

Destaques Principais
DeepSeek R1: Reconhecido por suas habilidades avançadas de raciocínio, desenvolvidas através de aprendizado por reforço (RL) combinado com ajuste fino supervisionado (SFT). Inclui variantes especializadas como DeepSeek-R1-Zero, treinado puramente com RL em larga escala (sem SFT), demonstrando capacidades como autoverificação, raciocínio reflexivo e geração extensiva de cadeia de pensamento.
Qwen 2.5 72B: Excepcional em programação, resolução de problemas matemáticos e tarefas de seguimento de instruções. Gera eficazmente conteúdo longo superior a 8K tokens, processa com precisão dados estruturados (ex.: tabelas) e produz saídas estruturadas em formatos como JSON. Além disso, oferece suporte multilíngue robusto em mais de 29 idiomas.
A Novita AI lança uma versão Turbo com 3x de throughput e um desconto de 20% por tempo limitado! Você pode iniciar uma avaliação gratuita no Novita AI Playground!

Os grandes modelos de linguagem (LLMs) continuam a evoluir rapidamente, com modelos de ponta como DeepSeek-R1 e Qwen 2.5 72B atualmente na vanguarda. Este artigo apresenta uma comparação técnica aprofundada entre DeepSeek-R1 e Qwen 2.5 72B, examinando suas arquiteturas, características de desempenho e casos de uso práticos.
Introdução Básica do Modelo
Para iniciar nossa comparação, primeiro entendemos as características fundamentais de cada modelo.
DeepSeek R1
- Data de Lançamento: 21 de janeiro de 2025
- Escala do Modelo:
- Características Principais:
- Tamanho do Modelo: 671B parâmetros (37B ativos/token)
- Tokenizador: Tokenizador aprimorado com tags de autorreflexão
- Idiomas Suportados: Multilíngue com adaptação cultural
- Multimodal: Apenas texto
- Janela de Contexto: 128K tokens
- Formatos de Armazenamento: Suporte a quantização Q8/Q5
- Arquitetura: Mixture of Experts (MoE) + pipeline de treinamento aprimorado com RL
- Método de Treinamento: Construído sobre a base V3 com pipeline RL (SFT → RL → SFT → RL)
- Dados de Treinamento: Dados base V3 + dados de otimização RL
Qwen 2.5 72B
- Data de Lançamento: 19 de setembro de 2024 (série Qwen 2.5)
- Escala do Modelo:
- Características Principais:
- Tamanho do Modelo: 72B parâmetros
- Idiomas Suportados: forte suporte multilíngue para mais de 29 idiomas
- Multimodal: Apenas texto
- Janela de Contexto: suporte até 128K tokens e pode gerar até 8K tokens
- Arquitetura: Mixture of Experts (MoE) + Multi-Head Latent Attention
- Dados de Treinamento: Treinamento em um conjunto extenso de dados de 18 trilhões de tokens
- Método de Treinamento: pré-treinamento baseado em diferentes dados
A principal diferença entre DeepSeek R1 e Qwen 2.5 72B é a abordagem de treinamento. DeepSeek R1 usa aprendizado por reforço (RL) extensivamente (SFT → RL → SFT → RL), aprimorando as capacidades de raciocínio. Em contraste, Qwen 2.5 72B depende principalmente de ajuste fino supervisionado (SFT) e pré-treinamento extensivo, sem otimização explícita de RL, focando em desempenho multilíngue e de propósito geral.
Comparação de Velocidade
Se você quiser testar por si mesmo, pode iniciar uma avaliação gratuita no site da Novita AI.
Experimente o DeepSeek R1 Turbo, econômico e completo, agora!
Comparação de Velocidade
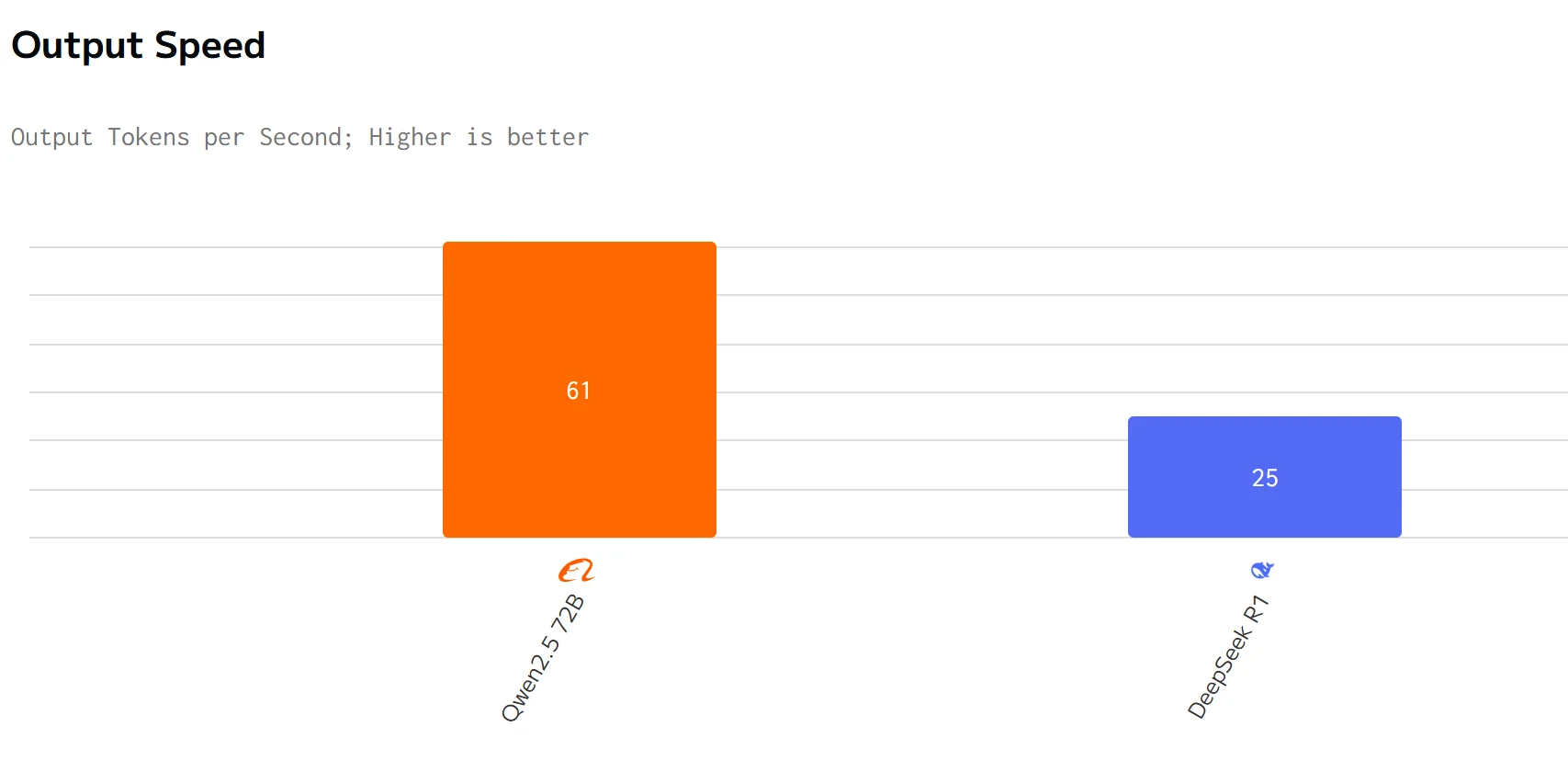
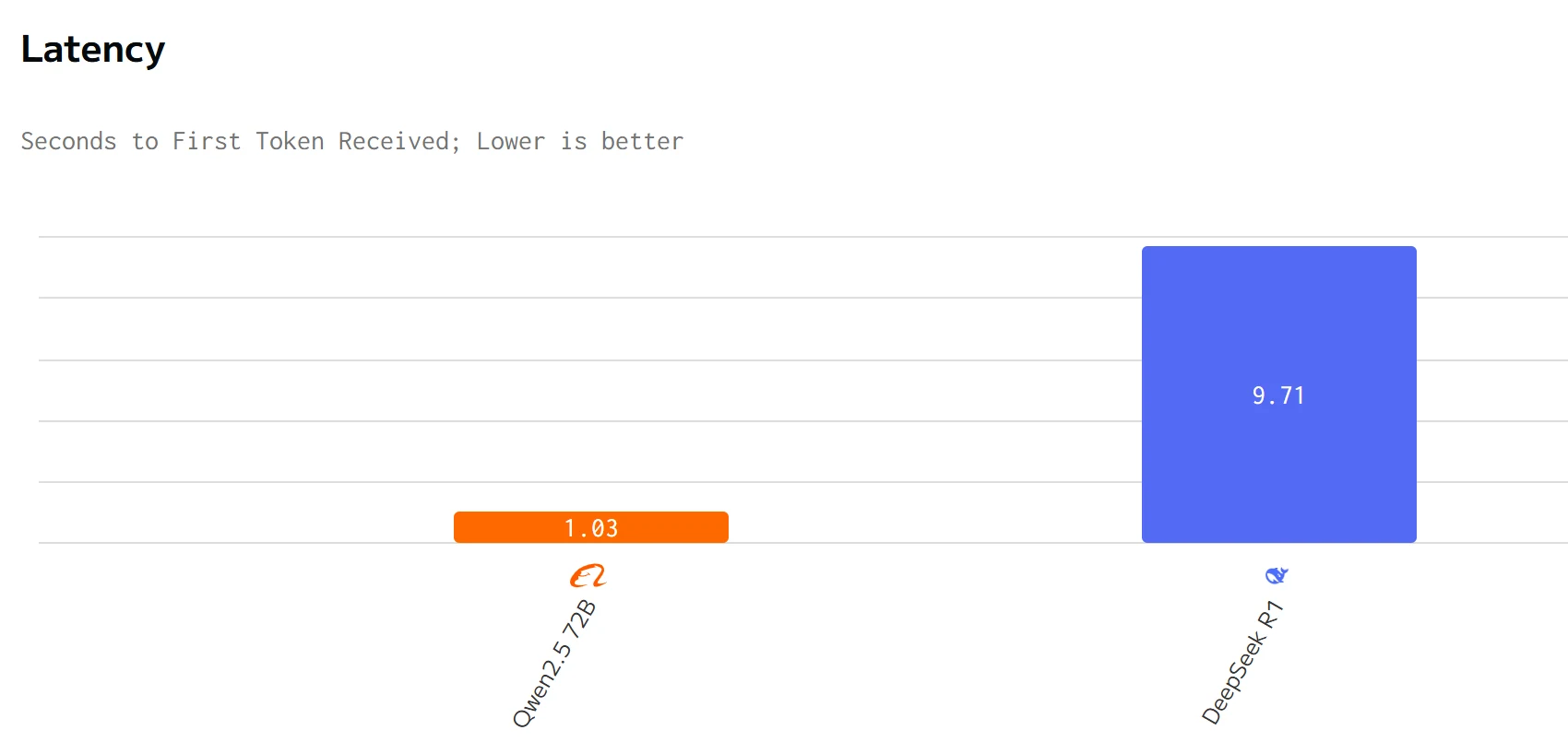
fonte: artificial analysis
Comparação de Custos
| Modelo | Contexto | Preço de Entrada ($/M Tokens) | Preço de Saída ($/M Tokens) |
|---|---|---|---|
| deepseek/deepseek-r1-turbo | 64000 | $0.7 | $2.5 |
| deepseek/deepseek_r1 | 64000 | $4 | $4 |
| qwen/qwen-2.5-72b-instruct | 32000 | $0.38 | $0.4 |
Qwen 2.5 72B supera DeepSeek R1 em velocidade de saída e latência. Os preços de entrada e saída do DeepSeek R1 são significativamente mais altos que os do Qwen 2.5 72B.
Comparação de Benchmarks
Agora que estabelecemos as características básicas de cada modelo, vamos nos aprofundar em seu desempenho em vários benchmarks. Esta comparação ajudará a ilustrar seus pontos fortes em diferentes áreas.
| Benchmark | DeepSeek-R1 (%) | Qwen 2.5 72B (%) |
|---|---|---|
| LiveCodeBench (Codificação) | 62 | 28 |
| GPQA Diamond | 71 | 49 |
| MATH-500 | 96 | 86 |
| MMLU-Pro | 84 | 72 |
Esses resultados sugerem que a abordagem de aprendizado por reforço iterativo orientado por máquina do DeepSeek R1 pode ser particularmente eficaz para desenvolver capacidades mais fortes em domínios técnicos especializados que exigem raciocínio preciso e habilidades estruturadas de resolução de problemas.
Se você quiser ver mais comparações, confira estes artigos:
- Deepseek V3 vs Llama 3.3 70b: Tarefas de Linguagem vs Código e Matemática
- DeepSeek R1 vs OpenAI o1: Arquiteturas Distintas de GRPO e PPO
- DeepSeek V3 vs. Qwen 2.5 72B: Precisão vs Eficiência Multilíngue
Requisitos de Hardware
| Modelo | Tamanho de Parâmetros | Configuração de GPU |
|---|---|---|
| DeepSeek-R1-Distill-Llama-8B | 4.9B | 1 x NVIDIA RTX 4090 (24GB VRAM) com sharding de modelo |
| DeepSeek-R1-Distill-Qwen-14B | 9.0B | 1 x NVIDIA A100 (40GB VRAM) ou 2 x RTX 4090 (24GB VRAM) com paralelismo de tensor |
| DeepSeek-R1-Distill-Qwen-32B | 32B | 2 x NVIDIA A100 (40GB VRAM) ou 1 x NVIDIA H100 (80GB VRAM) ou 4 x RTX 4090 (24GB VRAM) com paralelismo de tensor |
| DeepSeek-R1-Distill-Llama-70B | 70B | 4 x NVIDIA A100 (40GB VRAM) ou 2 x NVIDIA H100 (80GB VRAM) ou 8 x RTX 4090 (24GB VRAM) com paralelismo pesado |
| DeepSeek-R1:671B | 671B (37 bilhões de parâmetros ativos) | 16 x NVIDIA A100 (40GB VRAM) ou 8 x NVIDIA H100 (80GB VRAM), requer um cluster de GPU distribuído com InfiniBand |
| Qwen 2.5 72B | 72B | 8x RTX4090 ou 4 x A100 ou 2 x H100 |
Aplicações e Casos de Uso
DeepSeek R1
- Otimizado para raciocínio complexo, inferência lógica e cálculos matemáticos.
- Aprimorado através de aprendizado por reforço (RL), melhorando significativamente a precisão em tarefas de raciocínio.
- Altamente eficaz para tarefas de codificação, resolução algorítmica de problemas e geração de conteúdo técnico.
Qwen 2.5 72B
- Excelente em aplicações multilíngues, suportando proficientemente mais de 29 idiomas.
- Capaz de gerar conteúdo longo e coerente, com janelas de contexto de até 128K tokens.
- Ideal para tarefas de processamento de dados estruturados, incluindo interações com chatbots, análise de dados, sumarização e extração de informações.
Acessibilidade e Implantação através da Novita AI
A Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer a nuvem GPU acessível e confiável para construir e escalar.
Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login em sua conta e clique no botão Model Library.

Experimente a Demonstração do DeepSeek R1 Agora!
Passo 2: Escolha Seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.

Passo 3: Inicie Sua Avaliação Gratuita
Inicie sua avaliação gratuita para explorar as capacidades do modelo selecionado.
Passo 4: Obtenha Sua Chave de API
Para autenticar com a API, forneceremos a você uma nova chave de API. Acessando a página “Settings”, você pode copiar a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico para sua linguagem de programação.

Após a instalação, importe as bibliotecas necessárias para seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o LLM da Novita AI. Este é um exemplo de uso da API de chat completions para usuários Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek_r1"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Após o registro, a Novita AI fornece um crédito de $0.5 para você começar!
Se os créditos gratuitos acabarem, você pode pagar para continuar usando.
Tanto DeepSeek-R1 quanto Qwen 2.5 72B são modelos de linguagem grandes e poderosos, cada um com vantagens distintas. DeepSeek-R1 é especializado em tarefas complexas de raciocínio e resolução de problemas, enquanto Qwen 2.5 72B demonstra capacidades mais amplas, destacando-se em aplicações multilíngues, manipulação extensiva de contexto e processamento de dados estruturados.
Perguntas Frequentes
O que há de único na metodologia de treinamento do DeepSeek-R1-Zero?
DeepSeek-R1-Zero é único porque é um dos primeiros modelos a validar que fortes capacidades de raciocínio em LLMs podem ser incentivadas puramente através de aprendizado por reforço.
Onde posso acessar e usar esses modelos?
Tanto os modelos da série DeepSeek-R1 quanto Qwen2.5 podem ser acessados via Novita AI a preços muito econômicos.
O que é “destilação” no contexto do DeepSeek-R1?
Destilação refere-se ao processo de transferir as capacidades de raciocínio de um modelo maior (como DeepSeek-R1) para modelos menores.
Novita AI é a plataforma de nuvem All-in-one que capacita suas ambições de IA. APIs integradas, serverless, GPU Instance — as ferramentas econômicas que você precisa. Elimine a infraestrutura, comece gratuitamente e torne sua visão de IA realidade.



