극도로 낮은 첫 토큰 지연 시간(TTFT):
- Air는 약 0.58초 만에 첫 토큰을 출력하는 반면, 전체 크기 모델은 0.68초가 소요됩니다. 일부 테스트에서는 “사고” 시간을 포함할 경우 전체 크기 모델의 지연 시간이 22~23초까지 증가할 수 있습니다.
- 짧은 종단 간 응답 시간:
- Air는 입력 처리, 추론, 출력을 포함한 종단 간 응답을 약 16초 만에 제공하는 반면, 전체 크기 모델은 거의 29초가 소요되어 실시간 상호작용에는 덜 적합합니다.
- 복잡한 추론 작업에서 약간 낮은 점수:
- MMLU-Pro, GPQA, AIME 등의 추론 벤치마크에서 Air는 전체 크기 모델보다 약 2~3% 낮은 점수를 기록하지만, 여전히 업계 최고 수준의 성능을 유지합니다.
- 대부분의 사용 사례에 권장:
- 대부분의 텍스트 생성, 요약, 기본 추론, 코드 지원 작업의 경우 전체 크기 모델이 필요하지 않으며, Air만으로도 높은 성능과 응답성을 충족합니다.
- 현저히 빠른 생성 속도:
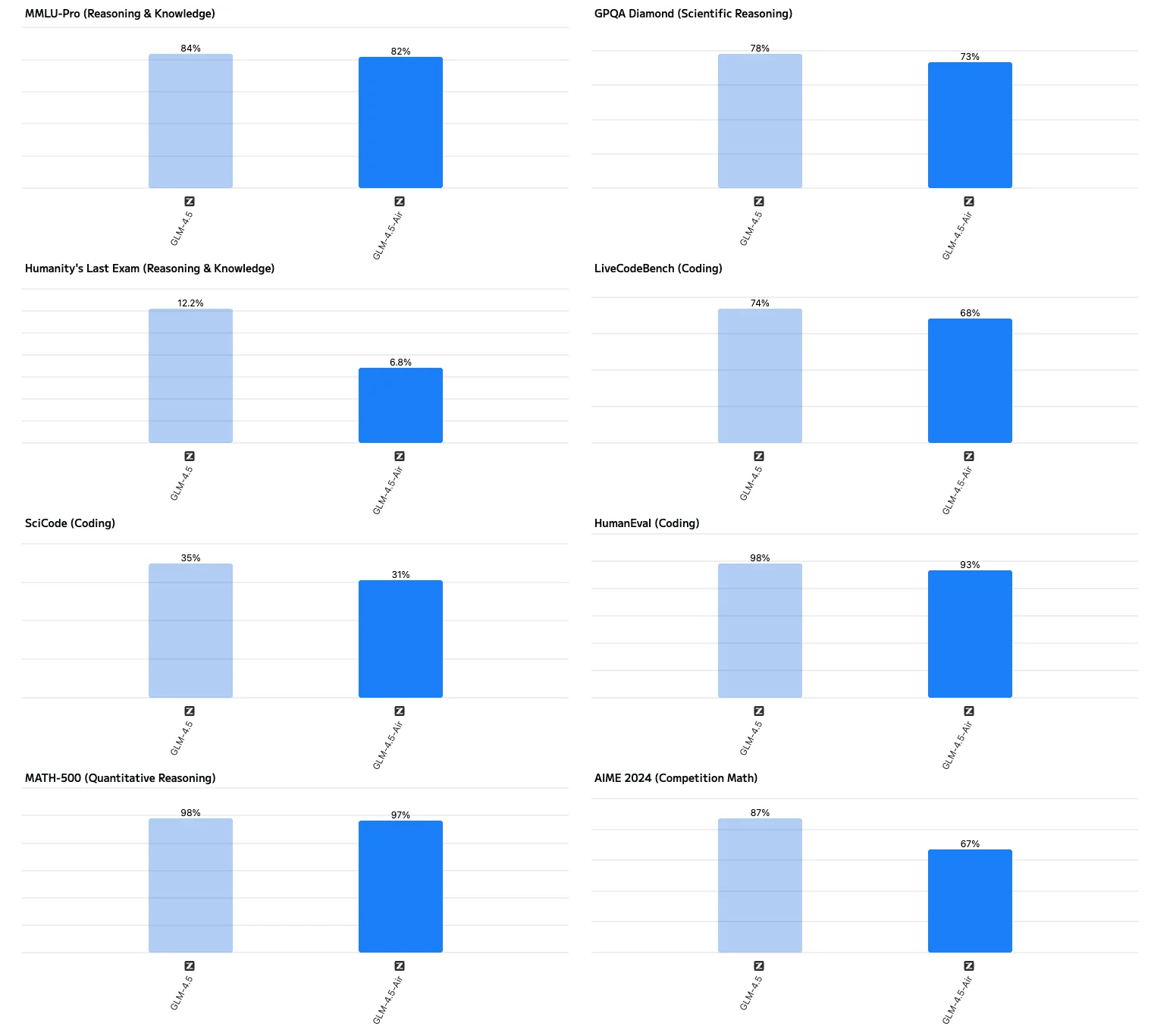
- 레이어 오프로딩: 선택한 MoE 전문가 또는 피드포워드 레이어를 CPU 메모리로 오프로드합니다.
- KV 캐시 양자화: 캐시 정밀도를 낮춰 VRAM을 절약하며, 품질 저하는 미미합니다.
- 배치 크기 = 1: GPU당 단일 샘플 추론으로 제한하여 활성화 값을 최소화합니다.
또 다른 비용 효율적인 옵션: API
로컬에서 GLM 4.5를 배포하는 것과 API를 통해 배포하는 것의 간단한 비교는 다음과 같습니다:
| 항목 | API 배포 | 로컬 배포 |
|---|---|---|
| 비용 | 사용량 기반 과금; 예를 들어 Novita AI에서 입력 토큰은 백만 개당 $0.6, 출력 토큰은 백만 개당 ¥2.2입니다. | 하드웨어(예: NVIDIA A100 GPU)에 대한 높은 초기 투자 비용이 필요하지만, 대량 사용의 경우 장기적으로 비용이 낮아질 수 있습니다. |
| 성능 | 확장 가능하지만 네트워크 지연 시간이 발생할 수 있으며, 약간의 지연이 허용되는 애플리케이션에 적합합니다. | 지연 시간이 낮고 성능이 일관적이며, 즉각적인 응답이 필요한 실시간 애플리케이션에 이상적입니다. |
| 확장성 | 인프라 관리 없이 쉽게 확장 가능하며, 제공자가 확장을 처리합니다. | 추가 하드웨어와 인프라 관리가 필요하여 확장합니다. |
| 데이터 개인정보 보호 | 데이터가 외부에서 처리되므로 규제 산업의 경우 개인정보 보호 문제가 발생할 수 있습니다. | 데이터가 내부에 유지되어 데이터 보호 규정 준수에 대한 더 큰 제어와 보장을 제공합니다. |
| 운영 복잡성 | 설정 및 유지보수가 최소화되며, 제공자가 업데이트와 인프라를 관리합니다. | 설정, 유지보수, 보안에 대한 기술 전문 지식이 필요하지만, 더 많은 사용자 정의를 제공합니다. |
| 사용자 정의 | 제공자의 구성으로 제한되므로 특정 요구사항에 대한 유연성이 낮습니다. | 모델 사용자 정의, 미세 조정, 기존 시스템과의 통합에 대한 완전한 제어 권한을 제공합니다. |
| 사용 사례 적합성 | 가변적이거나 낮은 사용량, 빠른 개발 필요, 제한된 기술 리소스가 있는 애플리케이션에 이상적입니다. | 높고 일관된 사용량, 엄격한 데이터 개인정보 보호 요구사항, 광범위한 사용자 정의가 필요한 애플리케이션에 가장 적합합니다. |
Novita AI를 통해 GLM 4.5에 접근하는 방법
Novita AI는 131K 컨텍스트를 지원하는 API를 제공하며, 입력당 $0.6, 출력당 $2.2의 비용으로 GLM 4.5의 코드 에이전트 잠재력을 극대화할 수 있도록 강력한 지원을 제공합니다.
Novita AI
1단계: 로그인 후 모델 라이브러리 접근
계정에 로그인한 후 모델 라이브러리 버튼을 클릭하세요.

2단계: 모델 선택
사용 가능한 옵션을 둘러본 후 필요에 맞는 모델을 선택하세요.
3단계: 무료 체험 시작
선택한 모델의 기능을 탐색하려면 무료 체험을 시작하세요.
4단계: API 키 발급
API로 인증하려면 새 API 키를 제공합니다. 설정 페이지에 들어가면 이미지에 표시된 대로 API 키를 복사할 수 있습니다.

5단계: API 설치
사용 중인 프로그래밍 언어의 패키지 관리자를 사용하여 API를 설치하세요.
설치 후 필요한 라이브러리를 개발 환경으로 가져오세요. API 키로 API를 초기화하여 Novita AI LLM과 상호작용을 시작할 수 있습니다. 아래는 Python 사용자를 위한 채팅 완성 API 사용 예시입니다.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_UsudmdAIggvSInjIdO2HWaTCyXxTFOXDV8TH8UCPbA576Rs4AGqSA5ThNbelSDgdEGAWQcWXnAU2bHi5BueceA==",
)
model = "zai-org/glm-4.5"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
GLM-4.5와 그 Air 변형은 에이전트 애플리케이션을 위한 강력한 솔루션을 제공하며, 다양한 배포 시나리오에 맞춘 다양한 VRAM 요구사항을 가지고 있습니다. 특정 요구사항과 리소스를 평가하면 로컬 배포와 API 기반 솔루션 중 선택하는 데 도움이 됩니다.
자주 묻는 질문
GLM 4.5를 사용해야 하는 사람은 누구인가요?
GLM-4.5는 특히 코딩, 자동화, 지식 작업과 관련된 고급 AI 에이전트 기능이 필요한 개발자, 연구원, 기업에 이상적입니다.
GLM-4.5란 무엇인가요?
GLM-4.5는 복잡한 추론과 도구 통합이 필요한 에이전트 애플리케이션에 최적화된 Mixture-of-Experts 아키텍처를 특징으로 하는 고급 대규모 언어 모델입니다.
방대한 하드웨어 없이 GLM-4.5를 배포할 수 있나요?
네, API를 통해 GLM-4.5를 사용하면 상당한 하드웨어 투자 필요성을 줄일 수 있지만, 데이터 개인정보 보호 및 네트워크 지연 시간에 대한 고려가 필요할 수 있습니다.
Novita AI는 간단한 API를 사용해 AI 모델을 쉽게 배포할 수 있는 방법을 개발자에게 제공하는 동시에, 구축 및 확장을 위한 합리적인 가격의 신뢰할 수 있는 GPU 클라우드를 제공하는 AI 클라우드 플랫폼입니다.



