

关键亮点
DeepSeek R1: 以其先进的推理能力闻名,通过强化学习(RL)结合监督微调(SFT)开发而成。包含专门的变体如 DeepSeek-R1-Zero,仅使用大规模 RL 训练(无 SFT),展示了自我验证、反思式推理以及广泛的思维链生成能力。
Qwen 2.5 72B: 在编程、数学问题求解和指令遵循任务方面表现卓越。能高效生成超过 8K token 的长文本,准确处理结构化数据(如表格),并生成 JSON 等格式的结构化输出。此外,它还支持超过 29 种语言的多语言能力。
Novita AI 推出吞吐量提升 3 倍的 Turbo 版本,限时 20% 折扣!你可以立即在 Novita AI Playground 上免费试用!

大型语言模型(LLM)快速发展,像 DeepSeek-R1 和 Qwen 2.5 72B 这样的前沿模型目前处于领先地位。本文对 DeepSeek-R1 和 Qwen 2.5 72B 进行深入的技术对比,分析它们的架构、性能特点以及实际应用场景。
模型基本介绍
首先,我们了解每个模型的基本特征。
DeepSeek R1
- 发布时间:2025 年 1 月 21 日
- 模型规模:
- 关键特性:
- 模型规模:671B 参数(37B 活跃/每个 token)
- 分词器:带自我反思标签的增强型分词器
- 支持语言:多语言且具有文化适应能力
- 多模态:仅文本
- 上下文窗口:128K tokens
- 存储格式:支持 Q8/Q5 量化
- 架构:混合专家(MoE)+ RL 增强训练流水线
- 训练方法:基于 V3 基座,采用 RL 流水线(SFT → RL → SFT → RL)
- 训练数据:V3 基座数据 + RL 优化数据
Qwen 2.5 72B
- 发布时间:2024 年 9 月 19 日(Qwen 2.5 系列)
- 模型规模:
- 关键特性:
- 模型规模:72B 参数
- 支持语言:强大的多语言支持,涵盖超过 29 种语言
- 多模态:仅文本
- **上下文窗口 **:支持高达 128K tokens,可生成长达 8K tokens
- 架构:混合专家(MoE)+ 多头潜在注意力
- 训练数据:基于 18 万亿 token 的大规模数据集训练
- 训练方法:根据不同数据进行预训练
DeepSeek R1 与 Qwen 2.5 72B 的主要区别在于训练方法。DeepSeek R1 广泛使用强化学习(RL)(SFT → RL → SFT → RL),增强了推理能力。而 Qwen 2.5 72B 主要依赖监督微调(SFT)和大规模预训练,没有明确的 RL 优化,侧重于多语言和通用性能。
速度对比
如果你想亲自测试,可以在 Novita AI 网站上免费试用。
立即尝试高性价比、完整规模的 DeepSeek R1 Turbo!
速度对比
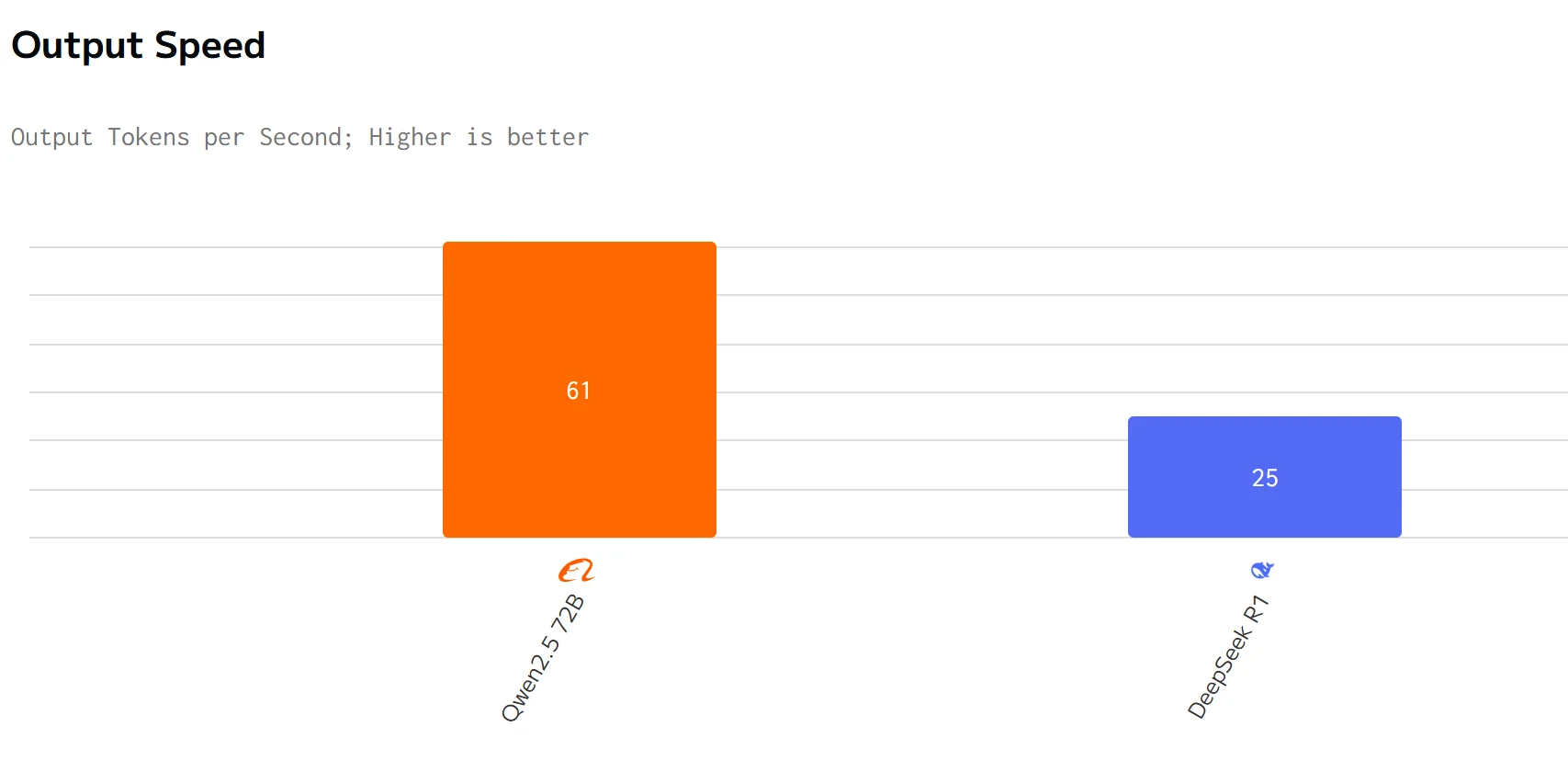
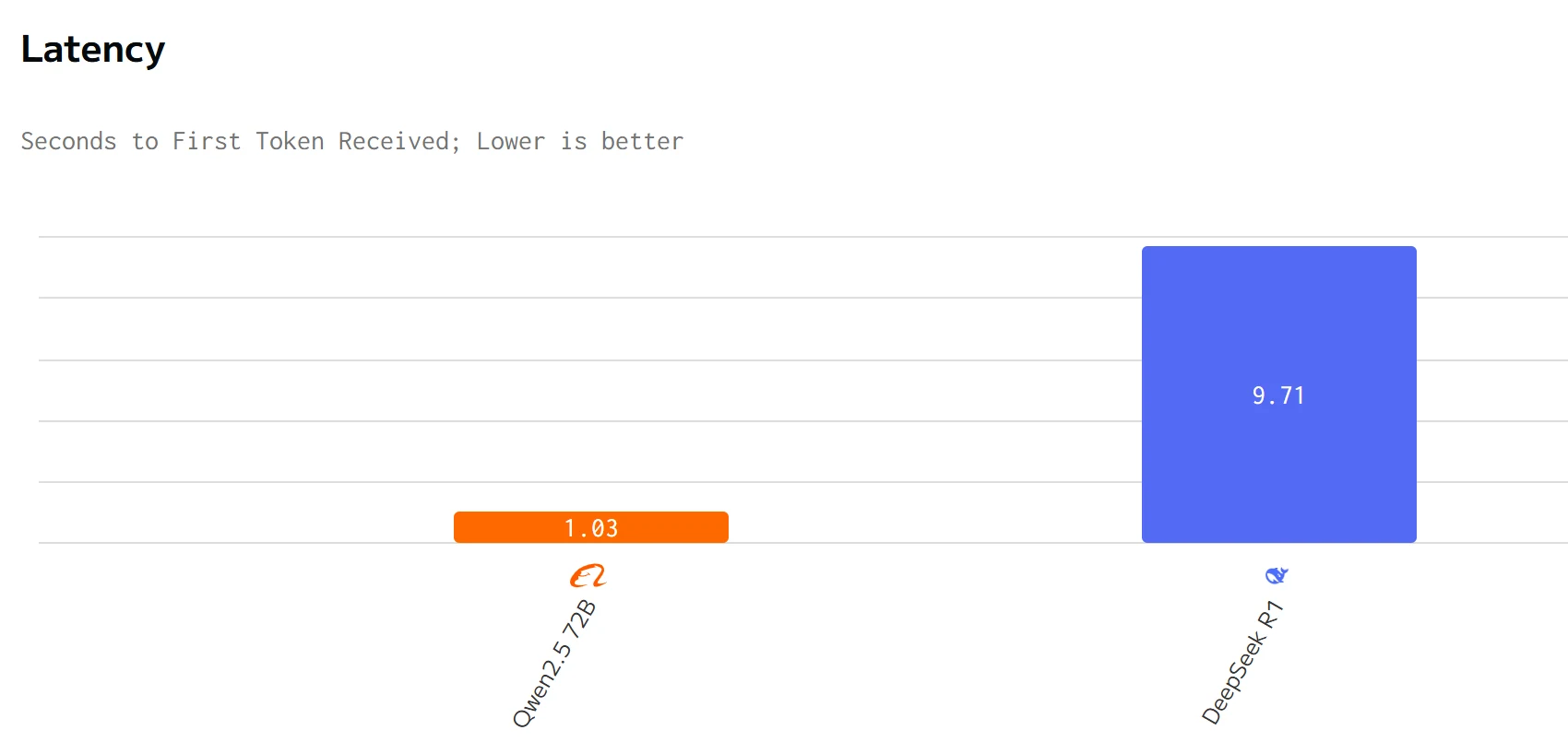
数据来自 artificial analysis
成本对比
| 模型 | 上下文 | 输入价格($/M Tokens) | 输出价格($/M Tokens) |
|---|---|---|---|
| deepseek/deepseek-r1-turbo | 64000 | $0.7 | $2.5 |
| deepseek/deepseek_r1 | 64000 | $4 | $4 |
| qwen/qwen-2.5-72b-instruct | 32000 | $0.38 | $0.4 |
Qwen 2.5 72B 在输出速度和延迟方面优于 DeepSeek R1。DeepSeek R1 的输入和输出价格显著高于 Qwen 2.5 72B。
基准测试对比
在了解了每个模型的基本特性之后,我们来深入看看它们在不同基准测试中的表现。这个对比将有助于说明它们在不同领域的优势。
| 基准测试 | DeepSeek-R1 (%) | Qwen 2.5 72B (%) |
|---|---|---|
| LiveCodeBench(编程) | 62 | 28 |
| GPQA Diamond | 71 | 49 |
| MATH-500 | 96 | 86 |
| MMLU-Pro | 84 | 72 |
这些结果表明,DeepSeek R1 基于机器驱动的迭代强化学习方法在开发需要精确推理和结构化问题解决能力的专业领域可能尤为有效。
如果你想看到更多对比,可以查阅以下文章:
- Deepseek V3 vs Llama 3.3 70b:语言任务 vs 代码与数学
- DeepSeek R1 vs OpenAI o1:GRPO 与 PPO 的不同架构
- DeepSeek V3 vs. Qwen 2.5 72B:精度 vs 多语言效率
硬件需求
| **模型 ** | ** 参数规模 ** | GPU 配置 |
|---|---|---|
| DeepSeek-R1-Distill-Llama-8B | 4.9B | 1 x NVIDIA RTX 4090(24GB VRAM),使用模型分片 |
| DeepSeek-R1-Distill-Qwen-14B | 9.0B | 1 x NVIDIA A100(40GB VRAM)或 2 x RTX 4090(24GB VRAM),使用张量并行 |
| DeepSeek-R1-Distill-Qwen-32B | 32B | 2 x NVIDIA A100(40GB VRAM)或 1 x NVIDIA H100(80GB VRAM)或 4 x RTX 4090(24GB VRAM),使用张量并行 |
| DeepSeek-R1-Distill-Llama-70B | 70B | 4 x NVIDIA A100(40GB VRAM)或 2 x NVIDIA H100(80GB VRAM)或 8 x RTX 4090(24GB VRAM),使用高度并行 |
| DeepSeek-R1:671B | 671B(370亿活跃参数) | 16 x NVIDIA A100(40GB VRAM)或 8 x NVIDIA H100(80GB VRAM),需要配备 InfiniBand 的分布式 GPU 集群 |
| Qwen 2.5 72B | 72B | 8x RTX4090 或 4 x A100 或 2 x H100 |
应用与使用场景
DeepSeek R1
- 针对复杂推理、逻辑推断和数学计算进行了优化。
- 通过强化学习(RL)增强,显著提高了推理任务的准确性。
- 在编程任务、算法问题解决和技术内容生成方面非常高效。
Qwen 2.5 72B
- 在多语言应用中表现出色,熟练支持超过 29 种语言。
- 能够生成长篇连贯内容,上下文窗口高达 128K tokens。
- 非常适合结构化数据处理任务,包括聊天机器人交互、数据分析、摘要和信息提取。
通过 Novita AI 进行访问与部署
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 轻松部署 AI 模型的方法,同时也提供经济实惠且可靠的 GPU 云来构建和扩展。
步骤 1:登录并访问模型库
登录你的账户,然后点击 Model Library 按钮。

步骤 2:选择你的模型
浏览可用的选项,选择适合你需求的模型。

步骤 3:开始免费试用
开始免费试用,探索所选模型的能力。
步骤 4:获取你的 API 密钥
为了验证 API 调用,我们将为你提供一个全新的 API 密钥。进入 Settings 页面,可以像图中所示复制 API 密钥。

步骤 5:安装 API
使用适合你编程语言的包管理器安装 API。

安装完成后,将必要的库导入到你的开发环境中。用你的 API 密钥初始化客户端,开始与 Novita AI LLM 交互。以下是 Python 用户使用聊天补全 API 的示例。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek_r1"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
注册后,Novita AI 会提供 $0.5 的免费额度,助你快速上手!
如果免费额度用完,你可以付费继续使用。
DeepSeek-R1 和 Qwen 2.5 72B 都是强大的大型语言模型,各有优势。DeepSeek-R1 专注于复杂推理和问题解决任务,而 Qwen 2.5 72B 表现出更广泛的能力,在多语言应用、长上下文处理和结构化数据处理方面表现出色。
常见问题
DeepSeek-R1-Zero 的训练方法有何独特之处?
DeepSeek-R1-Zero 的独特之处在于它是最早验证了仅通过强化学习即可激发 LLM 强大推理能力的模型之一。
我可以在哪里访问和使用这些模型?
DeepSeek-R1 和 Qwen2.5 系列模型都可以通过 Novita AI 以非常经济的价格访问。
在 DeepSeek-R1 的上下文中,“蒸馏”指的是什么?
不,Llama 3.3 是专门设计用于在广泛可用的 GPU 和开发者级硬件配置上高效运行,从而提升更多简单场景的可访问性。蒸馏指的是将较大模型(如 DeepSeek-R1)的推理能力迁移到较小模型的过程。
Novita AI 是一个一体化云平台,助力你的 AI 抱负。集成 API、无服务器、GPU 实例——你所需的经济高效工具。无需管理基础设施,免费开始,让你的 AI 愿景变为现实。



