

- ¿Cuáles son las principales diferencias arquitectónicas entre Qwen3 Coder y GLM 4.5?
- Resultados de Benchmark para Qwen3 Coder y GLM 4.5 en Tareas de Generación de Código
- Comparación de Velocidad y Precio: Qwen3 Coder vs GLM 4.5 para Principiantes
- Qwen3 Coder y GLM 4.5: ¿Qué Modelo es Más Eficiente en Términos de Recursos?
- Qwen3 Coder vs GLM 4.5: ¿Cuál es Mejor para Programación en Python?
- Comparación de Qwen3 Coder y GLM 4.5 para Software
- Cómo Acceder a Qwen 3 Coder 480B A35B Mediante Herramientas CLI?
- Qwen 3 Coder 480B A35B y GLM 4.5 con Trae
- Qwen 3 Coder 480B A35B y GLM 4.5 con Qwen Code
Cuando se trata de programación, no todos los modelos de lenguaje grandes están construidos de la misma manera. Dos de los contendientes más avanzados—Qwen3-Coder (480B-A35B-Instruct) y GLM-4.5—toman enfoques muy diferentes.
- Qwen3-Coder es un modelo especializado en código, entrenado con aproximadamente el 70% de sus datos en programación. Soporta 358 lenguajes de programación, logra resultados de vanguardia en Python, y es especialmente fuerte en depuración multi-turno, edición de grandes bases de código y flujos de trabajo a escala de repositorio.
- GLM-4.5, por otro lado, es un generalista versátil. Aunque sigue siendo muy capaz en código, su verdadera fortaleza radica en flujos de trabajo agénticos: orquestar APIs, bases de datos y herramientas externas con una tasa de éxito del 90.6% en llamadas de herramientas, la más alta entre los modelos actuales.
👉 Este artículo responderá la pregunta clave: ¿Cómo difieren realmente Qwen3-Coder y GLM-4.5 en rendimiento de programación—y qué tipo de desarrollador o flujo de trabajo es más adecuado para cada uno?
Novita AI, como uno de los proveedores más importantes en el campo de las API de LLM, ofrece API estables y altamente rentables. Según la información de precios, podemos ver que Qwen3-Coder es ligeramente más barato que GLM 4.5.
- GLM-4.5: $0.60 por 1M de tokens de entrada / $2.20 por 1M de tokens de salida, con una longitud de contexto de 131,072 tokens.
- Qwen3-Coder (480B A35B Instruct): $0.35 por 1M de tokens de entrada / $1.50 por 1M de tokens de salida, con una longitud de contexto de 262,144 tokens.
¿Cuáles son las principales diferencias arquitectónicas entre Qwen3 Coder y GLM 4.5?
https://www.youtube.com/watch?v=ulfZwEa1x\_o
| Característica | Qwen3-Coder (480B-A35B-Instruct) | GLM-4.5 |
|---|---|---|
| Arquitectura (MoE) | 480B parámetros totales, ~35B activos por inferencia (8 de 160 expertos) | 355B parámetros totales, 32B activos por inferencia |
| Longitud de Contexto | Soporte nativo de 262,144 tokens (≈256K) | Soporta hasta 128K de contexto con la configuración de hardware adecuada |
| Modos de Razonamiento | Solo soporta modo sin pensamiento; no genera bloques de thinking response |
Razonamiento híbrido: tanto modo “pensamiento” (formalmente estilo cadena de pensamiento) como modo “sin pensamiento” soportado |
Resultados de Benchmark para Qwen3 Coder y GLM 4.5 en Tareas de Generación de Código
| Benchmark / Escenario | Qwen3-Coder | GLM 4.5 |
|---|---|---|
| SWE-Bench Verified | 67.0 % | 64.2 % |
| SciCode (Programación) | 36% | 35% |
| LiveCodeBench (Programación) | 59% | 74% |
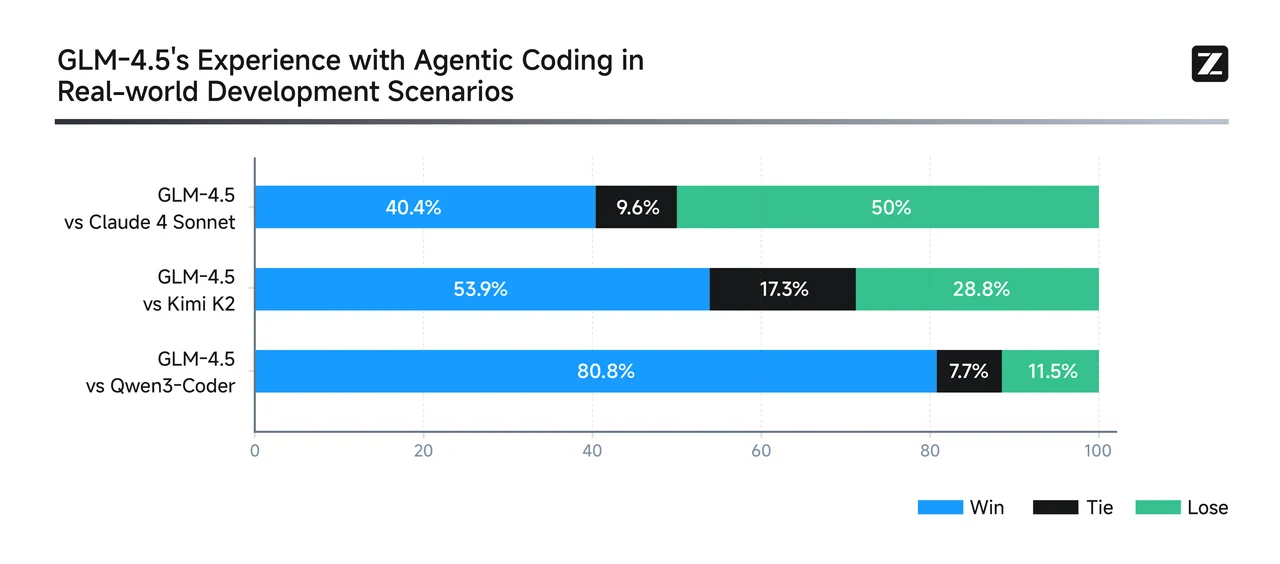
De GLM
Qwen3-Coder sobresale en flujos de trabajo de código agénticos multi-turno—especialmente en tareas de depuración del mundo real e integración de herramientas. Logra resultados de primer nivel para modelos de código abierto y es competitivo con sistemas propietarios de primer nivel. Para correcciones de errores a escala de repositorio, ediciones de múltiples archivos y flujos de trabajo automatizados de herramientas agénticas: Qwen3-Coder es probablemente la opción más fuerte.
GLM-4.5 es un generalista versátil—ocupa un lugar alto en benchmarks de razonamiento, programación y agénticos. Soporta modos de razonamiento híbrido y ofrece un rendimiento robusto en múltiples dominios, manteniendo una fuerte presencia en SWE-Bench. Para tareas equilibradas que abarcan razonamiento, programación e integración de herramientas—con necesidades de contexto moderadas: GLM-4.5 ofrece un ejecutor multidominio convincente.
Comparación de Velocidad y Precio: Qwen3 Coder vs GLM 4.5 para Principiantes
| Modelo | VRAM | GPU Recomendada |
| Qwen 3 Coder | 1050GB | 8 x H100 NVL |
| GLM 4.5 | 945GB | 8 x H100 NVL |
Aunque ambos necesitan la misma clase de GPUs, GLM 4.5 se ejecuta más rápido y de manera más eficiente debido a su menor consumo de VRAM, mientras que Qwen3-Coder es más pesado y lento bajo las mismas condiciones.
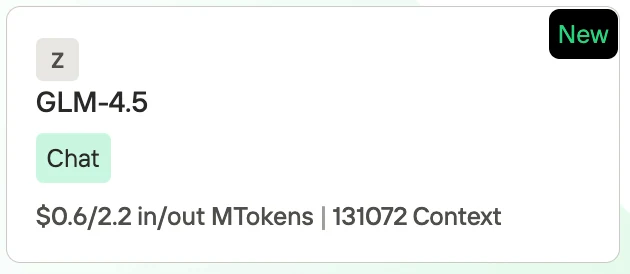
Precio de GLM 4.5
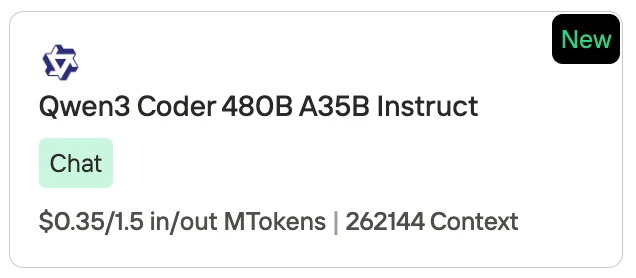
Precio de Qwen 3 Coder
Novita AI, como uno de los proveedores más importantes en el campo de las API de LLM, ofrece API estables y altamente rentables. Según la información de precios, podemos ver que Qwen3-Coder es ligeramente más barato que GLM 4.5.
- GLM-4.5: $0.60 por 1M de tokens de entrada / $2.20 por 1M de tokens de salida, con una longitud de contexto de 131,072 tokens.
- Qwen3-Coder (480B A35B Instruct): $0.35 por 1M de tokens de entrada / $1.50 por 1M de tokens de salida, con una longitud de contexto de 262,144 tokens.
Qwen3 Coder y GLM 4.5: ¿Qué Modelo es Más Eficiente en Términos de Recursos?
| Aspecto | Qwen3-Coder (480B A35B) | GLM 4.5 (355B) | Modelo Más Eficiente |
|---|---|---|---|
| Requisito de VRAM | ~1050 GB, necesita 8× H100 NVL | ~945 GB, necesita 8× H100 NVL | GLM 4.5 (≈10% más ligero) |
| Velocidad de Inferencia | Más lento debido al mayor consumo de memoria | Más rápido, menor latencia en el mismo hardware | GLM 4.5 |
| Capacidad de Contexto | 262K tokens (extensible a 1M) | 131K tokens | Qwen3-Coder |
| Precio (Novita AI) | $0.35 por 1M de entrada / $1.50 por 1M de salida | $0.60 por 1M de entrada / $2.20 por 1M de salida | Qwen3-Coder |
| Especialización | 70% de datos de entrenamiento en código; optimizado para tareas de código a gran escala | Mezcla equilibrada de razonamiento, programación y tareas agénticas | Depende del caso de uso |
| Eficiencia General | Eficiente por costo y uso de contexto largo | Eficiente por hardware y velocidad | Dividido: Qwen3 por costo/contexto, GLM 4.5 por cómputo/velocidad |
- GLM 4.5 es más eficiente en recursos cuando hablamos de hardware (VRAM, velocidad, latencia).
- Qwen3-Coder es más eficiente en términos de costo de tokens y manejo de contextos masivos.
👉 En la práctica:
- Elija GLM 4.5 si le importa inferencia más rápida y carga computacional más ligera.
- Elija Qwen3-Coder si necesita tokens más baratos y ventanas de contexto ultra largas para bases de código grandes.
Qwen3 Coder vs GLM 4.5: ¿Cuál es Mejor para Programación en Python?
| Aspecto | Qwen3-Coder | GLM 4.5 | Recomendación |
|---|---|---|---|
| Benchmarks de Programación en Python (HumanEval, MBPP, LCB) | Buen rendimiento; informes de usuarios y evaluaciones sugieren dominio en benchmarks estándar de Python | También funciona bien, pero ligeramente por detrás en generación de código Python puro | Qwen3-Coder |
| Tareas Agénticas / de Llamada de Herramientas | 77.1% | 90.6% | GLM 4.5—ideal para flujos de trabajo que involucran llamadas API, herramientas externas o interacciones complejas |
| Lenguajes de Programación Soportados | Soporta 358 lenguajes, incluyendo Python y lenguajes oscuros/heredados—excelente para casos de uso multilingüe o de borde | Sin datos específicos sobre soporte multilingüe—presumiblemente fuerte pero menos amplio | Qwen3-Coder |
| Longitud de Contexto | 256K tokens | Ventana de 128K tokens | Qwen3-Coder |
| Velocidad de Inferencia y Eficiencia | Mayor uso de VRAM; inferencia más lenta debido al requisito de 1050 GB | Más ligero (945 GB), más rápido y más eficiente en hardware | GLM 4.5 |
- Elija Qwen3-Coder si sus necesidades principales son:
- Escribir o refactorizar código Python puro (por ejemplo, notebooks, scripts, flujos de ML).
- Trabajar en muchos lenguajes o lenguajes de nicho (soporta 358).
- Manejar bases de código grandes o proyectos de Python que requieren contexto extendido (256K–1M tokens).
- Minimizar el costo por token—excelente para iteraciones frecuentes en Python.
- Elija GLM 4.5 si necesita:
- Integración confiable de herramientas, orquestación de API o flujos de trabajo agénticos con dependencias externas.
- Inferencia rápida y eficiente en el hardware disponible.
- Capacidades sólidas de razonamiento para depuración, explicación o tareas de lógica Python paso a paso.
Comparación de Qwen3 Coder y GLM 4.5 para Software
Crear un juego Tetris
Qwen 3 Coder
GLM 4.5
Construye una página web interactiva de Pokédex Pokémon que muestre los primeros 50 Pokémon, incluyendo sus animaciones y tipos.
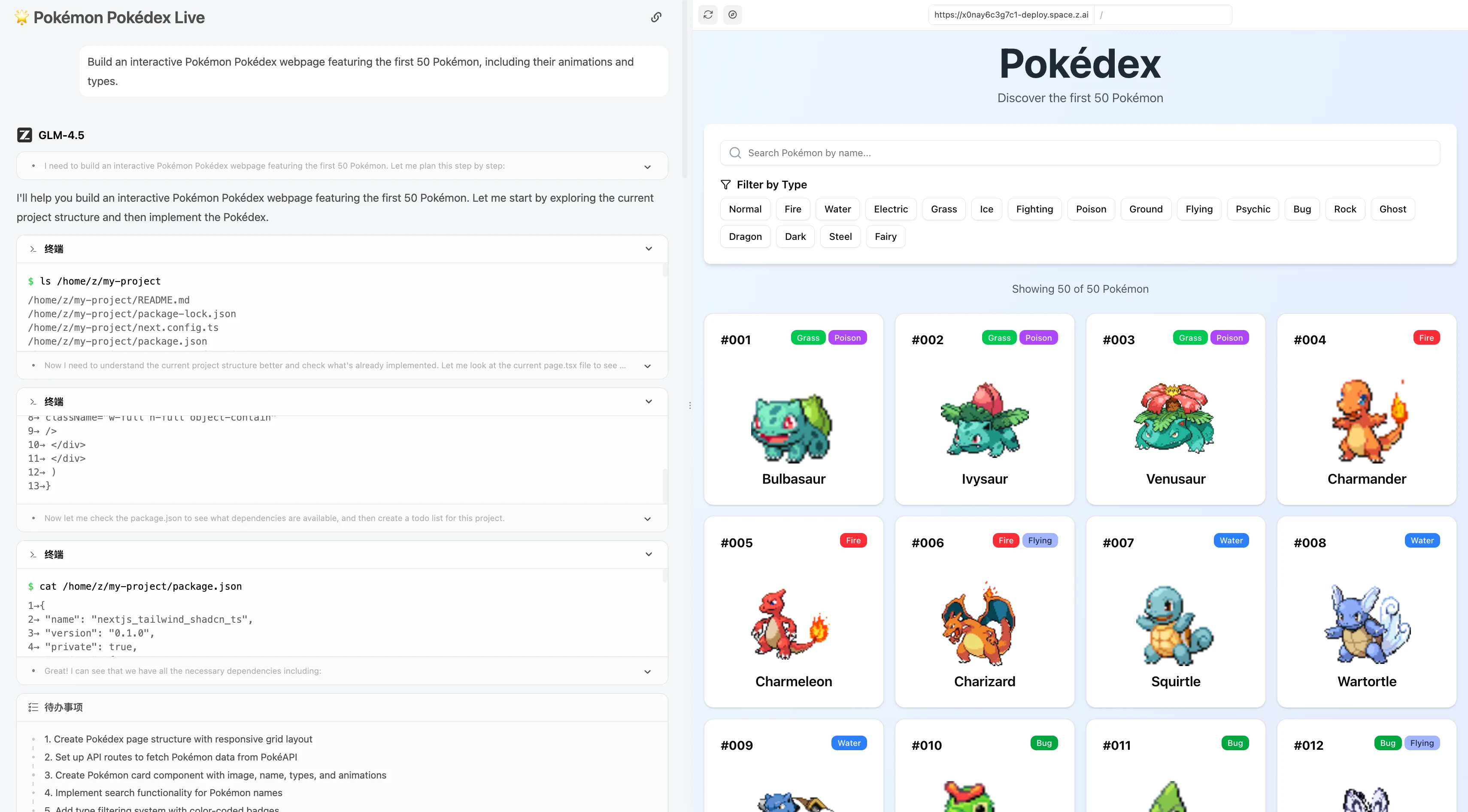
GLM 4.5
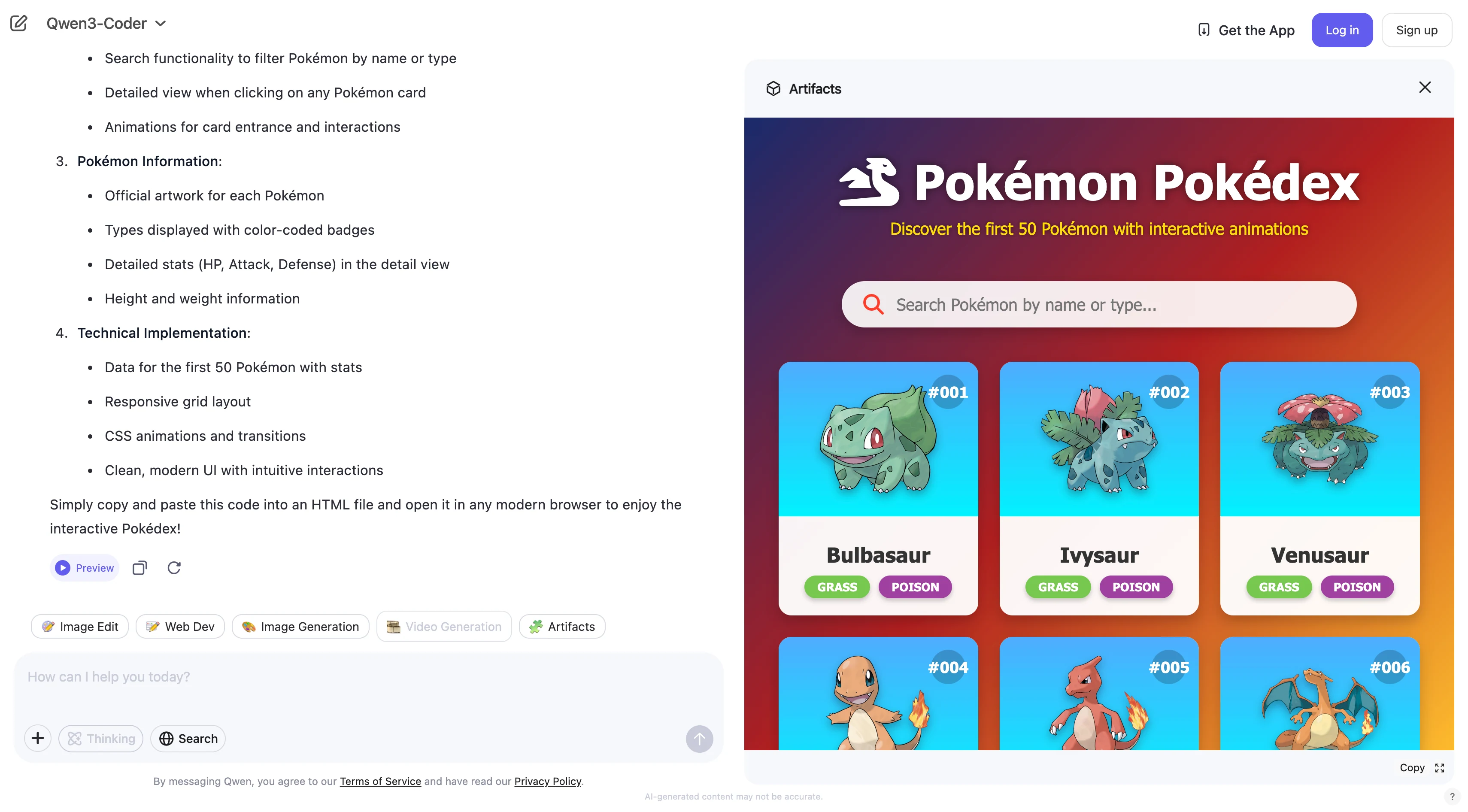
Qwen 3 coder
Cómo Acceder a Qwen 3 Coder 480B A35B Mediante Herramientas CLI?
https://www.youtube.com/watch?v=hsPzLalRnpc
- Más rápido: Puede usar Qwen3-Coder directamente desde la línea de comandos—sin necesidad de sitio web ni software adicional.
- Automatización más fácil: Es simple escribir scripts que usen Qwen3-Coder para tareas de programación.
- Se adapta al flujo de trabajo del desarrollador: La mayoría de los desarrolladores usan la línea de comandos, por lo que Qwen3-Coder se convierte en una parte natural del trabajo diario.
- Fácil de escalar: Puede procesar rápidamente muchos archivos o proyectos usando comandos CLI.
Lo Primero: Obtener una Clave API
Paso 1: Inicie sesión en su cuenta y haga clic en el botón Biblioteca de Modelos.

¡Pruebe el Modelo Qwen 3 Coder y GLM 4.5 Ahora!
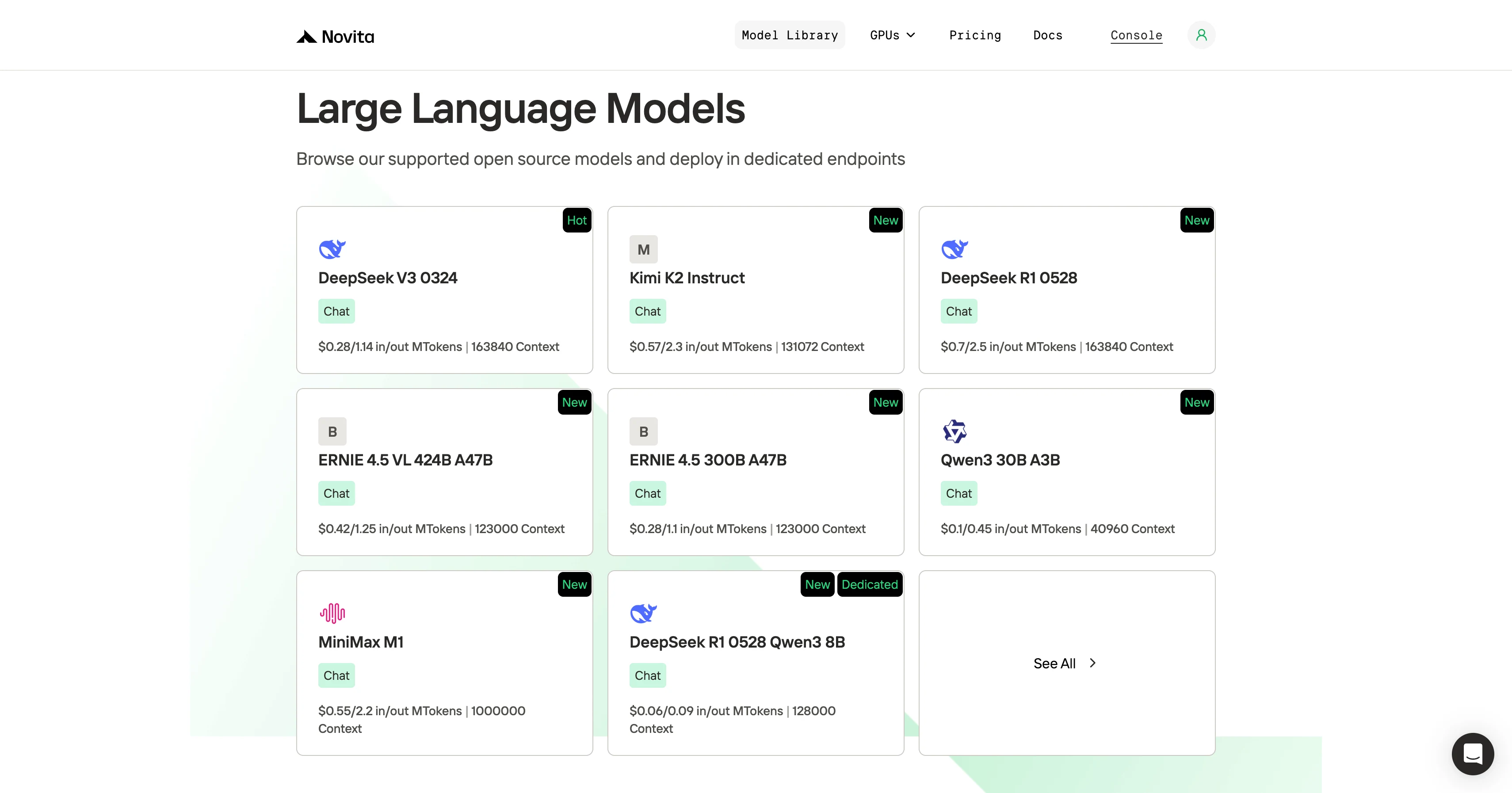
Paso 2: Elija su Modelo
Navegue por las opciones disponibles y seleccione el modelo que se ajuste a sus necesidades.
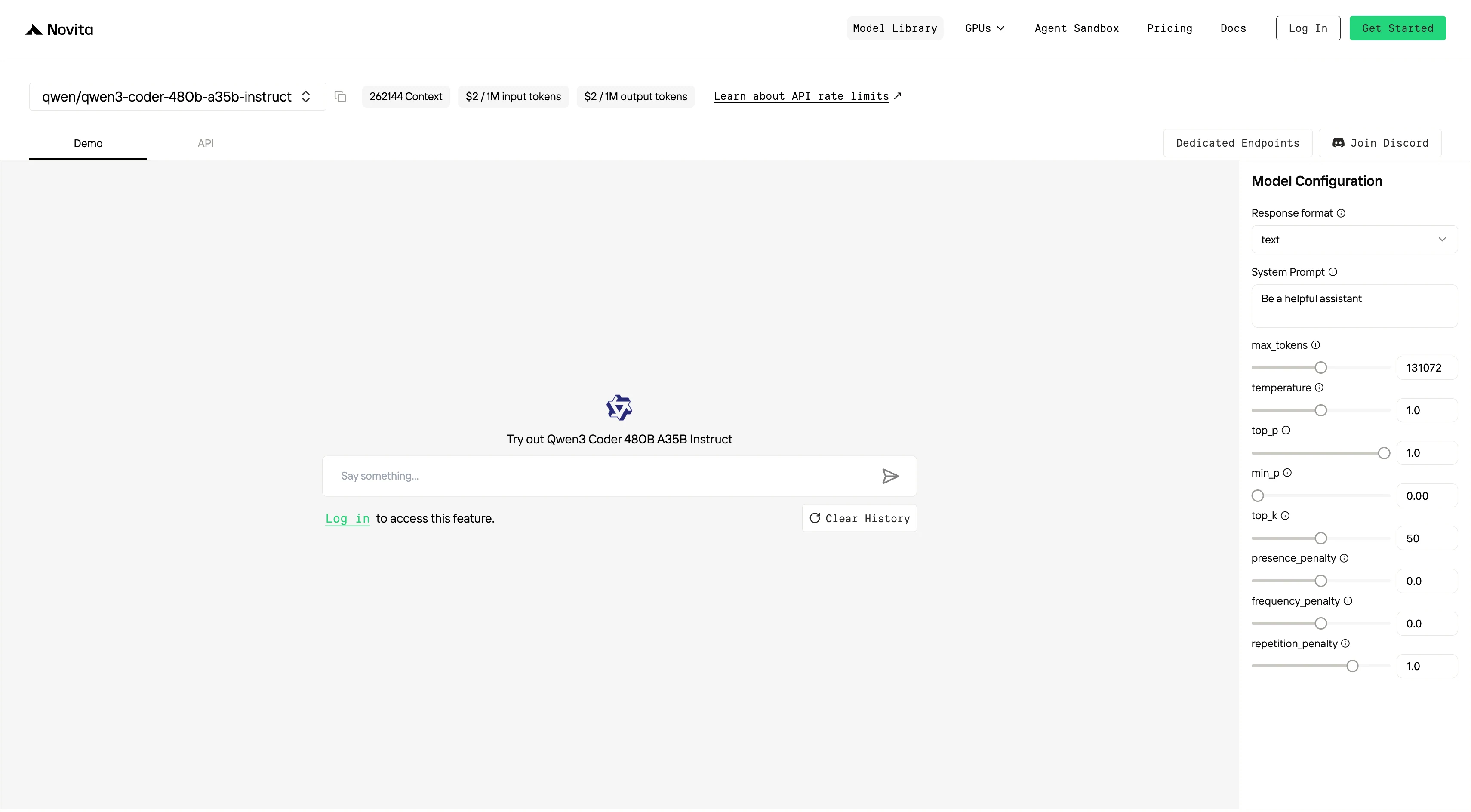
Paso 3: Inicie su Prueba Gratuita
Comience su prueba gratuita para explorar las capacidades del modelo seleccionado.
Paso 4: Obtenga su Clave API
Para autenticarse con la API, le proporcionaremos una nueva clave API. Ingrese a la página de “Configuración“, puede copiar la clave API como se indica en la imagen.

Paso 5: Instale la API
Instale la API usando el gestor de paquetes específico de su lenguaje de programación.
Después de la instalación, importe las bibliotecas necesarias en su entorno de desarrollo. Inicialice la API con su clave API para comenzar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de completado de chat para usuarios de Python.
pip install 'openai>=1.0.0'
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "qwen/qwen3-coder-480b-a35b-instruct"
stream = True # or False
max_tokens = 131072
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Qwen 3 Coder 480B A35B y GLM 4.5 con Trae
Paso 1: Abra Trae y Acceda a los Modelos
Inicie la aplicación Trae. Haga clic en el botón Alternar Barra Lateral de IA en la esquina superior derecha para abrir la Barra Lateral de IA. Luego, vaya a Gestión de IA y seleccione Modelos.

Paso 2: Añada un Modelo Personalizado y Elija Novita como Proveedor
Haga clic en el botón Añadir Modelo para crear una entrada de modelo personalizado. En el diálogo de añadir modelo, seleccione Proveedor = Novita del menú desplegable.


Paso 3: Seleccione o Ingrese el Modelo
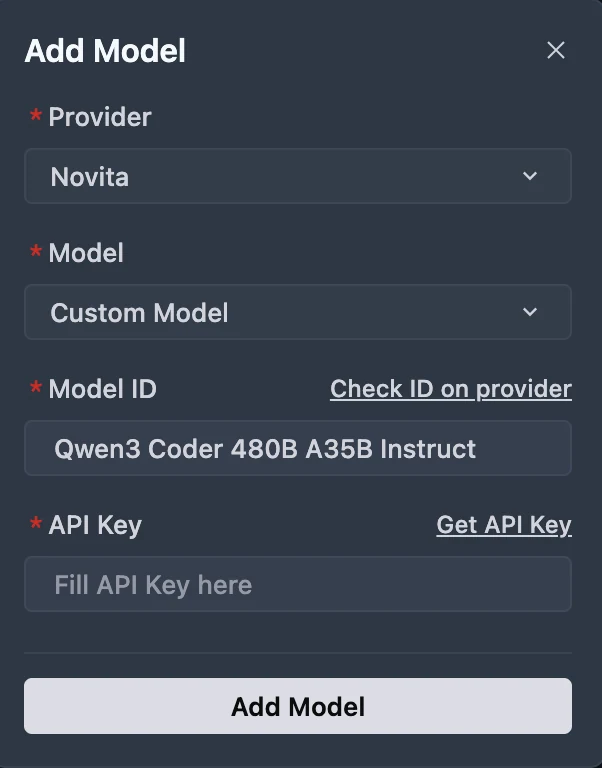
En el menú desplegable de Modelo, elija el modelo deseado (DeepSeek-R1-0528, Kimi K2 DeepSeek-V3-0324 o MiniMax-M1-80k). Si el modelo exacto no está listado, simplemente escriba el ID del modelo que anotó de la biblioteca de Novita. Asegúrese de elegir la variante correcta del modelo que desea usar.
Puede obtener una clave API en la consola de Novita!
Qwen 3 Coder 480B A35B y GLM 4.5 con Qwen Code
Qwen Code está desarrollado sobre Gemini Code, pero hemos adaptado los prompts y protocolos de llamada de herramientas para maximizar el rendimiento de Qwen3-Coder en tareas de codificación agénticas.
Paso 1: Instale Qwen Code
Requisitos previos: Asegúrese de tener Node.js versión 20 o superior instalado. Puede descargarlo desde el sitio web oficial de Node.js.
Instale el paquete globalmente:
npm install -g @qwen-code/qwen-code
Paso 2: Configure las Variables de Entorno
Para Windows (Símbolo del sistema):
set OPENAI_API_KEY=Your_Novita_API_Key
set OPENAI_BASE_URL=https://api.novita.ai/v3/openai
set OPENAI_MODEL=qwen/qwen3-coder-480b-a35b-instruct
Para Linux y Mac (Bash):
export OPENAI_API_KEY="Your_Novita_API_Key"
export OPENAI_BASE_URL="https://api.novita.ai/v3/openai"
export OPENAI_MODEL="qwen/qwen3-coder-480b-a35b-instruct"
Paso 3: Comience a Programar
Una vez configurado, puede comenzar a usar Qwen Code con el modelo Novita AI que haya elegido. La herramienta ahora utilizará el modelo especificado para todas las tareas de asistencia de codificación.
cd <directorio-de-su-proyecto>
qwen .
En tareas de codificación, ambos modelos brillan—pero de maneras diferentes:
- Qwen3-Coder es la opción más fuerte para rendimiento de programación pura: escribir y refactorizar Python, soportar lenguajes de nicho y manejar bases de código masivas gracias a su contexto de 256K–1M tokens y costos de token más bajos.
- GLM-4.5 se destaca cuando la programación se cruza con el razonamiento y la integración: es más rápido de ejecutar, más eficiente en recursos y domina en llamada de herramientas, lo que lo hace ideal para entornos de programación agénticos.
👉 Si está construyendo software dentro de bases de código enormes, elija Qwen3-Coder.
👉 Si está construyendo agentes de codificación inteligentes o aplicaciones impulsadas por API, elija GLM-4.5.
Preguntas Frecuentes
¿Qué modelo es mejor para programación en Python?
Qwen3-Coder lidera en benchmarks estándar de Python (HumanEval, MBPP, LiveCodeBench) y generalmente es preferido para notebooks, flujos de ML y automatización de scripts.
¿Qué modelo es mejor para código multilingüe o heredado?
Qwen3-Coder soporta 358 lenguajes de programación, lo que lo hace mejor para escenarios diversos o de casos extremos.
¿Qué modelo maneja la depuración y flujos de trabajo a escala de repositorio?
Qwen3-Coder sobresale en depuración multi-turno, ediciones de código grandes y tareas a escala de repositorio debido a su contexto ultra largo (256K–1M tokens).
Novita AI es la plataforma en la nube integral que impulsa sus ambiciones de IA. API integradas, serverless, instancias de GPU: las herramientas rentables que necesita. Elimine la infraestructura, comience gratis y haga realidad su visión de IA.
Lectura Recomendada
Llama 3.2 3B vs DeepSeek V3: Comparando Eficiencia y Rendimiento.
Cómo Acceder a ERNIE 4.5: Formas Sencillas a Través de Web, API y Código
Acceder a DeepSeek V3.1 en Trae: Guía Completa de Configuración e Integración



