

- Deepseek V3, R1, V3 0324: Gleiche Architektur
- Deepseek V3, R1, 0324 – Der wahre Unterschied liegt im Training
- Deepseek V3, R1, 0324: Niedriger Preis und niedrige Latenz
- DeepSeek V3, R1 und 0324: Benchmark-Vergleich mit GPT
- DeepSeek V3, R1 und 0324: Hohe Hardware-Anforderungen
- DeepSeek V3, R1 und 0324: 3 API-Zugriffsoptionen
DeepSeek R2 kommt – aber warum warten, wenn Sie mit dem, was bereits da ist, führen können?
Während alle auf DeepSeek R2 warten, dominieren clevere Entwickler bereits mit DeepSeek aktuellen Kraftpaket-Modellen auf Novita AI.
Neue Benutzer erhalten 10 $ kostenloses Guthaben und können Freunde werben, um bis zu 500 $ an LLM-API-Belohnungen zu erhalten!
Aktuelles DeepSeek-Angebot:
- DeepSeek V3 0324: 0,33 $ / M Eingabe, 1,30 $ / M Ausgabe (128K Kontext)
- DeepSeek R1 Turbo: 0,70 $ / M Eingabe, 2,50 $ / M Ausgabe (64K Kontext)
- DeepSeek V3 Turbo: 0,40 $ / M Eingabe, 1,30 $ / M Ausgabe (64K Kontext)
Warten Sie nicht auf die Modelle von morgen – setzen Sie noch heute mit nur einem API-Aufruf spielverändernde KI ein.
Deepseek V3, R1, V3 0324: Gleiche Architektur
| Kategorie | Details |
|---|---|
| Modellgröße | 671B Parameter (37B aktiv/Token) |
| Architektur | Mixture of Experts (MoE) |
| Open Source | Ja (alle Versionen) |
| Sprachunterstützung | Mehrsprachig – Hervorragend in Englisch und Chinesisch |
| Multimodal | Nur Text-zu-Text |
| Kontextfenster | 128K Token |
| Versionen | - DeepSeek R1: 21. Jan 2025 - DeepSeek V3 0324: 24. März 2025 - DeepSeek V3: 16. Dez 2024 |
Deepseek V3, R1, 0324 – Der wahre Unterschied liegt im Training
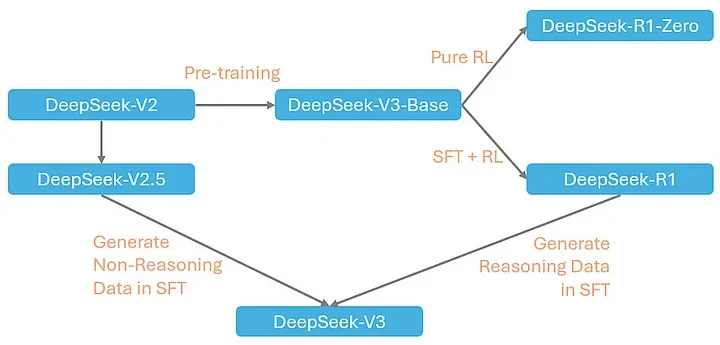
https://medium.com/@lixue421/deepseek-explained-8-post-training-of-deepseek-v3-6321d57f4fdf
Ansonsten enthält DeepSeek V3 0324 Erkenntnisse aus den Reinforcement-Learning-Techniken, die in DeepSeek-R1 verwendet werden.
Deepseek V3, R1, 0324: Niedriger Preis und niedrige Latenz
Novita AI hat DeepSeek R1 Turbo eingeführt, das 3-fachen Durchsatz und einen zeitlich begrenzten Rabatt von 60 % bietet. Darüber hinaus unterstützt diese Version vollständig Function Calling.
Jetzt DeepSeek zu sehr niedrigen Preisen ausprobieren!
Noch spannender: Novita AI gehört zu den bestbewerteten DeepSeek R1 APIs auf OpenRouter
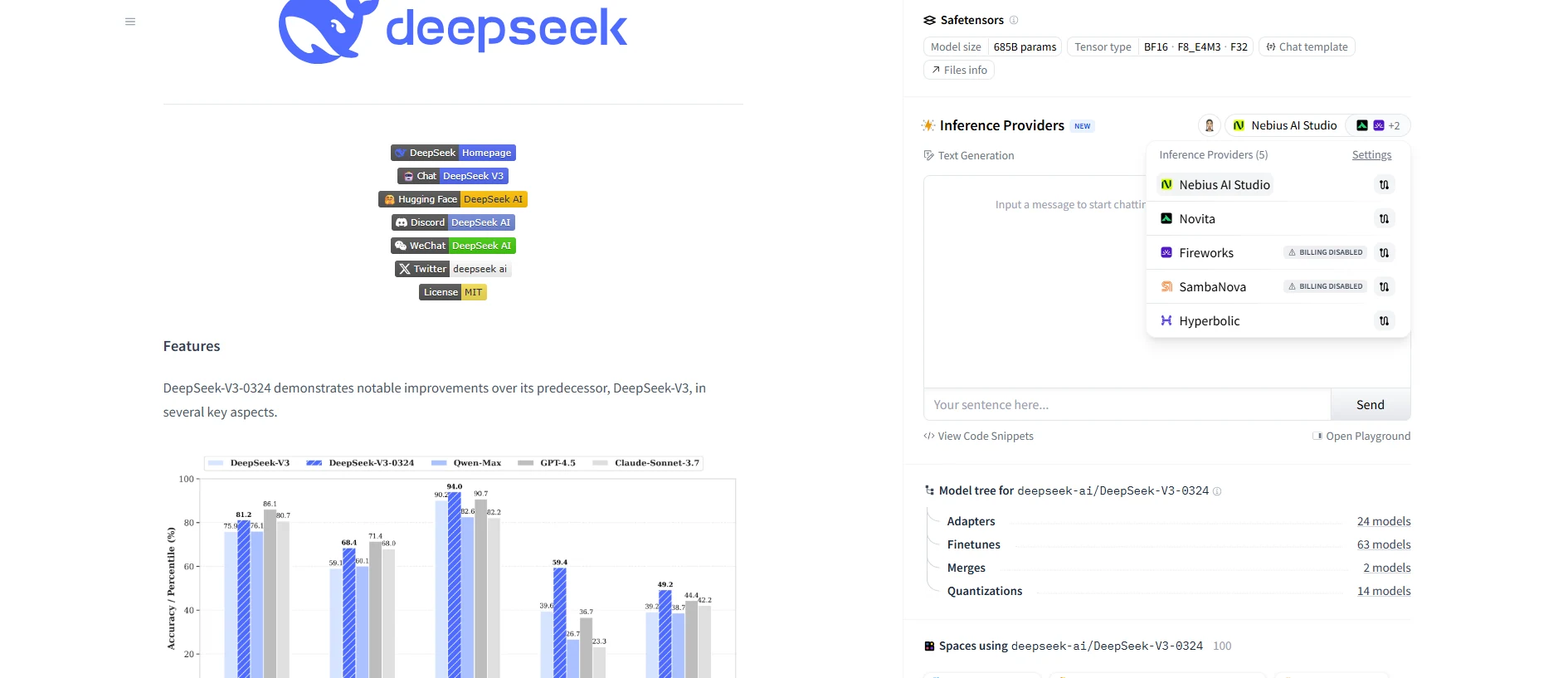
DeepSeek V3, R1 und 0324: Benchmark-Vergleich mit GPT
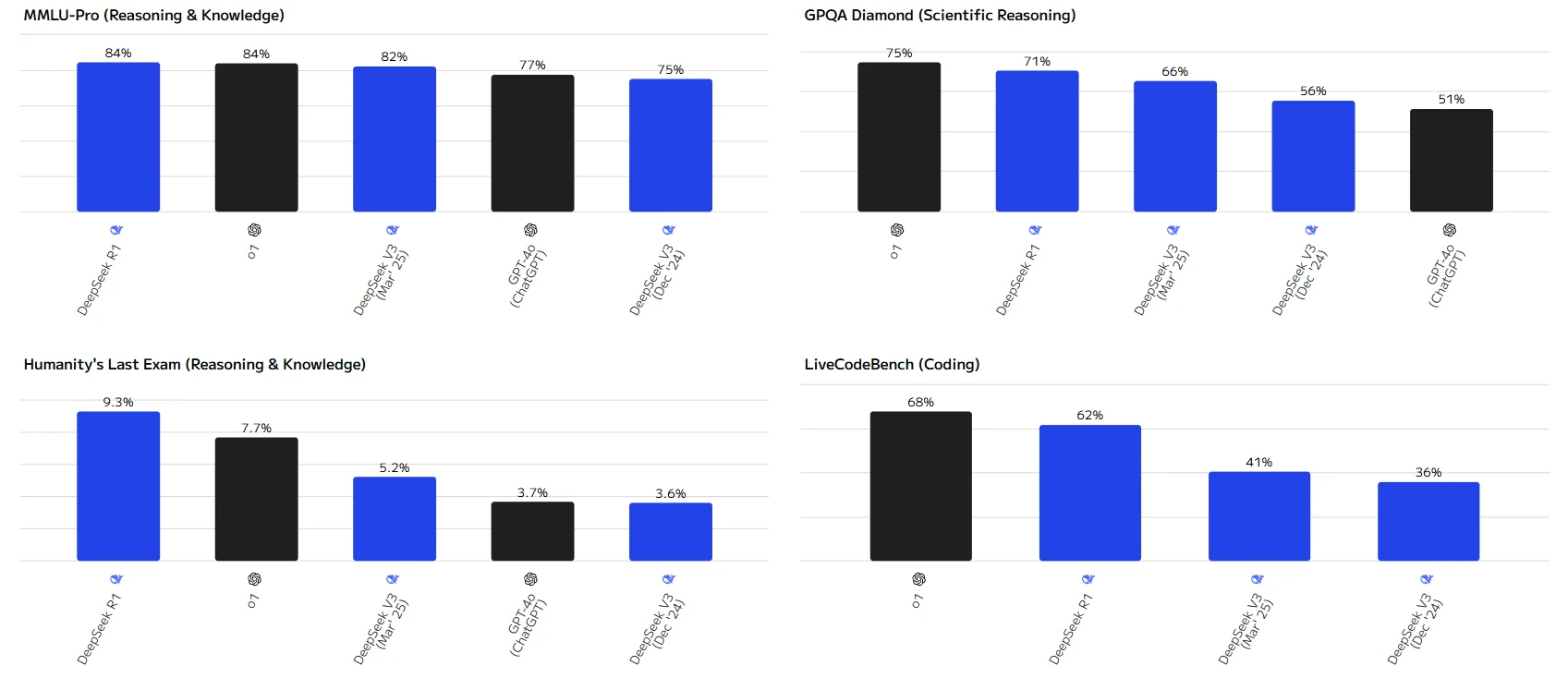
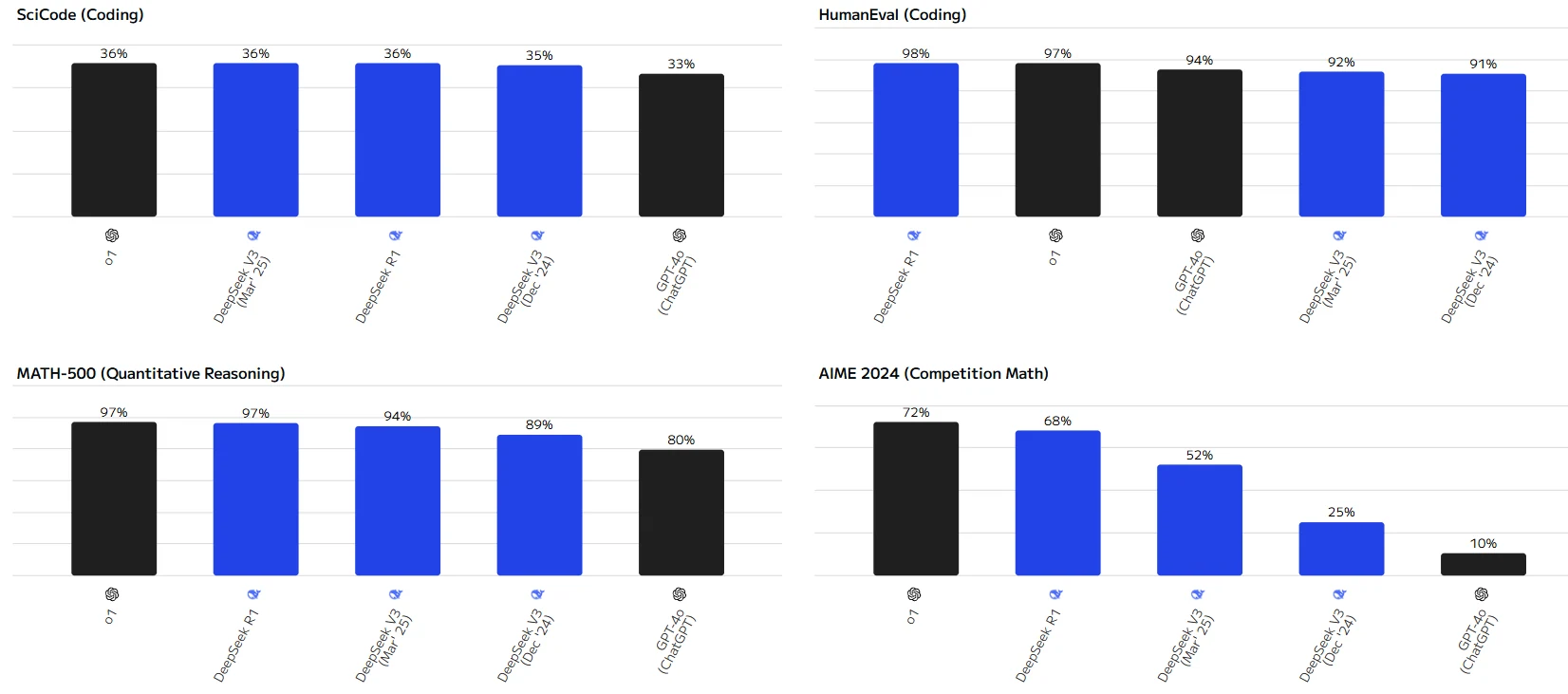
DeepSeek-R1 schneidet bei mehreren Evaluierungs-Benchmarks hervorragend ab und belegt insbesondere in Aufgaben wie HumanEval, MATH - 500 und MMLU - Pro einen Spitzenplatz.
Das o1-Modell zeigt ebenfalls gute Leistungen bei den meisten Aufgaben und erzielt in einigen Aufgaben vergleichbare Ergebnisse wie DeepSeek - R1.
Insgesamt übertrifft DeepSeek V3 (März '25) in den meisten Evaluierungsaufgaben DeepSeek V3 (Dez. '24). Nur bei der LiveCodeBench-Codierungsaufgabe hat die Version vom Dez. '24 einen leichten Vorteil.
DeepSeek V3, R1 und 0324: Hohe Hardware-Anforderungen
| Modellversion | Ca. erforderlicher VRAM | GPU-Konfiguration | Gesamter GPU-Speicher |
|---|---|---|---|
| DeepSeek V3 | 1423,01 GB | 24×H100 (je 80 GB) | 1920 GB |
| DeepSeek V3 0324 | 1532 GB | 24×H100 (je 80 GB) | 1920 GB |
| DeepSeek R1 (Base, 671B) | 1854,43 GB | 24×H100 (je 80 GB) | 1920 GB |
| DeepSeek-R1-Distill-Llama-8B | 22,2 GB | 1×RTX 4090 (24 GB) | 24 GB |
| DeepSeek-R1-Distill-Qwen-14B | 39 GB | 2×RTX 4090 (je 24 GB) | 48 GB |
| DeepSeek-R1-Distill-Qwen-32B | 88,99 GB | 2×H100 (je 80 GB) | 160 GB |
| DeepSeek-R1-Distill-Llama-70B | 194,14 GB | 4×H100 (je 80 GB) | 320 GB |
DeepSeek V3, R1 und 0324: 3 API-Zugriffsoptionen
Option 1: Direkte API-Integration
Jetzt DeepSeek zu sehr niedrigen Preisen ausprobieren!
Hauptmerkmale:
- Einheitlicher Endpunkt:
/v3/openaiunterstützt das Format der OpenAI Chat Completions API. - Flexible Steuerung: Passen Sie Temperatur, Top-p, Strafen und mehr für maßgeschneiderte Ergebnisse an.
- Streaming & Batching: Wählen Sie Ihren bevorzugten Antwortmodus.
Option 2: Multi-Agent-Workflows mit dem OpenAI Agents SDK
Erstellen Sie fortschrittliche Multi-Agenten-Systeme, indem Sie Novita AI mit dem OpenAI Agents SDK integrieren:
- Plug-and-Play: Nutzen Sie die LLMs von Novita AI in jedem OpenAI Agents Workflow.
- Unterstützt Übergaben, Routing und Tool-Nutzung: Entwerfen Sie Agenten, die delegieren, priorisieren oder Funktionen ausführen können – alle angetrieben von Novita AIs Modellen.
- Python-Integration: Richten Sie das SDK einfach auf Novitas Endpunkt (
https://api.novita.ai/v3/openai) aus und verwenden Sie Ihren API-Schlüssel.
Verbinden Sie die Qwen 3 API mit Drittanbieterplattformen
- Hugging Face: Nutzen Sie Qwen 3 in Spaces, Pipelines oder mit der Transformers-Bibliothek über Novita AI-Endpunkte.
- Agenten- und Orchestrierungs-Frameworks: Verbinden Sie Novita AI problemlos mit Partnerplattformen wie Continue, AnythingLLM, LangChain, Dify und Langflow über offizielle Konnektoren und schrittweise Integrationsanleitungen.
- OpenAI-kompatible API: Genießen Sie eine problemlose Migration und Integration mit Tools wie Cline und Cursor, die für den OpenAI API-Standard entwickelt wurden.
Während DeepSeek V3, R1 und 0324 dieselbe zugrunde liegende Modellarchitektur haben, führen ihre Trainingsmethoden zu erheblichen Unterschieden in Leistung und Anwendung. Ob Sie für Kosten, Hardware oder aufgabenspezifische Qualität optimieren – das Verständnis dieser Nuancen hilft Ihnen, das richtige Modell auszuwählen. Für Entwickler macht Novita AI den Zugriff einfach, flexibel und erschwinglich auf allen großen Plattformen.
Häufig gestellte Fragen
Welches DeepSeek-Modell ist insgesamt am leistungsfähigsten?
DeepSeek V3 (März 2025) zeigt die beste durchschnittliche Benchmark-Leistung, außer bei LiveCodeBench, wo die Version vom Dezember 2024 einen leichten Vorsprung hat.
Unterstützen alle Versionen Function Calling?
Ja – insbesondere R1 Turbo über Novita AI bietet volle Unterstützung mit OpenAI-kompatiblen Endpunkten.
Was sind die Hardware-Anforderungen?
Vollständige Modelle benötigen 24×H100 GPUs (~1920 GB VRAM); distillierte Versionen können auf einer einzelnen RTX 4090 oder dualen H100-Setups ausgeführt werden.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, während sie gleichzeitig die erschwingliche und zuverlässige GPU-Cloud zum Erstellen und Skalieren bereitstellt.



