

Erwägen Sie die lokale Bereitstellung von GLM-4.5, machen sich aber Sorgen über die erforderlichen umfangreichen GPU-Ressourcen? Das vollständige GLM-4.5-Modell erfordert Konfigurationen wie 16 NVIDIA H100-GPUs oder 8 H200-GPUs in FP8-Präzision, während die ressourcenschonendere Variante GLM-4.5-Air mit 2 H100-GPUs oder 1 H200-GPU in FP8-Präzision betrieben werden kann. Diese Konfigurationen gewährleisten optimale Leistung und unterstützen die umfangreiche Kontextlänge des Modells von bis zu 128K Tokens.
In diesem Artikel werden wir die VRAM-Anforderungen von GLM-4.5 untersuchen, die Machbarkeit der lokalen Bereitstellung diskutieren und alternative Methoden zur effektiven Nutzung dieses leistungsstarken Sprachmodells betrachten.
VRAM-Anforderungen von GLM 4.5
GLM-4.5 ist die neueste Weiterentwicklung der GLM-Familie, verfügt über eine ausgefeilte Mixture-of-Experts (MoE)-Architektur und ist für agentische Anwendungen optimiert. Das Modell wird in zwei Varianten angeboten: dem Flaggschiff GLM-4.5 mit 355 Milliarden Gesamtparametern (32 Milliarden aktiv) und dem effizienten GLM-4.5-Air mit 106 Milliarden Gesamtparametern (12 Milliarden aktiv).
Zu den wichtigsten architektonischen Innovationen gehören eine tiefere Modellstruktur mit reduzierter Breite und erhöhter Tiefe für verbessertes Reasoning, das Vortraining auf einem massiven Korpus von 15 Billionen Tokens für umfassendes Wissen sowie die quelloffene „Slime“-RL-Infrastruktur, die für skalierbares, groß angelegtes agentisches Reinforcement Learning entwickelt wurde.
Von Z.AI
Wie viel VRAM benötigt GLM 4.5 für die Inferenz?
Die Modelle können unter den Konfigurationen in der folgenden Tabelle ausgeführt werden:
| Modell | Präzision | GPU-Typ und -Anzahl | Test-Framework |
|---|---|---|---|
| GLM-4.5 | BF16 | H100 x 16 / H200 x 8 | sglang |
| GLM-4.5 | FP8 | H100 x 8 / H200 x 4 | sglang |
| GLM-4.5-Air | BF16 | H100 x 4 / H200 x 2 | sglang |
| GLM-4.5-Air | FP8 | H100 x 2 / H200 x 1 | sglang |
Mit den Konfigurationen in der folgenden Tabelle können die Modelle ihre volle 128K-Kontextlänge nutzen:
| Modell | Präzision | GPU-Typ und -Anzahl | Test-Framework |
|---|---|---|---|
| GLM-4.5 | BF16 | H100 x 32 / H200 x 16 | sglang |
| GLM-4.5 | FP8 | H100 x 16 / H200 x 8 | sglang |
| GLM-4.5-Air | BF16 | H100 x 8 / H200 x 4 | sglang |
| GLM-4.5-Air | FP8 | H100 x 4 / H200 x 2 | sglang |
Wie viel VRAM benötigt GLM 4.5 für das Fine-Tuning?
Der Code kann mit den Konfigurationen in der folgenden Tabelle unter Verwendung von Llama Factory ausgeführt werden:
| Modell | GPU-Typ und -Anzahl | Strategie | Batch-Größe (pro GPU) |
|---|---|---|---|
| GLM-4.5 | H100 x 16 | Lora | 1 |
| GLM-4.5-Air | H100 x 4 | Lora | 1 |
Der Code kann mit den Konfigurationen in der folgenden Tabelle unter Verwendung von Swift ausgeführt werden:
| Modell | GPU-Typ und -Anzahl | Strategie | Batch-Größe (pro GPU) |
|---|---|---|---|
| GLM-4.5 | H20 (96GiB) x 16 | Lora | 1 |
| GLM-4.5-Air | H20 (96GiB) x 4 | Lora | 1 |
| GLM-4.5 | H20 (96GiB) x 128 | SFT | 1 |
| GLM-4.5-Air | H20 (96GiB) x 32 | SFT | 1 |
| GLM-4.5 | H20 (96GiB) x 128 | RL | 1 |
| GLM-4.5-Air | H20 (96GiB) x 32 | RL | 1 |
VRAM-Nutzung von GLM 4.5 bei unterschiedlichen Batch-Größen
| Modell | Präzision | Batch-Größe (pro GPU) | VRAM |
|---|---|---|---|
| GLM-4.5 | FP16 | 1 | 945,36 GB |
| GLM-4.5 | FP16 | 8 | 1128,49 GB |
| GLM-4.5 | FP16 | 16 | 1137,79 GB |
| GLM-4.5 | FP16 | 32 | 1756,38 GB |
| GLM-4.5-Air | FP16 | 1 | 288,68 GB |
| GLM-4.5-Air | FP16 | 8 | 343,58 GB |
| GLM-4.5-Air | FP16 | 16 | 406,33 GB |
| GLM-4.5-Air | FP16 | 32 | 531,83 GB |
Welche Hardware-Anforderungen hat GLM 4.5?
https://www.youtube.com/watch?v=grAXN76\_-Ig
- GPUs:
- Inferenz: 8 × H100/4 × H200 (FP8) oder 16 × H100/8 × H200 (BF16) für das vollständige Modell; die Hälfte für die Air-Variante.
- Fine-Tuning: GPUs mit ≥ 80 GB VRAM.
- CPU & System:
- ≥ 1 TB RAM zum Laden von Modellen und Verwalten von Offload-Puffern.
- Hochgeschwindigkeitsverbindung (NVLink/HPC-Switch) für Multi-GPU-Tensorparallelität.
- Präzision:
- FP8 für minimale VRAM-Nutzung (erfordert GPUs mit nativer FP8-Unterstützung).
- BF16 als Alternative auf GPUs ohne FP8-Unterstützung.
- Software:
- vLLM oder Llama Factory für die Inferenz; Unterstützung für spekulative Dekodierung und CPU-Offload.
Optimierung von GLM 4.5 für geringeren VRAM-Verbrauch
- Modellvarianten: Wählen Sie GLM 4.5-Air (106 B Gesamt/12 B aktiv) für GPU-Setups mit 32–64 GB.
- Wann Sie GLM-4.5-Air wählen sollten:
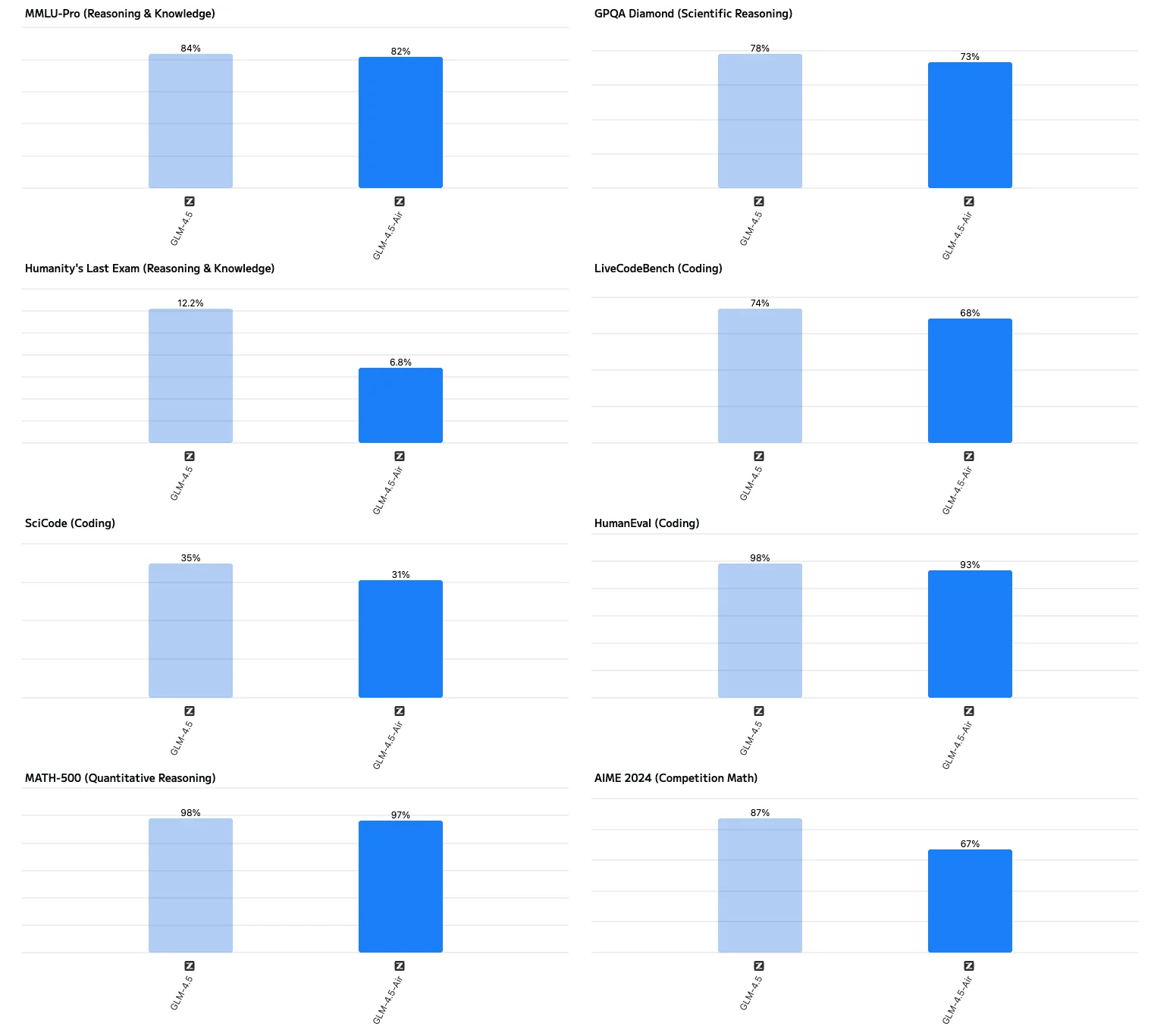
- Deutlich schnellere Generierung:
- GLM-4.5-Air erreicht eine Ausgaberate von etwa 160 Tokens pro Sekunde, fast doppelt so schnell wie das vollständige Modell (ca. 88 Tokens/s). Dies macht die Air-Variante ideal für latenzsensitive Anwendungen.
- Extrem niedrige Latenz für das erste Token (TTFT):
- Die Air-Variante gibt ihr erstes Token in etwa 0,58 Sekunden aus, verglichen mit 0,68 Sekunden für das vollständige Modell. In einigen Tests kann die Latenz des vollständigen Modells bei Einbeziehung der „Denkzeit“ 22–23 Sekunden erreichen.
- Kürzere End-to-End-Antwortzeit:
- Die Air-Variante liefert End-to-End-Antworten (Eingabeverarbeitung, Inferenz und Ausgabe) in etwa 16 Sekunden, während das vollständige Modell fast 29 Sekunden benötigt, was es für Echtzeitinteraktionen weniger geeignet macht.
- Etwas niedrigere Werte bei komplexen Reasoning-Aufgaben:
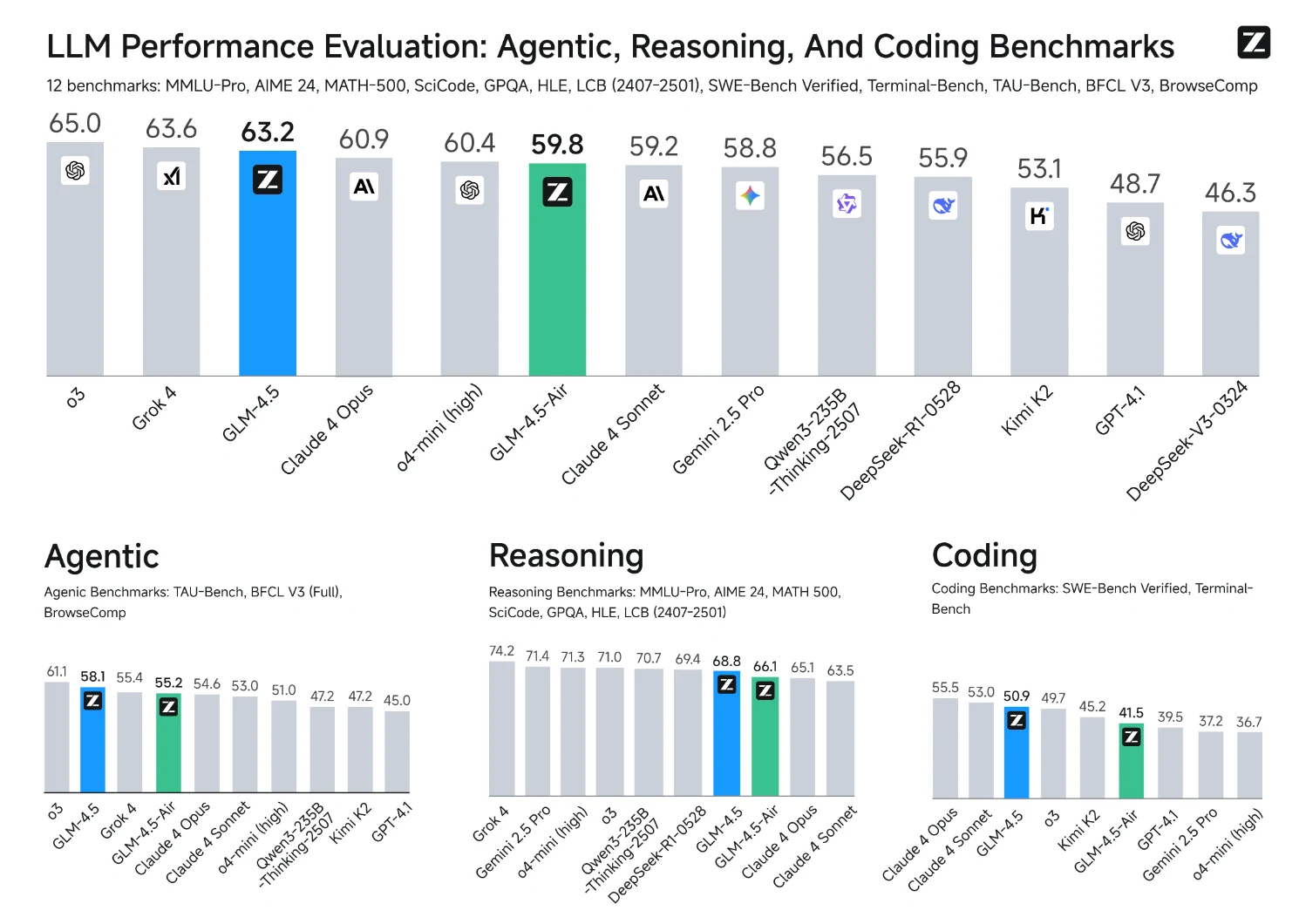
- Bei Reasoning-Benchmarks wie MMLU-Pro, GPQA und AIME liegt die Air-Variante etwa 2–3 % unter dem vollständigen Modell, behält aber dennoch eine branchenführende Leistung bei.
- Für die meisten Anwendungsfälle empfohlen:
- Für die meisten Aufgaben zur Textgenerierung, Zusammenfassung, einfachen Reasoning und Code-Assistenz ist das vollständige Modell nicht erforderlich – die Air-Variante reicht für hohe Leistung und Reaktionsfähigkeit aus.
- Deutlich schnellere Generierung:
- Layer-Offloading: Lagern Sie ausgewählte MoE-Experten oder Feed-Forward-Schichten in den CPU-Speicher aus.
- KV-Cache-Quantisierung: Reduzieren Sie die Cache-Präzision, um VRAM bei geringfügigem Qualitätsverlust zu sparen.
- Batch-Größe = 1: Beschränken Sie die Inferenz auf ein einzelnes Sample pro GPU, um Aktivierungen zu minimieren.
Eine weitere kosteneffektive Option: API
Hier ist ein vereinfachter Vergleich zwischen der Bereitstellung von GLM 4.5 über eine API und der lokalen Ausführung:
| Aspekt | API-Bereitstellung | Lokale Bereitstellung |
|---|---|---|
| Kosten | Pay-per-Use-Preise; beispielsweise Eingabetoken zu 0,6 $ pro Million und Ausgabetoken zu 2,2 ¥ pro Million bei Novita AI | Hohe Anfangsinvestition in Hardware (z. B. NVIDIA A100-GPUs); bei intensiver Nutzung potenziell niedrigere Kosten im Laufe der Zeit. |
| Leistung | Skalierbar mit potenzieller Netzwerklatenz; geeignet für Anwendungen, bei denen leichte Verzögerungen akzeptabel sind. | Niedrigere Latenz und konsistente Leistung; ideal für Echtzeitanwendungen, die sofortige Antworten erfordern. |
| Skalierbarkeit | Einfach skalierbar ohne Verwaltung der Infrastruktur; der Anbieter übernimmt die Skalierung. | Die Skalierung erfordert zusätzliche Hardware und Infrastrukturverwaltung. |
| Datenschutz | Daten werden extern verarbeitet, was insbesondere in regulierten Branchen Datenschutzbedenken aufwerfen kann. | Daten verbleiben im Unternehmen, bieten mehr Kontrolle und Konformität mit Datenschutzbestimmungen. |
| Betriebskomplexität | Minimaler Setup und Wartungsaufwand; der Anbieter verwaltet Updates und Infrastruktur. | Erfordert technisches Fachwissen für Setup, Wartung und Sicherheit; bietet mehr Anpassungsmöglichkeiten. |
| Anpassung | Beschränkt auf die Konfigurationen des Anbieters; weniger Flexibilität für spezifische Anforderungen. | Volle Kontrolle über die Anpassung des Modells, Fine-Tuning und Integration in bestehende Systeme. |
| Eignung für Anwendungsfälle | Ideal für Anwendungen mit variabler oder niedriger Nutzung, schnellen Entwicklungsanforderungen oder begrenzten technischen Ressourcen. | Am besten geeignet für Anwendungen mit hoher, konsistenter Nutzung, strengen Datenschutzanforderungen oder Bedarf an umfangreicher Anpassung. |
So greifen Sie über Novita AI auf GLM 4.5 zu
Novita AI bietet APIs mit 131K Kontext und Kosten von 0,6 $/Eingabe sowie 2,2 $/Ausgabe, die eine starke Unterstützung bei der Maximierung des Code-Agent-Potenzials von GLM 4.5 bieten.
Novita AI
Schritt 1: Anmelden und auf die Modellbibliothek zugreifen
Melden Sie sich bei Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.

Probieren Sie GLM 4.5 jetzt aus!
Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell, das Ihren Anforderungen entspricht.
Schritt 3: Starten Sie Ihre kostenlose Testversion
Starten Sie Ihre kostenlose Testversion, um die Funktionen des ausgewählten Modells zu erkunden.
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung bei der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Auf der Seite „Einstellungen“ können Sie den API-Schlüssel wie in der Abbildung gezeigt kopieren.

Schritt 5: Installieren Sie die API
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.
Nach der Installation importieren Sie die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit dem Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Nutzung der Chat-Completion-API für Python-Nutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_UsudmdAIggvSInjIdO2HWaTCyXxTFOXDV8TH8UCPbA576Rs4AGqSA5ThNbelSDgdEGAWQcWXnAU2bHi5BueceA==",
)
model = "zai-org/glm-4.5"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
GLM-4.5 und seine Air-Variante bieten leistungsstarke Lösungen für agentische Anwendungen mit unterschiedlichen VRAM-Anforderungen, die sich an verschiedene Bereitstellungsszenarien anpassen. Die Bewertung Ihrer spezifischen Anforderungen und Ressourcen hilft Ihnen bei der Wahl zwischen lokaler Bereitstellung und API-basierten Lösungen.
Häufig gestellte Fragen
Wer sollte GLM 4.5 verwenden?
GLM-4.5 ist ideal für Entwickler, Forscher und Unternehmen, die nach fortschrittlichen KI-Agent-Funktionen suchen, insbesondere für Programmier-, Automatisierungs- und Wissensaufgaben.
Was ist GLM-4.5?
GLM-4.5 ist ein fortschrittliches Large Language Model mit einer Mixture-of-Experts-Architektur, das für agentische Anwendungen optimiert ist, die komplexes Reasoning und Tool-Integration erfordern.
Kann ich GLM-4.5 ohne umfangreiche Hardware bereitstellen?
Ja, die Nutzung von GLM-4.5 über eine API ist eine Alternative, die den Bedarf an erheblichen Hardware-Investitionen reduziert, auch wenn dies Überlegungen in Bezug auf Datenschutz und Netzwerklatenz erfordern kann.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für die Erstellung und Skalierung bereitstellt.



