

Key Highlights
DeepSeek R1: Renowned for its advanced reasoning abilities, developed through reinforcement learning (RL) combined with supervised fine-tuning (SFT). It includes specialized variants such as DeepSeek-R1-Zero, trained purely with large-scale RL (without SFT), showcasing capabilities like self-verification, reflective reasoning, and extensive chain-of-thought generation.
Qwen 2.5 72B: Exceptional in programming, mathematical problem-solving, and instruction-following tasks. It effectively generates long-form content exceeding 8K tokens, accurately processes structured data (e.g., tables), and produces structured outputs in formats such as JSON. Additionally, it provides robust multilingual support across more than 29 languages.
Novita AI launches a Turbo version with 3x throughput and a limited-time 20% discount! You can start a free trail on Novita AI Playground!

Large language models (LLMs) continue to evolve rapidly, with cutting-edge models such as DeepSeek-R1 and Qwen 2.5 72B currently at the forefront. This article presents an in-depth technical comparison of DeepSeek-R1 and Qwen 2.5 72B, examining their architectures, performance characteristics, and practical use cases.
Basic Introduction of Model
To begin our comparison, we first understand the fundamental characteristics of each model.
DeepSeek R1
- Release Date: January 21, 2025
- Model Scale:
- Key Features:
- Model Size: 671B parameters (37B active/token)
- Tokenizer: Enhanced tokenizer with self-reflection tags
- Supported Languages: Multilingual with cultural adaptation
- Multimodal: Text-only
- Context Window: 128K tokens
- Storage Formats: Q8/Q5 quantization support
- Architecture: Mixture of Experts (MoE) + RL-enhanced training pipeline
- Training Method: Built on V3 base with RL pipeline (SFT → RL → SFT → RL)
- Training Data: V3 base + RL optimization data
Qwen 2.5 72B
- Release Date: September 19, 2024 (Qwen 2.5 series)
- Model Scale:
- Key Features:
- Model Size: 72B parameters
- Supported Languages: strong multilingual support for over 29 languages
- Multimodal: Text-only
- Context Window: support up to 128K tokens and can generate up to 8K tokens
- Architecture: Mixture of Experts (MoE) + Multi-Head Latent Attention
- Training Data: Training on an extensive dataset of 18 trillion tokens
- Training Method: according to different data to pretraining
The main difference between DeepSeek R1 and Qwen 2.5 72B is their training approach. DeepSeek R1 uses reinforcement learning (RL) extensively (SFT → RL → SFT → RL), enhancing reasoning capabilities. In contrast, Qwen 2.5 72B relies primarily on supervised fine-tuning (SFT) and extensive pretraining, without explicit RL optimization, focusing on multilingual and general-purpose performance.
Speed Comparison
If you want to test it yourself, you can start a free trial on the Novita AI website.
Try cost effective but full size DeepSeek R1 Turbo Now!
Speed Comparison
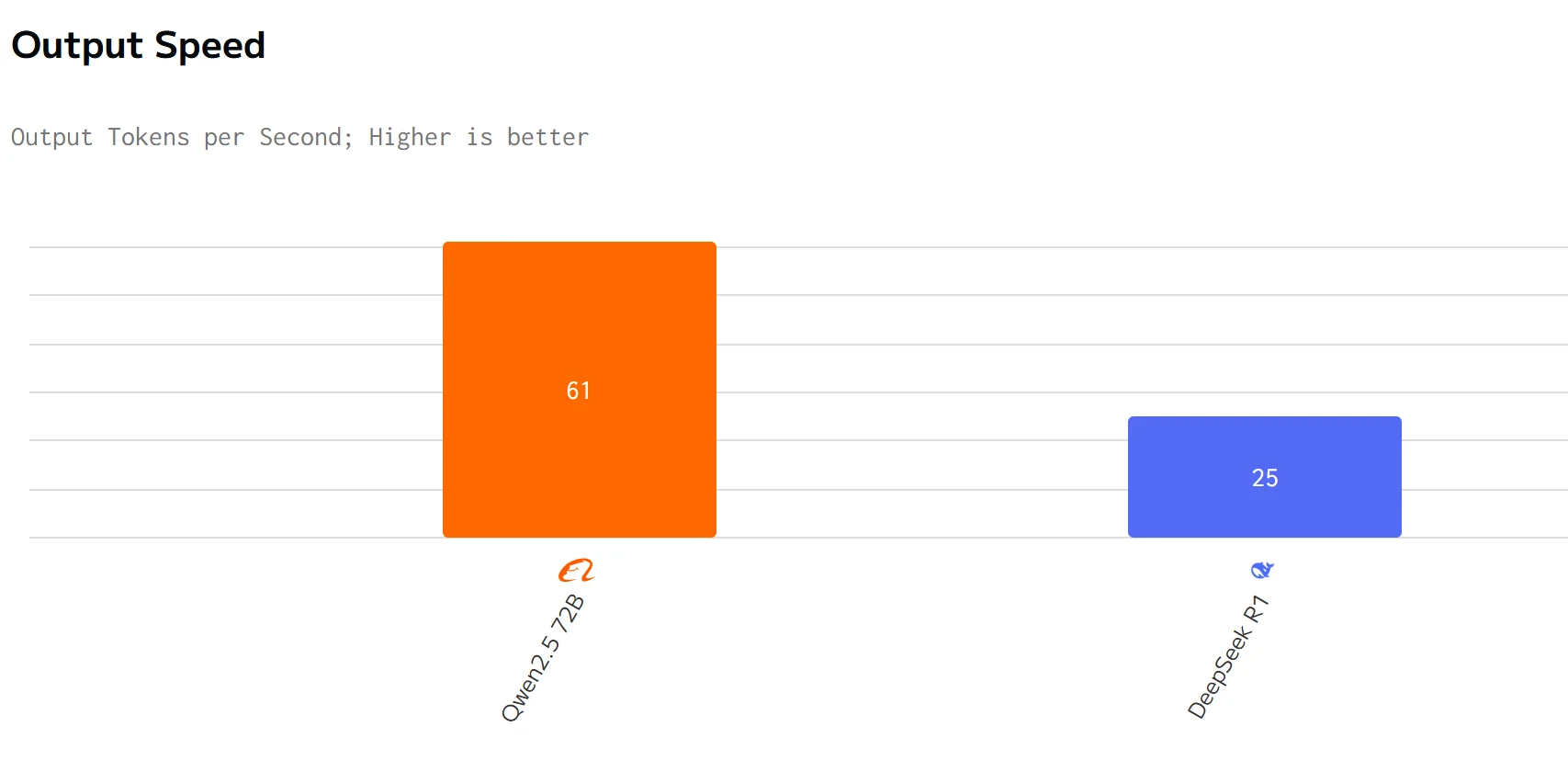
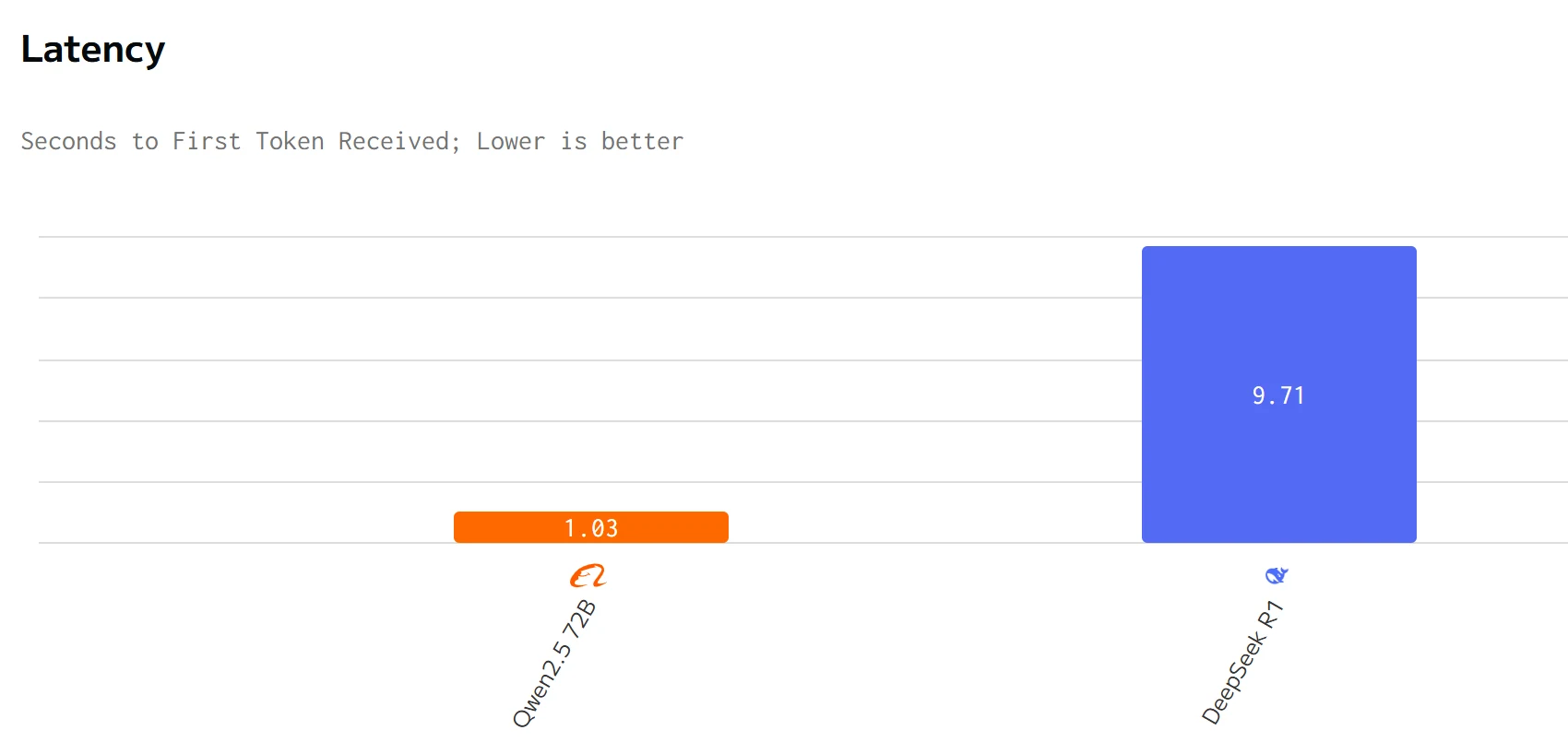
from artificial analysis
Cost Comparison
| Model | Context | Input Price ($/M Tokens) | Output Price ($/M Tokens) |
|---|---|---|---|
| deepseek/deepseek-r1-turbo | 64000 | $0.7 | $2.5 |
| deepseek/deepseek_r1 | 64000 | $4 | $4 |
| qwen/qwen-2.5-72b-instruct | 32000 | $0.38 | $0.4 |
Qwen 2.5 72B surpasses DeepSeek R1 in output speed and latency. The input and output prices of DeepSeek R1 are significantly higher than those of Qwen 2.5 72B .
Benchmark Comparison
Now that we’ve established the basic characteristics of each model, let’s delve into their performance across various benchmarks. This comparison will help illustrate their strengths in different areas.
| Benchmark | DeepSeek-R1 (%) | Qwen 2.5 72B (%) |
|---|---|---|
| LiveCodeBench (Coding) | 62 | 28 |
| GPQA Diamond | 71 | 49 |
| MATH-500 | 96 | 86 |
| MMLU-Pro | 84 | 72 |
These results suggest that DeepSeek R1’s machine-driven iterative reinforcement learning approach may be particularly effective for developing stronger capabilities in specialized technical domains requiring precise reasoning and structured problem-solving skills.
If you want to see more comparisons, you can check out these articles:
- Deepseek V3 vs Llama 3.3 70b: Language Tasks vs Code & Math
- DeepSeek R1 vs OpenAI o1: Distinct Architectures of GRPO and PPO
- DeepSeek V3 vs. Qwen 2.5 72B: Precision vs. Multilingual Efficiency
Hardware Requiremments
| Model | Parameter Size | GPU Configuration |
|---|---|---|
| DeepSeek-R1-Distill-Llama-8B | 4.9B | 1 x NVIDIA RTX 4090 (24GB VRAM) with model sharding |
| DeepSeek-R1-Distill-Qwen-14B | 9.0B | 1 x NVIDIA A100 (40GB VRAM) or 2 x RTX 4090 (24GB VRAM) with tensor parallelism |
| DeepSeek-R1-Distill-Qwen-32B | 32B | 2 x NVIDIA A100 (40GB VRAM) or 1 x NVIDIA H100 (80GB VRAM) or 4 x RTX 4090 (24GB VRAM) with tensor parallelism |
| DeepSeek-R1-Distill-Llama-70B | 70B | 4 x NVIDIA A100 (40GB VRAM) or 2 x NVIDIA H100 (80GB VRAM) or 8 x RTX 4090 (24GB VRAM) with heavy parallelism |
| DeepSeek-R1:671B | 671B (37 billion active parameters) | 16 x NVIDIA A100 (40GB VRAM) or 8 x NVIDIA H100 (80GB VRAM), requires a distributed GPU cluster with InfiniBand |
| Qwen 2.5 72B | 72B | 8x RTX4090 or 4 x A100 or 2 x H100 |
Applications and Use Cases
DeepSeek R1
- Optimized for complex reasoning, logical inference, and mathematical computations.
- Enhanced through reinforcement learning (RL), significantly improving accuracy in reasoning tasks.
- Highly effective for coding tasks, algorithmic problem-solving, and technical content generation.
Qwen 2.5 72B
- Excels in multilingual applications, proficiently supporting over 29 languages.
- Capable of generating coherent long-form content, with context windows up to 128K tokens.
- Ideal for structured data processing tasks, including chatbot interactions, data analysis, summarization, and information extraction.
Accessibility and Deployment through Novita AI
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.

Step 2: Choose Your Model
Browse through the available options and select the model that suits your needs.

Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.
Step 4: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.

Step 5: Install the API
Install API using the package manager specific to your programming language.

After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for python users.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek_r1"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Upon registration, Novita AI provides a $0.5 credit to get you started!
If the free credits is used up, you can pay to continue using it.
Both DeepSeek-R1 and Qwen 2.5 72B are powerful large language models, each with distinct advantages. DeepSeek-R1 specializes in complex reasoning and problem-solving tasks, while Qwen 2.5 72B demonstrates broader capabilities, excelling in multilingual applications, extensive context handling, and structured data processing.
Frequently Asked Questions
What is unique about DeepSeek-R1-Zero’s training methodology?
DeepSeek-R1-Zero is unique because it is one of the first models to validate that strong reasoning capabilities in LLMs can be incentivized purely through reinforcement learning
Where can I access and use these models?
Both DeepSeek-R1 and Qwen2.5 series models can be accessed via Novita AI in very cost-effective price
What is “distillation” in the context of DeepSeek-R1?
Yes, Llama 3.3 is specifically engineered to operate efficiently on widely available GPUs and developer-grade hardware configurations, enhancing accessibility for a broader range of simple Distillation refers to the process of transferring the reasoning capabilities of a larger model (like DeepSeek-R1) into smaller models.
Novita AI is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance — the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.



