

ローカル環境でGLM-4.5をデプロイすることを検討しているが、必要なGPUリソースの多さが気になっていませんか? フルサイズのGLM-4.5モデルは、FP8精度でNVIDIA H100 GPU 16台、またはH200 GPU 8台の構成が必要ですが、リソース効率の高いGLM-4.5-AirバリアントはFP8精度でH100 GPU 2台、またはH200 GPU 1台で動作します。これらの構成は最適なパフォーマンスを実現し、最大128Kトークンの長いコンテキスト長をサポートします。
本記事では、GLM-4.5のVRAM要件を解説し、ローカルデプロイの実現可能性を検討し、この強力な言語モデルを効果的に活用する代替手段について考察します。
GLM 4.5のVRAM要件
GLM-4.5はGLMファミリーの最新の成果で、高度なMixture-of-Experts(MoE)アーキテクチャを搭載し、エージェント向けアプリケーションに最適化されています。このモデルには2つのバリアントがあります:フラッグシップモデルのGLM-4.5は総パラメータ数3550億(アクティブパラメータ数320億)、効率性の高いGLM-4.5-Airは総パラメータ数1060億(アクティブパラメータ数120億)です。
主なアーキテクチャの革新点には、推論性能向上のために幅を縮小し深さを増したより深いモデル構造、包括的な知識のための15兆トークンの大規模コーパスでの事前学習、スケーラブルな大規模エージェント強化学習向けに設計されたオープンソースの「slime」RLインフラが含まれます。
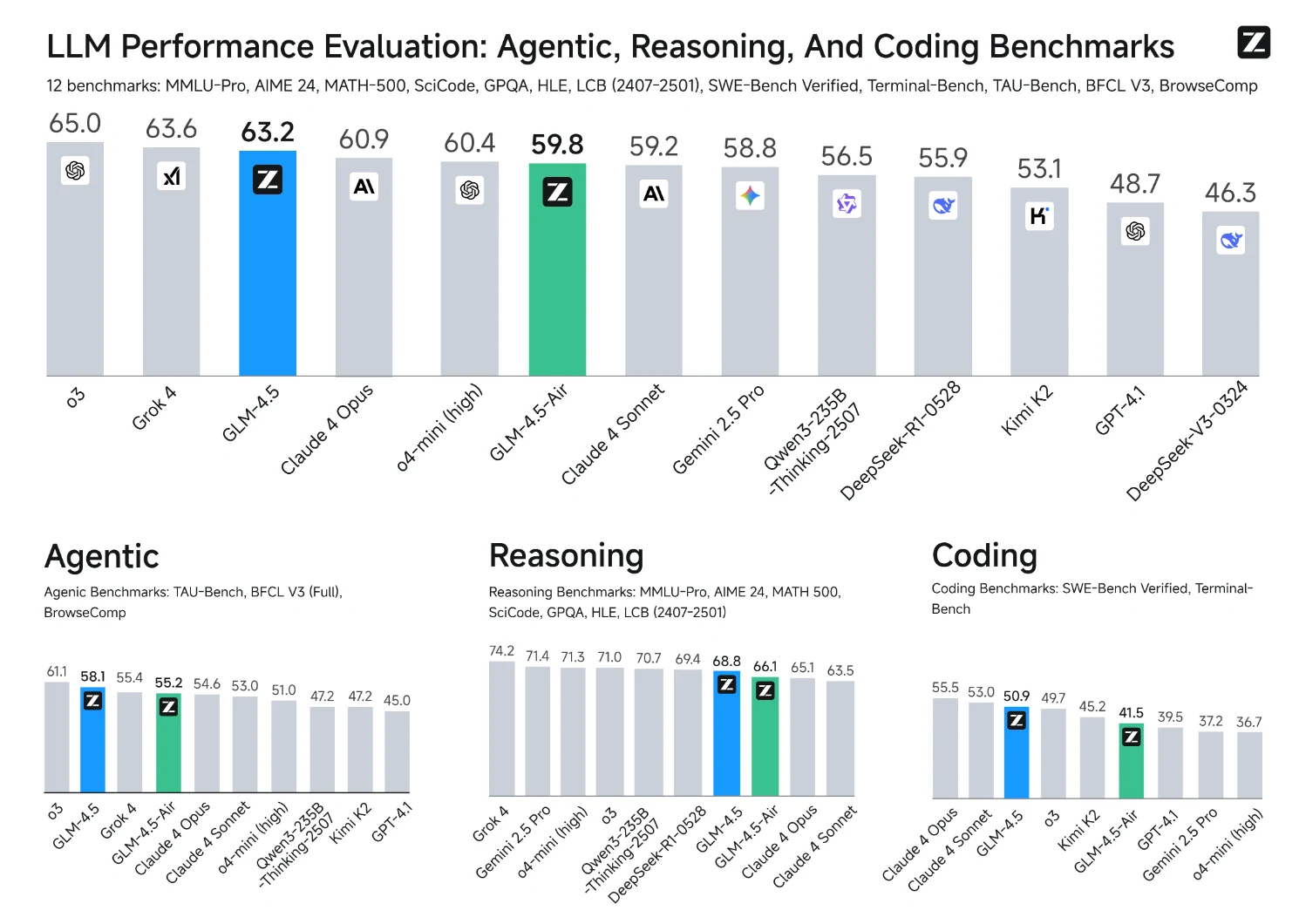
出典:Z.AI
GLM 4.5の推論に必要なVRAM容量は?
以下の表の構成でモデルを動作させることができます:
| モデル | 精度 | GPU種別と台数 | テストフレームワーク |
|---|---|---|---|
| GLM-4.5 | BF16 | H100 x 16 / H200 x 8 | sglang |
| GLM-4.5 | FP8 | H100 x 8 / H200 x 4 | sglang |
| GLM-4.5-Air | BF16 | H100 x 4 / H200 x 2 | sglang |
| GLM-4.5-Air | FP8 | H100 x 2 / H200 x 1 | sglang |
以下の表の構成では、モデルは最大128Kのコンテキスト長をフルに活用できます:
| モデル | 精度 | GPU種別と台数 | テストフレームワーク |
|---|---|---|---|
| GLM-4.5 | BF16 | H100 x 32 / H200 x 16 | sglang |
| GLM-4.5 | FP8 | H100 x 16 / H200 x 8 | sglang |
| GLM-4.5-Air | BF16 | H100 x 8 / H200 x 4 | sglang |
| GLM-4.5-Air | FP8 | H100 x 4 / H200 x 2 | sglang |
GLM 4.5のファインチューニングに必要なVRAM容量は?
Llama Factoryを使用した場合、以下の表の構成でコードを実行できます:
| モデル | GPU種別と台数 | 戦略 | バッチサイズ(GPUごと) |
|---|---|---|---|
| GLM-4.5 | H100 x 16 | Lora | 1 |
| GLM-4.5-Air | H100 x 4 | Lora | 1 |
Swiftを使用した場合、以下の表の構成でコードを実行できます:
| モデル | GPU種別と台数 | 戦略 | バッチサイズ(GPUごと) |
|---|---|---|---|
| GLM-4.5 | H20 (96GiB) x 16 | Lora | 1 |
| GLM-4.5-Air | H20 (96GiB) x 4 | Lora | 1 |
| GLM-4.5 | H20 (96GiB) x 128 | SFT | 1 |
| GLM-4.5-Air | H20 (96GiB) x 32 | SFT | 1 |
| GLM-4.5 | H20 (96GiB) x 128 | RL | 1 |
| GLM-4.5-Air | H20 (96GiB) x 32 | RL | 1 |
バッチサイズごとのGLM 4.5のVRAM使用量
| モデル | 精度 | バッチサイズ(GPUごと) | VRAM |
|---|---|---|---|
| GLM-4.5 | FP16 | 1 | 945.36GB |
| GLM-4.5 | FP16 | 8 | 1128.49GB |
| GLM-4.5 | FP16 | 16 | 1137.79GB |
| GLM-4.5 | FP16 | 32 | 1756.38GB |
| GLM-4.5-Air | FP16 | 1 | 288.68GB |
| GLM-4.5-Air | FP16 | 8 | 343.58GB |
| GLM-4.5-Air | FP16 | 16 | 406.33GB |
| GLM-4.5-Air | FP16 | 32 | 531.83GB |
GLM 4.5のハードウェア要件は?
https://www.youtube.com/watch?v=grAXN76\_-Ig
- GPU:
- 推論:フルサイズモデルはFP8精度でH100 x 8 / H200 x 4、BF16精度でH100 x 16 / H200 x 8。Airバリアントはこの半分の構成で動作します。
- ファインチューニング:80GB以上のVRAMを搭載したGPUが必要です。
- CPUとシステム:
- モデルの読み込みとオフロードバッファの管理のために1TB以上のRAMが必要です。
- マルチGPUでのテンソル並列処理のために、高速インターコネクト(NVLink/HPCスイッチ)が必要です。
- 精度:
- VRAM使用量を最小限に抑えるにはFP8が推奨(ネイティブFP8対応のGPUが必要です)。
- FP8非対応のGPUではBF16を代替として使用できます。
- ソフトウェア:
- 推論にはvLLMまたはLlama Factoryを使用。スペキュレーティブデコードやCPUオフロードをサポートしています。
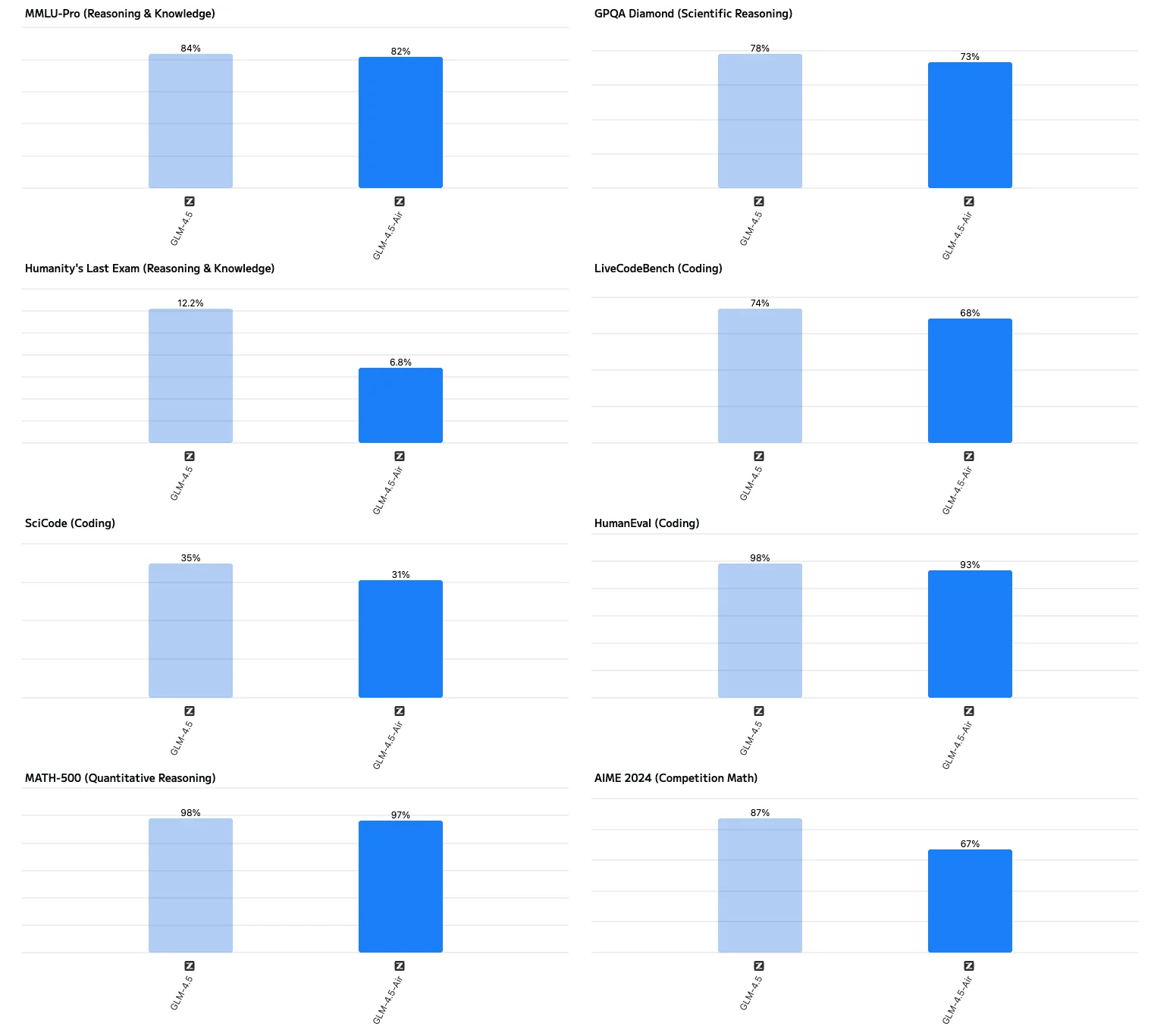
GLM 4.5のVRAM使用量を削減する最適化方法
- モデルバリアントの選択: 32〜64GBのGPU環境では、GLM 4.5-Air(総パラメータ1060億 / アクティブパラメータ120億)を選択しましょう。
- GLM-4.5-Airを選択すべき場面:
- 生成速度が大幅に高速:
- GLM-4.5-Airは1秒あたり約160トークンの出力速度を実現し、フルサイズモデル(約88トークン/秒)のほぼ2倍の速度です。レイテンシーが重視されるアプリケーションに最適です。
- 最初のトークンのレイテンシー(TTFT)が極めて低い:
- Airは最初のトークンを約0.58秒で出力するのに対し、フルサイズモデルは0.68秒です。一部のテストでは、「思考」時間を含むフルサイズモデルのレイテンシーが22〜23秒に達することもあります。
- エンドツーエンドの応答時間が短い:
- Airは入力処理・推論・出力を含むエンドツーエンドの応答を約16秒で完了するのに対し、フルサイズモデルは約29秒かかります。リアルタイムの対話にはフルサイズモデルは適していません。
- 複雑な推論タスクのスコアがわずかに低い:
- MMLU-Pro、GPQA、AIMEなどの推論ベンチマークでは、Airのスコアはフルサイズモデルより2〜3%低いものの、業界最高水準の性能を維持しています。
- ほとんどのユースケースで推奨:
- テキスト生成、要約、基本的な推論、コード支援タスクの大半では、フルサイズモデルは不要です。Airで十分な高性能と応答性を提供します。
- 生成速度が大幅に高速:
- レイヤーのオフロード: 選択したMoEエキスパートやフィードフォワード層をCPUメモリにオフロードします。
- KVキャッシュの量子化: キャッシュの精度を下げることで、わずかな品質の低下と引き換えにVRAMを節約できます。
- バッチサイズ = 1: アクティベーションを最小限に抑えるため、GPUごとに単一サンプルの推論に制限します。
コスト効率の高い代替手段:API
API経由でGLM 4.5をデプロイする場合とローカルで実行する場合の比較を以下に示します:
| 項目 | APIデプロイ | ローカルデプロイ |
|---|---|---|
| コスト | 従量課金制。例えばNovita AIでは入力トークン100万件あたり0.6ドル、出力トークン100万件あたり2.2ドル | ハードウェア(NVIDIA A100 GPUなど)への初期投資が高額だが、大量利用時は長期的にコストが低くなる可能性があります。 |
| パフォーマンス | スケーラブルだがネットワークレイテンシの可能性があり、多少の遅延が許容されるアプリケーションに適している | レイテンシーが低く性能が安定。即時応答が求められるリアルタイムアプリケーションに最適です。 |
| スケーラビリティ | インフラ管理が不要で容易にスケーラブル。プロバイダーがスケーリングを管理します | スケーリングには追加のハードウェアとインフラ管理が必要です。 |
| データプライバシー | データが外部で処理されるため、特に規制産業ではプライバシー上の懸念が生じる可能性があります | データは社内に留まるため、データ保護規制への対応や管理の自由度が高まります。 |
| 運用の複雑さ | セットアップとメンテナンスが最小限。プロバイダーがアップデートとインフラを管理します | セットアップ、メンテナンス、セキュリティに技術的専門知識が必要ですが、カスタマイズの自由度が高まります。 |
| カスタマイズ性 | プロバイダーの設定に限定されるため、特定のニーズへの柔軟性が低い | モデルのカスタマイズ、ファインチューニング、既存システムとの連携を完全に制御できます。 |
| ユースケースの適合性 | 利用量が変動的または低い場合、迅速な開発が必要な場合、技術的リソースが限られている場合に最適 | 利用量が多く安定している場合、厳格なデータプライバシー要件がある場合、または高度なカスタマイズが必要な場合に最適です。 |
Novita AI経由でGLM 4.5を利用する方法は?
Novita AIは131Kのコンテキスト長をサポートするAPIを提供しており、料金は入力トークン100万件あたり0.6ドル、出力トークン100万件あたり2.2ドルで、GLM 4.5のコードエージェントの可能性を最大限に引き出すための強力なサポートを提供します。
Novita AI
ステップ1:ログインしてモデルライブラリにアクセスする
アカウントにログインし、モデルライブラリボタンをクリックしてください。

ステップ2:モデルを選択する
利用可能なオプションを閲覧し、ニーズに合ったモデルを選択してください。
ステップ3:無料トライアルを開始する
選択したモデルの機能を探索するために、無料トライアルを開始してください。
ステップ4:APIキーを取得する
APIでの認証のために、新しいAPIキーを発行します。「設定」ページに移動すると、画像の指示に従ってAPIキーをコピーできます。

ステップ5:APIをインストールする
使用しているプログラミング言語に対応したパッケージマネージャーを使用してAPIをインストールしてください。
インストール後、開発環境に必要なライブラリをインポートしてください。APIキーでAPIを初期化することで、Novita AIのLLMとの対話を開始できます。以下はPythonユーザー向けのチャット補完APIの使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_UsudmdAIggvSInjIdO2HWaTCyXxTFOXDV8TH8UCPbA576Rs4AGqSA5ThNbelSDgdEGAWQcWXnAU2bHi5BueceA==",
)
model = "zai-org/glm-4.5"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
GLM-4.5とそのAirバリアントは、エージェント向けアプリケーションに強力なソリューションを提供しており、異なるデプロイシナリオに合わせてVRAM要件も異なります。具体的なニーズとリソースを評価することで、ローカルデプロイとAPIベースのソリューションのどちらを選択するか判断できます。
よくある質問
GLM 4.5は誰が使用すべきですか?
GLM-4.5は、コーディング、自動化、知識タスク向けに高度なAIエージェント機能を求める開発者、研究者、企業に最適です。
GLM-4.5とは何ですか?
GLM-4.5は、複雑な推論とツール統合を必要とするエージェント向けアプリケーションに最適化された、Mixture-of-Expertsアーキテクチャを搭載した高度な大規模言語モデルです。
大規模なハードウェアがなくてもGLM-4.5をデプロイできますか?
はい、API経由でGLM-4.5を利用することで、大規模なハードウェア投資の必要性を減らすことができます。ただし、データプライバシーやネットワークレイテンシに関する検討が必要になる場合があります。
Novita AIは、シンプルなAPIを使用してAIモデルを簡単にデプロイできる開発者向けAIクラウドプラットフォームであり、構築とスケーリングのための手頃で信頼性の高いGPUクラウドも提供しています。



