

مقدمة
RoBERTa (اختصار لـ “Robustly Optimized BERT Approach”) هي نسخة متطورة من نموذج BERT (Bidirectional Encoder Representations from Transformers)، تم إنشاؤها بواسطة باحثين في Facebook AI. كما هو الحال مع BERT، فإن RoBERTa هو نموذج لغة قائم على المحولات (transformer) يستخدم الانتباه الذاتي لتحليل تسلسلات الإدخال وإنتاج تمثيلات كلمات سياقية داخل الجملة.
في هذه المقالة، سنلقي نظرة أعمق على RoBERTa.
RoBERTa مقابل BERT
الفرق الرئيسي بين RoBERTa و BERT هو أن RoBERTa تم تدريبه على مجموعة بيانات أكبر بكثير وبتدريب أكثر فعالية. تحديداً، تم تدريب RoBERTa على 160 جيجابايت من النصوص، أي أكثر من 10 أضعاف حجم مجموعة البيانات المستخدمة لـ BERT. بالإضافة إلى ذلك، يستخدم RoBERTa تقنية الإخفاء الديناميكي (dynamic masking) أثناء التدريب، مما يعزز قدرة النموذج على تعلم تمثيلات كلمات أكثر قوة وقابلة للتعميم.
أظهر RoBERTa أداءً متفوقاً مقارنة بـ BERT والنماذج الرائدة الأخرى في العديد من مهام معالجة اللغة الطبيعية، مثل الترجمة اللغوية، تصنيف النصوص، والإجابة على الأسئلة. كما كان نموذجاً أساسياً للعديد من نماذج NLP الناجحة واكتسب شعبية في كل من التطبيقات البحثية والصناعية.
باختصار، RoBERTa هو نموذج لغة قوي وفعال قدم إسهامات كبيرة في مجال NLP، مما دفع التقدم عبر مجموعة واسعة من التطبيقات.
بنية نموذج RoBERTa
يشارك نموذج RoBERTa نفس بنية نموذج BERT. إنه إعادة تنفيذ لـ BERT مع تعديلات على المعلمات الفائقة الرئيسية وتعديلات طفيفة على التضمينات (embeddings).
يتم توضيح الإجراءات العامة للتدريب المسبق والضبط الدقيق لـ BERT في الشكل 1 أدناه. في BERT، يتم استخدام نفس البنية لكل من التدريب المسبق والضبط الدقيق، باستثناء طبقات الإخراج. تُستخدم معلمات النموذج المدربة مسبقاً لتهيئة النماذج لمهام مختلفة في المراحل اللاحقة. أثناء الضبط الدقيق، يتم ضبط جميع المعلمات.
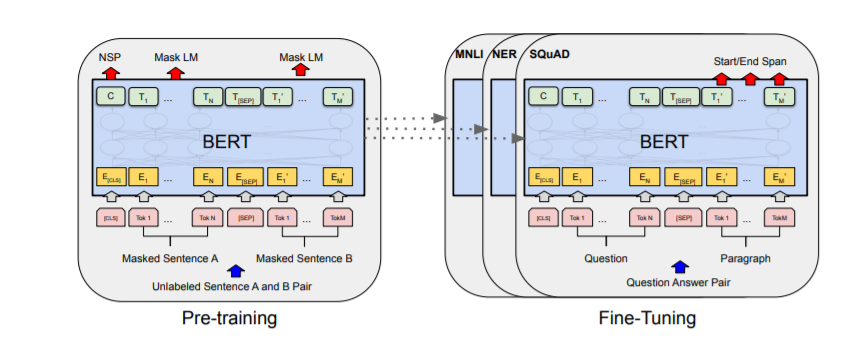
بنية نموذج BERT
في المقابل، لا يستخدم RoBERTa هدف التدريب المسبق للجملة التالية (next-sentence pretraining objective). بدلاً من ذلك، يتم تدريبه بدفعات صغيرة أكبر (mini-batches) ومعدلات تعلم أعلى. يستخدم RoBERTa مخطط تدريب مسبق مختلف ويستبدل مفردات BPE على مستوى الحرف بمفردات BPE على مستوى البايت (مشابهة لـ GPT-2). بالإضافة إلى ذلك، لا يتطلب RoBERTa تحديد أي رمز ينتمي إلى أي جزء، لأنه يفتقر إلى token_type_ids. يمكن تقسيم الأجزاء بسهولة باستخدام رمز الفصل tokenizer.sep_token (أو ).
علاوة على ذلك، على عكس مجموعة البيانات 16 جيجابايت التي استُخدمت أصلاً لتدريب BERT، يتم تدريب RoBERTa على مجموعة بيانات ضخمة تتجاوز 160 جيجابايت من النصوص غير المضغوطة. تشمل هذه المجموعة 16 جيجابايت من ويكيبيديا الإنجليزية ومجموعة كتب BERT، بالإضافة إلى بيانات إضافية من مجموعة WebText (38 جيجابايت)، مجموعة أخبار CommonCrawl (63 مليون مقال، 76 جيجابايت)، وقصص من Common Crawl (31 جيجابايت). تم تدريب RoBERTa مسبقاً باستخدام هذه المجموعة الضخمة و 1024 من وحدات معالجة الرسوم V100 Tesla تعمل لمدة يوم.
مزايا نموذج RoBERTa
لدى RoBERTa بنية مشابهة لـ BERT، ولكن لتحسين الأداء، أجرى المؤلفون العديد من التغييرات التصميمية البسيطة على البنية وإجراءات التدريب. تشمل هذه التغييرات:
- إزالة هدف التنبؤ بالجملة التالية (NSP): في BERT، يتم تدريب النموذج للتنبؤ ما إذا كان جزآن من مستند من نفس المستند أو من مستندات مختلفة باستخدام خسارة NSP المساعدة. جرب المؤلفون إصدارات من النموذج مع وبدون خسارة NSP ووجدوا أن إزالة خسارة NSP إما تطابق أو تحسن قليلاً من الأداء في المهام اللاحقة.
- التدريب بأحجام دفعات أكبر وتسلسلات أطول: تم تدريب BERT أصلاً لمليون خطوة بحجم دفعة 256 تسلسلاً. تم تدريب RoBERTa بـ 125 خطوة من 2000 تسلسلاً و 31000 خطوة مع 8000 تسلسلاً لكل دفعة. تعمل الدفعات الأكبر على تحسين الارتباك (perplexity) في هدف نمذجة اللغة المخفية ودقة المهمة النهائية. كما أنها أسهل في التوازي باستخدام التدريب المتوازي الموزع.
- تغيير نمط الإخفاء ديناميكياً: في BERT، يتم الإخفاء مرة واحدة أثناء معالجة البيانات المسبقة، مما ينتج عنه قناع ثابت واحد. لتجنب ذلك، يتم تكرار بيانات التدريب وإخفائها 10 مرات باستراتيجيات مختلفة على 40 حقبة (epoch)، مما ينتج عنه 4 عصور بنفس القناع. تمت مقارنة هذه الاستراتيجية بالإخفاء الديناميكي، حيث يتم إنشاء أقنعة مختلفة في كل مرة يتم فيها تمرير البيانات إلى النموذج.
أداء RoBERTa
حقق نموذج RoBERTa أداءً متطوراً في مهام MNLI و QNLI و RTE و STS-B و RACE في ذلك الوقت، وأظهر تحسينات كبيرة في الأداء على معيار GLUE. مع درجة 88.5، احتل RoBERTa المركز الأول على لوحة متصدرين GLUE.

مقارنة بين BERT والتحسينات المتتالية عليه
كيفية استخدام RoBERTa
تقدم مكتبة Transformers من Huggingface مجموعة متنوعة من نماذج RoBERTa المدربة مسبقاً بأحجام مختلفة ولمهام مختلفة. في هذه التدوينة، سنركز على كيفية تحميل نموذج RoBERTa وإجراء تصنيف المشاعر.
سنستخدم نموذج RoBERTa معدلاً (fine-tuned) على مجموعة بيانات خاصة بمهمة محددة، وهو النموذج المدرب مسبقاً “cardiffnlp/twitter-roberta-base-emotion” من Huggingface hub.
أولاً، نحتاج إلى تثبيت واستيراد جميع الحزم الضرورية وتحميل النموذج باستخدام RobertaForSequenceClassification (الذي يتضمن رأس تصنيف) والمحلل باستخدام RobertaTokenizer.
!pip install -q transformers
#Importing the necessary packages
import torch
from transformers import RobertaTokenizer, RobertaForSequenceClassification
#Loading the model and tokenizer
model_name = "cardiffnlp/twitter-roberta-base-emotion"
tokenizer = RobertaTokenizer.from_pretrained(model_name)
model = RobertaForSequenceClassification.from_pretrained(model_name)
#Tokenizing the input
inputs = tokenizer("I love my cat", return_tensors="pt")
#Retrieving the logits and using them for predicting the underlying emotion
with torch.no_grad():
logits = model(**inputs).logits
predicted_class_id = logits.argmax().item()
model.config.id2label[predicted_class_id]
>> Output: Optimism
المخرج هو “Optimism” (تفاؤل)، وهو صحيح بناءً على التصنيفات المحددة مسبقاً لنموذج التصنيف الذي استخدمناه. يمكننا استخدام نموذج مدرب مسبقاً آخر أو ضبط نموذج للحصول على نتائج بتصنيفات أكثر ملاءمة.
نتائج تقييم RoBERTa
التدريب بالإخفاء الديناميكي
في تنفيذ BERT الأصلي، يحدث الإخفاء أثناء معالجة البيانات المسبقة، مما يؤدي إلى قناع ثابت واحد. تمت مقارنة هذه الطريقة بالإخفاء الديناميكي، حيث يتم إنشاء نمط إخفاء جديد في كل مرة يتم فيها إدخال تسلسل إلى النموذج. أظهر الإخفاء الديناميكي أداءً مشابهاً أو أفضل قليلاً مقارنة بالإخفاء الثابت.

مقارنة بين الإخفاء الثابت والديناميكي لـ BERT
بناءً على النتائج المذكورة أعلاه، يتم استخدام نهج الإخفاء الديناميكي للتدريب المسبق لـ RoBERTa.
الجمل الكاملة بدون خسارة NSP
كشفت المقارنة بين التدريب بدون خسارة NSP والتدريب مع كتل نصية من مستند واحد (جمل المستند) أن هذا التكوين يتفوق على نتائج BERTBASE المنشورة أصلاً. علاوة على ذلك، فإن إزالة خسارة NSP إما تطابق أو تحسن قليلاً من الأداء في المهام اللاحقة.

جدول يوضح أداء RoBERTa مع وبدون خسارة NSP
بينما لوحظ أن تقييد التسلسلات لتأتي من مستند واحد (جمل المستند) يعطي أداءً أفضل قليلاً مقارنة بتضمين تسلسلات من مستندات متعددة (جمل كاملة)، يختار RoBERTa استخدام الجمل الكاملة لتسهيل المقارنة لأن تنسيق جمل المستند يؤدي إلى أحجام دفعات متغيرة.
التدريب بدفعات كبيرة
يعمل التدريب بأحجام دفعات كبيرة على تسريع التحسين وتحسين دقة المهمة. علاوة على ذلك، يسهل التدريب المتوازي الموزع للبيانات موازنة الدفعات الكبيرة، مما يزيد من الكفاءة. عند ضبطها بشكل مناسب، يمكن لأحجام الدفعات الكبيرة تحسين أداء النموذج في مهمة معينة.

مقارنة أداء RoBERTa في مهام مختلفة بأحجام دفعات متفاوتة
مفردات BPE أكبر على مستوى البايت
يجمع ترميز زوج البايت (BPE) بين جوانب التمثيل على مستوى الحرف والكلمة، مما يتيح معالجة فعالة للمفردات الواسعة النموذجية في مجموعات النصوص الطبيعية. يختلف RoBERTa عن BERT باستخدام مفردات BPE أكبر على مستوى البايت تتكون من 50 ألف وحدة فرعية، دون الحاجة إلى معالجة مسبقة إضافية أو تحليل رمزي للإدخال.
التنقل في حدود RoBERTa
بينما يعتبر RoBERTa نموذجاً قوياً، إلا أنه لا يخلو من القيود. فيما يلي بعضها:
- الموارد الحاسوبية: يتطلب تدريب وضبط RoBERTa موارد حاسوبية كبيرة، بما في ذلك وحدات معالجة رسوم قوية وذاكرة كبيرة. هذا قد يجعل من الصعب على الأفراد أو المؤسسات ذات الموارد المحدودة استخدام RoBERTa بفعالية.
- الخصوصية المجالية: قد لا تعمل نماذج اللغة المدربة مسبقاً مثل RoBERTa بشكل مثالي في المهام أو مجموعات البيانات الخاصة بمجال معين دون مزيد من الضبط الدقيق. قد تتطلب تدريباً إضافياً على بيانات خاصة بالمجال لتحقيق مستوى الأداء المطلوب.
- كفاءة البيانات: تتطلب نماذج مثل RoBERTa كميات كبيرة من البيانات للتدريب المسبق، والتي قد لا تكون متاحة لجميع اللغات أو المجالات. هذا الاعتماد على البيانات الضخمة يمكن أن يحد من قابلية تطبيقها في البيئات التي تكون فيها البيانات نادرة أو باهظة الثمن.
- قابلية التفسير: يمكن أن تجعل طبيعة الصندوق الأسود لـ RoBERTa من الصعب تفسير كيفية وصول النموذج إلى تنبؤاته. قد يكون فهم الآليات الداخلية للنموذج وتشخيص الأخطاء أو التحيزات أمراً صعباً، خاصة في التطبيقات المعقدة أو الحساسة.
- تحديات الضبط الدقيق: على الرغم من أن ضبط RoBERTa لمهام محددة يمكن أن يحسن الأداء، إلا أنه يتطلب خبرة وتجارب لاختيار المعلمات الفائقة الصحيحة، تقنيات زيادة البيانات، واستراتيجيات التدريب. هذه العملية يمكن أن تستغرق وقتاً وتستهلك موارد.
- التحيز والعدالة: يمكن لنماذج اللغة المدربة مسبقاً مثل RoBERTa أن ترث التحيزات الموجودة في بيانات التدريب، مما يؤدي إلى تنبؤات متحيزة أو غير عادلة. معالجة التحيز وضمان العدالة في نماذج الذكاء الاصطناعي لا يزال تحدياً كبيراً يتطلب تنظيماً دقيقاً للبيانات واعتبارات تصميم النموذج.
- التعميم خارج التوزيع: قد يجد RoBERTa صعوبة في التعميم على بيانات خارج توزيعه الأصلي أو التعامل مع سيناريوهات مختلفة بشكل كبير عن بيانات تدريبه. هذا القيد يمكن أن يؤثر على متانة وموثوقية RoBERTa في التطبيقات الواقعية حيث تكون تحولات توزيع البيانات شائعة.
للتغلب على هذه القيود، يمكنك اختيار نماذج أكثر تقدماً مثل Llama 3 الذي تم إصداره مؤخراً. أو يمكنك تطبيق مفتاح API LLM الخاص بـ novita.ai على نظامك الحالي بسلاسة وبتكلفة منخفضة:

النماذج المميزة في API LLM الخاص بـ novita.ai

الخلاصة
يحقق RoBERTa تقدماً كبيراً في معالجة اللغة الطبيعية من خلال البناء على أساس BERT، باستخدام مجموعة بيانات تدريب أكبر بكثير وتقنيات محسّنة مثل الإخفاء الديناميكي وإزالة هدف التنبؤ بالجملة التالية. هذه التحسينات، إلى جانب استخدام مفردات BPE على مستوى البايت وأحجام الدفعات الأكبر، تمكن RoBERTa من تحقيق أداء متفوق في مهام NLP المختلفة. على الرغم من أنه يتطلب موارد حاسوبية كبيرة وخبرة في الضبط الدقيق، إلا أن تأثير RoBERTa في هذا المجال عميق، حيث يضع معايير جديدة ويعمل كنموذج متعدد الاستخدامات للتطبيقات البحثية والصناعية.
novita.ai، المنصة الشاملة للإبداع غير المحدود التي تمنحك الوصول إلى أكثر من 100 واجهة برمجة تطبيقات. من توليد الصور ومعالجة اللغة إلى تحسين الصوت ومعالجة الفيديو، بنظام الدفع حسب الاستخدام الرخيص، يحررك من متاعب صيانة وحدات معالجة الرسوم أثناء بناء منتجاتك الخاصة. جربها مجاناً.
قراءة موصى بها
محرك استدلال LLM من Novita AI: أكبر إنتاجية وأرخص استدلال متاح



