

DeepSeek R2가 곧 출시됩니다. 하지만 이미 여기 있는 것으로 선도할 수 있는데 왜 기다리시나요?
모두가 DeepSeek R2를 기다리는 동안, 똑똑한 개발자들은 이미 Novita AI에서 DeepSeek의 현재 강력한 모델로 앞서 나가고 있습니다.
신규 사용자는 $10 무료 크레딧을 받고, 친구를 추천하면 총 최대 $500의 LLM API 보상을 받을 수 있습니다!
현재 DeepSeek 라인업:
- DeepSeek V3 0324: $0.33 / M 입력, $1.3 / M 출력 (128K 컨텍스트)
- DeepSeek R1 Turbo: $0.7 / M 입력, $2.5 / M 출력 (64K 컨텍스트)
- DeepSeek V3 Turbo: $0.4 / M 입력, $1.3 / M 출력 (64K 컨텍스트)
내일의 모델을 기다리지 마세요. 지금 API 호출 한 번으로 게임 체인저 AI를 배포하세요.
Deepseek V3, R1, V3 0324: Same Architecture
| **카테고리 ** | ** 세부 정보** |
|---|---|
| Model Size | 671B 파라미터 (토큰당 37B 활성) |
| Architecture | Mixture of Experts (MoE) |
| Open Source | 예 (모든 버전) |
| Language Support | 다국어 — 영어와 중국어에서 뛰어남 |
| Multimodal | 텍스트 간 전용 |
| Context Window | 128K 토큰 |
| Versions | - DeepSeek R1: Jan 21, 2025 - DeepSeek V3 0324: Mar 24, 2025 - DeepSeek V3: Dec 16.2024 |
Deepseek V3, R1, 0324 — The Real Difference Is Training
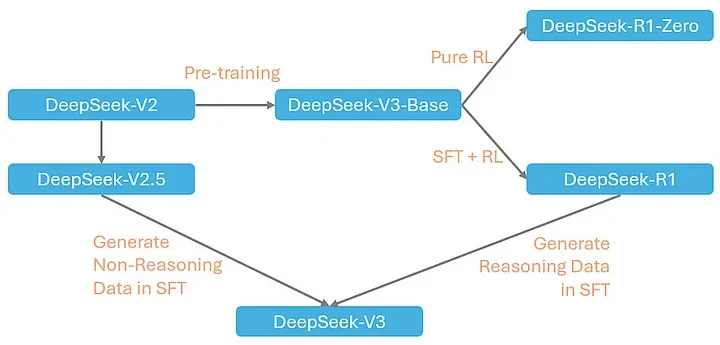
https://medium.com/@lixue421/deepseek-explained-8-post-training-of-deepseek-v3-6321d57f4fdf
그 외에도 DeepSeek V3 0324는 DeepSeek-R1에서 사용된 강화 학습 기술의 통찰을 통합했습니다.
Deepseek V3, R1, 0324: Low Price and Latency
Novita AI는 DeepSeek R1 Turbo 를 도입하여 **3배 처리량 ** 과 **한정 시간 60% 할인 ** 을 제공합니다. 또한 이 버전은 함수 호출 을 완전히 지원합니다.
지금 매우 저렴한 가격에 DeepSeek을 사용해보세요!
더 흥미로운 점: Novita AI는 OpenRouter에서 최상위 순위의 DeepSeek R1 API 중 하나입니다.
DeepSeek V3, R1, and 0324: Benchmark Showdown with GPT
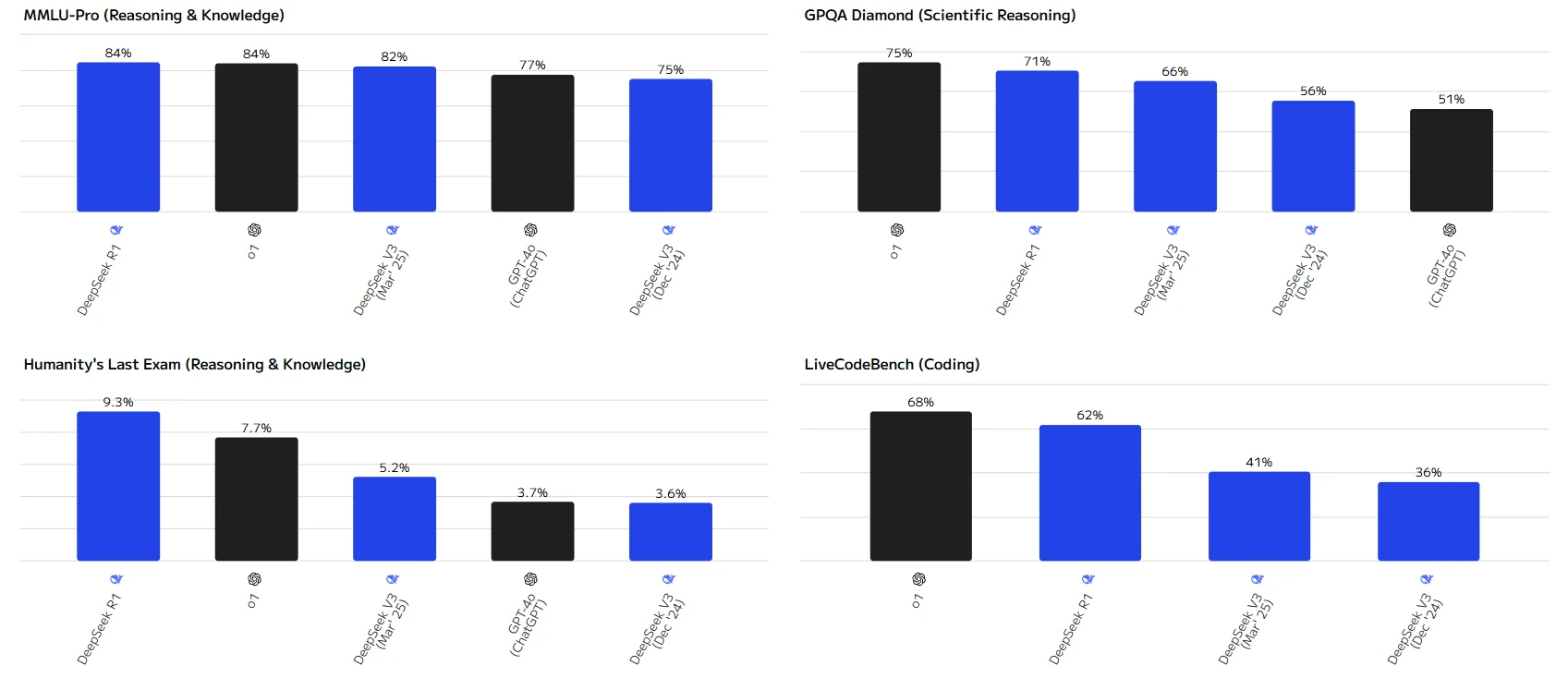
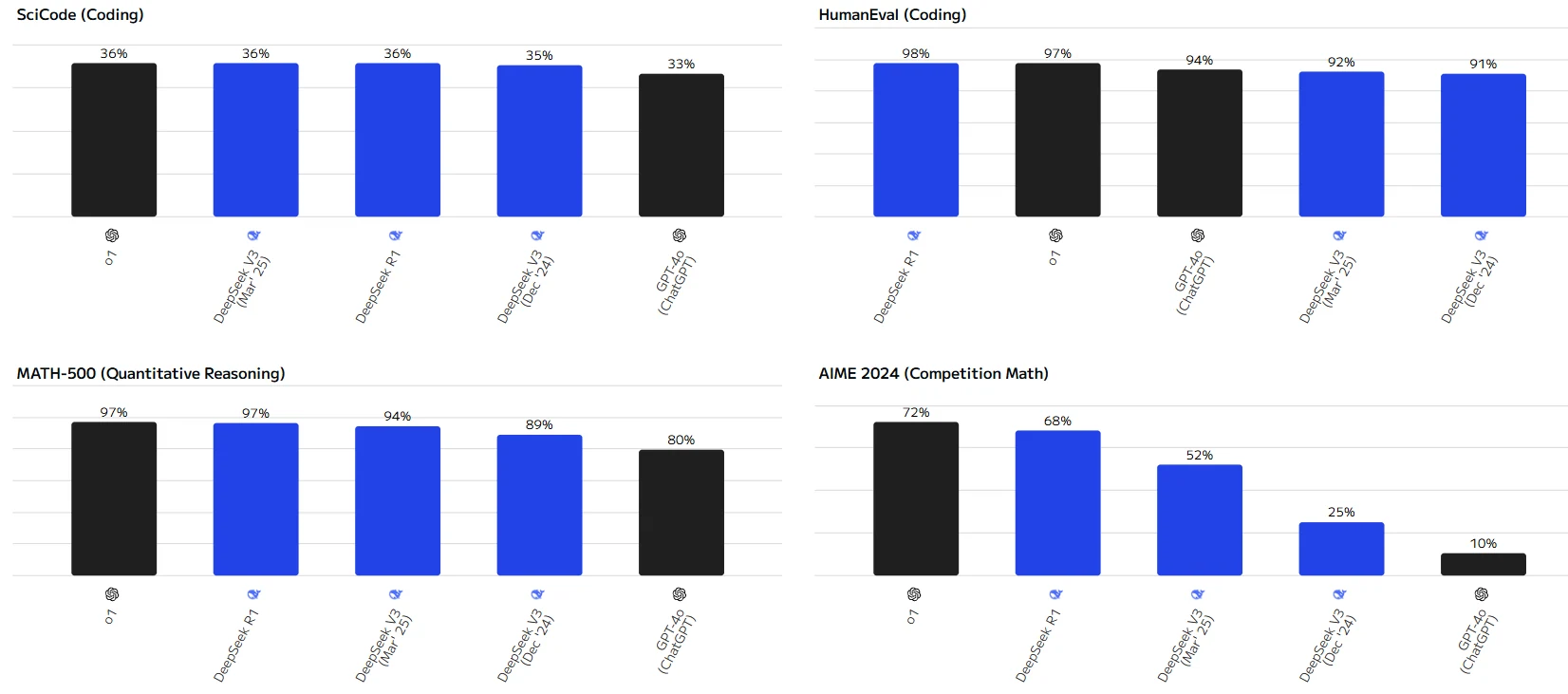
DeepSeek-R1은 여러 평가 벤치마크에서 뛰어난 성능을 보이며, 특히 HumanEval, MATH-500, MMLU-Pro와 같은 작업에서 최상위권에 랭크됩니다.
o1 모델도 대부분의 작업에서 좋은 성능을 보이며 일부 작업에서 DeepSeek-R1과 비슷한 결과를 달성합니다.
전반적으로 대부분의 평가 작업에서 DeepSeek V3(2025년 3월)가 DeepSeek V3(2024년 12월)를 능가합니다. LiveCodeBench 코딩 작업에서만 2024년 12월 버전이 약간 우위에 있습니다.
DeepSeek V3, R1, and 0324: Heavy Hardware Demands
| 모델 버전 | 필요한 VRAM(약) | GPU 구성 | 총 GPU 메모리 |
|---|---|---|---|
| DeepSeek V3 | 1423.01 GB | 24×H100 (80GB each) | 1920 GB |
| DeepSeek V3 0324 | 1532 GB | 24×H100 (80GB each) | 1920 GB |
| DeepSeek R1 (Base, 671B) | 1854.43 GB | 24×H100 (80GB each) | 1920 GB |
| DeepSeek-R1-Distill-Llama-8B | 22.2 GB | 1×RTX 4090 (24GB) | 24 GB |
| DeepSeek-R1-Distill-Qwen-14B | 39 GB | 2×RTX 4090 (24GB each) | 48 GB |
| DeepSeek-R1-Distill-Qwen-32B | 88.99 GB | 2×H100 (80GB each) | 160 GB |
| DeepSeek-R1-Distill-Llama-70B | 194.14 GB | 4×H100 (80GB each) | 320 GB |
DeepSeek V3, R1, and 0324: 3 API Access Options
Option 1: Direct API Integration
지금 매우 저렴한 가격에 DeepSeek을 사용해보세요!
Key Features:
- 통합 엔드포인트:
/v3/openai는 OpenAI의 Chat Completions API 형식을 지원합니다. - 유연한 제어: temperature, top-p, penalties 등을 조정하여 맞춤형 결과를 얻을 수 있습니다.
- 스트리밍 및 배치: 원하는 응답 모드를 선택하세요.
Option 2: Multi-Agent Workflows with OpenAI Agents SDK
Novita AI를 OpenAI Agents SDK와 통합하여 고급 멀티 에이전트 시스템을 구축하세요:
- 플러그 앤 플레이: 모든 OpenAI Agents 워크플로에서 Novita AI의 LLM을 사용하세요.
- 핸드오프, 라우팅, 도구 사용 지원: 위임, 분류 또는 함수 실행이 가능한 에이전트를 설계할 수 있으며, 모두 Novita AI의 모델로 구동됩니다.
- Python 통합: SDK를 Novita의 엔드포인트(
https://api.novita.ai/v3/openai)로 지정하고 API 키를 사용하기만 하면 됩니다.
Connect Qwen 3 API on Third-Party Platforms
- Hugging Face: Novita AI 엔드포인트를 통해 Spaces, 파이프라인 또는 Transformers 라이브러리에서 Qwen 3를 사용하세요.
- Agent & Orchestration Frameworks: 공식 커넥터와 단계별 통합 가이드를 통해 Novita AI를 Continue, AnythingLLM, LangChain, Dify 및 Langflow와 같은 파트너 플랫폼에 쉽게 연결하세요.
- OpenAI-Compatible API: OpenAI API 표준에 맞게 설계된 Cline 및 Cursor와 같은 도구와 함께 번거로움 없는 마이그레이션 및 통합을 즐기세요.
DeepSeek V3, R1, 0324 는 동일한 기본 모델 아키텍처를 공유하지만, 훈련 방식에 따라 성능과 응용에 큰 차이가 있습니다. 비용, 하드웨어 또는 작업별 품질을 최적화하든 이러한 차이점을 이해하면 올바른 모델을 선택하는 데 도움이 됩니다. 개발자의 경우 Novita AI는 주요 플랫폼에서 간단하고 유연하며 저렴한 액세스를 제공합니다.
Frequently Asked Questions
어느 DeepSeek 모델이 전체적으로 가장 우수한 성능을 보입니까?
DeepSeek V3(2025년 3월)가 LiveCodeBench에서 2024년 12월 버전이 약간 우위에 있는 것을 제외하고 평균 벤치마크 성능이 가장 좋습니다.
모든 버전이 함수 호출을 지원합니까?
예. 특히 Novita AI를 통한 R1 Turbo는 OpenAI 호환 엔드포인트로 완전한 지원을 제공합니다.
하드웨어 요구 사항은 무엇입니까?
전체 모델은 24×H100 GPU(약 1920GB VRAM)가 필요합니다. 증류 버전은 단일 RTX 4090 또는 듀얼 H100 설정에서 실행할 수 있습니다.
Novita AI는 개발자가 간단한 API를 사용하여 AI 모델을 쉽게 배포할 수 있는 AI 클라우드 플랫폼이며, 구축 및 확장을 위한 저렴하고 안정적인 GPU 클라우드를 제공합니다.



