

はじめに
RoBERTa(「Robustly Optimized BERT Approach」の略)は、Facebook AIの研究者によって作成されたBERT(Bidirectional Encoder Representations from Transformers)モデルの高度なバージョンです。BERTと同様に、RoBERTaはトランスフォーマーベースの言語モデルであり、自己注意機構を使用して入力シーケンスを分析し、文内の文脈化された単語表現を生成します。
この記事では、RoBERTaについてより詳しく見ていきます。
RoBERTa vs BERT
RoBERTaとBERTの主な違いは、RoBERTaが大幅に大きなデータセットとより効果的なトレーニング手順でトレーニングされたことです。具体的には、RoBERTaは160GBのテキストでトレーニングされており、これはBERTに使用されたデータセットの10倍以上のサイズです。さらに、RoBERTaはトレーニング中に動的マスキング手法を採用しており、モデルがより堅牢で一般化可能な単語表現を学習する能力を高めています。
RoBERTaは、言語翻訳、テキスト分類、質問応答など、さまざまな自然言語処理タスクにおいてBERTや他の主要モデルよりも優れたパフォーマンスを示しています。また、多くの成功したNLPモデルの基盤モデルとしても機能し、研究および産業用途の両方で人気を博しています。
まとめると、RoBERTaは強力で効果的な言語モデルであり、NLPに多大な貢献をし、幅広いアプリケーションにわたる進歩を促進しています。
RoBERTaモデルのアーキテクチャ
RoBERTaモデルはBERTモデルと同じアーキテクチャを共有しています。これはBERTの再実装であり、主要なハイパーパラメータの変更と埋め込みの微調整が行われています。
BERTの一般的な事前トレーニングとファインチューニングの手順を以下の図1に示します。BERTでは、出力層を除いて、事前トレーニングとファインチューニングに同じアーキテクチャが使用されます。事前トレーニングされたモデルパラメータは、さまざまな下流タスクのモデルを初期化するために使用されます。ファインチューニング中は、すべてのパラメータが調整されます。
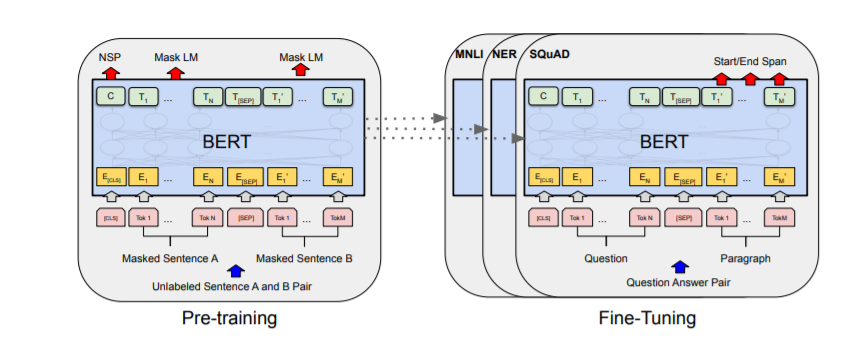
BERTモデルのアーキテクチャ
対照的に、RoBERTaは次の文予測の事前トレーニング目的を使用しません。代わりに、はるかに大きなミニバッチと高い学習率でトレーニングされます。RoBERTaは異なる事前トレーニングスキームを採用し、文字レベルのBPEボキャブラリをバイトレベルのBPEトークナイザ(GPT-2と同様)に置き換えています。さらに、RoBERTaは token_type_ids を持たないため、どのトークンがどのセグメントに属するかを定義する必要がありません。セグメントは、区切りトークン tokenizer.sep_token (または <sep> )を使用して簡単に分割できます。
さらに、BERTのトレーニングに使用された16GBのデータセットとは異なり、RoBERTaは160GBを超える非圧縮テキストの大規模なデータセットでトレーニングされています。このデータセットには、BERTで使用された16GBの英語版WikipediaとBooks Corpusに加えて、WebTextコーパス(38GB)、CommonCrawl Newsデータセット(6300万記事、76GB)、Common Crawlのストーリー(31GB)の追加データが含まれています。RoBERTaはこの広範なデータセットと1024台のV100 Tesla GPUを1日かけて使用して事前トレーニングされました。
RoBERTaモデルの利点
RoBERTaはBERTと同様のアーキテクチャを持ちますが、パフォーマンスを向上させるために、著者はアーキテクチャとトレーニング手順にいくつかの簡単な設計変更を加えました。これらの変更には以下のものがあります。
- Next Sentence Prediction (NSP) 目的の削除: BERTでは、モデルは補助的なNSP損失を使用して、ドキュメントの2つのセグメントが同じドキュメントからか異なるドキュメントからかを予測するようにトレーニングされます。著者はNSP損失の有無でモデルのバージョンを実験し、NSP損失を削除すると下流タスクのパフォーマンスが同等かわずかに向上することを発見しました。
- より大きなバッチサイズと長いシーケンスでのトレーニング: BERTはもともと256シーケンスのバッチサイズで100万ステップトレーニングされました。RoBERTaは2000シーケンスの125ステップと、1バッチあたり8000シーケンスの31,000ステップでトレーニングされました。大きなバッチは、マスク言語モデリング目的のパープレキシティと最終タスクの精度を向上させます。また、分散並列トレーニングを使用して並列化も容易です。
- マスキングパターンの動的変更: BERTでは、マスキングはデータ前処理中に1回行われるため、単一の静的マスクになります。これを避けるために、トレーニングデータを複製し、40エポックにわたって異なる戦略で10回マスキングし、同じマスクで4エポックになります。この戦略は、データがモデルに渡されるたびに異なるマスクが生成される動的マスキングと比較されました。
RoBERTaのパフォーマンス
RoBERTaモデルは、当時MNLI、QNLI、RTE、STS-B、RACEのタスクで最先端のパフォーマンスを達成し、GLUEベンチマークで大幅なパフォーマンス向上を示しました。スコア88.5で、RoBERTaはGLUEリーダーボードでトップの位置を獲得しました。

BERTとその後の改良の比較
RoBERTaの使用方法
HuggingfaceのTransformersライブラリは、さまざまなサイズとタスク向けの多様な事前トレーニング済みRoBERTaモデルを提供しています。この投稿では、RoBERTaモデルをロードして感情分類を実行する方法に焦点を当てます。
タスク固有のデータセットでファインチューニングされたRoBERTaモデル、具体的にはHuggingfaceハブの事前トレーニング済みモデル「cardiffnlp/twitter-roberta-base-emotion」を使用します。
まず、必要なパッケージをすべてインストールしてインポートし、RobertaForSequenceClassification(分類ヘッドを含む)を使用してモデルを、RobertaTokenizerを使用してトークナイザをロードする必要があります。
!pip install -q transformers
# Importing the necessary packages
import torch
from transformers import RobertaTokenizer, RobertaForSequenceClassification
# Loading the model and tokenizer
model_name = "cardiffnlp/twitter-roberta-base-emotion"
tokenizer = RobertaTokenizer.from_pretrained(model_name)
model = RobertaForSequenceClassification.from_pretrained(model_name)
# Tokenizing the input
inputs = tokenizer("I love my cat", return_tensors="pt")
# Retrieving the logits and using them for predicting the underlying emotion
with torch.no_grad():
logits = model(**inputs).logits
predicted_class_id = logits.argmax().item()
model.config.id2label[predicted_class_id]
# >> Output: Optimism
出力は「Optimism」であり、これは使用した分類モデルの事前定義されたラベルに基づいて正しいです。別の事前トレーニング済みモデルを使用するか、モデルをファインチューニングして、より適切なラベルの結果を得ることができます。
RoBERTaの評価結果
動的マスキングによるトレーニング
元のBERT実装では、マスキングはデータ前処理中に行われるため、単一の静的マスクになります。この方法は、シーケンスがモデルに入力されるたびに新しいマスキングパターンが生成される動的マスキングと比較されました。動的マスキングは、静的マスキングと比較して同等またはわずかに優れたパフォーマンスを示しました。

BERTの静的マスキングと動的マスキングの比較
上記の結果に基づき、RoBERTaの事前トレーニングには動的マスキングアプローチが使用されています。
NSP損失なしのFULL-SENTENCES
NSP損失なしのトレーニングと、単一ドキュメントからのテキストブロック(doc-sentences)によるトレーニングの比較では、この構成が元の公開されたBERTBASEの結果を上回ることが明らかになりました。さらに、NSP損失を排除すると、下流タスクのパフォーマンスが同等かわずかに向上します。

NSP損失の有無によるRoBERTaのパフォーマンスを示す表
シーケンスを単一ドキュメント(DOC-SENTENCES)からのものに制限すると、複数ドキュメントからのシーケンス(FULL-SENTENCES)を取り入れる場合よりもわずかに優れたパフォーマンスが得られることが観察されましたが、RoBERTaはDOC-SENTENCES形式がバッチサイズの変動を引き起こすため、比較を容易にするためにFULL-SENTENCESを使用することを選択しました。
大規模バッチによるトレーニング
大規模なバッチサイズでのトレーニングは最適化を加速し、タスクの精度を向上させます。さらに、分散データ並列トレーニングにより、大規模バッチの並列化が容易になり、効率がさらに向上します。適切に調整された場合、大規模なバッチサイズは特定のタスクにおけるモデルのパフォーマンスを向上させることができます。

異なるバッチサイズでのRoBERTaのパフォーマンス比較
より大きなバイトレベルのBPE
バイトペアエンコーディング(BPE)は、文字レベルと単語レベルの表現の側面を組み合わせ、自然言語コーパスに典型的な広範な語彙を効果的に処理できるようにします。RoBERTaは、50Kのサブワードユニットからなるより大きなバイトレベルのBPEボキャブラリを使用することでBERTと異なり、追加の前処理や入力トークン化を必要としません。
RoBERTaの限界
RoBERTaは強力なモデルですが、限界がないわけではありません。以下にいくつか挙げます。
- 計算リソース: RoBERTaのトレーニングとファインチューニングには、強力なGPUと大量のメモリを含む多大な計算リソースが必要です。そのため、リソースが限られている個人や組織がRoBERTaを効果的に活用することが困難になる可能性があります。
- ドメイン特異性: 事前トレーニングされた言語モデルであるRoBERTaは、さらなるファインチューニングを行わないと、ドメイン固有のタスクやデータセットで最適に機能しない場合があります。望ましいパフォーマンスレベルを達成するには、ドメイン固有のデータで追加のトレーニングが必要になる場合があります。
- データ効率: RoBERTaおよび同様のモデルは事前トレーニングに大量のデータを必要としますが、それがすべての言語やドメインで利用できるとは限りません。このデータへの依存度の高さは、データが不足しているか、取得に費用がかかる環境での適用性を制限する可能性があります。
- 解釈可能性: RoBERTaのブラックボックス的な性質により、モデルがどのように予測に至るかを解釈することが困難になる場合があります。モデルの内部動作を理解し、エラーやバイアスを診断することは、特に複雑なアプリケーションやセンシティブなドメインでは難しい場合があります。
- ファインチューニングの課題: 特定のタスク向けにRoBERTaをファインチューニングするとパフォーマンスが向上する可能性がありますが、適切なハイパーパラメータ、データ拡張技術、トレーニング戦略を選択するには専門知識と実験が必要です。このプロセスには時間とリソースがかかる場合があります。
- バイアスと公平性: 事前トレーニングされた言語モデルであるRoBERTaは、トレーニングデータに存在するバイアスを継承し、バイアスのかかった不公平な予測につながる可能性があります。AIモデルのバイアスに対処し、公平性を確保することは依然として重要な課題であり、慎重なデータキュレーションとモデル設計の考慮が必要です。
- 分布外の一般化: RoBERTaは、分布外のデータに対して一般化したり、トレーニングデータとは大幅に異なるシナリオを処理したりするのに苦労する可能性があります。この限界は、データ分布の変化が一般的な実世界のアプリケーションにおけるRoBERTaの堅牢性と信頼性に影響を与える可能性があります。
これらの限界を克服するために、最近発表されたLlama 3などのより高度なモデルを選択することができます。または、novita.aiのLLM APIキーを既存のシステムに低コストでシームレスに適用することもできます。

novita.ai LLM APIが提供するモデル

結論
RoBERTaは、BERTの基盤を基に、はるかに大規模なトレーニングデータセットと、動的マスキングや次の文予測目的の削除などの改善された技術を活用することで、自然言語処理を大幅に進歩させます。これらの強化に加え、バイトレベルのBPEトークナイザと大規模バッチサイズの使用により、RoBERTaはさまざまなNLPタスクで優れたパフォーマンスを達成できます。多大な計算リソースとファインチューニングの専門知識を必要としますが、RoBERTaのこの分野への影響は大きく、新しいベンチマークを設定し、研究および産業用途向けの汎用モデルとして機能しています。
novita.ai は、無限の創造性を実現するワンストッププラットフォームで、100以上のAPIにアクセスできます。画像生成や言語処理からオーディオ強化、ビデオ操作まで、従量課金制で手頃な価格を実現し、GPUメンテナンスの手間から解放されながら独自の製品を構築できます。無料でお試しください。
おすすめ記事



