

주요 요점
DeepSeek R1: 강화 학습(RL)과 지도 미세 조정(SFT)을 결합하여 개발된 고급 추론 능력으로 유명합니다. SFT 없이 대규모 RL로만 훈련된 DeepSeek-R1-Zero와 같은 특화 변형 모델을 포함하며, 자가 검증, 반성적 추론, 광범위한 사고 사슬 생성 등의 기능을 보여줍니다.
Qwen 2.5 72B: 프로그래밍, 수학적 문제 해결, 명령 수행 작업에 탁월합니다. 8K 토큰을 초과하는 장문 콘텐츠를 효과적으로 생성하고, 구조화된 데이터(예: 표)를 정확하게 처리하며, JSON과 같은 형식으로 구조화된 출력을 생성합니다. 또한 29개 이상의 언어에 걸친 강력한 다국어 지원을 제공합니다.
Novita AI가 3배 처리량과 한정 기간 20% 할인을 제공하는 Turbo 버전을 출시했습니다! Novita AI Playground에서 무료 체험을 시작할 수 있습니다!

대규모 언어 모델(LLM)은 빠르게 발전하고 있으며, DeepSeek-R1과 Qwen 2.5 72B와 같은 최첨단 모델이 현재 선두에 있습니다. 이 글에서는 DeepSeek-R1과 Qwen 2.5 72B의 아키텍처, 성능 특성 및 실제 사용 사례를 심층적으로 기술 비교합니다.
모델 기본 소개
비교를 시작하기 위해 먼저 각 모델의 기본 특성을 이해해 보겠습니다.
DeepSeek R1
- 출시일: 2025년 1월 21일
- 모델 규모:
- 주요 특징:
- 모델 크기: 671B 파라미터 (토큰당 37B 활성)
- 토크나이저: 자기 반성 태그가 포함된 향상된 토크나이저
- 지원 언어: 문화 적응형 다국어
- 멀티모달: 텍스트 전용
- 컨텍스트 윈도우: 128K 토큰
- 저장 형식: Q8/Q5 양자화 지원
- 아키텍처: 혼합 전문가(MoE) + RL 강화 훈련 파이프라인
- 훈련 방법: V3 기반 + RL 파이프라인 (SFT → RL → SFT → RL)
- 훈련 데이터: V3 기반 + RL 최적화 데이터
Qwen 2.5 72B
- 출시일: 2024년 9월 19일 (Qwen 2.5 시리즈)
- 모델 규모:
- 주요 특징:
- 모델 크기: 72B 파라미터
- 지원 언어: 29개 이상의 언어에 대한 강력한 다국어 지원
- 멀티모달: 텍스트 전용
- **컨텍스트 윈도우 **: 최대 128K 토큰 지원, 최대 8K 토큰 생성 가능
- 아키텍처: 혼합 전문가(MoE) + 멀티헤드 잠재 어텐션
- 훈련 데이터: 18조 토큰의 방대한 데이터셋으로 훈련
- 훈련 방법: 데이터에 따라 사전 훈련 방식 상이
DeepSeek R1과 Qwen 2.5 72B의 주요 차이점은 훈련 방식입니다. DeepSeek R1은 강화 학습(RL)을 광범위하게 사용(SFT → RL → SFT → RL)하여 추론 능력을 향상시킵니다. 반면 Qwen 2.5 72B는 주로 지도 미세 조정(SFT)과 광범위한 사전 훈련에 의존하며 명시적인 RL 최적화 없이 다국어 및 범용 성능에 중점을 둡니다.
속도 비교
직접 테스트해보고 싶다면 Novita AI 웹사이트에서 무료 체험을 시작할 수 있습니다.
비용 효율적이면서도 전체 크기의 DeepSeek R1 Turbo를 지금 사용해보세요!
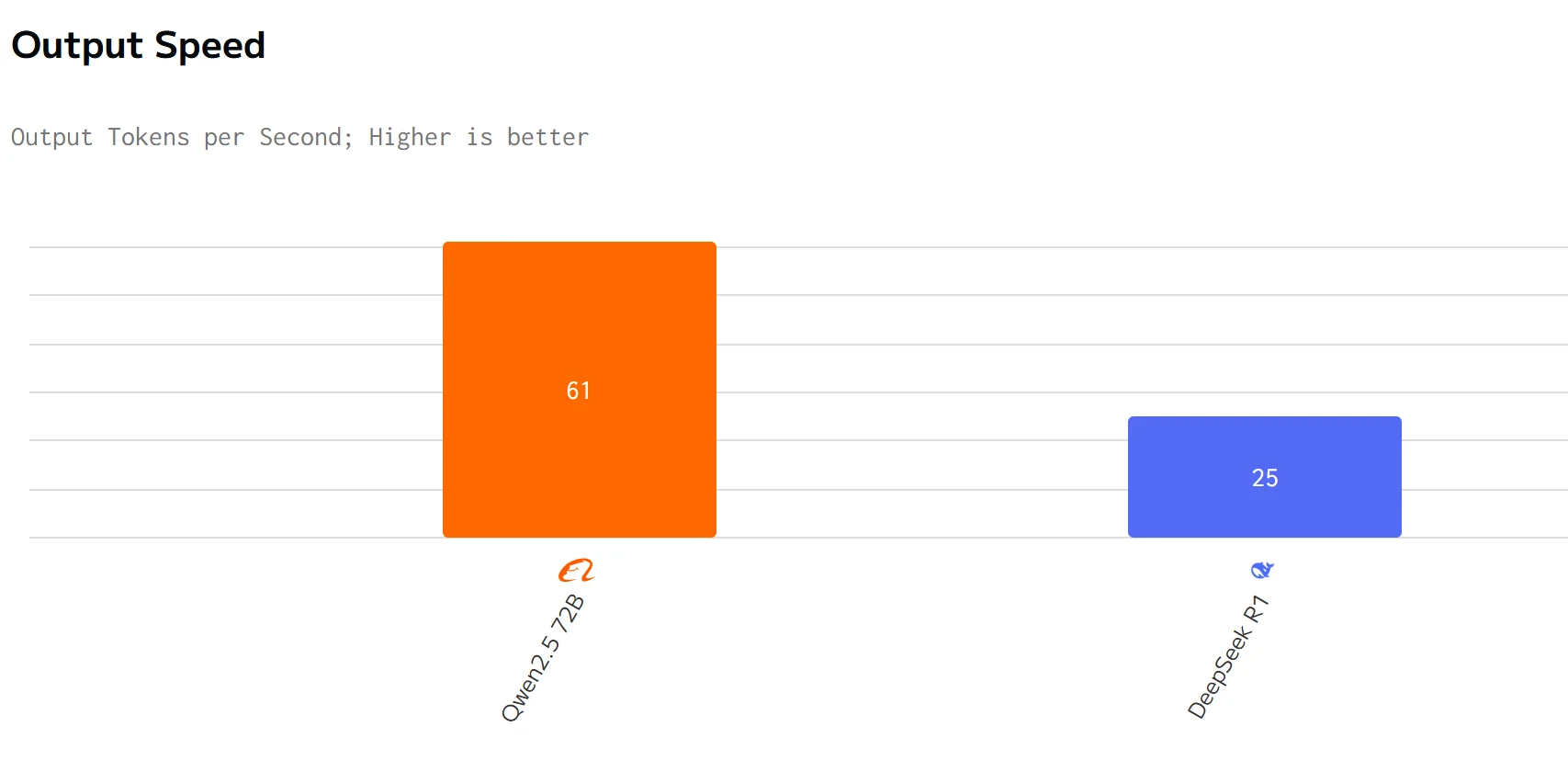
속도 비교
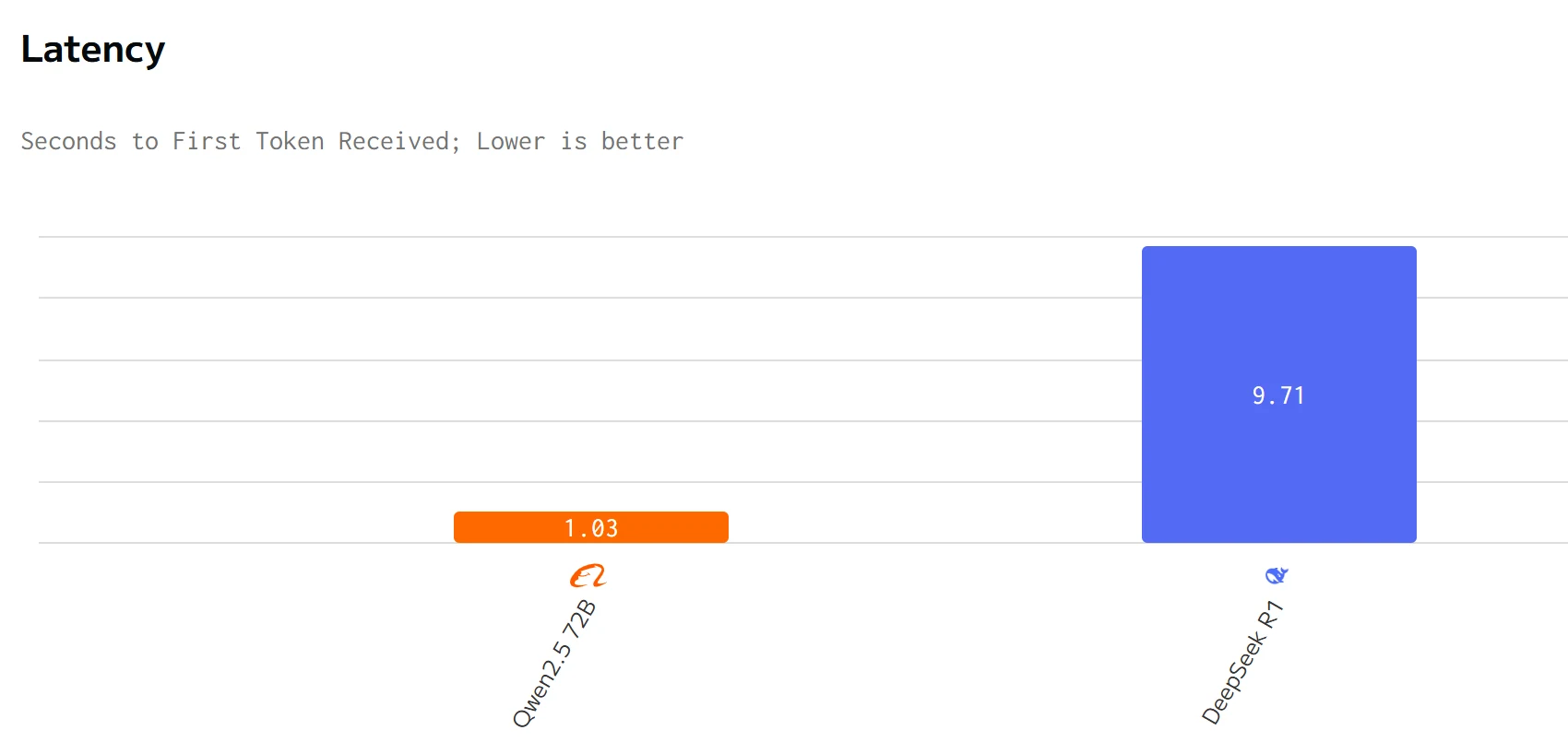
비용 비교
| 모델 | 컨텍스트 | 입력 가격 ($/M 토큰) | 출력 가격 ($/M 토큰) |
|---|---|---|---|
| deepseek/deepseek-r1-turbo | 64000 | $0.7 | $2.5 |
| deepseek/deepseek_r1 | 64000 | $4 | $4 |
| qwen/qwen-2.5-72b-instruct | 32000 | $0.38 | $0.4 |
Qwen 2.5 72B는 출력 속도와 지연 시간에서 DeepSeek R1을 능가합니다. DeepSeek R1의 입력 및 출력 가격은 Qwen 2.5 72B보다 훨씬 높습니다.
벤치마크 비교
이제 각 모델의 기본 특성을 확인했으니 다양한 벤치마크에서의 성능을 자세히 살펴보겠습니다. 이 비교는 각 모델이 서로 다른 영역에서 어떤 강점을 보이는지 이해하는 데 도움이 될 것입니다.
| 벤치마크 | DeepSeek-R1 (%) | Qwen 2.5 72B (%) |
|---|---|---|
| LiveCodeBench (코딩) | 62 | 28 |
| GPQA Diamond | 71 | 49 |
| MATH-500 | 96 | 86 |
| MMLU-Pro | 84 | 72 |
이러한 결과는 DeepSeek R1의 기계 기반 반복 강화 학습 접근 방식이 정밀한 추론과 구조화된 문제 해결 능력이 필요한 특화된 기술 분야에서 더 강력한 역량을 개발하는 데 특히 효과적일 수 있음을 시사합니다.
더 많은 비교를 보려면 다음 글을 확인하세요:
- Deepseek V3 vs Llama 3.3 70b: 언어 작업 vs 코드 및 수학
- DeepSeek R1 vs OpenAI o1: GRPO와 PPO의 독특한 아키텍처
- DeepSeek V3 vs. Qwen 2.5 72B: 정밀성 vs 다국어 효율성
하드웨어 요구 사항
| **모델 ** | ** 파라미터 크기 ** | GPU 구성 |
|---|---|---|
| DeepSeek-R1-Distill-Llama-8B | 4.9B | 모델 샤딩 적용 시 1 x NVIDIA RTX 4090 (24GB VRAM) |
| DeepSeek-R1-Distill-Qwen-14B | 9.0B | 텐서 병렬 처리 적용 시 1 x NVIDIA A100 (40GB VRAM) 또는 2 x RTX 4090 (24GB VRAM) |
| DeepSeek-R1-Distill-Qwen-32B | 32B | 텐서 병렬 처리 적용 시 2 x NVIDIA A100 (40GB VRAM) 또는 1 x NVIDIA H100 (80GB VRAM) 또는 4 x RTX 4090 (24GB VRAM) |
| DeepSeek-R1-Distill-Llama-70B | 70B | 대규모 병렬 처리 적용 시 4 x NVIDIA A100 (40GB VRAM) 또는 2 x NVIDIA H100 (80GB VRAM) 또는 8 x RTX 4090 (24GB VRAM) |
| DeepSeek-R1:671B | 671B (370억 활성 파라미터) | 16 x NVIDIA A100 (40GB VRAM) 또는 8 x NVIDIA H100 (80GB VRAM), InfiniBand가 있는 분산 GPU 클러스터 필요 |
| Qwen 2.5 72B | 72B | 8x RTX4090 또는 4 x A100 또는 2 x H100 |
애플리케이션 및 사용 사례
DeepSeek R1
- 복잡한 추론, 논리적 추론 및 수학적 계산에 최적화됨.
- 강화 학습(RL)을 통해 향상되어 추론 작업의 정확도가 크게 향상됨.
- 코딩 작업, 알고리즘 문제 해결 및 기술 콘텐츠 생성에 매우 효과적.
Qwen 2.5 72B
- 29개 이상의 언어를 능숙하게 지원하는 다국어 애플리케이션에 탁월.
- 최대 128K 토큰의 컨텍스트 윈도우로 일관된 장문 콘텐츠 생성 가능.
- 챗봇 상호작용, 데이터 분석, 요약 및 정보 추출을 포함한 구조화된 데이터 처리 작업에 이상적.
Novita AI를 통한 접근성 및 배포
Novita AI는 개발자가 간단한 API를 사용하여 AI 모델을 쉽게 배포할 수 있도록 하는 AI 클라우드 플랫폼이며, 구축 및 확장을 위한 저렴하고 안정적인 GPU 클라우드를 제공합니다.
1단계: 로그인 및 모델 라이브러리 접속
계정에 로그인하고 Model Library 버튼을 클릭하세요.

2단계: 모델 선택
사용 가능한 옵션을 살펴보고 필요에 맞는 모델을 선택하세요.

3단계: 무료 체험 시작
선택한 모델의 기능을 탐색하려면 무료 체험을 시작하세요.
4단계: API 키 받기
API 인증을 위해 새로운 API 키를 제공해 드립니다. “Settings” 페이지로 이동하여 이미지에 표시된 대로 API 키를 복사할 수 있습니다.

5단계: API 설치
프로그래밍 언어에 맞는 패키지 관리자를 사용하여 API를 설치합니다.

설치 후 개발 환경에 필요한 라이브러리를 가져옵니다. API 키로 클라이언트를 초기화하여 Novita AI LLM과 상호 작용을 시작합니다. 다음은 Python 사용자를 위한 채팅 완성 API 사용 예시입니다.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek_r1"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
가입 시 Novita AI가 $0.5 크레딧을 제공하여 시작을 도와드립니다!
무료 크레딧을 모두 사용한 경우 결제 후 계속 사용할 수 있습니다.
DeepSeek-R1과 Qwen 2.5 72B는 모두 강력한 대규모 언어 모델로, 각각 뚜렷한 장점을 가지고 있습니다. DeepSeek-R1은 복잡한 추론 및 문제 해결 작업에 특화되어 있으며, Qwen 2.5 72B는 다국어 애플리케이션, 광범위한 컨텍스트 처리 및 구조화된 데이터 처리에서 뛰어난 더 넓은 역량을 보여줍니다.
자주 묻는 질문
DeepSeek-R1-Zero의 훈련 방법론에서 독특한 점은 무엇인가요?
DeepSeek-R1-Zero는 LLM의 강력한 추론 능력이 순수하게 강화 학습만으로도 유도될 수 있음을 검증한 최초의 모델 중 하나라는 점에서 독특합니다.
이 모델들은 어디에서 접근하고 사용할 수 있나요?
DeepSeek-R1 및 Qwen2.5 시리즈 모델은 모두 Novita AI에서 매우 비용 효율적인 가격으로 이용할 수 있습니다.
DeepSeek-R1의 맥락에서 “증류(distillation)”란 무엇인가요?
증류는 더 큰 모델(예: DeepSeek-R1)의 추론 능력을 더 작은 모델로 전송하는 과정을 의미합니다.
Novita AI는 AI 야망을 실현하는 올인원 클라우드 플랫폼입니다. 통합 API, 서버리스, GPU 인스턴스 — 비용 효율적인 도구를 제공합니다. 인프라 걱정 없이 무료로 시작하여 AI 비전을 현실로 만드세요.



