

- Qwen3 Coder と GLM 4.5 の主なアーキテクチャの違いは?
- Qwen3 Coder と GLM 4.5 のコード生成タスクにおけるベンチマーク結果
- 速度と価格の比較:初心者向け Qwen3 Coder vs GLM 4.5
- Qwen3 Coder と GLM 4.5:リソース効率に優れているのはどちらか?
- Qwen3 Coder vs GLM 4.5:Python プログラミングにはどちらが良いか?
- ソフトウェア向け Qwen3 Coder と GLM 4.5 の比較
- CLIツールで Qwen 3 Coder 480B A35B にアクセスする方法
- Trae での Qwen 3 Coder 480B A35B と GLM 4.5 の利用
- Qwen Code での Qwen 3 Coder 480B A35B と GLM 4.5 の利用
コーディングに関しては、すべての大規模言語モデルが同じように作られているわけではありません。最先端の2つのモデル、Qwen3-Coder (480B-A35B-Instruct) と GLM-4.5 は、非常に異なるアプローチをとっています。
- Qwen3-Coder は ** コード専門モデル ** で、学習データの約70%がプログラミング関連です。358のプログラミング言語 をサポートし、Pythonで最先端の結果を達成しており、特にマルチターンのデバッグ、大規模コードベースの編集、リポジトリ規模のワークフローに強みを持ちます。
- GLM-4.5 は、** 多用途のジェネラリスト ** です。コード能力も高いですが、真の強みは ** エージェント的ワークフロー** にあります。API、データベース、外部ツールをオーケストレーションし、90.6%のツール呼び出し成功率 を誇り、これは現行モデルの中で最高です。
👉 本記事では、以下の重要な問いに答えます。Qwen3-Coder と GLM-4.5 は、コーディングパフォーマンスにおいて実際にどう異なるのか、そしてそれぞれどのような開発者やワークフローに最適なのか?
主要なLLM APIプロバイダーの一つである Novita AI は、安定した低コストのAPIを提供しています。料金情報から、Qwen3-Coder は GLM 4.5 よりもわずかに安価 であることがわかります。
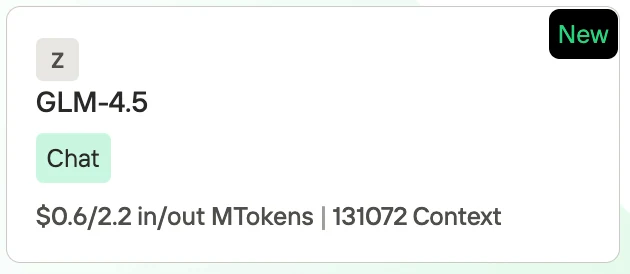
- GLM-4.5: ** 入力100万トークンあたり $0.60 / 出力100万トークンあたり $2.20**、コンテキスト長は 131,072 トークン。
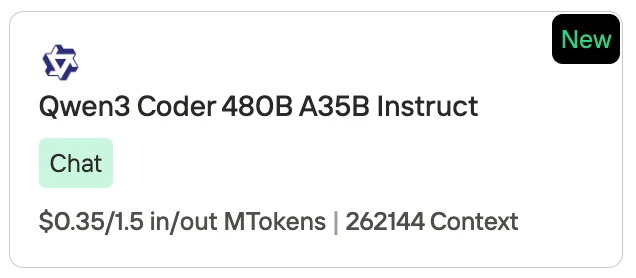
- Qwen3-Coder (480B A35B Instruct): ** 入力100万トークンあたり $0.35 / 出力100万トークンあたり $1.50**、コンテキスト長は 262,144 トークン。
Qwen3 Coder と GLM 4.5 の主なアーキテクチャの違いは?
https://www.youtube.com/watch?v=ulfZwEa1x\_o
| 機能 | Qwen3-Coder (480B-A35B-Instruct) | GLM-4.5 |
|---|---|---|
| アーキテクチャ (MoE) | 総パラメータ480B、推論ごとに約35B活性化(160エキスパート中8) | 総パラメータ355B、推論ごとに32B活性化 |
| コンテキスト長 | ネイティブサポート 262,144 トークン(約256K) | 適切なハードウェア設定で最大128Kコンテキストをサポート |
| **推論モード ** | 非思考モードのみサポート。thinking response ブロックは生成** しない** |
ハイブリッド推論:「思考」モードと「非思考」モードの両方をサポート |
Qwen3 Coder と GLM 4.5 のコード生成タスクにおけるベンチマーク結果
| ベンチマーク / シナリオ | Qwen3-Coder | GLM 4.5 |
|---|---|---|
| SWE-Bench Verified | 67.0% | 64.2% |
| SciCode (Coding) | 36% | 35% |
| LiveCodeBench (Coding) | 59% | 74% |
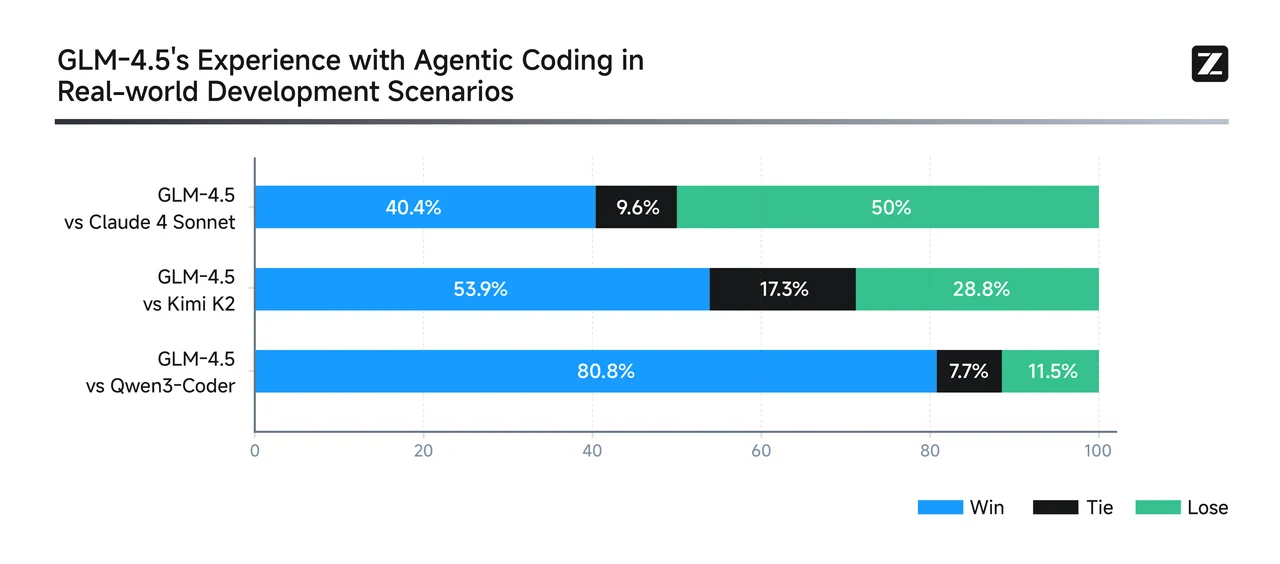
GLM より
Qwen3-Coder は、マルチターン、エージェント的なコードワークフロー に優れています。特に実世界に近いデバッグやツール統合タスクで際立ちます。オープンソースモデルとして最高クラスの結果を達成し、トップのプロプライエタリシステムと競争力があります。**リポジトリ規模のバグ修正 **、複数ファイルの編集、自動化されたエージェント的ツールワークフローには、Qwen3-Coder がより強い選択肢と言えるでしょう。
GLM-4.5 は 多用途のジェネラリスト であり、推論、コーディング、エージェント的ベンチマークで高いスコアを獲得しています。ハイブリッド推論モードをサポートし、複数のドメインで堅牢なパフォーマンスを発揮しつつ、SWE-Benchでも高い存在感を示しています。推論、コーディング、ツール統合をバランスよく必要とし、中程度のコンテキストニーズがあるタスクには、GLM-4.5 が魅力的なマルチドメインパフォーマーです。
速度と価格の比較:初心者向け Qwen3 Coder vs GLM 4.5
| モデル | VRAM | 推奨 GPU |
|---|---|---|
| Qwen 3 Coder | 1050GB | 8 x H100 NVL |
| GLM 4.5 | 945GB | 8 x H100 NVL |
どちらも同じクラスのGPUを必要としますが、GLM 4.5 はVRAMフットプリントが小さいため、より高速かつ効率的に動作します。一方、Qwen3-Coder は同じ条件下でより重く、処理が遅くなります。
GLM 4.5 の価格
Qwen 3 Coder の価格
主要なLLM APIプロバイダーの一つである Novita AI は、安定した低コストのAPIを提供しています。料金情報から、Qwen3-Coder は GLM 4.5 よりもわずかに安価 であることがわかります。
- GLM-4.5: ** 入力100万トークンあたり $0.60 / 出力100万トークンあたり $2.20**、コンテキスト長は 131,072 トークン。
- Qwen3-Coder (480B A35B Instruct): ** 入力100万トークンあたり $0.35 / 出力100万トークンあたり $1.50**、コンテキスト長は 262,144 トークン。
Qwen3 Coder と GLM 4.5:リソース効率に優れているのはどちらか?
| 側面 | Qwen3-Coder (480B A35B) | GLM 4.5 (355B) | ** より効率的なモデル** |
|---|---|---|---|
| **VRAM要件 ** | ~1050 GB、8× H100 NVL が必要 | ~945 GB、8× H100 NVL が必要 | GLM 4.5(約10%軽量) |
| **推論速度 ** | メモリフットプリントが大きいため低速 | 同一ハードウェアで高速、低レイテンシ | GLM 4.5 |
| **コンテキスト容量 ** | 262K トークン(100万まで拡張可能) | 131K トークン | Qwen3-Coder |
| 価格 (Novita AI) | 入力100万トークンあたり $0.35 / 出力100万トークンあたり $1.50 | 入力100万トークンあたり $0.60 / 出力100万トークンあたり $2.20 | Qwen3-Coder |
| **専門性 ** | 学習データの70%がコード。大規模コーディングタスクに最適化 | 推論、コーディング、エージェント的タスクのバランス型 | ** ユースケースによる** |
| **総合的な効率 ** | コストと長文脈利用に効率的 | ハードウェアと速度に効率的 | ** 分割:Qwen3 はコスト/コンテキスト、GLM 4.5 は計算/速度** |
- GLM 4.5 は、** ハードウェア(VRAM、速度、レイテンシ)** に関しては ** よりリソース効率的** です。
- Qwen3-Coder は、** トークンコストと大規模コンテキスト処理 ** の点で ** より効率的** です。
👉 実際には:
- **高速な推論と軽い計算負荷 ** を重視する場合は GLM 4.5 を選択してください。
- **低コストのトークンと超長文脈 ** を大規模コードベースで必要とする場合は Qwen3-Coder を選択してください。
Qwen3 Coder vs GLM 4.5:Python プログラミングにはどちらが良いか?
| 側面 | Qwen3-Coder | GLM 4.5 | 推奨 |
|---|---|---|---|
| **Python コーディングベンチマーク ** (HumanEval, MBPP, LCB) | 強力なパフォーマンス。ユーザーレポートや評価では標準的なPythonベンチマークで優位とされる | 良好なパフォーマンスだが、純粋なPythonコード生成ではやや劣る | Qwen3-Coder |
| **エージェント的 / ツール呼び出しタスク ** | 77.1% | 90.6% | GLM 4.5 — API呼び出し、外部ツール、複雑な対話を含むワークフローに最適 |
| **サポートプログラミング言語 ** | **358言語 ** をサポート。Pythonやニッチ/レガシー言語もカバー – 多言語やエッジケースに最適 | 多言語サポートに関する具体的なデータなし – おそらく強いが範囲は狭い | Qwen3-Coder |
| **コンテキスト長 ** | 256K トークン | 128K トークンウィンドウ | Qwen3-Coder |
| **推論速度と効率 ** | VRAM使用量が大きく、1050 GB 必要のため低速 | 軽量(945 GB)、高速、ハードウェア効率が良い | GLM 4.5 |
- Qwen3-Coder を選ぶべき主なケース:
- 純粋なPythonコードの作成やリファクタリング(ノートブック、スクリプト、MLワークフローなど)。
- 多数またはニッチな言語(358言語対応)を扱う場合。
- 拡張コンテキスト(256K~1Mトークン)を必要とする 大規模コードベース やPythonプロジェクトを扱う場合。
- トークンあたりのコスト を最小化したい場合 — 頻繁なPython反復に最適。
- GLM 4.5 を選ぶべき主なケース:
- 信頼性の高いツール統合、APIオーケストレーション、外部依存関係を含むエージェント的ワークフローが必要な場合。
- 特定のハードウェア上での 高速かつ効率的な推論 が必要な場合。
- デバッグ、説明、段階的なPythonロジックタスクのための強力な推論能力が必要な場合。
ソフトウェア向け Qwen3 Coder と GLM 4.5 の比較
テトリスゲームを作成する
Qwen 3 Coder
GLM 4.5
最初の50匹のポケモンを表示し、アニメーションとタイプを含むインタラクティブなポケモン図鑑ウェブページを構築する。
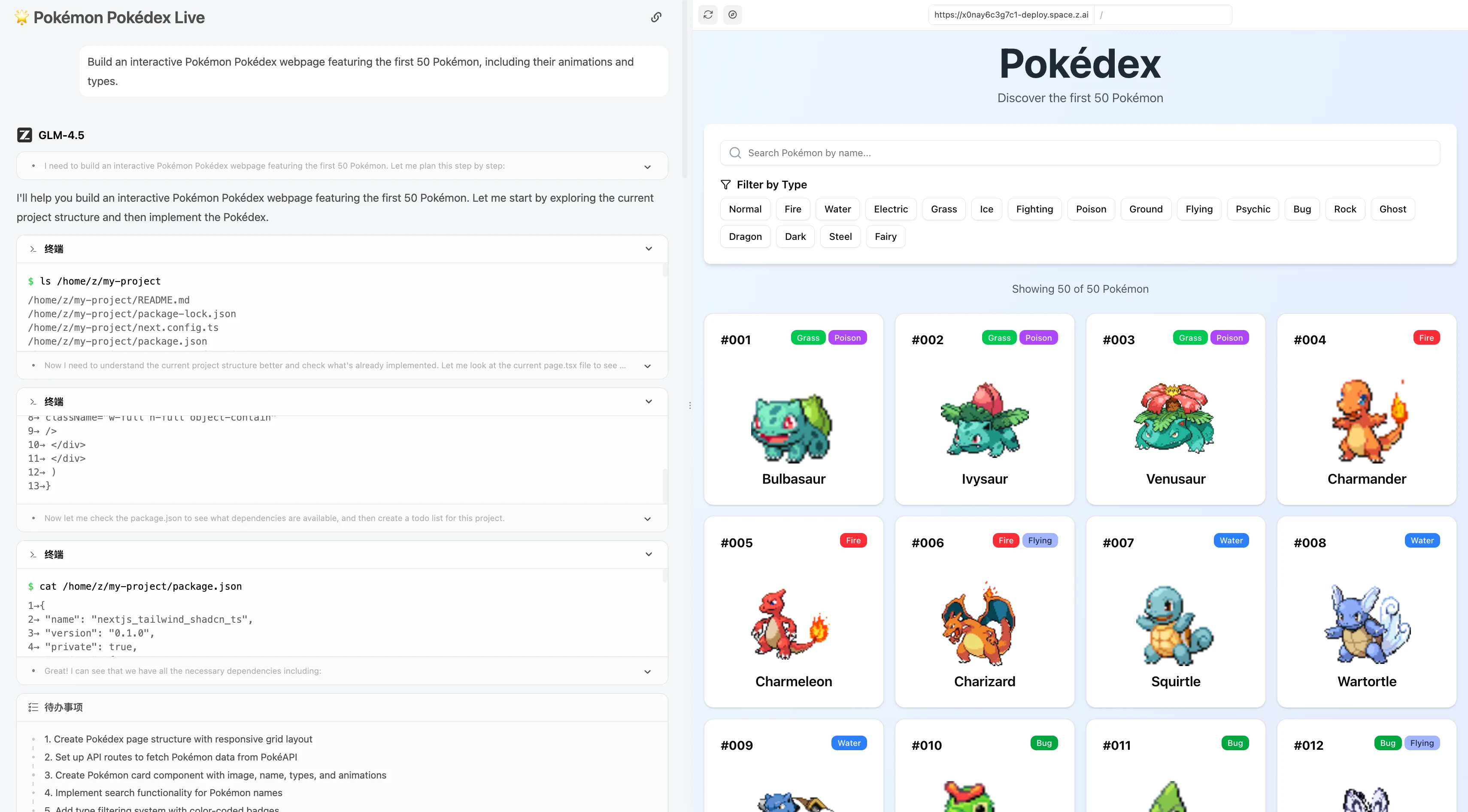
GLM 4.5
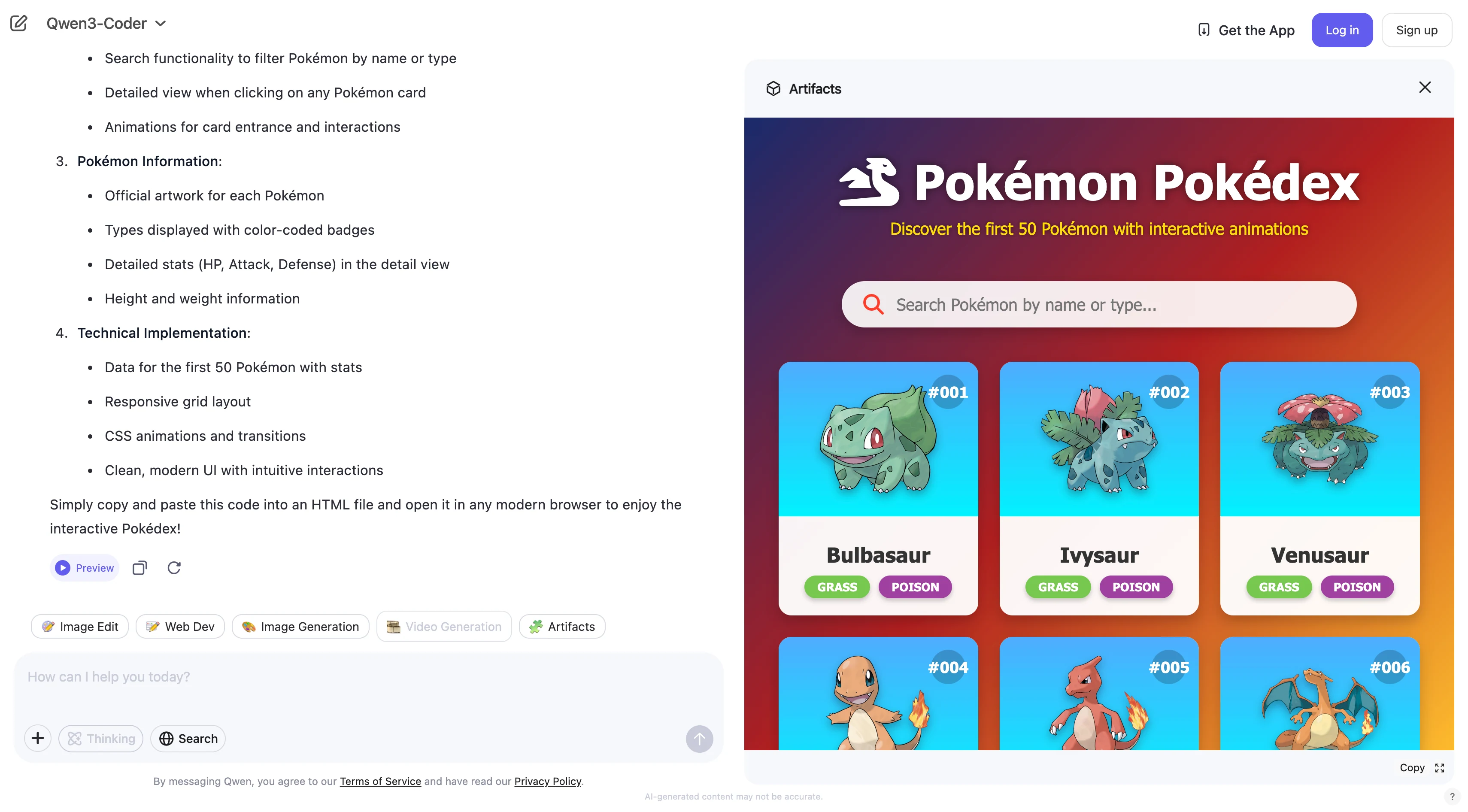
Qwen 3 coder
CLIツールで Qwen 3 Coder 480B A35B にアクセスする方法
https://www.youtube.com/watch?v=hsPzLalRnpc
- 高速: Qwen3-Coder をコマンドラインから直接使用可能 — ウェブサイトや追加ソフトウェアは不要。
- 簡単な自動化: Qwen3-Coder をコーディングタスクに利用するスクリプトを簡単に記述可能。
- 開発者のワークフローに適合: 多くの開発者はコマンドラインを使用するため、Qwen3-Coder は日常業務の自然な一部となる。
- 容易なスケーリング: CLIコマンドを使用して、多数のファイルやプロジェクトを迅速に処理可能。
その1:APIキーを取得
ステップ 1: アカウントにログインし、モデルライブラリボタンをクリックします。

今すぐ Qwen 3 Coder モデルと GLM 4.5 を試す!
ステップ 2: モデルを選択
利用可能なオプションから、ニーズに合ったモデルを選択します。
ステップ 3: 無料トライアルを開始
選択したモデルの機能を試すために、無料トライアルを開始します。
ステップ 4: APIキーを取得
APIで認証するために、新しいAPIキーを提供します。「設定」ページに移動し、画像のようにAPIキーをコピーします。

ステップ 5: APIをインストール
プログラミング言語固有のパッケージマネージャーを使用してAPIをインストールします。
インストール後、開発環境に必要なライブラリをインポートします。APIキーを使ってAPIを初期化し、Novita AI LLMとの対話を開始します。以下は、Pythonユーザー向けのチャット補完APIの使用例です。
pip install 'openai>=1.0.0'
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "qwen/qwen3-coder-480b-a35b-instruct"
stream = True # or False
max_tokens = 131072
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Trae での Qwen 3 Coder 480B A35B と GLM 4.5 の利用
ステップ 1: Trae を開き、モデルにアクセス
Trae アプリを起動します。右上隅の AI サイドバーの切り替えボタンをクリックして、AI サイドバーを開きます。次に、AI管理に移動し、「モデル」を選択します。

ステップ 2: カスタムモデルを追加し、プロバイダーとして Novita を選択
「モデルを追加」ボタンをクリックして、カスタムモデルエントリを作成します。モデル追加ダイアログで、ドロップダウンメニューから Provider = Novita を選択します。


ステップ 3: モデルを選択または入力
モデルのドロップダウンから、希望するモデル(DeepSeek-R1-0528、Kimi K2 DeepSeek-V3-0324、または MiniMax-M1-80k)を選択します。正確なモデルがリストにない場合は、Novita ライブラリで確認したモデルIDを直接入力します。使用したいモデルの正しいバリアントを選択してください。
APIキーは Novita コンソール で取得できます。
Qwen Code での Qwen 3 Coder 480B A35B と GLM 4.5 の利用
Qwen Code は Gemini Code をベースに開発されていますが、Qwen3-Coder のエージェント的コーディングタスクにおけるパフォーマンスを最大化するために、プロンプトとツール呼び出しプロトコルを適応させています。
ステップ 1: Qwen Code をインストール
前提条件: Node.js バージョン20以上がインストールされていることを確認してください。公式 Node.js ウェブサイト からダウンロードできます。
パッケージをグローバルにインストール:
npm install -g @qwen-code/qwen-code
ステップ 2: 環境変数を設定
Windows(コマンドプロンプト)の場合:
set OPENAI_API_KEY=Your_Novita_API_Key
set OPENAI_BASE_URL=https://api.novita.ai/v3/openai
set OPENAI_MODEL=qwen/qwen3-coder-480b-a35b-instruct
Linux および Mac(Bash)の場合:
export OPENAI_API_KEY="Your_Novita_API_Key"
export OPENAI_BASE_URL="https://api.novita.ai/v3/openai"
export OPENAI_MODEL="qwen/qwen3-coder-480b-a35b-instruct"
ステップ 3: コーディングを開始
設定が完了したら、選択した Novita AI モデルで Qwen Code の使用を開始できます。このツールは、すべてのコーディング支援タスクで指定されたモデルを使用します。
cd <your-project-directory>
qwen .
コーディングタスクでは、両方のモデルが優れていますが、異なる方法で輝きます。
- Qwen3-Coder は ** 純粋なコーディングパフォーマンス ** でより強い選択肢です。Pythonの作成やリファクタリング、ニッチな言語のサポート、大規模コードベースの処理において優れており、256K~1Mトークン のコンテキストと低いトークンコストが強みです。
- GLM-4.5 は、** コーディングと推論・統合が交差する場面 ** で際立ちます。実行速度が速く、リソース効率が高く、** ツール呼び出し** で優位性を発揮するため、エージェント的プログラミング環境に最適です。
👉 **大規模コードベース内のソフトウェア ** を構築する場合は Qwen3-Coder を選択してください。
👉 **インテリジェントなコーディングエージェントやAPI駆動型アプリケーション ** を構築する場合は GLM-4.5 を選択してください。
よくある質問
Python プログラミングにはどちらのモデルが良いですか?
Qwen3-Coder は標準的なPythonベンチマーク(HumanEval、MBPP、LiveCodeBench)でリードしており、ノートブック、MLワークフロー、スクリプト自動化に推奨されます。
多言語やレガシーコードにはどちらのモデルが良いですか?
Qwen3-Coder は 358のプログラミング言語 をサポートしており、多様な開発シナリオやエッジケースに適しています。
デバッグやリポジトリ規模のワークフローを処理するのはどちらですか?
Qwen3-Coder は、超長文脈(256K~1Mトークン)により、マルチターンデバッグ、大規模コード編集、リポジトリ規模のタスクに優れています。
Novita AI は、AIの野心を支援するオールインワンのクラウドプラットフォームです。統合API、サーバーレス、GPUインスタンス — コスト効率の高いツールを提供します。インフラストラクチャを排除し、無料で始めて、AIのビジョンを現実にしましょう。
おすすめの記事
Llama 3.2 3B vs DeepSeek V3: 効率とパフォーマンスの比較.



