

Vous envisagez de déployer GLM-4.5 en local mais vous inquiétez des importantes ressources GPU nécessaires ? Le modèle GLM-4.5 complet nécessite des configurations telles que 16 GPU NVIDIA H100 ou 8 GPU H200 en précision FP8, tandis que la variante plus économe en ressources GLM-4.5-Air fonctionne sur 2 GPU H100 ou 1 GPU H200 en précision FP8. Ces configurations garantissent des performances optimales et prennent en charge la longueur de contexte étendue du modèle, allant jusqu’à 128 000 tokens.
Dans cet article, nous allons explorer les exigences en VRAM du GLM-4.5, discuter de la faisabilité du déploiement local et examiner des méthodes alternatives pour utiliser efficacement ce puissant modèle de langage.
Exigences en VRAM du GLM 4.5
Le GLM-4.5 est la dernière avancée de la famille GLM, dotée d’une architecture sophistiquée de mélange d’experts (MoE) et optimisée pour les applications agentiques. Le modèle est disponible en deux variantes : le GLM-4.5 flagship avec 355 milliards de paramètres totaux (32 milliards actifs), et le GLM-4.5-Air efficace avec 106 milliards de paramètres totaux (12 milliards actifs).
Les principales innovations architecturales incluent une structure de modèle plus profonde avec une largeur réduite et une profondeur accrue pour un raisonnement amélioré, un pré-entraînement sur un corpus massif de 15 billions de tokens pour des connaissances complètes, et l’infrastructure RL open source « slime » conçue pour un apprentissage par renforcement agentique scalable à grande échelle.
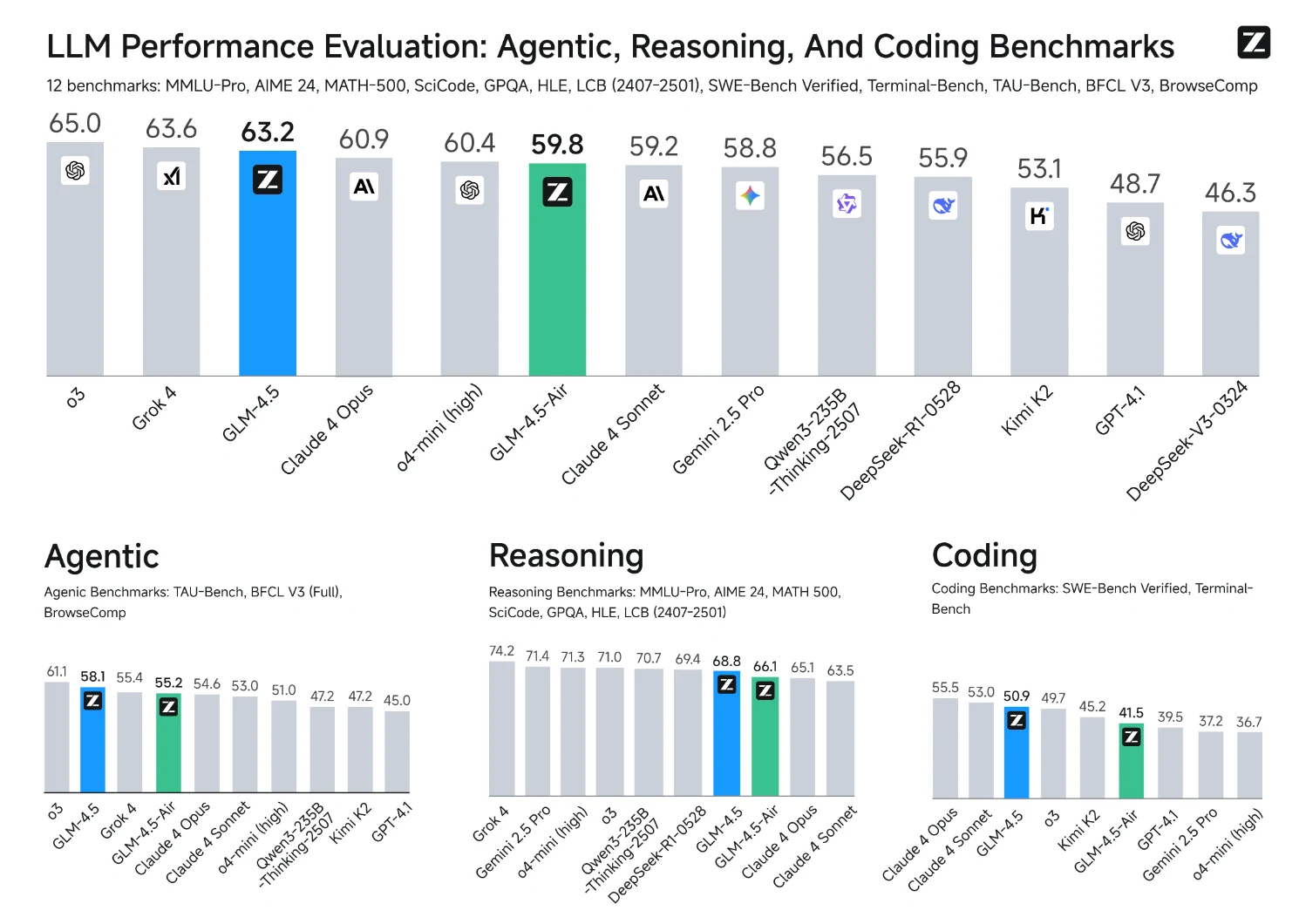
De Z.AI
Quelle quantité de VRAM le GLM 4.5 nécessite-t-il pour l’inférence ?
Les modèles peuvent fonctionner avec les configurations présentées dans le tableau ci-dessous :
| Modèle | Précision | Type et nombre de GPU | Framework de test |
|---|---|---|---|
| GLM-4.5 | BF16 | H100 x 16 / H200 x 8 | sglang |
| GLM-4.5 | FP8 | H100 x 8 / H200 x 4 | sglang |
| GLM-4.5-Air | BF16 | H100 x 4 / H200 x 2 | sglang |
| GLM-4.5-Air | FP8 | H100 x 2 / H200 x 1 | sglang |
Avec les configurations présentées dans le tableau ci-dessous, les modèles peuvent utiliser leur longueur de contexte complète de 128 000 tokens :
| Modèle | Précision | Type et nombre de GPU | Framework de test |
|---|---|---|---|
| GLM-4.5 | BF16 | H100 x 32 / H200 x 16 | sglang |
| GLM-4.5 | FP8 | H100 x 16 / H200 x 8 | sglang |
| GLM-4.5-Air | BF16 | H100 x 8 / H200 x 4 | sglang |
| GLM-4.5-Air | FP8 | H100 x 4 / H200 x 2 | sglang |
Quelle quantité de VRAM le GLM 4.5 nécessite-t-il pour le fine-tuning ?
Le code peut fonctionner avec les configurations présentées dans le tableau ci-dessous en utilisant Llama Factory :
| Modèle | Type et nombre de GPU | Stratégie | Taille de batch (par GPU) |
|---|---|---|---|
| GLM-4.5 | H100 x 16 | Lora | 1 |
| GLM-4.5-Air | H100 x 4 | Lora | 1 |
Le code peut fonctionner avec les configurations présentées dans le tableau ci-dessous en utilisant Swift :
| Modèle | Type et nombre de GPU | Stratégie | Taille de batch (par GPU) |
|---|---|---|---|
| GLM-4.5 | H20 (96GiB) x 16 | Lora | 1 |
| GLM-4.5-Air | H20 (96GiB) x 4 | Lora | 1 |
| GLM-4.5 | H20 (96GiB) x 128 | SFT | 1 |
| GLM-4.5-Air | H20 (96GiB) x 32 | SFT | 1 |
| GLM-4.5 | H20 (96GiB) x 128 | RL | 1 |
| GLM-4.5-Air | H20 (96GiB) x 32 | RL | 1 |
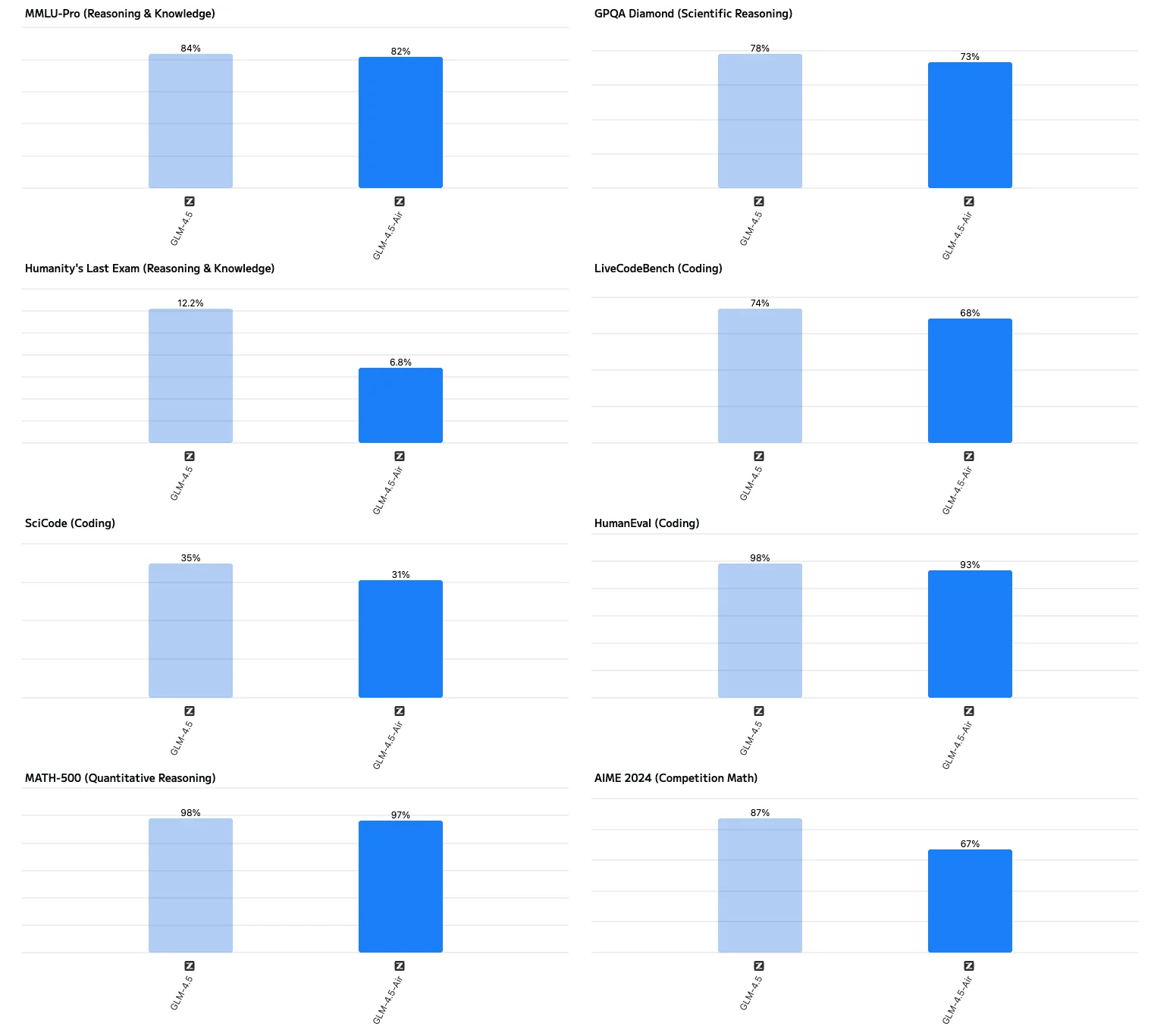
Utilisation de la VRAM du GLM 4.5 selon différentes tailles de batch
| Modèle | Précision | Taille de batch (par GPU) | VRAM |
|---|---|---|---|
| GLM-4.5 | FP16 | 1 | 945,36 Go |
| GLM-4.5 | FP16 | 8 | 1128,49 Go |
| GLM-4.5 | FP16 | 16 | 1137,79 Go |
| GLM-4.5 | FP16 | 32 | 1756,38 Go |
| GLM-4.5-Air | FP16 | 1 | 288,68 Go |
| GLM-4.5-Air | FP16 | 8 | 343,58 Go |
| GLM-4.5-Air | FP16 | 16 | 406,33 Go |
| GLM-4.5-Air | FP16 | 32 | 531,83 Go |
Quelles sont les exigences matérielles pour le GLM 4.5 ?
https://www.youtube.com/watch?v=grAXN76\_-Ig
- GPU :
- Inférence : 8 × H100 / 4 × H200 (FP8) ou 16 × H100 / 8 × H200 (BF16) pour le modèle complet ; la moitié pour la variante Air.
- Fine-tuning : GPU avec ≥ 80 Go de VRAM.
- CPU et système :
- ≥ 1 To de RAM pour charger les modèles et gérer les tampons de déchargement.
- Interconnexion à haut débit (commutateur NVLink/HPC) pour le parallélisme de tenseurs multi-GPU.
- Précision :
- FP8 pour une utilisation minimale de la VRAM (nécessite des GPU avec prise en charge native du FP8).
- BF16 comme alternative sur les GPU sans prise en charge FP8.
- Logiciels :
- vLLM ou Llama Factory pour l’inférence ; prise en charge du décodage spéculatif et du déchargement sur CPU.
Optimiser le GLM 4.5 pour réduire la consommation de VRAM
- Variantes de modèle : Choisissez le GLM 4.5-Air (106 milliards de paramètres totaux / 12 milliards actifs) pour des configurations GPU de 32 à 64 Go.
- Quand choisir le GLM-4.5-Air :
- Génération significativement plus rapide :
- Le GLM-4.5-Air atteint un débit de sortie d’environ 160 tokens par seconde, soit près de deux fois plus rapide que le modèle complet (environ 88 tokens/s). Cela fait de la variante Air un choix idéal pour les applications sensibles à la latence.
- Latence extrêmement faible pour le premier token (TTFT) :
- La variante Air génère son premier token en environ 0,58 seconde, contre 0,68 seconde pour le modèle complet. Lors de certains tests, la latence du modèle complet peut atteindre 22 à 23 secondes si l’on inclut le temps de « réflexion ».
- Temps de réponse de bout en bout plus court :
- La variante Air fournit des réponses de bout en bout (traitement des entrées, inférence et sortie) en environ 16 secondes, contre près de 29 secondes pour le modèle complet, ce qui rend ce dernier moins adapté aux interactions en temps réel.
- Scores légèrement inférieurs sur les tâches de raisonnement complexes :
- Sur des benchmarks de raisonnement tels que MMLU-Pro, GPQA et AIME, la variante Air obtient des scores environ 2 à 3 % inférieurs à ceux du modèle complet, mais conserve tout de même des performances de premier plan dans l’industrie.
- Recommandé pour la plupart des cas d’usage :
- Pour la majorité des tâches de génération de texte, de résumé, de raisonnement basique et d’assistance au code, le modèle complet n’est pas nécessaire : la variante Air est suffisante pour des performances et une réactivité élevées.
- Génération significativement plus rapide :
- Déchargement de couches : Déchargez certains experts MoE ou couches de propagation avant vers la mémoire CPU.
- Quantisation du cache KV : Réduisez la précision du cache pour économiser de la VRAM avec un impact minime sur la qualité.
- Taille de batch = 1 : Limitez l’inférence à un seul échantillon par GPU pour minimiser les activations.
Une autre option rentable : l’API
Voici une comparaison simplifiée entre le déploiement du GLM 4.5 via une API et son exécution en local :
| Aspect | Déploiement via API | Déploiement local |
|---|---|---|
| Coût | Tarification à l’usage ; par exemple, 0,6 $ par million de tokens d’entrée et 2,2 ¥ par million de tokens de sortie sur Novita AI | Investissement initial élevé dans du matériel (par exemple, GPU NVIDIA A100) ; coûts potentiellement plus faibles sur le long terme pour une utilisation intensive. |
| Performance | Scalable avec une latence réseau potentielle ; adapté aux applications où des délais légers sont acceptables. | Latence faible et performances constantes ; idéal pour les applications en temps réel nécessitant des réponses immédiates. |
| Scalabilité | Facilement scalable sans gestion d’infrastructure ; le fournisseur gère la mise à l’échelle. | La mise à l’échelle nécessite du matériel supplémentaire et la gestion de l’infrastructure. |
| Confidentialité des données | Les données sont traitées en externe, ce qui peut poser des problèmes de confidentialité, notamment dans les secteurs réglementés. | Les données restent en interne, offrant un meilleur contrôle et la conformité avec les réglementations sur la protection des données. |
| Complexité opérationnelle | Configuration et maintenance minimales ; le fournisseur gère les mises à jour et l’infrastructure. | Nécessite une expertise technique pour la configuration, la maintenance et la sécurité ; offre une plus grande personnalisation. |
| Personnalisation | Limitée aux configurations du fournisseur ; moins de flexibilité pour des besoins spécifiques. | Contrôle total sur la personnalisation du modèle, le fine-tuning et l’intégration avec les systèmes existants. |
| Adéquation aux cas d’usage | Idéal pour les applications avec une utilisation variable ou faible, des besoins de développement rapide ou des ressources techniques limitées. | Meilleur pour les applications avec une utilisation élevée et constante, des exigences strictes en matière de confidentialité des données ou un besoin de personnalisation étendue. |
Comment accéder au GLM 4.5 via Novita AI ?
Novita AI propose des API avec un contexte de 131 000 tokens, et des coûts de 0,6 $ par token d’entrée et 2,2 ¥ par token de sortie, offrant un soutien solide pour maximiser le potentiel d’agent de code du GLM 4.5.
Novita AI
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Essayer le GLM 4.5 dès maintenant !
Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.
Étape 3 : Démarrez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Récupérez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En accédant à la page « Paramètres », vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec le LLM de Novita AI. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_UsudmdAIggvSInjIdO2HWaTCyXxTFOXDV8TH8UCPbA576Rs4AGqSA5ThNbelSDgdEGAWQcWXnAU2bHi5BueceA==",
)
model = "zai-org/glm-4.5"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Le GLM-4.5 et sa variante Air offrent des solutions puissantes pour les applications agentiques, avec des exigences en VRAM variables adaptées à différents scénarios de déploiement. L’évaluation de vos besoins et ressources spécifiques vous guidera dans le choix entre un déploiement local et des solutions basées sur une API.
Questions fréquemment posées
Qui devrait utiliser le GLM 4.5 ?
Le GLM-4.5 est idéal pour les développeurs, les chercheurs et les entreprises recherchant des capacités avancées d’agent IA, notamment pour le codage, l’automatisation et les tâches de gestion des connaissances.
Qu’est-ce que le GLM-4.5 ?
Le GLM-4.5 est un modèle de langage avancé doté d’une architecture de mélange d’experts (MoE), optimisé pour les applications agentiques nécessitant un raisonnement complexe et l’intégration d’outils.
Puis-je déployer le GLM-4.5 sans matériel important ?
Oui, l’utilisation du GLM-4.5 via une API est une alternative qui réduit le besoin d’investissement matériel important, même si elle peut impliquer des considérations liées à la confidentialité des données et à la latence réseau.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA grâce à notre API intuitive, tout en fournissant un cloud GPU abordable et fiable pour la construction et la mise à l’échelle.



