

Introdução
RoBERTa (abreviação de “Robustly Optimized BERT Approach”) é uma versão avançada do modelo BERT (Bidirectional Encoder Representations from Transformers), criada por pesquisadores da Facebook AI. Semelhante ao BERT, o RoBERTa é um modelo de linguagem baseado em transformer que utiliza autoatenção para analisar sequências de entrada e produzir representações de palavras contextualizadas dentro de uma frase.
Neste artigo, examinaremos o RoBERTa em mais detalhes.
RoBERTa vs BERT
Uma diferença fundamental entre RoBERTa e BERT é que o RoBERTa foi treinado em um conjunto de dados significativamente maior e com um procedimento de treinamento mais eficaz. Especificamente, o RoBERTa foi treinado em 160 GB de texto, mais de 10 vezes o tamanho do conjunto de dados usado para o BERT. Além disso, o RoBERTa emprega uma técnica de mascaramento dinâmico durante o treinamento, o que melhora a capacidade do modelo de aprender representações de palavras mais robustas e generalizáveis.
O RoBERTa demonstrou desempenho superior em comparação com o BERT e outros modelos líderes em várias tarefas de processamento de linguagem natural, como tradução de idiomas, classificação de texto e resposta a perguntas. Também serviu como modelo fundamental para vários modelos de PNL bem-sucedidos e ganhou popularidade tanto para pesquisa quanto para aplicações industriais.
Em resumo, o RoBERTa é um modelo de linguagem poderoso e eficaz que fez contribuições significativas para a PNL, avançando o progresso em uma ampla gama de aplicações.
Arquitetura do Modelo RoBERTa
O modelo RoBERTa compartilha a mesma arquitetura do modelo BERT. É uma reimplementação do BERT com modificações em hiperparâmetros-chave e pequenos ajustes nos embeddings.
Os procedimentos gerais de pré-treinamento e ajuste fino para o BERT são ilustrados na Figura 1 abaixo. No BERT, a mesma arquitetura é usada tanto para pré-treinamento quanto para ajuste fino, exceto pelas camadas de saída. Os parâmetros do modelo pré-treinado são usados para inicializar modelos para várias tarefas downstream. Durante o ajuste fino, todos os parâmetros são ajustados.
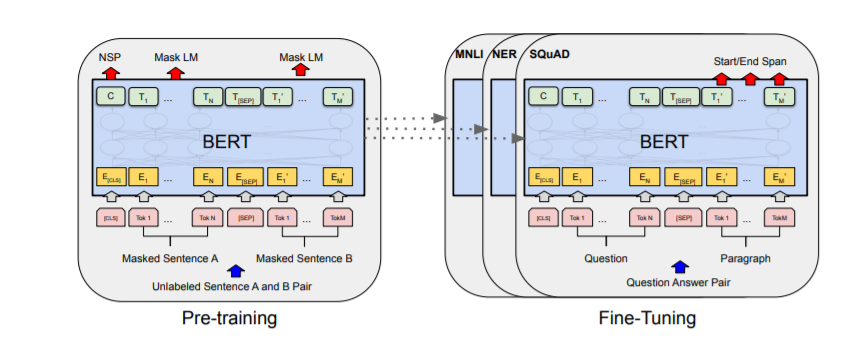
Arquitetura do modelo BERT
Em contraste, o RoBERTa não usa o objetivo de pré-treinamento de próxima frase. Em vez disso, é treinado com mini-lotes muito maiores e taxas de aprendizado mais altas. O RoBERTa emprega um esquema de pré-treinamento diferente e substitui o vocabulário BPE de nível de caractere por um tokenizador BPE de nível de byte (semelhante ao GPT-2). Além disso, o RoBERTa não requer a definição de qual token pertence a qual segmento, pois não possui token_type_ids. Os segmentos podem ser facilmente divididos usando o token de separação tokenizer.sep_token (ou ).
Além disso, ao contrário do conjunto de dados de 16 GB usado originalmente para treinar o BERT, o RoBERTa é treinado em um conjunto de dados massivo que excede 160 GB de texto descompactado. Este conjunto de dados inclui os 16 GB da Wikipédia em inglês e do Books Corpus usados no BERT, juntamente com dados adicionais do corpus WebText (38 GB), do conjunto de dados CommonCrawl News (63 milhões de artigos, 76 GB) e Stories from Common Crawl (31 GB). O RoBERTa foi pré-treinado usando este extenso conjunto de dados e 1024 GPUs V100 Tesla rodando por um dia.
Vantagens do Modelo RoBERTa
O RoBERTa tem uma arquitetura semelhante ao BERT, mas para melhorar o desempenho, os autores fizeram várias mudanças simples de design na arquitetura e no procedimento de treinamento. Essas mudanças incluem:
- Remoção do Objetivo de Predição da Próxima Frase (NSP): No BERT, o modelo é treinado para prever se dois segmentos de um documento são do mesmo documento ou de documentos diferentes usando uma perda auxiliar de NSP. Os autores experimentaram versões do modelo com e sem a perda de NSP e descobriram que remover a perda de NSP igualou ou melhorou ligeiramente o desempenho em tarefas downstream.
- Treinamento com Tamanhos de Lote Maiores e Sequências Mais Longas: O BERT foi originalmente treinado por 1 milhão de passos com um tamanho de lote de 256 sequências. O RoBERTa foi treinado com 125 passos de 2.000 sequências e 31.000 passos com 8.000 sequências por lote. Lotes maiores melhoram a perplexidade no objetivo de modelagem de linguagem mascarada e a precisão da tarefa final. Eles também são mais fáceis de paralelizar usando treinamento paralelo distribuído.
- Mudança Dinâmica do Padrão de Mascaramento: No BERT, o mascaramento é feito uma vez durante o pré-processamento dos dados, resultando em uma máscara estática única. Para evitar isso, os dados de treinamento são duplicados e mascarados 10 vezes com diferentes estratégias ao longo de 40 épocas, resultando em 4 épocas com a mesma máscara. Esta estratégia foi comparada com o mascaramento dinâmico, onde diferentes máscaras são geradas cada vez que os dados são passados para o modelo.
Desempenho do RoBERTa
O modelo RoBERTa alcançou desempenho de última geração nas tarefas MNLI, QNLI, RTE, STS-B e RACE na época, e demonstrou melhorias significativas de desempenho no benchmark GLUE. Com uma pontuação de 88,5, o RoBERTa reivindicou a primeira posição na tabela de classificação do GLUE.

Comparação do BERT e melhorias sucessivas sobre ele
Como Usar o RoBERTa
A biblioteca Transformers da Huggingface oferece uma variedade de modelos RoBERTa pré-treinados em diferentes tamanhos e para várias tarefas. Neste post, focaremos em como carregar um modelo RoBERTa e realizar classificação de emoções.
Usaremos um modelo RoBERTa ajustado em um conjunto de dados específico da tarefa, especificamente o modelo pré-treinado “cardiffnlp/twitter-roberta-base-emotion” do hub Huggingface.
Primeiro, precisamos instalar e importar todos os pacotes necessários e carregar o modelo usando RobertaForSequenceClassification (que inclui uma cabeça de classificação) e o tokenizador usando RobertaTokenizer.
!pip install -q transformers
#Importando os pacotes necessários
import torch
from transformers import RobertaTokenizer, RobertaForSequenceClassification
#Carregando o modelo e o tokenizador
model_name = "cardiffnlp/twitter-roberta-base-emotion"
tokenizer = RobertaTokenizer.from_pretrained(model_name)
model = RobertaForSequenceClassification.from_pretrained(model_name)
#Tokenizando a entrada
inputs = tokenizer("I love my cat", return_tensors="pt")
#Recuperando os logits e usando-os para prever a emoção subjacente
with torch.no_grad():
logits = model(**inputs).logits
predicted_class_id = logits.argmax().item()
model.config.id2label[predicted_class_id]
>> Output: Optimism
A saída é “Optimism”, que está correta com base nos rótulos predefinidos do modelo de classificação que usamos. Podemos usar outro modelo pré-treinado ou ajustar um modelo para obter resultados com rótulos mais apropriados.
Resultados de Avaliação do RoBERTa
Treinamento com mascaramento dinâmico
Na implementação original do BERT, o mascaramento ocorre durante o pré-processamento dos dados, levando a uma única máscara estática. Este método foi comparado ao mascaramento dinâmico, onde um novo padrão de mascaramento é gerado cada vez que uma sequência é inserida no modelo. O mascaramento dinâmico demonstrou desempenho comparável ou ligeiramente superior em comparação ao mascaramento estático.

Comparação entre mascaramento estático e dinâmico para BERT
Com base nas descobertas mencionadas acima, a abordagem de mascaramento dinâmico é utilizada para o pré-treinamento do RoBERTa.
FRASES COMPLETAS sem perda NSP
A comparação entre o treinamento sem a perda NSP e o treinamento com blocos de texto de um único documento (doc-sentences) revelou que esta configuração supera os resultados publicados originalmente para BERTBASE. Além disso, eliminar a perda NSP iguala ou melhora ligeiramente o desempenho em tarefas downstream.

Tabela ilustrando o desempenho do RoBERTa com e sem perda NSP
Embora tenha sido observado que limitar sequências a um único documento (DOC-SENTENCES) produz desempenho ligeiramente melhor em comparação com a incorporação de sequências de múltiplos documentos (FULL-SENTENCES), o RoBERTa opta por usar FULL-SENTENCES para facilitar a comparação, já que o formato DOC-SENTENCES leva a tamanhos de lote variáveis.
Treinamento com lotes grandes
O treinamento com tamanhos de lote grandes acelera a otimização e melhora a precisão da tarefa. Além disso, o treinamento paralelo distribuído de dados facilita a paralelização de lotes grandes, melhorando ainda mais a eficiência. Quando ajustados adequadamente, tamanhos de lote grandes podem melhorar o desempenho do modelo em uma determinada tarefa.

Comparação do desempenho do RoBERTa em diferentes tarefas com tamanhos de lote variados
Um BPE de nível de byte maior
A codificação por pares de bytes (BPE) combina aspectos de representações de nível de caractere e de palavra, permitindo o tratamento eficaz dos extensos vocabulários típicos em corpora de linguagem natural. O RoBERTa diverge do BERT ao empregar um vocabulário BPE de nível de byte maior, consistindo em 50 mil unidades de subpalavras, sem exigir pré-processamento adicional ou tokenização de entrada.
Navegando pelas Limitações do RoBERTa
Embora o RoBERTa seja um modelo poderoso, não está isento de limitações. Aqui estão algumas:
- Recursos Computacionais: Treinar e ajustar o RoBERTa requer recursos computacionais significativos, incluindo GPUs poderosas e grandes quantidades de memória. Isso pode dificultar o uso eficaz do RoBERTa por indivíduos ou organizações com recursos limitados.
- Especificidade de Domínio: Modelos de linguagem pré-treinados como o RoBERTa podem não ter desempenho ideal em tarefas ou conjuntos de dados específicos de domínio sem ajuste fino adicional. Eles podem exigir treinamento adicional em dados específicos do domínio para alcançar o nível de desempenho desejado.
- Eficiência de Dados: O RoBERTa e modelos semelhantes requerem grandes quantidades de dados para pré-treinamento, que podem não estar disponíveis para todos os idiomas ou domínios. Essa dependência de dados extensos pode limitar sua aplicabilidade em ambientes onde os dados são escassos ou caros de adquirir.
- Interpretabilidade: A natureza de caixa preta do RoBERTa pode dificultar a interpretação de como o modelo chega às suas previsões. Entender o funcionamento interno do modelo e diagnosticar erros ou vieses pode ser desafiador, especialmente em aplicações complexas ou domínios sensíveis.
- Desafios de Ajuste Fino: Embora o ajuste fino do RoBERTa para tarefas específicas possa melhorar o desempenho, requer experiência e experimentação para selecionar os hiperparâmetros, técnicas de aumento de dados e estratégias de treinamento corretos. Esse processo pode ser demorado e intensivo em recursos.
- Viés e Equidade: Modelos de linguagem pré-treinados como o RoBERTa podem herdar vieses presentes nos dados de treinamento, levando a previsões tendenciosas ou injustas. Abordar o viés e garantir a equidade em modelos de IA continua sendo um desafio significativo, exigindo curadoria cuidadosa de dados e considerações de design de modelo.
- Generalização Fora da Distribuição: O RoBERTa pode ter dificuldade em generalizar para dados fora da distribuição ou lidar com cenários significativamente diferentes de seus dados de treinamento. Essa limitação pode impactar a robustez e confiabilidade do RoBERTa em aplicações do mundo real, onde mudanças na distribuição de dados são comuns.
Para superar essas limitações, você pode escolher modelos mais avançados, como o Llama 3, que foi lançado recentemente. Ou você pode aplicar a chave da API LLM da novita.ai ao seu sistema existente de forma integrada e com baixo custo:

Modelos apresentados pela API LLM da novita.ai

Conclusão
O RoBERTa avança significativamente o processamento de linguagem natural ao construir sobre a base do BERT, utilizando um conjunto de dados de treinamento muito maior e técnicas aprimoradas como mascaramento dinâmico e a remoção do objetivo de predição da próxima frase. Essas melhorias, juntamente com o uso de um tokenizador BPE de nível de byte e tamanhos de lote maiores, permitem que o RoBERTa alcance desempenho superior em várias tarefas de PNL. Embora exija recursos computacionais substanciais e experiência em ajuste fino, o impacto do RoBERTa no campo é profundo, estabelecendo novos benchmarks e servindo como um modelo versátil para pesquisa e aplicações industriais.
novita.ai, a plataforma completa para criatividade ilimitada que oferece acesso a mais de 100 APIs. Desde geração de imagens e processamento de linguagem até aprimoramento de áudio e manipulação de vídeo, com pagamento conforme o uso e baixo custo, libera você das preocupações com manutenção de GPU enquanto constrói seus próprios produtos. Experimente gratuitamente.
Leitura recomendada
Novita AI LLM Inference Engine: a maior taxa de transferência e a inferência mais barata disponível



