

Introduction
RoBERTa (short for “Robustly Optimized BERT Approach”) is an advanced version of the BERT (Bidirectional Encoder Representations from Transformers) model, created by researchers at Facebook AI. Similar to BERT, RoBERTa is a transformer-based language model that employs self-attention to analyze input sequences and produce contextualized word representations within a sentence.
In this article, we will take a look a look at the RoBERTa in more detail.
RoBERTa vs BERT
A key difference between RoBERTa and BERT is that RoBERTa was trained on a significantly larger dataset and with a more effective training procedure. Specifically, RoBERTa was trained on 160GB of text, over 10 times the size of the dataset used for BERT. Additionally, RoBERTa employs a dynamic masking technique during training, which enhances the model’s ability to learn more robust and generalizable word representations.
RoBERTa has demonstrated superior performance compared to BERT and other leading models on various natural language processing tasks, such as language translation, text classification, and question answering. It has also served as a foundational model for numerous successful NLP models and has gained popularity for both research and industrial applications.
In summary, RoBERTa is a powerful and effective language model that has made significant contributions to NLP, advancing progress across a wide range of applications.
RoBERTa Model Architecture
The RoBERTa model shares the same architecture as the BERT model. It is a reimplementation of BERT with modifications to key hyperparameters and minor adjustments to embeddings.
The general pre-training and fine-tuning procedures for BERT are illustrated in Figure 1 below. In BERT, the same architecture is used for both pre-training and fine-tuning, except for the output layers. The pre-trained model parameters are used to initialize models for various downstream tasks. During fine-tuning, all parameters are adjusted.
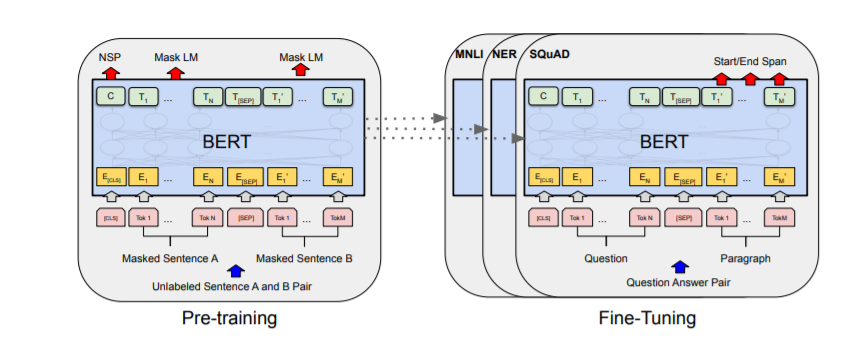
Architecture of BERT model
In contrast, RoBERTa does not use the next-sentence pretraining objective. Instead, it is trained with much larger mini-batches and higher learning rates. RoBERTa employs a different pretraining scheme and replaces the character-level BPE vocabulary with a byte-level BPE tokenizer (similar to GPT-2). Additionally, RoBERTa does not require the definition of which token belongs to which segment, as it lacks token_type_ids. Segments can be easily divided using the separation token tokenizer.sep_token (or ).
Furthermore, unlike the 16GB dataset originally used to train BERT, RoBERTa is trained on a massive dataset exceeding 160GB of uncompressed text. This dataset includes the 16GB of English Wikipedia and Books Corpus used in BERT, along with additional data from the WebText corpus (38 GB), the CommonCrawl News dataset (63 million articles, 76 GB), and Stories from Common Crawl (31 GB). RoBERTa was pre-trained using this extensive dataset and 1024 V100 Tesla GPUs running for a day.
Advantages of RoBERTa Model
RoBERTa has a similar architecture to BERT, but to enhance performance, the authors made several simple design changes to the architecture and training procedure. These changes include:
- Removing the Next Sentence Prediction (NSP) Objective: In BERT, the model is trained to predict whether two segments of a document are from the same or different documents using an auxiliary NSP loss. The authors experimented with versions of the model with and without the NSP loss and found that removing the NSP loss either matched or slightly improved performance on downstream tasks.
- Training with Larger Batch Sizes and Longer Sequences: BERT was originally trained for 1 million steps with a batch size of 256 sequences. RoBERTa was trained with 125 steps of 2,000 sequences and 31,000 steps with 8,000 sequences per batch. Larger batches improve perplexity on the masked language modeling objective and end-task accuracy. They are also easier to parallelize using distributed parallel training.
- Dynamically Changing the Masking Pattern: In BERT, masking is done once during data preprocessing, resulting in a single static mask. To avoid this, training data is duplicated and masked 10 times with different strategies over 40 epochs, resulting in 4 epochs with the same mask. This strategy was compared with dynamic masking, where different masks are generated each time data is passed into the model.
performance of RoBERTa
The RoBERTa model achieved state-of-the-art performance on the MNLI, QNLI, RTE, STS-B, and RACE tasks at the time, and demonstrated significant performance improvements on the GLUE benchmark. With a score of 88.5, RoBERTa claimed the top position on the GLUE leaderboard.

Comparison of BERT and successive improvements over it
How to Use RoBERTa
Huggingface’s Transformers library offers a variety of pre-trained RoBERTa models in different sizes and for various tasks. In this post, we will focus on how to load a RoBERTa model and perform emotion classification.
We will use a RoBERTa model fine-tuned on a task-specific dataset, specifically the pre-trained model “cardiffnlp/twitter-roberta-base-emotion” from the Huggingface hub.
First, we need to install and import all the necessary packages and load the model using `RobertaForSequenceClassification` (which includes a classification head) and the tokenizer using `RobertaTokenizer`.
!pip install -q transformers#Importing the necessary packages
import torch
from transformers import RobertaTokenizer, RobertaForSequenceClassification#Loading the model and tokenizer
model_name = “cardiffnlp/twitter-roberta-base-emotion”
tokenizer = RobertaTokenizer.from_pretrained(model_name)
model = RobertaForSequenceClassification.from_pretrained(model_name)#Tokenizing the input
inputs = tokenizer(“I love my cat”, return_tensors=“pt”)#Retrieving the logits and using them for predicting the underlying emotion
with torch.no_grad():
logits = model(**inputs).logitspredicted_class_id = logits.argmax().item()model.config.id2label[predicted_class_id]
Output: Optimism
The output is “Optimism,” which is correct based on the pre-defined labels of the classification model we used. We can use another pre-trained model or fine-tune a model to obtain results with more appropriate labels.
Evaluation Results of RoBERTa
Training with dynamic masking
In the original BERT implementation, masking occurs during data preprocessing, leading to a single static mask. This method was compared to dynamic masking, where a new masking pattern is generated each time a sequence is inputted into the model. Dynamic masking demonstrated comparable or slightly superior performance compared to static masking.

Comparison between static and dynamic masking for BERT
Based on the findings mentioned above, the dynamic masking approach is utilized for pretraining RoBERTa.
FULL-SENTENCES without NSP loss
The comparison between training without the NSP loss and training with blocks of text from a single document (doc-sentences) revealed that this configuration outperforms the originally published BERTBASE results. Furthermore, eliminating the NSP loss either matches or slightly enhances performance on downstream tasks.

Table illustrating the performance of RoBERTa with and without NSP loss
While it was observed that limiting sequences to come from a single document (DOC-SENTENCES) yields slightly better performance compared to incorporating sequences from multiple documents (FULL-SENTENCES), RoBERTa opts for using FULL-SENTENCES for easier comparison as the DOC-SENTENCES format leads to variable batch sizes.
Training with large batches
Training with large batch sizes expedites optimization and enhances task accuracy. Moreover, distributed data-parallel training facilitates the parallelization of large batches, further improving efficiency. When appropriately tuned, large batch sizes can enhance the model’s performance on a given task.

Comparison of Performance of the RoBERTa on different tasks with varying Batch Sizes
A larger byte-level BPE
Byte-pair encoding (BPE) combines aspects of character-level and word-level representations, enabling effective handling of the extensive vocabularies typical in natural language corpora. RoBERTa diverges from BERT by employing a larger byte-level BPE vocabulary consisting of 50K subword units, without requiring additional preprocessing or input tokenization.
Navigating to Limitations of RoBERTa
While RoBERTa is a powerful model, it’s not without its limitations. Here are some:
- Computational Resources: Training and fine-tuning RoBERTa requires significant computational resources, including powerful GPUs and large amounts of memory. This can make it challenging for individuals or organizations with limited resources to utilize RoBERTa effectively.
- Domain Specificity: Pre-trained language models like RoBERTa may not perform optimally on domain-specific tasks or datasets without further fine-tuning. They may require additional training on domain-specific data to achieve the desired level of performance.
- Data Efficiency: RoBERTa and similar models require large amounts of data for pre-training, which might not be available for all languages or domains. This reliance on extensive data can limit their applicability in settings where data is scarce or expensive to acquire.
- Interpretability: The black-box nature of RoBERTa can make it difficult to interpret how the model arrives at its predictions. Understanding the inner workings of the model and diagnosing errors or biases can be challenging, especially in complex applications or sensitive domains.
- Fine-tuning Challenges: While fine-tuning RoBERTa for specific tasks can improve performance, it requires expertise and experimentation to select the right hyperparameters, data augmentation techniques, and training strategies. This process can be time-consuming and resource-intensive.
- Bias and Fairness: Pre-trained language models like RoBERTa can inherit biases present in the training data, leading to biased or unfair predictions. Addressing bias and ensuring fairness in AI models remains a significant challenge, requiring careful data curation and model design considerations.
- Out-of-Distribution Generalization: RoBERTa may struggle to generalize to out-of-distribution data or handle scenarios significantly different from its training data. This limitation can impact the robustness and reliability of RoBERTa in real-world applications where data distribution shifts are common.
To overcome these limitations, you can choose more advanced models such an Llama 3 which is released recently. Or you can apply novita.aiLLM API key to your existing system seamlessly with low cost:

Models featured by novita.ai LLM API

Conclusion
RoBERTa significantly advances natural language processing by building on BERT’s foundation, utilizing a much larger training dataset and improved techniques like dynamic masking and the removal of the next-sentence prediction objective. These enhancements, along with the use of a byte-level BPE tokenizer and larger batch sizes, enable RoBERTa to achieve superior performance on various NLP tasks. While it requires substantial computational resources and fine-tuning expertise, RoBERTa’s impact on the field is profound, setting new benchmarks and serving as a versatile model for research and industrial applications.
novita.ai, the one-stop platform for limitless creativity that gives you access to 100+ APIs. From image generation and language processing to audio enhancement and video manipulation,cheap pay-as-you-go , it frees you from GPU maintenance hassles while building your own products. Try it for free.
Recommended reading
Novita AI LLM Inference Engine: the largest throughput and cheapest inference available



