

Você está considerando implantar o GLM-4.5 localmente, mas está preocupado com os substanciais recursos de GPU necessários? O modelo completo GLM-4.5 exige configurações como 16 GPUs NVIDIA H100 ou 8 GPUs H200 com precisão FP8, enquanto a variante mais eficiente em recursos GLM-4.5-Air opera com 2 GPUs H100 ou 1 GPU H200 com precisão FP8. Essas configurações garantem desempenho ideal e suportam o extenso comprimento de contexto do modelo de até 128K tokens.
Neste artigo, vamos explorar os requisitos de VRAM para o GLM-4.5, discutir a viabilidade da implantação local e examinar métodos alternativos para utilizar efetivamente esse poderoso modelo de linguagem.
Requisitos de VRAM do GLM 4.5
O GLM-4.5 é o avanço mais recente da família GLM, apresentando uma arquitetura sofisticada de Mixture-of-Experts (MoE) e otimização para aplicações agenticas. O modelo vem em duas variantes: o principal GLM-4.5 com 355 bilhões de parâmetros totais (32 bilhões ativos), e o eficiente GLM-4.5-Air com 106 bilhões de parâmetros totais (12 bilhões ativos).
Principais inovações arquitetônicas incluem uma estrutura de modelo mais profunda com largura reduzida e profundidade aumentada para raciocínio aprimorado, pré-treinamento em um corpus massivo de 15 trilhões de tokens para conhecimento abrangente, e a infraestrutura de RL de código aberto “slime” projetada para aprendizado por reforço agentico escalável e em larga escala.
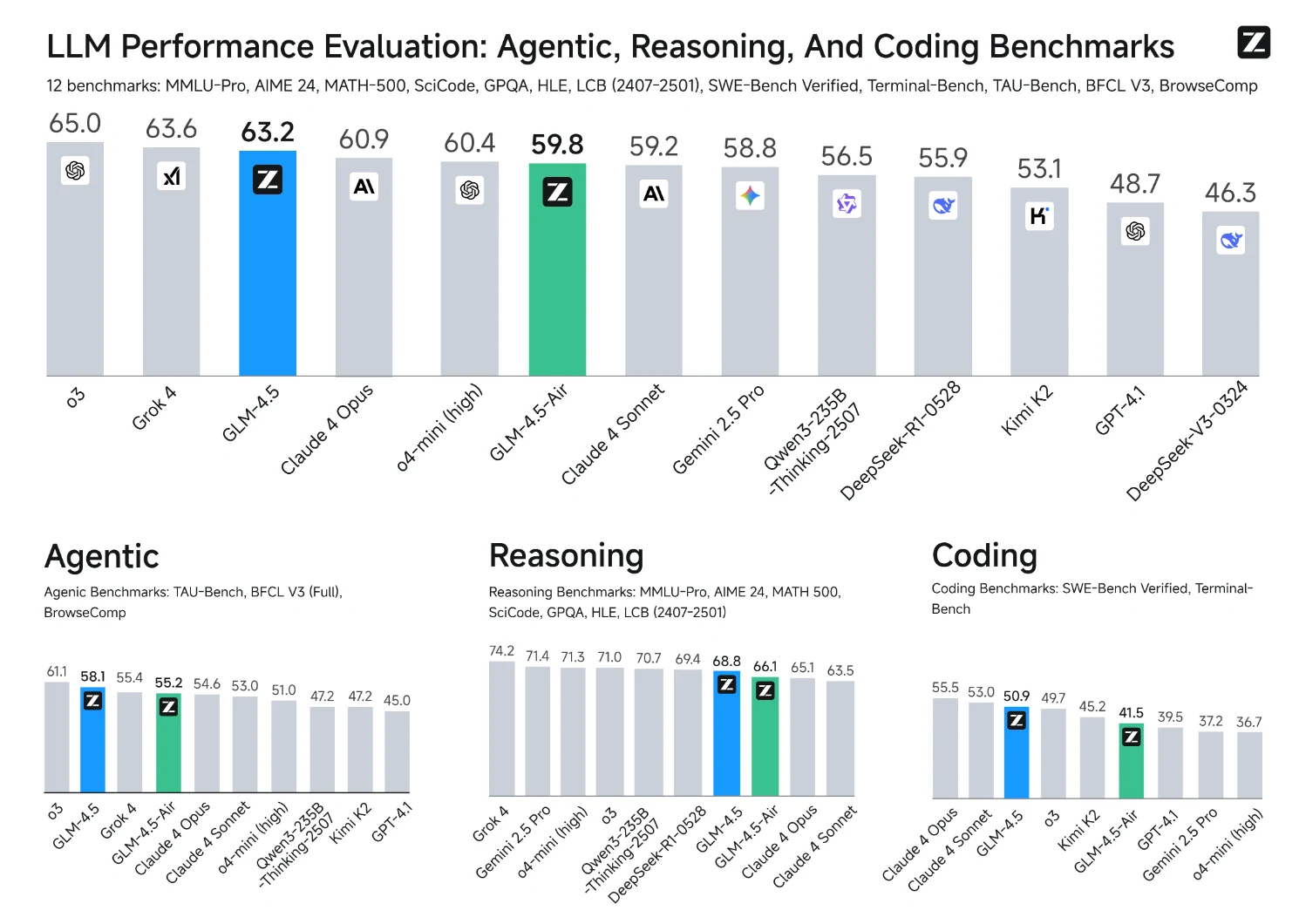
De Z.AI
Quanta VRAM o GLM 4.5 precisa para inferência?
Os modelos podem ser executados nas configurações da tabela abaixo:
| Modelo | Precisão | Tipo e Quantidade de GPU | Framework de Teste |
|---|---|---|---|
| GLM-4.5 | BF16 | H100 x 16 / H200 x 8 | sglang |
| GLM-4.5 | FP8 | H100 x 8 / H200 x 4 | sglang |
| GLM-4.5-Air | BF16 | H100 x 4 / H200 x 2 | sglang |
| GLM-4.5-Air | FP8 | H100 x 2 / H200 x 1 | sglang |
Nas configurações da tabela abaixo, os modelos podem utilizar seu comprimento de contexto completo de 128K:
| Modelo | Precisão | Tipo e Quantidade de GPU | Framework de Teste |
|---|---|---|---|
| GLM-4.5 | BF16 | H100 x 32 / H200 x 16 | sglang |
| GLM-4.5 | FP8 | H100 x 16 / H200 x 8 | sglang |
| GLM-4.5-Air | BF16 | H100 x 8 / H200 x 4 | sglang |
| GLM-4.5-Air | FP8 | H100 x 4 / H200 x 2 | sglang |
Quanta VRAM o GLM 4.5 precisa para ajuste fino?
O código pode ser executado nas configurações da tabela abaixo usando o Llama Factory:
| Modelo | Tipo e Quantidade de GPU | Estratégia | Tamanho do Lote (por GPU) |
|---|---|---|---|
| GLM-4.5 | H100 x 16 | Lora | 1 |
| GLM-4.5-Air | H100 x 4 | Lora | 1 |
O código pode ser executado nas configurações da tabela abaixo usando o Swift:
| Modelo | Tipo e Quantidade de GPU | Estratégia | Tamanho do Lote (por GPU) |
|---|---|---|---|
| GLM-4.5 | H20 (96GiB) x 16 | Lora | 1 |
| GLM-4.5-Air | H20 (96GiB) x 4 | Lora | 1 |
| GLM-4.5 | H20 (96GiB) x 128 | SFT | 1 |
| GLM-4.5-Air | H20 (96GiB) x 32 | SFT | 1 |
| GLM-4.5 | H20 (96GiB) x 128 | RL | 1 |
| GLM-4.5-Air | H20 (96GiB) x 32 | RL | 1 |
Uso de VRAM do GLM 4.5 com diferentes tamanhos de lote
| Modelo | Precisão | Tamanho do Lote (por GPU) | VRAM |
|---|---|---|---|
| GLM-4.5 | FP16 | 1 | 945,36GB |
| GLM-4.5 | FP16 | 8 | 1128,49GB |
| GLM-4.5 | FP16 | 16 | 1137,79GB |
| GLM-4.5 | FP16 | 32 | 1756,38GB |
| GLM-4.5-Air | FP16 | 1 | 288,68GB |
| GLM-4.5-Air | FP16 | 8 | 343,58GB |
| GLM-4.5-Air | FP16 | 16 | 406,33GB |
| GLM-4.5-Air | FP16 | 32 | 531,83GB |
Quais são os Requisitos de Hardware para o GLM 4.5?
https://www.youtube.com/watch?v=grAXN76\_-Ig
- GPUs:
- Inferência: 8 × H100/4 × H200 (FP8) ou 16 × H100/8 × H200 (BF16) para o modelo completo; metade para a variante Air.
- Ajuste fino: GPUs com ≥ 80 GB de VRAM.
- CPU e Sistema:
- ≥ 1 TB de RAM para carregar modelos e gerenciar buffers de descarregamento.
- Interconexão de alta largura de banda (NVLink/switch HPC) para paralelismo de tensores multi-GPU.
- Precisão:
- FP8 para uso mínimo de VRAM (requer GPUs com suporte nativo a FP8).
- BF16 como alternativa em GPUs sem suporte a FP8.
- Software:
- vLLM ou Llama Factory para inferência; suporte a decodificação especulativa e descarregamento para CPU.
Otimizando o GLM 4.5 para menor consumo de VRAM
- Variantes de Modelo: Escolha o GLM 4.5-Air (106 B no total/12 B ativos) para configurações de GPU de 32 a 64 GB.
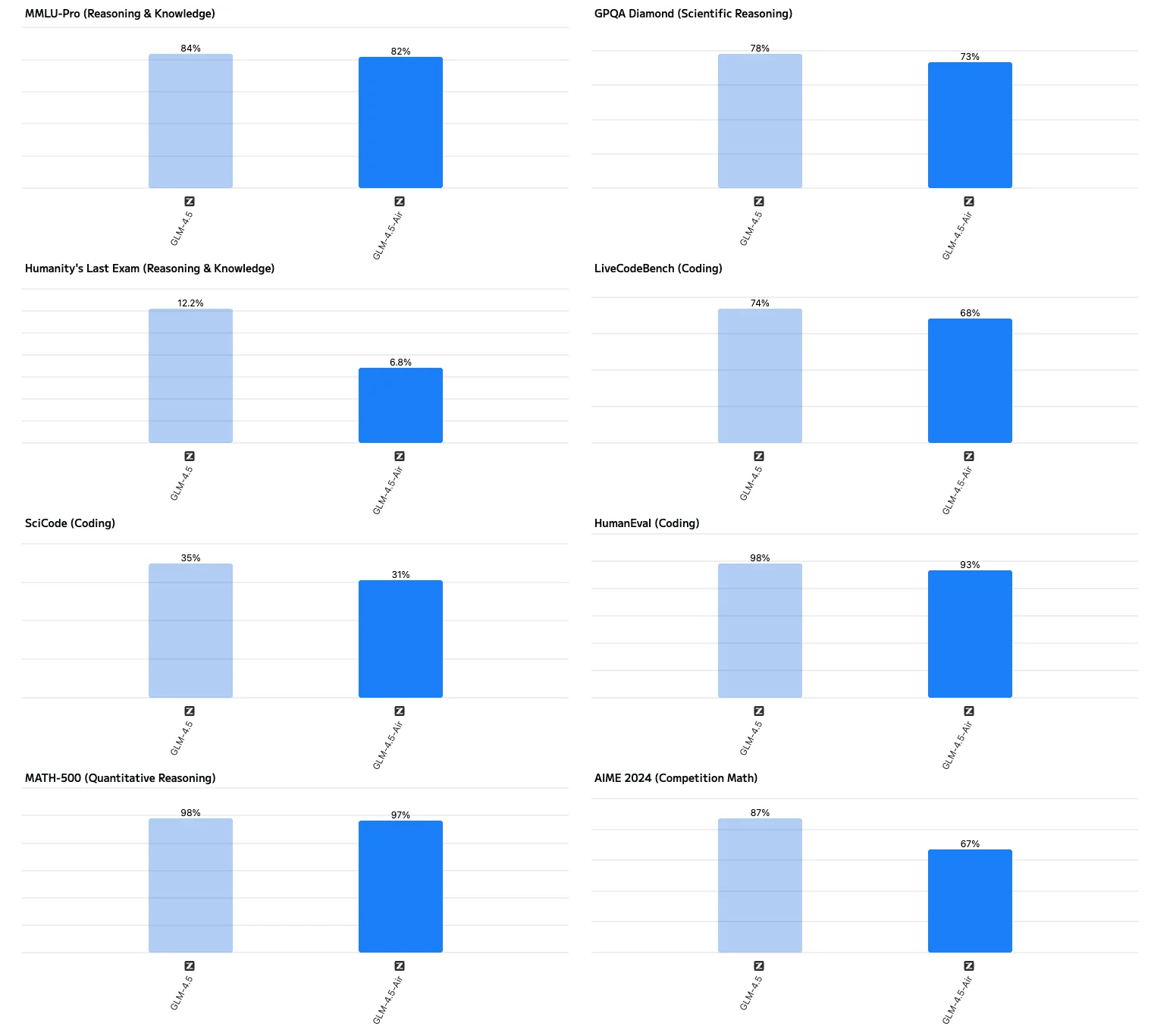
- Quando escolher o GLM-4.5-Air:
- Geração significativamente mais rápida:
- O GLM-4.5-Air atinge uma taxa de saída de cerca de 160 tokens por segundo, quase duas vezes mais rápido que o modelo de tamanho completo (aproximadamente 88 tokens/s). Isso torna o Air ideal para aplicações sensíveis à latência.
- Latência do primeiro token (TTFT) extremamente baixa:
- O Air emite seu primeiro token em cerca de 0,58 segundos, contra 0,68 segundos do modelo de tamanho completo. Em alguns testes, a latência do modelo de tamanho completo pode chegar a 22 a 23 segundos quando incluído o tempo de “pensamento”.
- Tempo de resposta ponta a ponta mais curto:
- O Air fornece respostas ponta a ponta (processamento de entrada, inferência e saída) em cerca de 16 segundos, enquanto o modelo de tamanho completo leva quase 29 segundos, tornando o modelo de tamanho completo menos adequado para interações em tempo real.
- Pontuações ligeiramente menores em tarefas de raciocínio complexo:
- Em benchmarks de raciocínio como MMLU-Pro, GPQA e AIME, o Air tem pontuação cerca de 2 a 3% menor que o modelo de tamanho completo, mas ainda mantém desempenho líder na indústria.
- Recomendado para a maioria dos casos de uso:
- Para a maioria das tarefas de geração de texto, sumarização, raciocínio básico e assistência de código, o modelo de tamanho completo não é necessário — o Air é suficiente para alto desempenho e responsividade.
- Geração significativamente mais rápida:
- Descarregamento de Camadas: Descarregue especialistas MoE selecionados ou camadas de feed-forward para a memória da CPU.
- Quantização do KV-Cache: Reduza a precisão do cache para economizar VRAM com um custo de qualidade mínimo.
- Tamanho do Lote = 1: Limite a inferência de amostra única por GPU para minimizar as ativações.
Outra Opção Econômica: API
Aqui está uma comparação simplificada entre implantar o GLM 4.5 via API e executá-lo localmente:
| Aspecto | Implantação via API | Implantação Local |
|---|---|---|
| Custo | Precificação por uso; por exemplo, tokens de entrada a $0,6 por milhão e tokens de saída a ¥2,2 por milhão na Novita AI | Alto investimento inicial em hardware (ex: GPUs NVIDIA A100); custos potencialmente menores ao longo do tempo para uso intensivo. |
| Desempenho | Escalável com possível latência de rede; adequado para aplicações onde pequenos atrasos são aceitáveis. | Latência menor e desempenho consistente; ideal para aplicações em tempo real que exigem respostas imediatas. |
| Escalabilidade | Facilmente escalável sem gerenciamento de infraestrutura; o provedor gerencia a escalabilidade. | A escalabilidade requer hardware adicional e gerenciamento de infraestrutura. |
| Privacidade de Dados | Os dados são processados externamente, o que pode levantar preocupações de privacidade, especialmente em setores regulamentados. | Os dados permanecem internamente, oferecendo maior controle e conformidade com regulamentações de proteção de dados. |
| Complexidade Operacional | Configuração e manutenção mínimas; o provedor gerencia atualizações e infraestrutura. | Requer expertise técnica para configuração, manutenção e segurança; oferece maior personalização. |
| Personalização | Limitado às configurações do provedor; menos flexibilidade para necessidades específicas. | Controle total sobre a personalização do modelo, ajuste fino e integração com sistemas existentes. |
| Adequação aos Casos de Uso | Ideal para aplicações com uso variável ou baixo, necessidades de desenvolvimento rápido ou recursos técnicos limitados. | Melhor para aplicações com uso alto e consistente, requisitos rigorosos de privacidade de dados ou necessidade de personalização extensiva. |
Como acessar o GLM 4.5 via Novita AI?
A Novita AI fornece APIs com contexto de 131K, e custos de $0,6/entrada e $2,2/saída, oferecendo forte suporte para maximizar o potencial do agente de código do GLM 4.5.
Novita AI
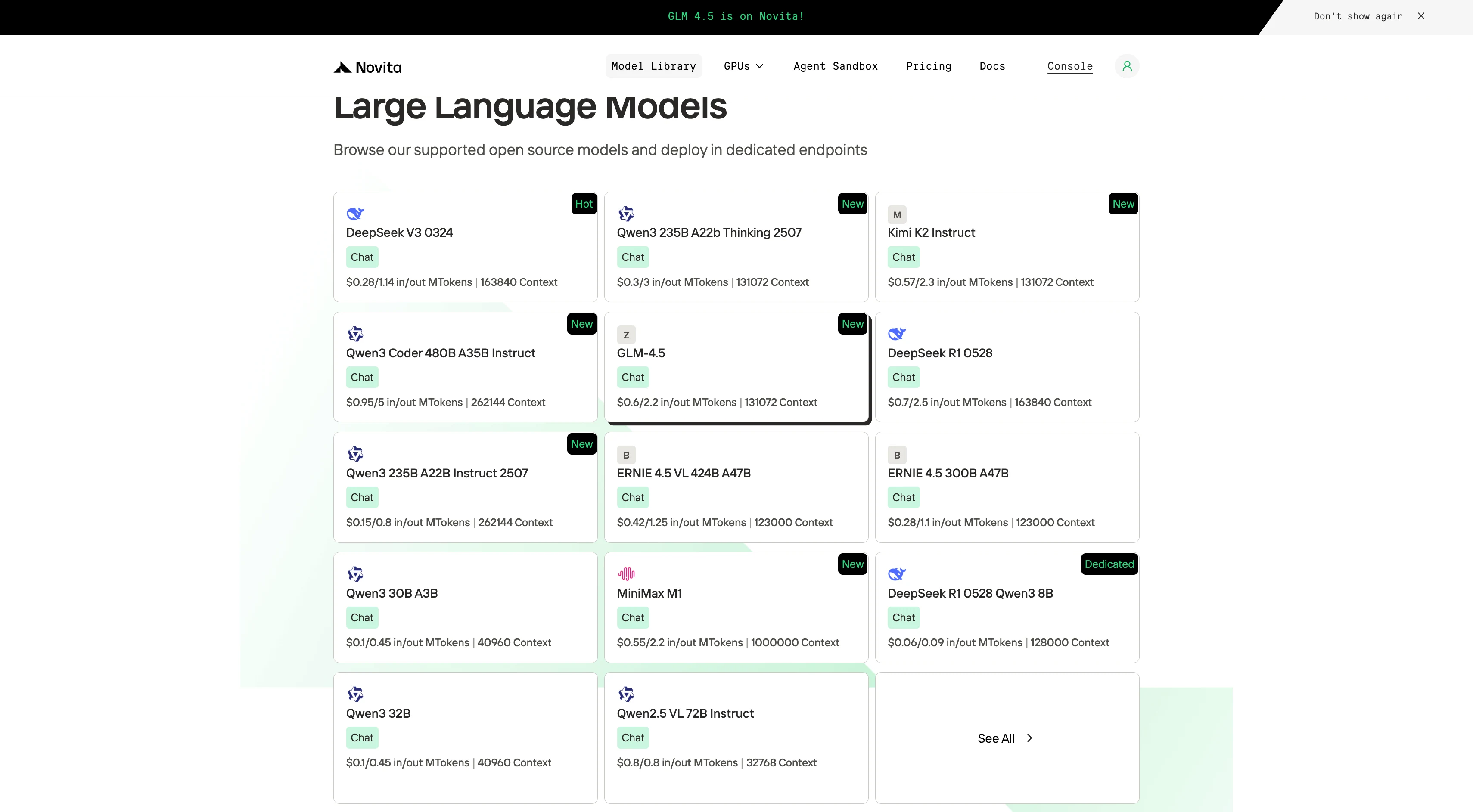
Passo 1: Faça login e acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Biblioteca de Modelos.

Passo 2: Escolha seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que melhor atende às suas necessidades.
Passo 3: Inicie seu Teste Gratuito
Comece seu teste gratuito para explorar as capacidades do modelo selecionado.
Passo 4: Obtenha sua Chave de API
Para autenticar com a API, forneceremos uma nova chave de API. Ao acessar a página de “Configurações”, você pode copiar a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico da sua linguagem de programação.
Após a instalação, importe as bibliotecas necessárias para o seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o LLM da Novita AI. Este é um exemplo de uso da API de conclusões de chat para usuários de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_UsudmdAIggvSInjIdO2HWaTCyXxTFOXDV8TH8UCPbA576Rs4AGqSA5ThNbelSDgdEGAWQcWXnAU2bHi5BueceA==",
)
model = "zai-org/glm-4.5"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
O GLM-4.5 e sua variante Air fornecem soluções poderosas para aplicações agenticas, com requisitos de VRAM variados para se adequar a diferentes cenários de implantação. Avaliar suas necessidades e recursos específicos irá guiá-lo na escolha entre implantação local e soluções baseadas em API.
Perguntas Frequentes
Quem deve usar o GLM 4.5?
O GLM-4.5 é ideal para desenvolvedores, pesquisadores e empresas que buscam recursos avançados de agentes de IA, especialmente para tarefas de codificação, automação e conhecimento.
O que é o GLM-4.5?
O GLM-4.5 é um modelo de linguagem grande avançado, com arquitetura de Mixture-of-Experts, otimizado para aplicações agenticas que exigem raciocínio complexo e integração de ferramentas.
Posso implantar o GLM-4.5 sem hardware extenso?
Sim, utilizar o GLM-4.5 através de uma API é uma alternativa que reduz a necessidade de investimento significativo em hardware, embora possa envolver considerações sobre privacidade de dados e latência de rede.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construção e escalonamento.



