

소개
RoBERTa(‘Robustly Optimized BERT Approach’의 약자)는 Facebook AI 연구진이 만든 BERT(Bidirectional Encoder Representations from Transformers) 모델의 고급 버전입니다. BERT와 유사하게 RoBERTa는 트랜스포머 기반 언어 모델로, self-attention을 사용하여 입력 시퀀스를 분석하고 문장 내에서 문맥화된 단어 표현을 생성합니다.
이 글에서는 RoBERTa를 더 자세히 살펴보겠습니다.
RoBERTa vs BERT
RoBERTa와 BERT의 주요 차이점은 RoBERTa가 훨씬 더 큰 데이터셋과 더 효과적인 학습 절차로 학습되었다는 점입니다. 구체적으로 RoBERTa는 BERT에 사용된 데이터셋 크기의 10배가 넘는 160GB의 텍스트로 학습되었습니다. 또한 RoBERTa는 학습 중 동적 마스킹 기법을 사용하여 모델이 더 강력하고 일반화 가능한 단어 표현을 학습할 수 있도록 합니다.
RoBERTa는 언어 번역, 텍스트 분류, 질문 답변과 같은 다양한 자연어 처리 작업에서 BERT 및 다른 선도 모델보다 뛰어난 성능을 보여주었습니다. 또한 수많은 성공적인 NLP 모델의 기초 모델 역할을 하며 연구 및 산업 응용 분야에서 인기를 얻었습니다.
요약하면 RoBERTa는 NLP에 중요한 기여를 하고 다양한 응용 분야의 발전을 촉진한 강력하고 효과적인 언어 모델입니다.
RoBERTa 모델 아키텍처
RoBERTa 모델은 BERT 모델과 동일한 아키텍처를 공유합니다. 이는 주요 하이퍼파라미터 수정과 임베딩의 사소한 조정이 포함된 BERT의 재구현입니다.
BERT의 일반적인 사전 학습 및 미세 조정 절차는 아래 그림 1에 나와 있습니다. BERT에서는 출력 레이어를 제외하고 사전 학습과 미세 조정에 동일한 아키텍처가 사용됩니다. 사전 학습된 모델 파라미터는 다양한 다운스트림 작업의 모델을 초기화하는 데 사용됩니다. 미세 조정 중에는 모든 파라미터가 조정됩니다.
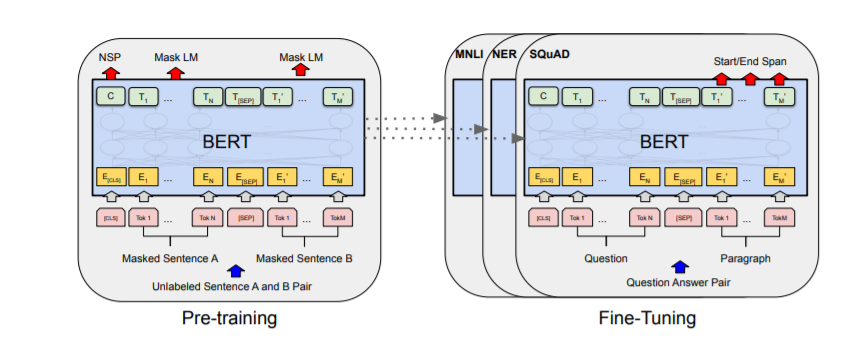
BERT 모델의 아키텍처
반면 RoBERTa는 다음 문장 사전 학습 목표를 사용하지 않습니다. 대신 훨씬 더 큰 미니 배치와 더 높은 학습률로 학습됩니다. RoBERTa는 다른 사전 학습 방식을 사용하며 문자 수준 BPE 어휘를 바이트 수준 BPE 토크나이저(GPT-2와 유사)로 대체합니다. 또한 RoBERTa는 token_type_ids가 없기 때문에 어떤 토큰이 어떤 세그먼트에 속하는지 정의할 필요가 없습니다. 세그먼트는 분리 토큰 tokenizer.sep_token(또는 )을 사용하여 쉽게 나눌 수 있습니다.
또한 BERT 학습에 원래 사용된 16GB 데이터셋과 달리 RoBERTa는 160GB가 넘는 압축되지 않은 텍스트의 방대한 데이터셋으로 학습됩니다. 이 데이터셋에는 BERT에 사용된 16GB의 영어 위키피디아와 Books Corpus, WebText 코퍼스(38GB), CommonCrawl News 데이터셋(6300만 개 기사, 76GB), Common Crawl의 Stories(31GB)가 포함됩니다. RoBERTa는 이 광범위한 데이터셋과 하루 동안 실행된 1024개의 V100 Tesla GPU를 사용하여 사전 학습되었습니다.
RoBERTa 모델의 장점
RoBERTa는 BERT와 유사한 아키텍처를 가지지만, 성능을 향상시키기 위해 저자는 아키텍처와 학습 절차에 몇 가지 간단한 설계 변경을 가했습니다. 이러한 변경 사항은 다음과 같습니다.
- NSP(Next Sentence Prediction) 목표 제거: BERT에서는 보조 NSP 손실을 사용하여 문서의 두 세그먼트가 동일한 문서에서 왔는지 다른 문서에서 왔는지 예측하도록 모델을 학습합니다. 저자는 NSP 손실이 있거나 없는 모델 버전을 실험했으며, NSP 손실을 제거해도 다운스트림 작업에서 성능이 같거나 약간 향상된다는 것을 발견했습니다.
- 더 큰 배치 크기와 더 긴 시퀀스로 학습: BERT는 원래 배치 크기 256 시퀀스로 100만 스텝 학습되었습니다. RoBERTa는 배치당 2,000 시퀀스로 125스텝, 8,000 시퀀스로 31,000스텝 학습되었습니다. 더 큰 배치는 마스크 언어 모델링 목표의 perplexity와 최종 작업 정확도를 향상시킵니다. 또한 분산 병렬 학습을 사용하여 병렬화하기 쉽습니다.
- 마스킹 패턴 동적 변경: BERT에서는 마스킹이 데이터 전처리 중 한 번만 수행되어 단일 정적 마스크가 생성됩니다. 이를 피하기 위해 학습 데이터를 복제하고 40 epoch에 걸쳐 다른 전략으로 10번 마스킹하여 동일한 마스크로 4 epoch를 생성합니다. 이 전략을 데이터가 모델에 전달될 때마다 다른 마스크가 생성되는 동적 마스킹과 비교했습니다.
RoBERTa의 성능
RoBERTa 모델은 당시 MNLI, QNLI, RTE, STS-B, RACE 작업에서 최첨단 성능을 달성했으며 GLUE 벤치마크에서 상당한 성능 향상을 보여주었습니다. 88.5점으로 RoBERTa는 GLUE 리더보드에서 1위를 차지했습니다.

BERT와 그에 대한 연속적인 개선 사항 비교
RoBERTa 사용 방법
Huggingface의 Transformers 라이브러리는 다양한 크기와 다양한 작업을 위한 다양한 사전 학습된 RoBERTa 모델을 제공합니다. 이 글에서는 RoBERTa 모델을 로드하고 감정 분류를 수행하는 방법에 초점을 맞추겠습니다.
작업별 데이터셋에 미세 조정된 RoBERTa 모델, 특히 Huggingface 허브의 사전 학습된 모델 cardiffnlp/twitter-roberta-base-emotion을 사용하겠습니다.
먼저 필요한 모든 패키지를 설치하고 가져온 후 RobertaForSequenceClassification(분류 헤드 포함)을 사용하여 모델을 로드하고 RobertaTokenizer를 사용하여 토크나이저를 로드합니다.
!pip install -q transformers
# 필요한 패키지 가져오기
import torch
from transformers import RobertaTokenizer, RobertaForSequenceClassification
# 모델 및 토크나이저 로드
model_name = "cardiffnlp/twitter-roberta-base-emotion"
tokenizer = RobertaTokenizer.from_pretrained(model_name)
model = RobertaForSequenceClassification.from_pretrained(model_name)
# 입력 토큰화
inputs = tokenizer("I love my cat", return_tensors="pt")
# 로짓 검색 및 기본 감정 예측에 사용
with torch.no_grad():
logits = model(**inputs).logits
predicted_class_id = logits.argmax().item()
model.config.id2label[predicted_class_id]
>> Output: Optimism
출력은 “Optimism”이며, 사용한 분류 모델의 미리 정의된 레이블에 따라 정확합니다. 다른 사전 학습된 모델을 사용하거나 모델을 미세 조정하여 더 적절한 레이블로 결과를 얻을 수 있습니다.
RoBERTa 평가 결과
동적 마스킹을 사용한 학습
원래 BERT 구현에서는 마스킹이 데이터 전처리 중에 발생하여 단일 정적 마스크가 생성됩니다. 이 방법을 시퀀스가 모델에 입력될 때마다 새로운 마스킹 패턴이 생성되는 동적 마스킹과 비교했습니다. 동적 마스킹은 정적 마스킹에 비해 비슷하거나 약간 더 나은 성능을 보였습니다.

BERT의 정적 마스킹과 동적 마스킹 비교
위의 결과를 바탕으로 RoBERTa 사전 학습에는 동적 마스킹 접근 방식이 사용됩니다.
NSP 손실이 없는 전체 문장
NSP 손실 없이 학습하는 것과 단일 문서(doc-sentences)의 텍스트 블록으로 학습하는 것을 비교한 결과, 이 구성이 원래 게시된 BERTBASE 결과보다 성능이 뛰어난 것으로 나타났습니다. 또한 NSP 손실을 제거하면 다운스트림 작업에서 성능이 같거나 약간 향상됩니다.

NSP 손실 유무에 따른 RoBERTa 성능을 보여주는 표
시퀀스를 단일 문서(DOC-SENTENCES)로 제한하면 여러 문서(FULL-SENTENCES)의 시퀀스를 포함하는 것보다 약간 더 나은 성능을 보이지만, RoBERTa는 DOC-SENTENCES 형식이 가변 배치 크기를 초래하기 때문에 비교를 쉽게 하기 위해 FULL-SENTENCES를 사용합니다.
대규모 배치 학습
대규모 배치 크기로 학습하면 최적화 속도가 빨라지고 작업 정확도가 향상됩니다. 또한 분산 데이터 병렬 학습을 통해 대규모 배치를 병렬화하여 효율성을 더욱 높일 수 있습니다. 적절히 조정하면 대규모 배치 크기는 주어진 작업에서 모델의 성능을 향상시킬 수 있습니다.

다양한 배치 크기로 다양한 작업에서 RoBERTa 성능 비교
더 큰 바이트 수준 BPE
바이트 쌍 인코딩(BPE)은 문자 수준과 단어 수준 표현의 측면을 결합하여 자연어 코퍼스에서 일반적인 광범위한 어휘를 효과적으로 처리할 수 있게 합니다. RoBERTa는 50K 서브워드 단위로 구성된 더 큰 바이트 수준 BPE 어휘를 사용하여 추가 전처리나 입력 토큰화 없이 BERT와 차별화됩니다.
RoBERTa의 한계 탐색
RoBERTa는 강력한 모델이지만 한계가 없는 것은 아닙니다. 몇 가지는 다음과 같습니다.
- 계산 리소스: RoBERTa를 학습하고 미세 조정하려면 강력한 GPU와 대용량 메모리를 포함한 상당한 계산 리소스가 필요합니다. 이는 리소스가 제한된 개인이나 조직이 RoBERTa를 효과적으로 활용하는 데 어려움을 줄 수 있습니다.
- 도메인 특수성: 사전 학습된 언어 모델(RoBERTa)은 추가 미세 조정 없이 도메인별 작업이나 데이터셋에서 최적으로 작동하지 않을 수 있습니다. 원하는 성능 수준을 달성하려면 도메인별 데이터에 대한 추가 학습이 필요할 수 있습니다.
- 데이터 효율성: RoBERTa 및 유사한 모델은 사전 학습에 많은 양의 데이터가 필요하며, 이는 모든 언어나 도메인에 사용 가능하지 않을 수 있습니다. 이렇게 방대한 데이터에 의존하면 데이터가 부족하거나 확보 비용이 많이 드는 환경에서 적용 가능성이 제한될 수 있습니다.
- 해석 가능성: RoBERTa의 블랙박스 특성으로 인해 모델이 어떻게 예측에 도달하는지 해석하기 어려울 수 있습니다. 모델의 내부 작동 방식을 이해하고 오류나 편향을 진단하는 것은 복잡한 응용 프로그램이나 민감한 도메인에서 특히 어려울 수 있습니다.
- 미세 조정의 어려움: 특정 작업을 위해 RoBERTa를 미세 조정하면 성능이 향상될 수 있지만, 올바른 하이퍼파라미터, 데이터 증강 기법, 학습 전략을 선택하려면 전문 지식과 실험이 필요합니다. 이 과정은 시간이 많이 걸리고 리소스 집약적일 수 있습니다.
- 편향과 공정성: 사전 학습된 언어 모델(RoBERTa)은 학습 데이터에 존재하는 편향을 물려받아 편향되거나 불공정한 예측을 초래할 수 있습니다. AI 모델의 편향을 해결하고 공정성을 보장하는 것은 여전히 중요한 과제이며, 신중한 데이터 큐레이션과 모델 설계 고려가 필요합니다.
- 분포 외 일반화: RoBERTa는 분포 외 데이터에 일반화하거나 학습 데이터와 크게 다른 시나리오를 처리하는 데 어려움을 겪을 수 있습니다. 이 한계는 데이터 분포 변화가 흔한 실제 응용 프로그램에서 RoBERTa의 견고성과 신뢰성에 영향을 미칠 수 있습니다.
이러한 한계를 극복하려면 최근 출시된 Llama 3와 같은 고급 모델을 선택할 수 있습니다. 또는 novita.ai LLM API 키를 기존 시스템에 저렴한 비용으로 원활하게 적용할 수 있습니다.

novita.ai LLM API가 제공하는 모델

결론
RoBERTa는 BERT의 기반 위에 훨씬 더 큰 학습 데이터셋과 동적 마스킹 및 다음 문장 예측 목표 제거와 같은 개선된 기술을 활용하여 자연어 처리를 크게 발전시켰습니다. 이러한 향상된 기능은 바이트 수준 BPE 토크나이저와 더 큰 배치 크기 사용과 함께 RoBERTa가 다양한 NLP 작업에서 뛰어난 성능을 달성할 수 있게 합니다. 상당한 계산 리소스와 미세 조정 전문 지식이 필요하지만, RoBERTa는 이 분야에 깊은 영향을 미쳐 새로운 벤치마크를 설정하고 연구 및 산업 응용을 위한 다재다능한 모델 역할을 하고 있습니다.
novita.ai는 무한한 창의성을 위한 원스톱 플랫폼으로, 100개 이상의 API에 액세스할 수 있습니다. 이미지 생성, 언어 처리, 오디오 향상, 비디오 조작에 이르기까지 저렴한 종량제 요금제로 GPU 유지 관리 걱정 없이 자체 제품을 구축할 수 있습니다. 지금 무료로 사용해 보세요.
추천 자료



