

النقاط البارزة
DeepSeek R1: يشتهر بقدراته المتقدمة في الاستدلال، التي تم تطويرها من خلال التعلم المعزز (RL) مع الضبط الدقيق الخاضع للإشراف (SFT). يتضمن متغيرات متخصصة مثل DeepSeek-R1-Zero، المدرب بشكل نقي باستخدام التعلم المعزز على نطاق واسع (بدون SFT)، مما يظهر قدرات مثل التحقق الذاتي، والاستدلال التأملي، وتوليد سلاسل الفكر الطويلة.
Qwen 2.5 72B: استثنائي في البرمجة، وحل المشكلات الرياضية، ومهام اتباع التعليمات. يقوم بشكل فعال بتوليد محتوى طويل يتجاوز 8 آلاف رمز، ومعالجة البيانات المنظمة بدقة (مثل الجداول)، وإنتاج مخرجات منظمة بتنسيقات مثل JSON. بالإضافة إلى ذلك، يوفر دعمًا قويًا متعدد اللغات لأكثر من 29 لغة.
تطلق Novita AI إصدار Turbo مع إنتاجية أعلى بـ 3 مرات وخصم 20% لفترة محدودة! يمكنك بدء تجربة مجانية على Novita AI Playground!

تستمر نماذج اللغة الكبيرة (LLMs) في التطور بسرعة، مع نماذج متطورة مثل DeepSeek-R1 و Qwen 2.5 72B في الطليعة حالياً. تقدم هذه المقالة مقارنة تقنية متعمقة بين DeepSeek-R1 و Qwen 2.5 72B، مع فحص بنياتها وخصائص أدائها وحالات الاستخدام العملية.
مقدمة أساسية للنموذج
لبدء المقارنة، نفهم أولاً الخصائص الأساسية لكل نموذج.
DeepSeek R1
- تاريخ الإصدار: 21 يناير 2025
- حجم النموذج:
- الميزات الرئيسية:
- حجم النموذج: 671 مليار معلمة (37 مليار نشطة لكل رمز)
- المحلل اللغوي (Tokenizer): محلل محسّن مع وسوم تأمل ذاتي
- اللغات المدعومة: متعدد اللغات مع تكيف ثقافي
- متعدد الوسائط: نص فقط
- نافذة السياق: 128 ألف رمز
- تنسيقات التخزين: دعم تكميم Q8/Q5
- الهندسة المعمارية: خليط من الخبراء (MoE) + خط أنابيب تدريب معزز بالتعلم المعزز
- طريقة التدريب: مبني على قاعدة V3 مع خط أنابيب التعلم المعزز (SFT ← RL ← SFT ← RL)
- بيانات التدريب: قاعدة V3 + بيانات تحسين التعلم المعزز
Qwen 2.5 72B
- تاريخ الإصدار: 19 سبتمبر 2024 (سلسلة Qwen 2.5)
- حجم النموذج:
- الميزات الرئيسية:
- حجم النموذج: 72 مليار معلمة
- اللغات المدعومة: دعم قوي متعدد اللغات لأكثر من 29 لغة
- متعدد الوسائط: نص فقط
- نافذة السياق: يدعم حتى 128 ألف رمز ويمكنه توليد حتى 8 آلاف رمز
- الهندسة المعمارية: خليط من الخبراء (MoE) + انتباه الرأس الكامن المتعدد
- بيانات التدريب: تدريب على مجموعة بيانات ضخمة مكونة من 18 تريليون رمز
- طريقة التدريب: التدريب المسبق وفقًا لبيانات مختلفة
الفرق الرئيسي بين DeepSeek R1 و Qwen 2.5 72B هو نهج التدريب. يستخدم DeepSeek R1 التعلم المعزز (RL) على نطاق واسع (SFT ← RL ← SFT ← RL)، مما يعزز قدرات الاستدلال. في المقابل، يعتمد Qwen 2.5 72B بشكل أساسي على الضبط الدقيق الخاضع للإشراف (SFT) والتدريب المسبق المكثف، دون تحسين صريح للتعلم المعزز، مع التركيز على الأداء متعدد اللغات والأغراض العامة.
مقارنة السرعة
إذا كنت ترغب في اختبار ذلك بنفسك، يمكنك بدء تجربة مجانية على موقع Novita AI.
جرب DeepSeek R1 Turbo الفعال من حيث التكلفة والكامل الحجم الآن!
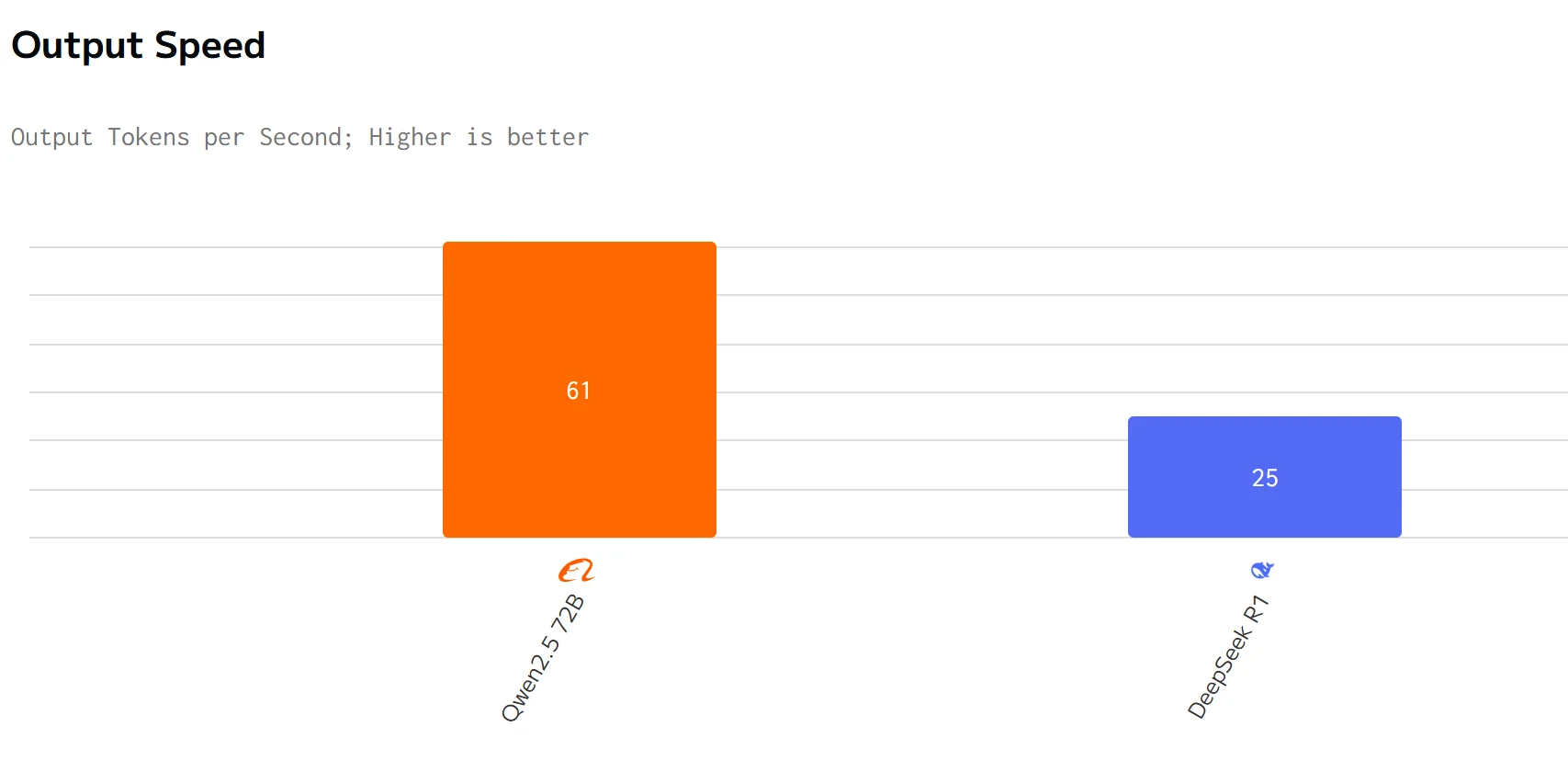
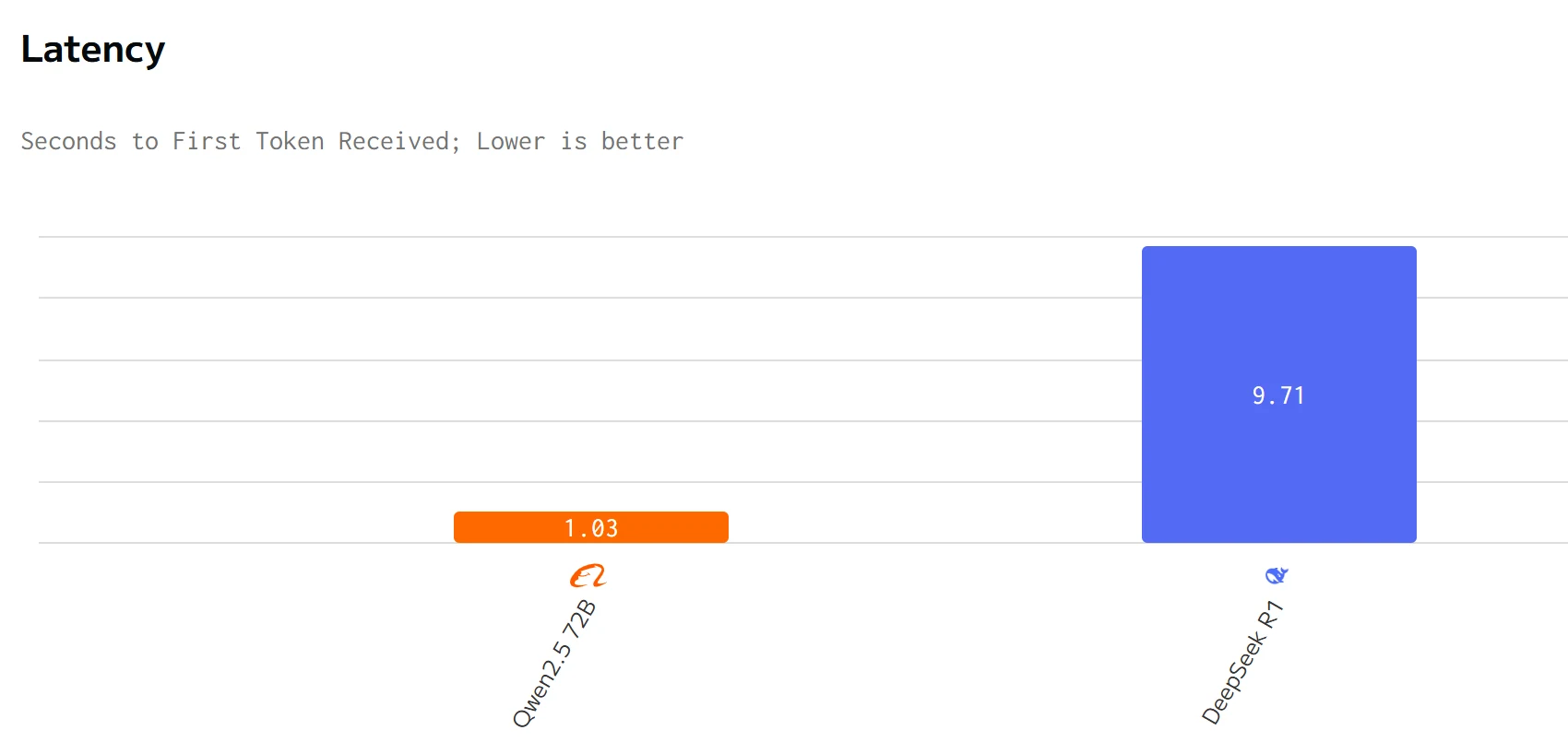
مقارنة السرعة
مقارنة التكلفة
| النموذج | السياق | سعر الإدخال ($/مليون رمز) | سعر الإخراج ($/مليون رمز) |
|---|---|---|---|
| deepseek/deepseek-r1-turbo | 64000 | $0.7 | $2.5 |
| deepseek/deepseek_r1 | 64000 | $4 | $4 |
| qwen/qwen-2.5-72b-instruct | 32000 | $0.38 | $0.4 |
يتفوق Qwen 2.5 72B على DeepSeek R1 في سرعة الإخراج وزمن الاستجابة. أسعار الإدخال والإخراج لـ DeepSeek R1 أعلى بكثير من أسعار Qwen 2.5 72B.
مقارنة المعايير
الآن بعد أن حددنا الخصائص الأساسية لكل نموذج، دعنا نتعمق في أدائهم عبر مختلف المعايير. ستساعد هذه المقارنة في توضيح نقاط قوتهم في المجالات المختلفة.
| المعيار | DeepSeek-R1 (%) | Qwen 2.5 72B (%) |
|---|---|---|
| LiveCodeBench (البرمجة) | 62 | 28 |
| GPQA Diamond | 71 | 49 |
| MATH-500 | 96 | 86 |
| MMLU-Pro | 84 | 72 |
تشير هذه النتائج إلى أن نهج التعلم المعزز التكراري القائم على الآلة لـ DeepSeek R1 قد يكون فعالاً بشكل خاص لتطوير قدرات أقوى في المجالات التقنية المتخصصة التي تتطلب استدلالاً دقيقاً ومهارات حل مشكلات منظمة.
إذا كنت ترغب في رؤية المزيد من المقارنات، يمكنك الاطلاع على هذه المقالات:
- Deepseek V3 مقابل Llama 3.3 70b: المهام اللغوية مقابل البرمجة والرياضيات
- DeepSeek R1 مقابل OpenAI o1: بنيات مختلفة لـ GRPO و PPO
- DeepSeek V3 مقابل Qwen 2.5 72B: الدقة مقابل الكفاءة متعددة اللغات
متطلبات الأجهزة
| النموذج | حجم المعلمات | تكوين GPU |
|---|---|---|
| DeepSeek-R1-Distill-Llama-8B | 4.9 مليار | 1 × NVIDIA RTX 4090 (24GB VRAM) مع تجزئة النموذج |
| DeepSeek-R1-Distill-Qwen-14B | 9.0 مليار | 1 × NVIDIA A100 (40GB VRAM) أو 2 × RTX 4090 (24GB VRAM) مع توازي الموتر |
| DeepSeek-R1-Distill-Qwen-32B | 32 مليار | 2 × NVIDIA A100 (40GB VRAM) أو 1 × NVIDIA H100 (80GB VRAM) أو 4 × RTX 4090 (24GB VRAM) مع توازي الموتر |
| DeepSeek-R1-Distill-Llama-70B | 70 مليار | 4 × NVIDIA A100 (40GB VRAM) أو 2 × NVIDIA H100 (80GB VRAM) أو 8 × RTX 4090 (24GB VRAM) مع توازي ثقيل |
| DeepSeek-R1:671B | 671 مليار (37 مليار معلمة نشطة) | 16 × NVIDIA A100 (40GB VRAM) أو 8 × NVIDIA H100 (80GB VRAM)، يتطلب مجموعة GPU موزعة مع InfiniBand |
| Qwen 2.5 72B | 72 مليار | 8x RTX4090 أو 4 × A100 أو 2 × H100 |
التطبيقات وحالات الاستخدام
DeepSeek R1
- محسّن للاستدلال المعقد، والاستدلال المنطقي، والحسابات الرياضية.
- معزز من خلال التعلم المعزز (RL)، مما يحسن بشكل كبير الدقة في مهام الاستدلال.
- فعال للغاية في مهام البرمجة، وحل المشكلات الخوارزمية، وتوليد المحتوى التقني.
Qwen 2.5 72B
- يتفوق في التطبيقات متعددة اللغات، ويدعم بكفاءة أكثر من 29 لغة.
- قادر على توليد محتوى طويل متماسك، مع نوافذ سياق تصل إلى 128 ألف رمز.
- مثالي لمهام معالجة البيانات المنظمة، بما في ذلك التفاعلات مع الروبوتات الدردشة، وتحليل البيانات، والتلخيص، واستخراج المعلومات.
سهولة الوصول والنشر عبر Novita AI
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة التطبيقات البسيطة لدينا، مع توفير سحابة GPU موثوقة وبأسعار معقولة للبناء والتوسع.
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج
قم بتسجيل الدخول إلى حسابك وانقر على زر مكتبة النماذج.

جرب DeepSeek R1 التجريبي الآن!
الخطوة 2: اختر نموذجك
تصفح الخيارات المتاحة واختر النموذج الذي يناسب احتياجاتك.

الخطوة 3: ابدأ تجربتك المجانية
ابدأ تجربتك المجانية لاستكشاف إمكانيات النموذج المحدد.
الخطوة 4: احصل على مفتاح API الخاص بك
للمصادقة مع API، سنزودك بمفتاح API جديد. بالدخول إلى صفحة “الإعدادات”، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

الخطوة 5: تثبيت API
قم بتثبيت API باستخدام مدير الحزم الخاص بلغة البرمجة التي تستخدمها.

بعد التثبيت، قم باستيراد المكتبات الضرورية إلى بيئة التطوير الخاصة بك. قم بتهيئة API باستخدام مفتاح API الخاص بك لبدء التفاعل مع Novita AI LLM. هذا مثال لاستخدام API إكمال الدردشة لمستخدمي Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "deepseek/deepseek_r1"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
عند التسجيل، تقدم Novita AI رصيدًا بقيمة $0.5 لتبدأ!
إذا تم استخدام الرصيد المجاني، يمكنك الدفع لمواصلة الاستخدام.
كلا من DeepSeek-R1 و Qwen 2.5 72B هما نموذجان قويان للغة كبيرة، لكل منهما مزايا مميزة. يتخصص DeepSeek-R1 في مهام الاستدلال المعقدة وحل المشكلات، بينما يُظهر Qwen 2.5 72B قدرات أوسع، متفوقاً في التطبيقات متعددة اللغات، ومعالجة السياق الواسعة، ومعالجة البيانات المنظمة.
الأسئلة الشائعة
ما هو الشيء الفريد في منهجية تدريب DeepSeek-R1-Zero؟
DeepSeek-R1-Zero فريد من نوعه لأنه من أوائل النماذج التي تؤكد أنه يمكن تحفيز قدرات الاستدلال القوية في نماذج اللغة الكبيرة بشكل نقي من خلال التعلم المعزز.
أين يمكنني الوصول إلى هذه النماذج واستخدامها؟
يمكن الوصول إلى كل من نماذج سلسلة DeepSeek-R1 و Qwen2.5 عبر Novita AI بأسعار فعالة من حيث التكلفة.
ما هو “التقطير” في سياق DeepSeek-R1؟
نعم، Llama 3.3 مصمم هندسياً للعمل بكفاءة على وحدات GPU المتاحة على نطاق واسع وتكوينات الأجهزة على مستوى المطورين، مما يعزز الوصول لمجموعة أوسع من المهام البسيطة. يشير التقطير إلى عملية نقل قدرات الاستدلال من نموذج أكبر (مثل DeepSeek-R1) إلى نماذج أصغر.
Novita AI هي المنصة السحابية الشاملة التي تعزز طموحاتك في الذكاء الاصطناعي. واجهات API متكاملة، بدون خادم، مثيلات GPU — الأدوات الفعالة من حيث التكلفة التي تحتاجها. تخلص من البنية التحتية، ابدأ مجاناً، وحقق رؤيتك في الذكاء الاصطناعي.



