

هل تفكر في نشر نموذج GLM-4.5 محليًا ولكنك قلق بشأن الموارد الكبيرة لوحدات المعالجة الرسومية (GPU) المطلوبة؟ يتطلب النموذج الكامل لـ GLM-4.5 تكوينات مثل 16 وحدة معالجة رسومية من NVIDIA H100 أو 8 وحدات من H200 بدقة FP8، بينما يعمل البديل الأكثر كفاءة في استخدام الموارد GLM-4.5-Air على وحدتي H100 أو وحدة واحدة من H200 بدقة FP8. تضمن هذه الإعدادات الأداء الأمثل ويدعم طول السياق الواسع للنموذج يصل إلى 128 ألف رمز.
في هذا المقال، سنستكشف متطلبات ذاكرة الفيديو (VRAM) لنموذج GLM-4.5، ونناقش جدوى النشر المحلي، ونفحص طرقًا بديلة لاستخدام هذا النموذج اللغوي القوي بشكل فعال.
متطلبات ذاكرة الفيديو (VRAM) لنموذج GLM 4.5
يعد نموذج GLM-4.5 أحدث تطور في عائلة GLM، ويتميز بهندسة معقدة من نوع خلط الخبراء (Mixture-of-Experts, MoE) ومحسّن للتطبيقات القائمة على الوكلاء (agentic). يأتي النموذج في نسختين: النسخة الرئيسية GLM-4.5 التي تحتوي على 355 مليار معامل إجمالي (32 مليار معامل نشط)، والنسخة الفعالة GLM-4.5-Air التي تحتوي على 106 مليار معامل إجمالي (12 مليار معامل نشط).
تشمل الابتكارات المعمارية الرئيسية هيكل نموذج أعمق مع عرض أقل وعمق أكبر لتعزيز الاستدلال، ومرحلة ما قبل التدريب على مجموعة ضخمة من الرموز تبلغ 15 تريليون رمز لمعرفة شاملة، وبنية تحتية مفتوحة المصدر للتعلم المعزز (RL) المسماة “slime” المصممة للتعلم المعزز القابل للتطوير على نطاق واسع للتطبيقات القائمة على الوكلاء.
من Z.AI
كم كمية ذاكرة الفيديو (VRAM) التي يحتاجها نموذج GLM 4.5 للاستدلال؟
يمكن تشغيل النماذج ضمن التكوينات الموضحة في الجدول أدناه:
| النموذج | الدقة | نوع وعدد وحدات المعالجة الرسومية (GPU) | إطار الاختبار |
|---|---|---|---|
| GLM-4.5 | BF16 | H100 × 16 / H200 × 8 | sglang |
| GLM-4.5 | FP8 | H100 × 8 / H200 × 4 | sglang |
| GLM-4.5-Air | BF16 | H100 × 4 / H200 × 2 | sglang |
| GLM-4.5-Air | FP8 | H100 × 2 / H200 × 1 | sglang |
ضمن التكوينات الموضحة في الجدول أدناه، يمكن للنماذج استخدام طول السياق الكامل البالغ 128 ألف رمز:
| النموذج | الدقة | نوع وعدد وحدات المعالجة الرسومية (GPU) | إطار الاختبار |
|---|---|---|---|
| GLM-4.5 | BF16 | H100 × 32 / H200 × 16 | sglang |
| GLM-4.5 | FP8 | H100 × 16 / H200 × 8 | sglang |
| GLM-4.5-Air | BF16 | H100 × 8 / H200 × 4 | sglang |
| GLM-4.5-Air | FP8 | H100 × 4 / H200 × 2 | sglang |
كم كمية ذاكرة الفيديو (VRAM) التي يحتاجها نموذج GLM 4.5 للضبط الدقيق (fine-tuning)؟
يمكن تشغيل الكود ضمن التكوينات الموضحة في الجدول أدناه باستخدام Llama Factory:
| النموذج | نوع وعدد وحدات المعالجة الرسومية (GPU) | الاستراتيجية | حجم الدفعة (لكل وحدة معالجة رسومية) |
|---|---|---|---|
| GLM-4.5 | H100 × 16 | Lora | 1 |
| GLM-4.5-Air | H100 × 4 | Lora | 1 |
يمكن تشغيل الكود ضمن التكوينات الموضحة في الجدول أدناه باستخدام Swift:
| النموذج | نوع وعدد وحدات المعالجة الرسومية (GPU) | الاستراتيجية | حجم الدفعة (لكل وحدة معالجة رسومية) |
|---|---|---|---|
| GLM-4.5 | H20 (96GiB) × 16 | Lora | 1 |
| GLM-4.5-Air | H20 (96GiB) × 4 | Lora | 1 |
| GLM-4.5 | H20 (96GiB) × 128 | SFT | 1 |
| GLM-4.5-Air | H20 (96GiB) × 32 | SFT | 1 |
| GLM-4.5 | H20 (96GiB) × 128 | RL | 1 |
| GLM-4.5-Air | H20 (96GiB) × 32 | RL | 1 |
استخدام ذاكرة الفيديو (VRAM) لنموذج GLM 4.5 مع أحجام دفعات مختلفة
| النموذج | الدقة | حجم الدفعة (لكل وحدة معالجة رسومية) | ذاكرة الفيديو (VRAM) |
|---|---|---|---|
| GLM-4.5 | FP16 | 1 | 945.36GB |
| GLM-4.5 | FP16 | 8 | 1128.49GB |
| GLM-4.5 | FP16 | 16 | 1137.79GB |
| GLM-4.5 | FP16 | 32 | 1756.38GB |
| GLM-4.5-Air | FP16 | 1 | 288.68GB |
| GLM-4.5-Air | FP16 | 8 | 343.58GB |
| GLM-4.5-Air | FP16 | 16 | 406.33GB |
| GLM-4.5-Air | FP16 | 32 | 531.83GB |
ما هي متطلبات الأجهزة لنموذج GLM 4.5؟
https://www.youtube.com/watch?v=grAXN76\_-Ig
- وحدات المعالجة الرسومية (GPU):
- الاستدلال: 8 × H100 / 4 × H200 (بدقة FP8) أو 16 × H100 / 8 × H200 (بدقة BF16) للنموذج الكامل؛ نصف هذه القيمة للنسخة Air.
- الضبط الدقيق (Fine-Tuning): وحدات معالجة رسومية بذاكرة فيديو (VRAM) تبلغ 80 جيجابايت على الأقل.
- وحدة المعالجة المركزية (CPU) والنظام:
- ذاكرة وصول عشوائي (RAM) تبلغ 1 تيرابايت على الأقل لتحميل النماذج وإدارة مخازن الإفراغ المؤقت.
- وصلة اتصال عالية النطاق (مثل NVLink أو مفتاح HPC) لدعم التوازي في معالجة Tensors بين وحدات المعالجة الرسومية المتعددة.
- الدقة:
- دقة FP8 لاستخدام ذاكرة الفيديو (VRAM) بأقل قدر ممكن (تتطلب وحدات معالجة رسومية تدعم دقة FP8 بشكل أصلي).
- دقة BF16 كبديل لوحدات المعالجة الرسومية التي لا تدعم FP8.
- البرمجيات:
- استخدام vLLM أو Llama Factory للاستدلال؛ مع دعم فك التشفير التخميني (Speculative Decoding) والإفراغ المؤقت إلى وحدة المعالجة المركزية (CPU).
تحسين نموذج GLM 4.5 لتقليل استهلاك ذاكرة الفيديو (VRAM)
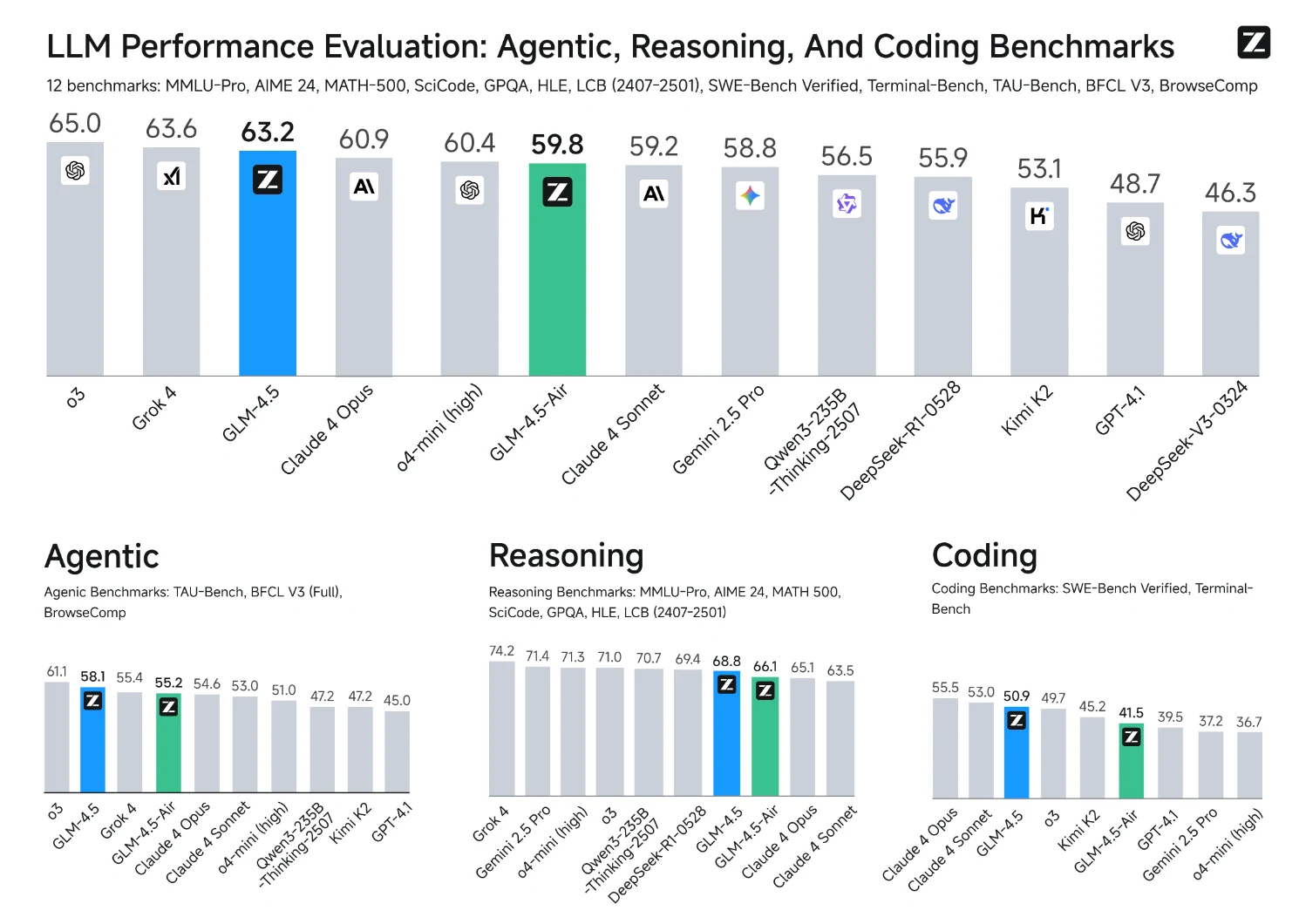
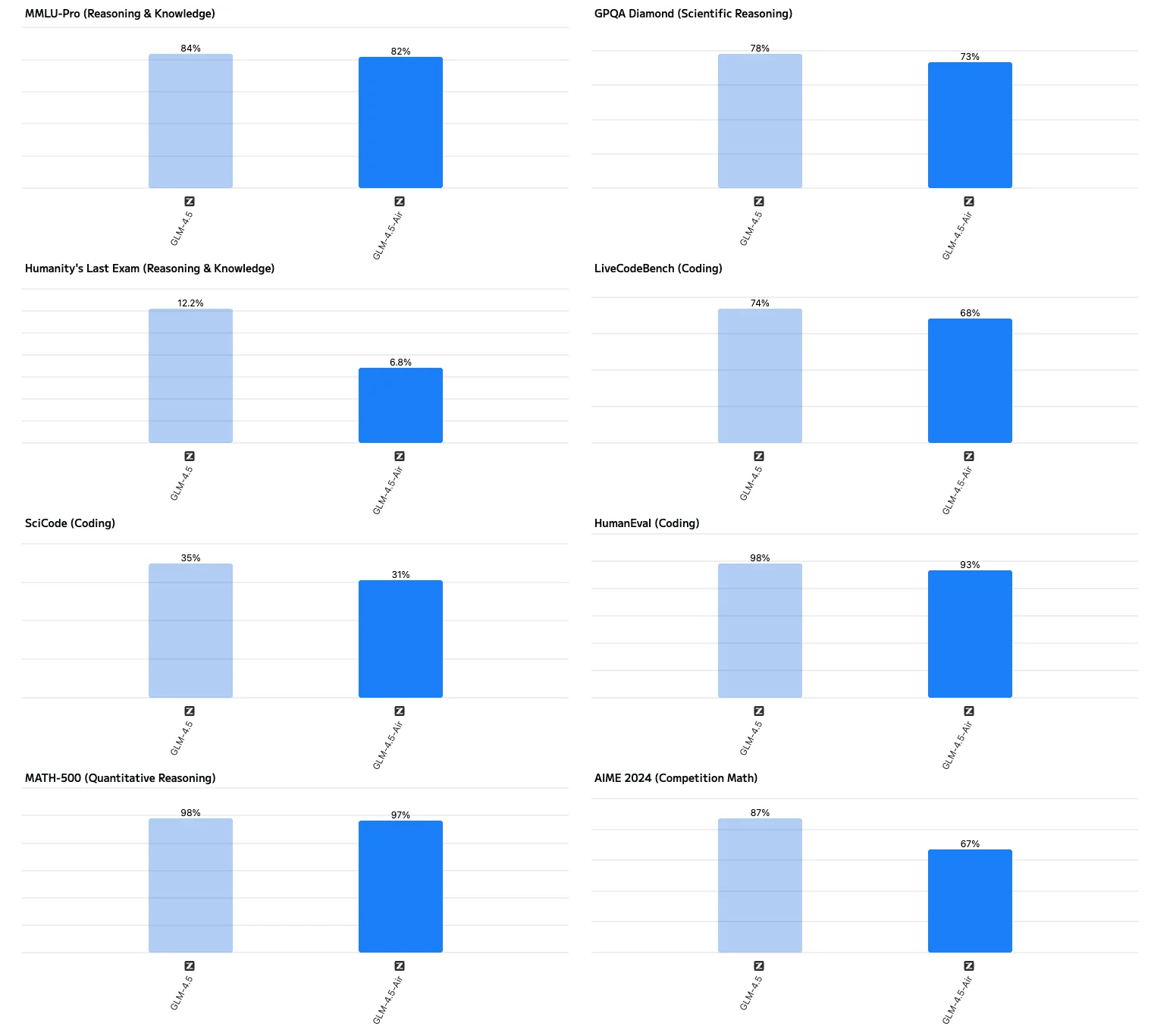
- نسخ النموذج: اختر نسخة GLM 4.5-Air (106 مليار معامل إجمالي / 12 مليار معامل نشط) للإعدادات التي تحتوي على وحدات معالجة رسومية بذاكرة 32–64 جيجابايت.
- متى تختار نسخة GLM-4.5-Air:
- سرعة توليد أعلى بكثير: تصل سرعة إخراج نسخة GLM-4.5-Air إلى حوالي 160 رمزًا في الثانية، أي ما يقارب ضعف سرعة النموذج كامل الحجم (حوالي 88 رمزًا في الثانية).这使得 هذه النسخة مثالية للتطبيقات الحساسة لزمن الاستجابة.
- زمن استجابة أول رمز منخفض للغاية (TTFT): تخرج نسخة Air أول رمز لها في حوالي 0.58 ثانية، مقارنة بـ 0.68 ثانية للنموذج كامل الحجم. في بعض الاختبارات، يمكن أن يصل زمن استجابة النموذج كامل الحجم إلى 22–23 ثانية عند إضافة وقت “التفكير”.
- زمن استجابة من البداية إلى النهاية أقصر: تقدم نسخة Air استجابات من البداية إلى النهاية (معالجة المدخلات، الاستدلال، الإخراج) في حوالي 16 ثانية، بينما يستغرق النموذج كامل الحجم ما يقارب 29 ثانية، مما يجعل النموذج كامل الحجم أقل ملاءمة للتفاعلات في الوقت الفعلي.
- درجات أقل قليلاً في مهام الاستدلال المعقد: في معايير الاستدلال مثل MMLU-Pro و GPQA و AIME، تحقق نسخة Air درجات أقل بنسبة 2–3% مقارنة بالنموذج كامل الحجم، لكنها لا تزال تحافظ على أداء رائد في المجال.
- موصى بها لمعظم حالات الاستخدام: لمعظم مهام توليد النصوص، التلخيص، الاستدلال الأساسي، ومساعدة البرمجة، لا حاجة إلى النموذج كامل الحجم—فإن نسخة Air كافية لتحقيق أداء عالي واستجابة سريعة.
- إفراج الطبقات مؤقتًا (Layer Offloading): انقل خبراء MoE المحددين أو طبقات التغذية الأمامية إلى ذاكرة وحدة المعالجة المركزية (CPU).
- تقليل كمية ذاكرة التخزين المؤقت KV (KV-Cache Quantization): قلل دقة ذاكرة التخزين المؤقت لتوفير ذاكرة الفيديو (VRAM) مع تكلفة جودة طفيفة.
- حجم الدفعة = 1: قصر الاستدلال على عينة واحدة لكل وحدة معالجة رسومية لتقليل التنشيطات (activations).
خيار آخر فعال من حيث التكلفة: واجهة برمجة التطبيقات (API)
إليك مقارنة مبسطة بين نشر نموذج GLM 4.5 عبر واجهة برمجة التطبيقات (API) وتشغيله محليًا:
| الجانب | النشر عبر API | النشر المحلي |
|---|---|---|
| التكلفة | تسعير حسب الاستخدام؛ على سبيل المثال، 0.6 دولار لكل مليون رمز مدخل و 2.2 يوان صيني لكل مليون رمز مخرج على منصة Novita AI | استثمار أولي كبير في الأجهزة (مثل وحدات معالجة رسومية NVIDIA A100)؛ قد تكون التكاليف أقل بمرور الوقت للاستخدام المكثف. |
| الأداء | قابل للتطوير مع احتمال وجود زمن استجابة للشبكة؛ مناسب للتطبيقات التي يمكنها قبول تأخيرات طفيفة. | زمن استجابة منخفض وأداء متسق؛ مثالي للتطبيقات في الوقت الفعلي التي تتطلب استجابات فورية. |
| قابلية التوسع | قابل للتوسع بسهولة دون إدارة البنية التحتية؛ حيث يتولى المزود عملية التوسع. | يتطلب التوسع إضافة أجهزة وإدارة بنية تحتية إضافية. |
| خصوصية البيانات | تتم معالجة البيانات خارجيًا، مما قد يثير مخاوف تتعلق بالخصوصية، خاصة في الصناعات الخاضعة للتنظيم. | تبقى البيانات داخل المؤسسة، مما يوفر تحكمًا أكبر وامتثالًا للوائح حماية البيانات. |
| التعقيد التشغيلي | إعداد وصيانة ضئيلة؛ حيث يتولى المزود عملية التحديثات وإدارة البنية التحتية. | يتطلب خبرة تقنية للإعداد والصيانة والأمان؛ ولكنه يوفر تخصيصًا أكبر. |
| التخصيص | محدود بتكوينات المزود؛ مرونة أقل للاحتياجات المحددة. | تحكم كامل في تخصيص النموذج، الضبط الدقيق، والتكامل مع الأنظمة الحالية. |
| ملاءمة حالات الاستخدام | مثالي للتطبيقات ذات الاستخدام المتغير أو المنخفض، أو احتياجات التطوير السريع، أو الموارد التقنية المحدودة. | الأفضل للتطبيقات ذات الاستخدام المرتفع والمستمر، أو متطلبات خصوصية البيانات الصارمة، أو الحاجة إلى تخصيص واسع النطاق. |
كيفية الوصول إلى نموذج GLM 4.5 عبر منصة Novita AI؟
توفر منصة Novita AI واجهات برمجة تطبيقات (API) بسياق يبلغ 131 ألف رمز، وتكاليف تبلغ 0.6 دولار للمدخلات و 2.2 دولار للمخرجات، مما يوفر دعماً قوياً لتحقيق أقصى استفادة من إمكانيات وكيل البرمجة لنموذج GLM 4.5.
Novita AI
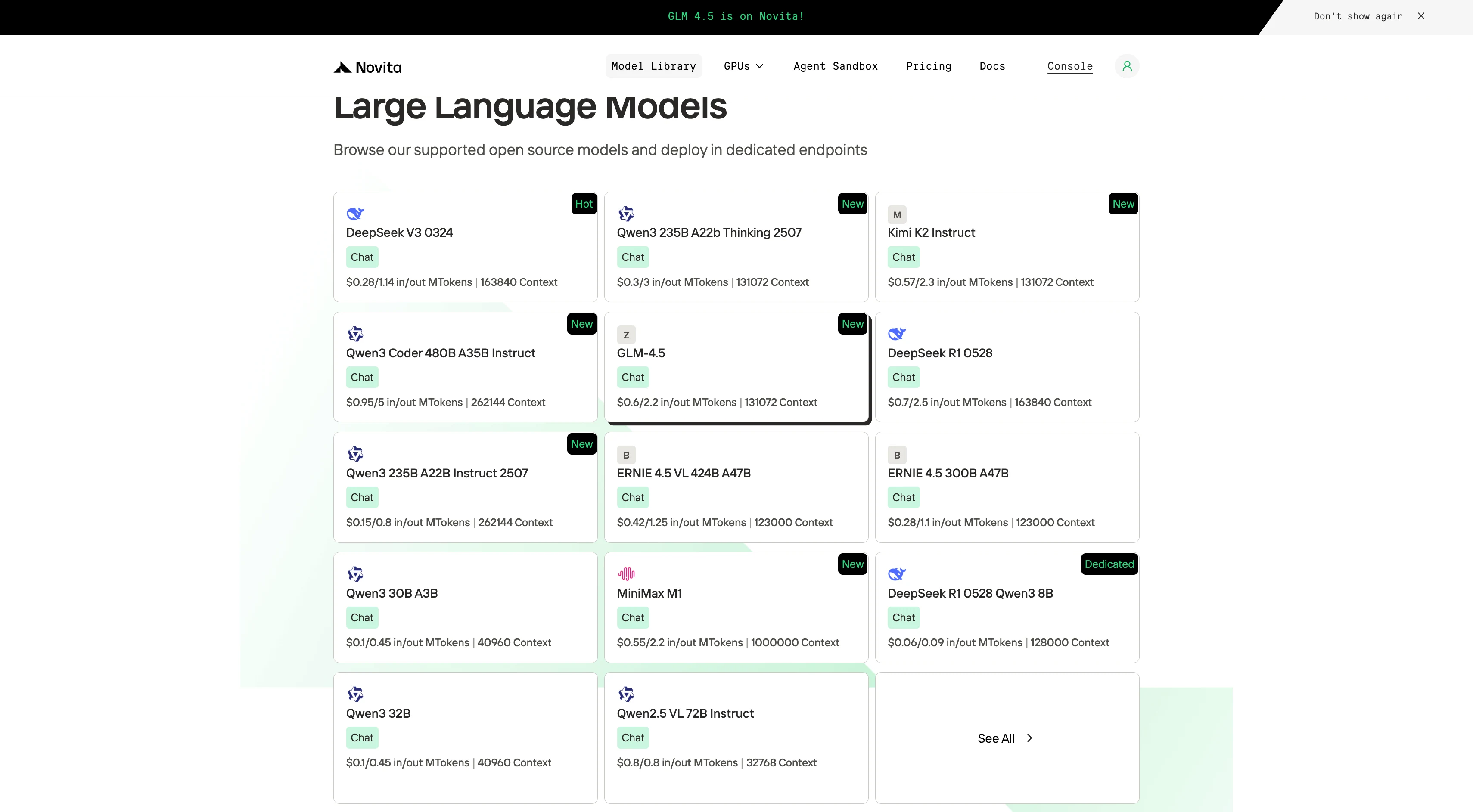
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
سجل الدخول إلى حسابك وانقر على زر مكتبة النماذج.

الخطوة 2: اختر النموذج الخاص بك
تصفح الخيارات المتاحة واختر النموذج الذي يناسب احتياجاتك.
الخطوة 3: ابدأ تجربتك المجانية
ابدأ تجربتك المجانية لاستكشاف إمكانيات النموذج المختار.
الخطوة 4: احصل على مفتاح API الخاص بك
للمصادقة مع واجهة برمجة التطبيقات (API)، سنزودك بمفتاح API جديد. عند الدخول إلى صفحة “الإعدادات”، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

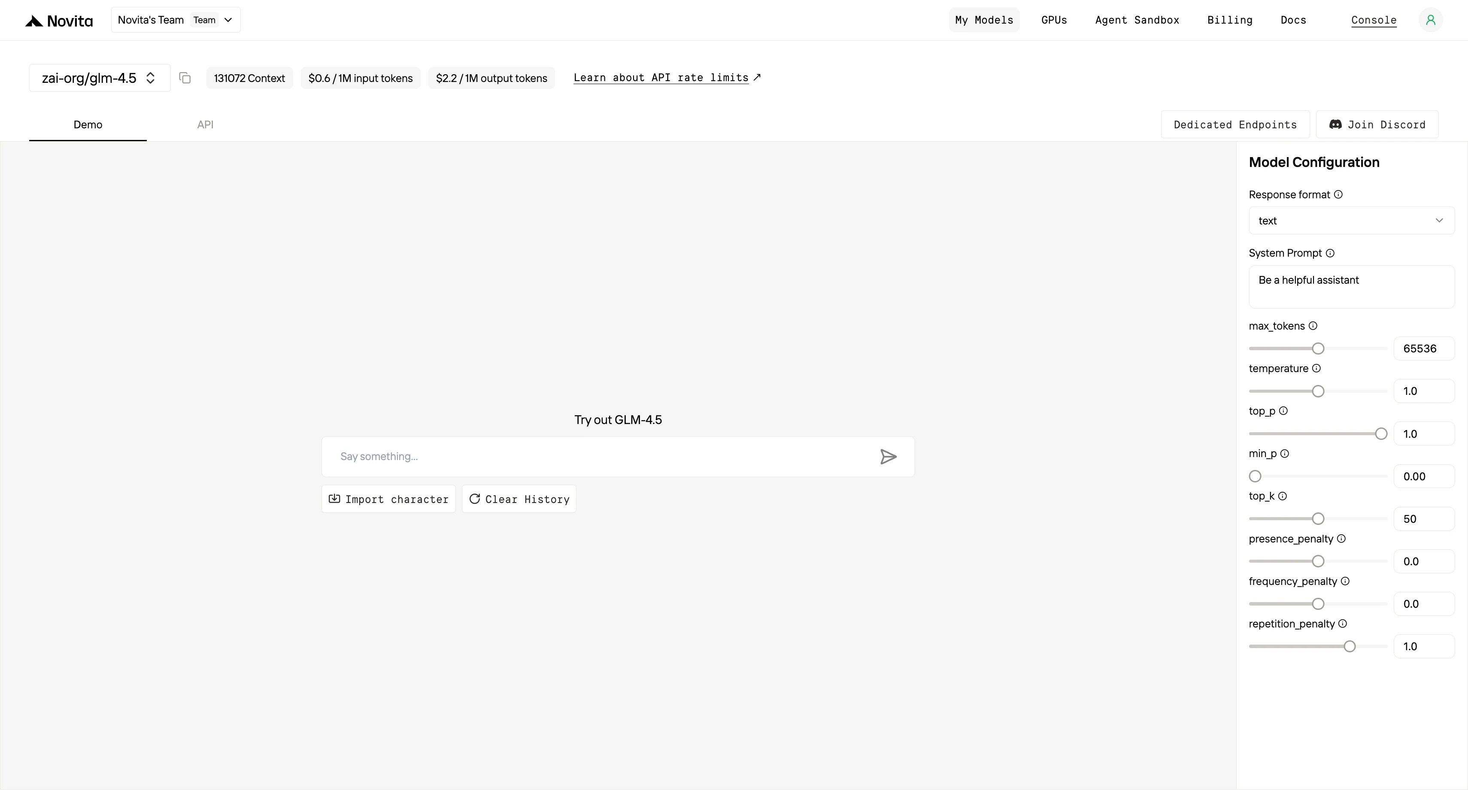
الخطوة 5: تثبيت واجهة برمجة التطبيقات (API)
قم بتثبيت واجهة برمجة التطبيقات (API) باستخدام مدير الحزم الخاص بلغة البرمجة التي تستخدمها.
بعد التثبيت، قم باستيراد المكتبات اللازمة إلى بيئة التطوير الخاصة بك. قم بتهيئة واجهة برمجة التطبيقات (API) باستخدام مفتاح API الخاص بك لبدء التفاعل مع نموذج اللغات الكبيرة (LLM) لـ Novita AI. إليك مثال لاستخدام واجهة برمجة التطبيقات لإكمال المحادثات لمستخدمي لغة بايثون.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_UsudmdAIggvSInjIdO2HWaTCyXxTFOXDV8TH8UCPbA576Rs4AGqSA5ThNbelSDgdEGAWQcWXnAU2bHi5BueceA==",
)
model = "zai-org/glm-4.5"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
يوفر نموذج GLM-4.5 ونسخته Air حلولًا قوية للتطبيقات القائمة على الوكلاء، مع متطلبات مختلفة لذاكرة الفيديو (VRAM) لتناسب سيناريوهات النشر المختلفة. سيساعدك تقييم احتياجاتك ومواردك المحددة في الاختيار بين النشر المحلي والحلول القائمة على واجهات برمجة التطبيقات (API).
الأسئلة الشائعة
من يجب أن يستخدم نموذج GLM 4.5؟
يعد نموذج GLM-4.5 مثاليًا للمطورين والباحثين والشركات التي تسعى إلى الحصول على إمكانيات متقدمة لوكلاء الذكاء الاصطناعي، خاصة لمهام البرمجة والأتمتة والمهام المعرفية.
ما هو نموذج GLM-4.5؟
يعد نموذج GLM-4.5 نموذجًا لغويًا كبيرًا متقدمًا يتميز بهندسة خلط الخبراء (Mixture-of-Experts)، ومحسّن للتطبيقات القائمة على الوكلاء التي تتطلب استدلالًا معقدًا وتكاملًا مع الأدوات.
هل يمكنني نشر نموذج GLM-4.5 دون أجهزة متطورة؟
نعم، يعد استخدام نموذج GLM-4.5 عبر واجهة برمجة التطبيقات (API) بديلاً يقلل من الحاجة إلى استثمار كبير في الأجهزة، على الرغم من أنه قد يتضمن اعتبارات تتعلق بخصوصية البيانات وزمن استجابة الشبكة.
Novita AI هي منصة سحابية للذكاء الاصطناعي توفر للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة التطبيقات (API) البسيطة الخاصة بنا، بالإضافة إلى توفير سحابة وحدات معالجة رسومية (GPU) بأسعار معقولة وموثوقة للبناء والتوسع.



