

- Quais São as Principais Diferenças Arquiteturais Entre Qwen3 Coder e GLM 4.5?
- Resultados de Benchmark para Qwen3 Coder e GLM 4.5 em Tarefas de Geração de Código
- Comparação de Velocidade e Preço: Qwen3 Coder vs GLM 4.5 para Iniciantes
- Qwen3 Coder e GLM 4.5: Qual Modelo é Mais Eficiente em Termos de Recursos?
- Qwen3 Coder vs GLM 4.5: Qual é Melhor para Programação em Python?
- Comparação de Qwen3 Coder e GLM 4.5 para Software
- Como Acessar o Qwen 3 Coder 480B A35B por Ferramentas CLI?
- Qwen 3 Coder 480B A35B e GLM 4.5 com Trae
- Qwen 3 Coder 480B A35B e GLM 4.5 com Qwen Code
Quando se trata de codificação, nem todos os modelos de linguagem grandes são construídos da mesma forma. Dois dos concorrentes mais avançados—Qwen3-Coder (480B-A35B-Instruct) e GLM-4.5—adotam abordagens muito diferentes.
- Qwen3-Coder é um modelo especialista em código, treinado com ~70% de seus dados em programação. Ele suporta 358 linguagens de programação, alcança resultados de ponta em Python e é especialmente forte em depuração de múltiplas interações, edição de grandes bases de código e fluxos de trabalho em escala de repositório.
- GLM-4.5, por outro lado, é um generalista versátil. Embora ainda seja altamente capaz em código, sua verdadeira força está em fluxos de trabalho agentivos: orquestrar APIs, bancos de dados e ferramentas externas com uma taxa de sucesso de chamada de ferramentas de 90,6%, a mais alta entre os modelos atuais.
👉 Este artigo responderá à pergunta chave: Como Qwen3-Coder e GLM-4.5 realmente diferem no desempenho de codificação—e que tipo de desenvolvedor ou fluxo de trabalho é mais adequado para cada um?
A Novita AI, como um dos provedores mais importantes no campo de API de LLM, oferece APIs estáveis e altamente econômicas. Pelas informações de preços, podemos ver que Qwen3-Coder é ligeiramente mais barato que GLM 4.5.
- GLM-4.5: $0,60 por 1M de tokens de entrada / $2,20 por 1M de tokens de saída, com comprimento de contexto de 131.072 tokens.
- Qwen3-Coder (480B A35B Instruct): $0,35 por 1M de tokens de entrada / $1,50 por 1M de tokens de saída, com comprimento de contexto de 262.144 tokens.
Quais São as Principais Diferenças Arquiteturais Entre Qwen3 Coder e GLM 4.5?
https://www.youtube.com/watch?v=ulfZwEa1x\_o
| Característica | Qwen3-Coder (480B-A35B-Instruct) | GLM-4.5 |
|---|---|---|
| Arquitetura (MoE) | 480B parâmetros totais, ~35B ativos por inferência (8 de 160 especialistas) | 355B parâmetros totais, 32B ativos por inferência |
| Comprimento do Contexto | Suporte nativo para 262.144 tokens (≈256K) | Suporta até 128K de contexto com configuração de hardware adequada |
| Modos de Raciocínio | Suporta apenas modo sem pensamento; não gera blocos thinking response |
Raciocínio híbrido: modo “pensamento” (formalmente estilo cadeia de pensamento) e modo “sem pensamento” suportados |
Resultados de Benchmark para Qwen3 Coder e GLM 4.5 em Tarefas de Geração de Código
| Benchmark / Cenário | Qwen3-Coder | GLM 4.5 |
|---|---|---|
| SWE-Bench Verified | 67,0 % | 64,2 % |
| SciCode (Codificação) | 36% | 35% |
| LiveCodeBench (Codificação) | 59% | 74% |
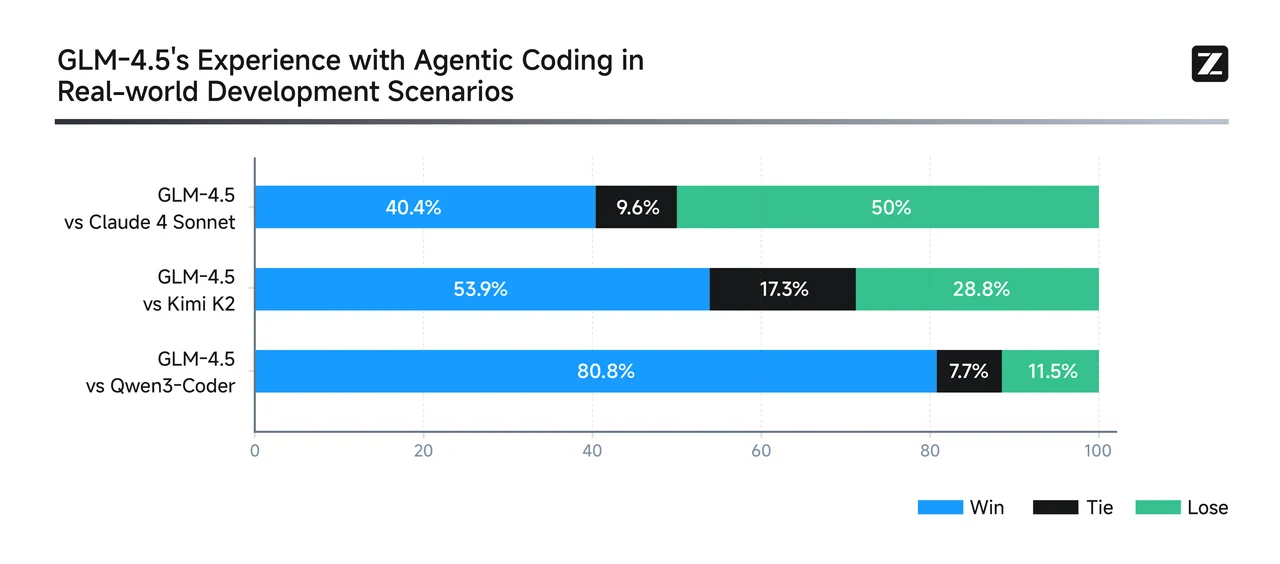
Fonte: GLM
Qwen3-Coder se destaca em fluxos de código agentivos de múltiplas interações—especialmente em depuração em estilo de mundo real e tarefas de integração de ferramentas. Ele alcança resultados de classe mundial para modelos open-source e é competitivo com sistemas proprietários de ponta. Para correções de bugs em escala de repositório, edições de múltiplos arquivos e fluxos de trabalho agentivos automatizados de ferramentas: Qwen3-Coder é provavelmente a escolha mais forte.
GLM-4.5 é um generalista versátil—classificando-se alto em benchmarks de raciocínio, codificação e agentivos. Ele suporta modos de raciocínio híbridos e oferece desempenho robusto em múltiplos domínios, mantendo uma forte presença no SWE-Bench. Para tarefas equilibradas que abrangem raciocínio, codificação e integração de ferramentas—com necessidades moderadas de contexto: GLM-4.5 oferece um desempenho atraente em vários domínios.
Comparação de Velocidade e Preço: Qwen3 Coder vs GLM 4.5 para Iniciantes
| Modelo | VRAM | GPU Recomendada |
| Qwen 3 Coder | 1050GB | 8 x H100 NVL |
| GLM 4.5 | 945GB | 8 x H100 NVL |
Embora ambos precisem da mesma classe de GPUs, o GLM 4.5 roda mais rápido e de forma mais eficiente devido à sua menor pegada de VRAM, enquanto o Qwen3-Coder é mais pesado e mais lento nas mesmas condições.
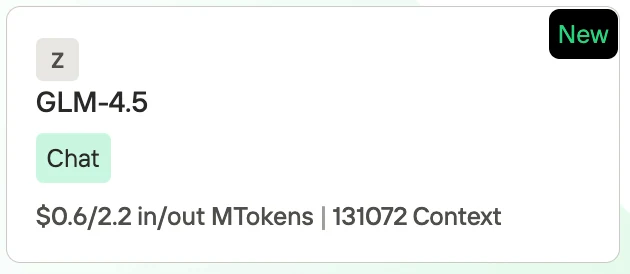
Preço do GLM 4.5
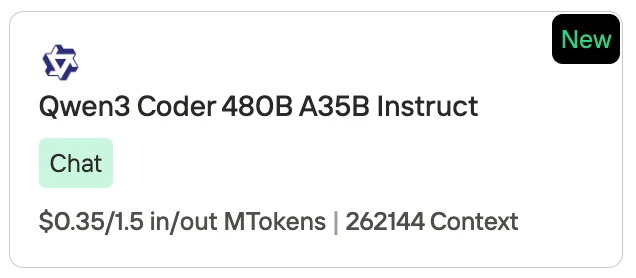
Preço do Qwen 3 Coder
A Novita AI, como um dos provedores mais importantes no campo de API de LLM, oferece APIs estáveis e altamente econômicas. Pelas informações de preços, podemos ver que Qwen3-Coder é ligeiramente mais barato que GLM 4.5.
- GLM-4.5: $0,60 por 1M de tokens de entrada / $2,20 por 1M de tokens de saída, com comprimento de contexto de 131.072 tokens.
- Qwen3-Coder (480B A35B Instruct): $0,35 por 1M de tokens de entrada / $1,50 por 1M de tokens de saída, com comprimento de contexto de 262.144 tokens.
Qwen3 Coder e GLM 4.5: Qual Modelo é Mais Eficiente em Termos de Recursos?
| Aspecto | Qwen3-Coder (480B A35B) | GLM 4.5 (355B) | Modelo Mais Eficiente |
|---|---|---|---|
| Requisito de VRAM | ~1050 GB, precisa de 8× H100 NVL | ~945 GB, precisa de 8× H100 NVL | GLM 4.5 (≈10% mais leve) |
| Velocidade de Inferência | Mais lento devido à maior pegada de memória | Mais rápido, menor latência no mesmo hardware | GLM 4.5 |
| Capacidade de Contexto | 262K tokens (extensível para 1M) | 131K tokens | Qwen3-Coder |
| Preço (Novita AI) | $0,35 por 1M de entrada / $1,50 por 1M de saída | $0,60 por 1M de entrada / $2,20 por 1M de saída | Qwen3-Coder |
| Especialização | 70% dos dados de treinamento em código; otimizado para tarefas de codificação em grande escala | Mistura equilibrada de raciocínio, codificação e tarefas agentivas | Depende do caso de uso |
| Eficiência Geral | Eficiente para custo e uso de contexto longo | Eficiente para hardware e velocidade | Dividido: Qwen3 para custo/contexto, GLM 4.5 para computação/velocidade |
- GLM 4.5 é mais eficiente em recursos quando falamos de hardware (VRAM, velocidade, latência) .
- Qwen3-Coder é mais eficiente em termos de custo de token e manipulação de contexto massivo.
👉 Na prática:
- Escolha GLM 4.5 se você se importa com inferência mais rápida e carga computacional mais leve.
- Escolha Qwen3-Coder se você precisa de tokens mais baratos e janelas de contexto ultra-longas para grandes bases de código.
Qwen3 Coder vs GLM 4.5: Qual é Melhor para Programação em Python?
| Aspecto | Qwen3-Coder | GLM 4.5 | Recomendação |
|---|---|---|---|
| Benchmarks de Codificação Python (HumanEval, MBPP, LCB) | Bom desempenho; relatos de usuários e avaliações sugerem domínio em benchmarks Python padrão | Também tem bom desempenho, mas ligeiramente atrás na geração de código Python puro | Qwen3-Coder |
| Tarefas Agentivas / Chamada de Ferramentas | 77,1% | 90,6% | GLM 4.5—ideal para fluxos de trabalho envolvendo chamadas de API, ferramentas externas ou interações complexas |
| Linguagens de Programação Suportadas | Suporta 358 linguagens, incluindo Python e obscuras/legadas—ótimo para casos de uso multilíngue ou de borda | Não há dados específicos sobre suporte a múltiplas linguagens—presumivelmente forte, mas menos abrangente | Qwen3-Coder |
| Comprimento do Contexto | 256K tokens | Janela de 128K tokens | Qwen3-Coder |
| Velocidade e Eficiência de Inferência | Uso mais pesado de VRAM; inferência mais lenta devido ao requisito de 1050 GB | Mais leve (945 GB), mais rápido e mais eficiente em hardware | GLM 4.5 |
- Escolha Qwen3-Coder se suas principais necessidades são:
- Escrever ou refatorar código Python puro (por exemplo, notebooks, scripts, fluxos de ML).
- Trabalhar com muitas ou nicho linguagens (suporta 358).
- Lidar com grandes bases de código ou projetos Python que exigem contexto estendido (256K–1M tokens).
- Minimizar custo por token—ótimo para iterações frequentes em Python.
- Escolha GLM 4.5 se você precisa de:
- Integração confiável de ferramentas, orquestração de API ou fluxos de trabalho agentivos com dependências externas.
- Inferência de alta velocidade e eficiente no hardware disponível.
- Fortes capacidades de raciocínio para depuração, explicação ou tarefas de lógica Python passo a passo.
Comparação de Qwen3 Coder e GLM 4.5 para Software
Criar um jogo Tetris
Qwen 3 Coder
GLM 4.5
Construir uma página web interativa de Pokédex com os primeiros 50 Pokémon, incluindo suas animações e tipos.
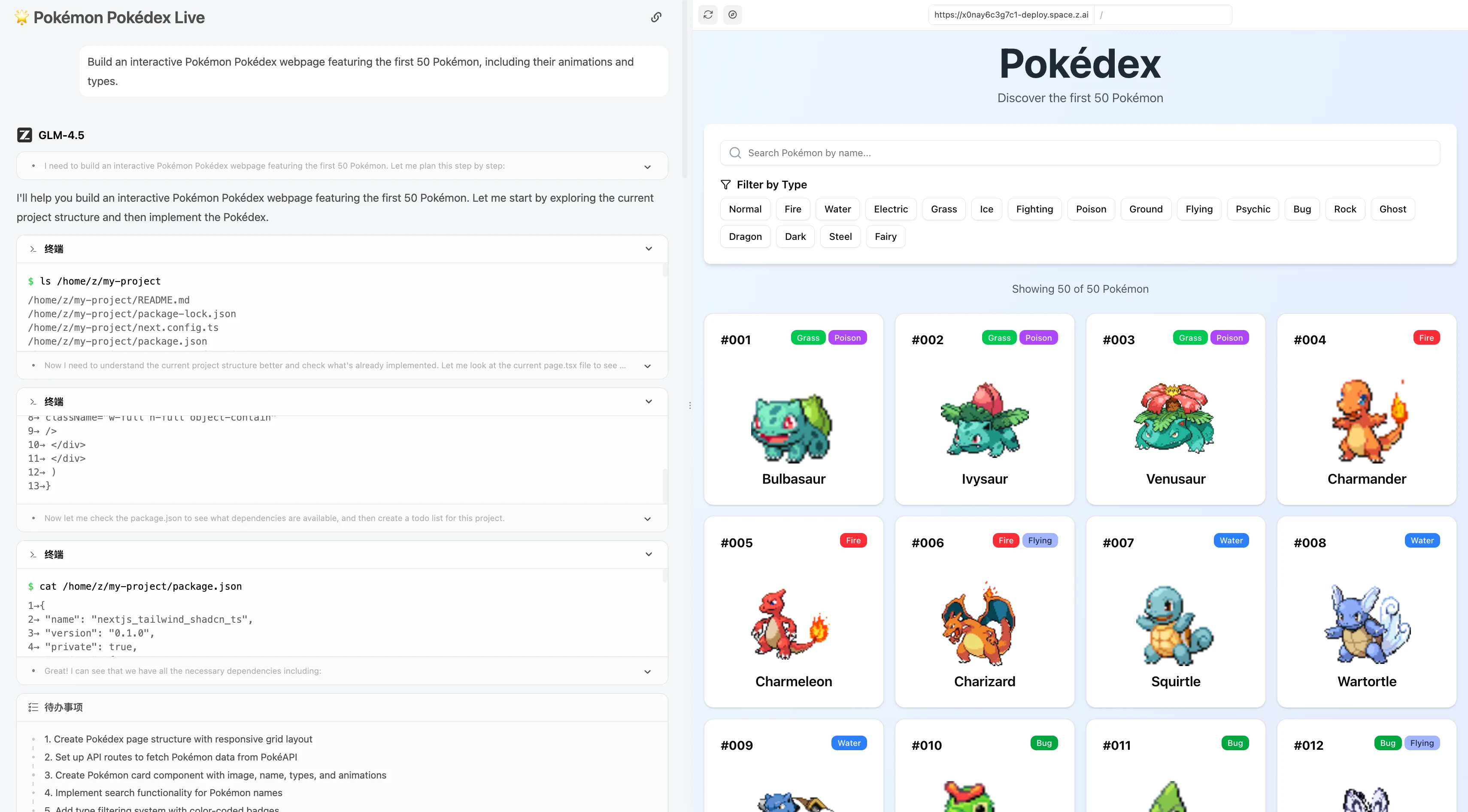
GLM 4.5
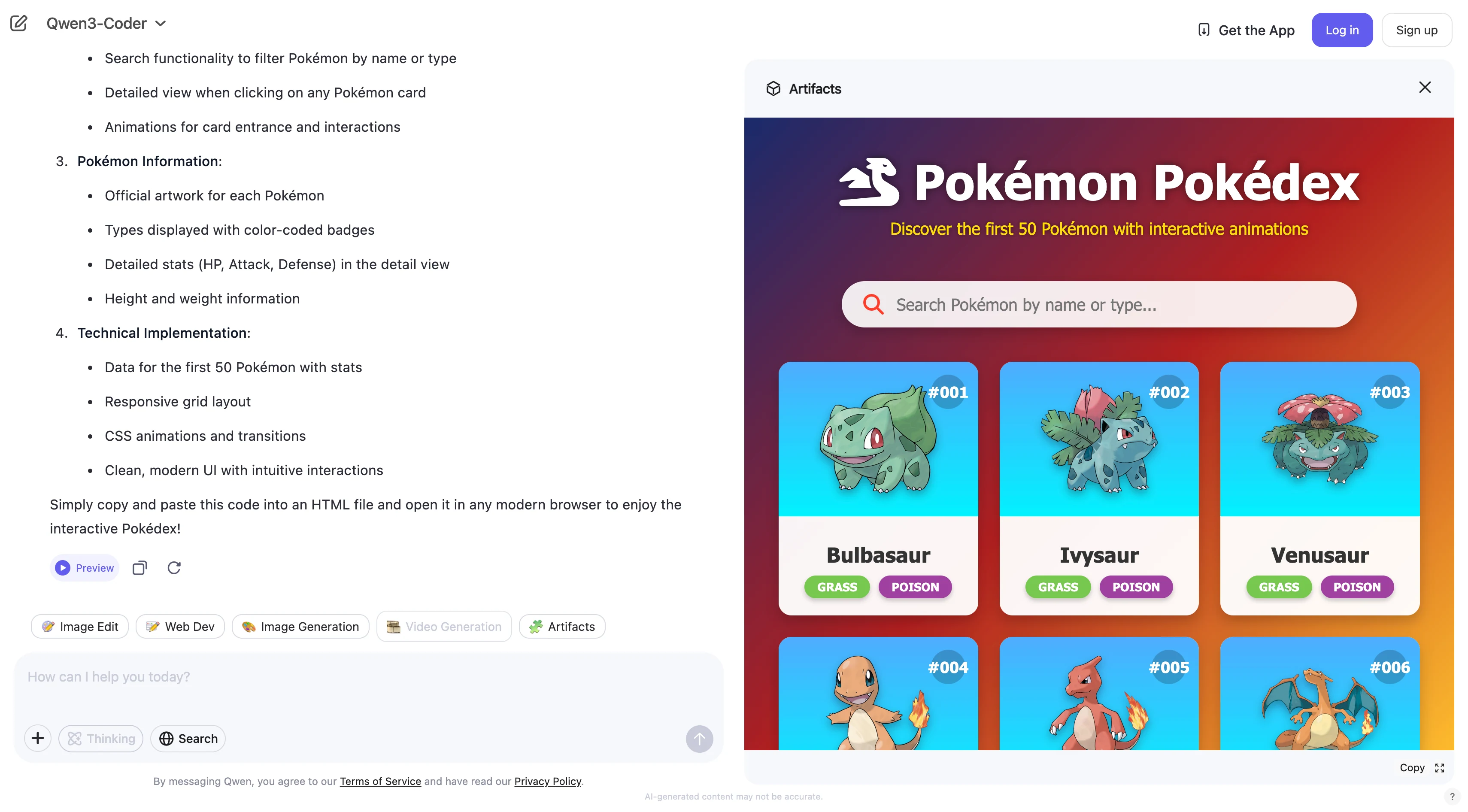
Qwen 3 coder
Como Acessar o Qwen 3 Coder 480B A35B por Ferramentas CLI?
https://www.youtube.com/watch?v=hsPzLalRnpc
- Mais rápido: Você pode usar o Qwen3-Coder diretamente da linha de comando—sem site ou software extra.
- Automação mais fácil: É simples escrever scripts que usam o Qwen3-Coder para tarefas de codificação.
- Adequa-se ao fluxo de trabalho do desenvolvedor: A maioria dos desenvolvedores usa a linha de comando, então o Qwen3-Coder se torna uma parte natural do trabalho diário.
- Fácil de escalar: Você pode processar rapidamente muitos arquivos ou projetos usando comandos CLI.
Primeiro: Obter Chave de API
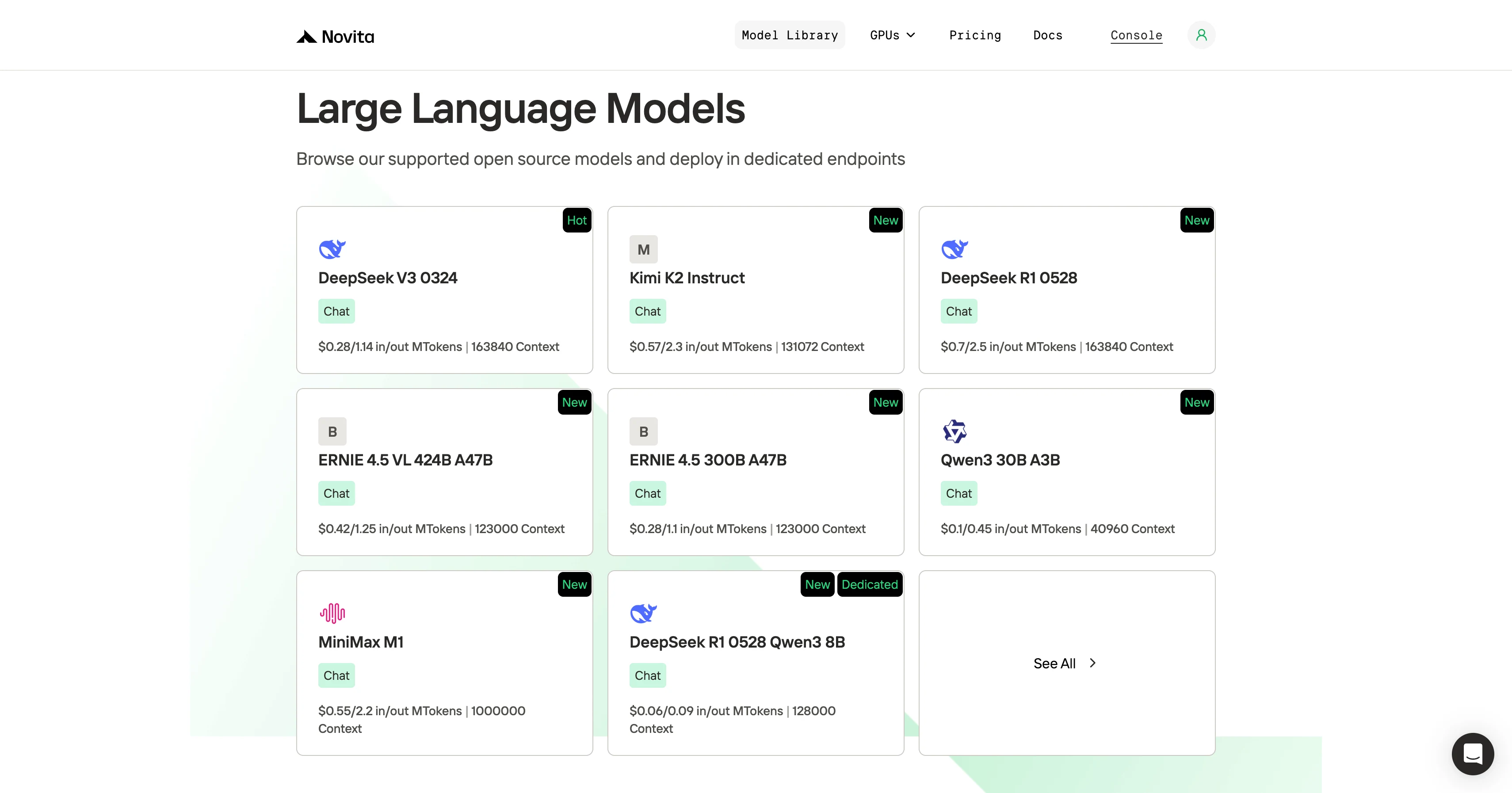
Passo 1: Faça login na sua conta e clique no botão Model Library.

Experimente o Modelo Qwen 3 Coder e o GLM 4.5 Agora!
Passo 2: Escolha Seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.
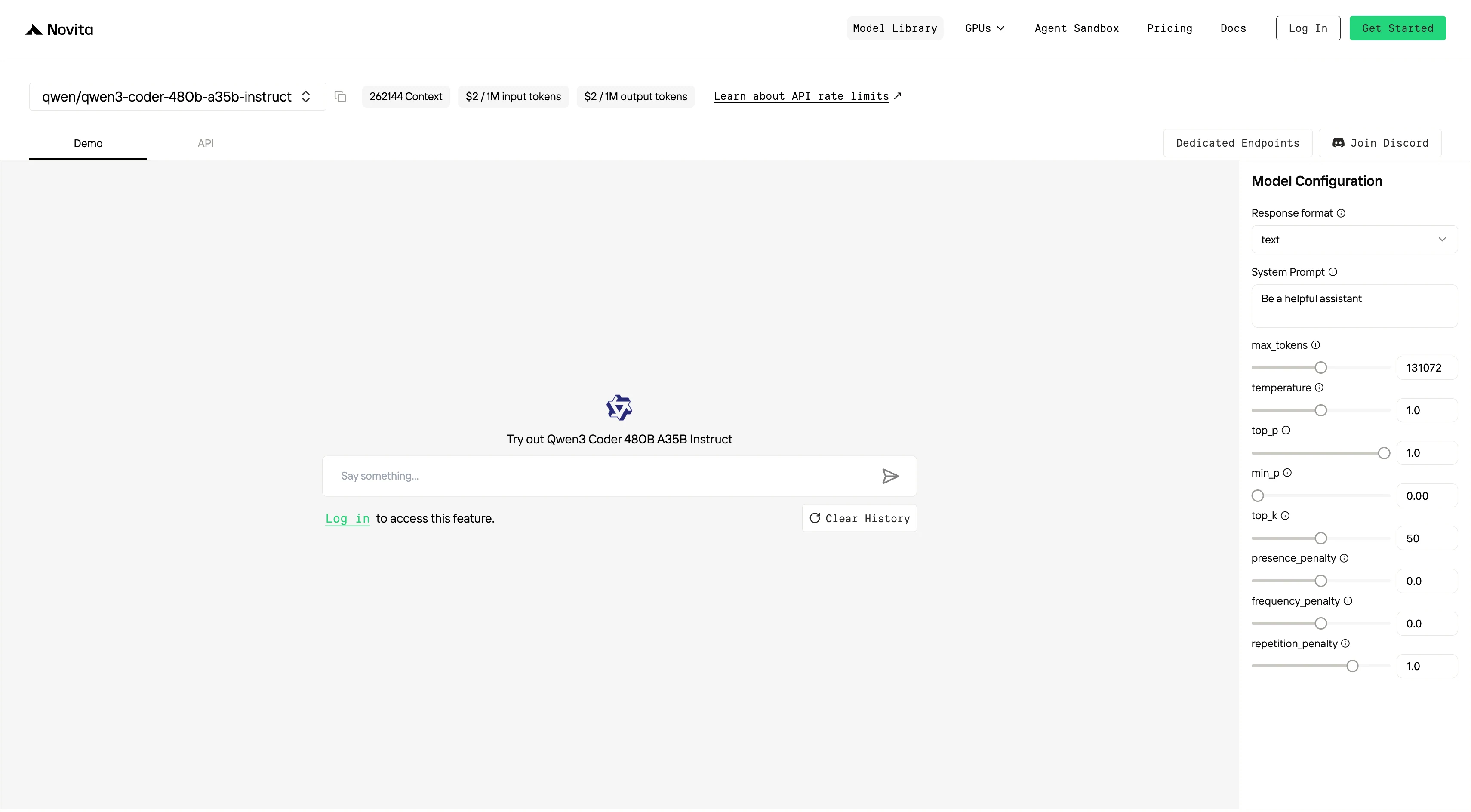
Passo 3: Inicie Seu Teste Gratuito
Comece seu teste gratuito para explorar as capacidades do modelo selecionado.
Passo 4: Obtenha Sua Chave de API
Para autenticar com a API, forneceremos uma nova chave de API. Entrando na página “Settings”, você pode copiar a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico para sua linguagem de programação.
Após a instalação, importe as bibliotecas necessárias para seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o LLM Novita AI. Este é um exemplo de uso da API de chat completions para usuários Python.
pip install 'openai>=1.0.0'
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "qwen/qwen3-coder-480b-a35b-instruct"
stream = True # or False
max_tokens = 131072
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Qwen 3 Coder 480B A35B e GLM 4.5 com Trae
Passo 1: Abra o Trae e Acesse os Modelos
Inicie o aplicativo Trae. Clique no Toggle AI Side Bar no canto superior direito para abrir a Barra Lateral de IA. Em seguida, vá para AI Management e selecione Models.
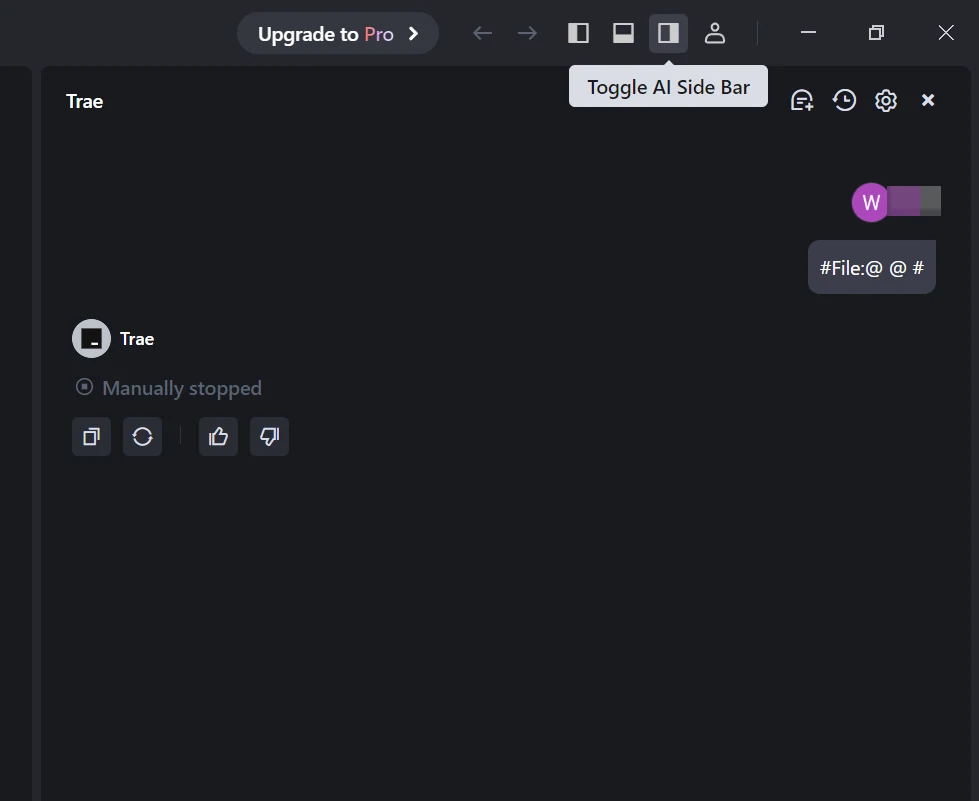

Passo 2: Adicione um Modelo Personalizado e Escolha Novita como Provedor
Clique no botão Add Model para criar uma entrada de modelo personalizada. No diálogo de adicionar modelo, selecione Provider = Novita no menu suspenso.


Passo 3: Selecione ou Insira o Modelo
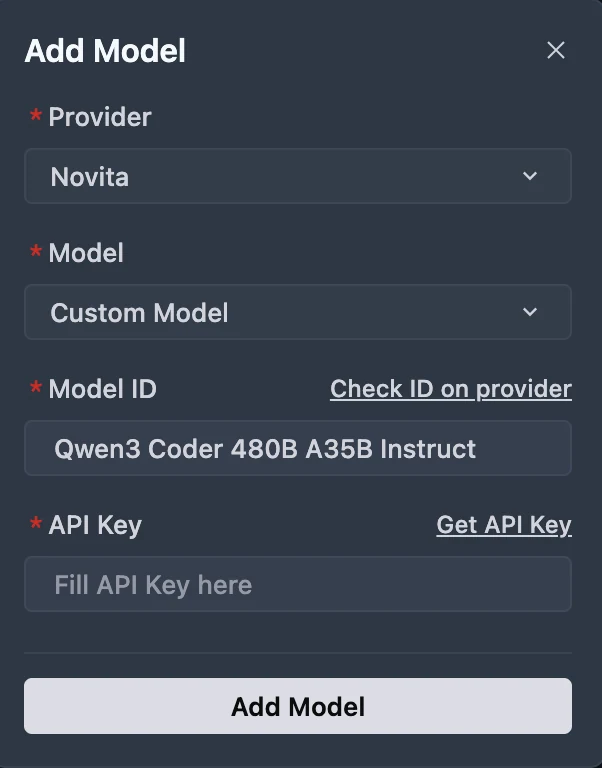
No menu suspenso Model, escolha o modelo desejado (DeepSeek-R1-0528, Kimi K2 DeepSeek-V3-0324, ou MiniMax-M1-80k). Se o modelo exato não estiver listado, basta digitar o ID do modelo que você anotou da biblioteca Novita. Certifique-se de escolher a variante correta do modelo que deseja usar.
Você pode obter a Chave de API no console Novita!
Qwen 3 Coder 480B A35B e GLM 4.5 com Qwen Code
O Qwen Code é desenvolvido sobre o Gemini Code, mas adaptamos os prompts e protocolos de chamada de ferramentas para maximizar o desempenho do Qwen3-Coder em tarefas de codificação agentivas.
Passo 1: Instale o Qwen Code
Pré-requisitos: Certifique-se de ter o Node.js versão 20 ou superior instalado. Você pode baixá-lo do site oficial do Node.js.
Instale o pacote globalmente:
npm install -g @qwen-code/qwen-code
Passo 2: Configure as Variáveis de Ambiente
Para Windows (Command Prompt):
set OPENAI_API_KEY=Your_Novita_API_Key
set OPENAI_BASE_URL=https://api.novita.ai/v3/openai
set OPENAI_MODEL=qwen/qwen3-coder-480b-a35b-instruct
Para Linux e Mac (Bash):
export OPENAI_API_KEY="Your_Novita_API_Key"
export OPENAI_BASE_URL="https://api.novita.ai/v3/openai"
export OPENAI_MODEL="qwen/qwen3-coder-480b-a35b-instruct"
Passo 3: Comece a Codificar
Uma vez configurado, você pode começar a usar o Qwen Code com o modelo Novita AI escolhido. A ferramenta agora utilizará o modelo especificado para todas as tarefas de assistência à codificação.
cd <seu-diretório-do-projeto>
qwen .
Em tarefas de codificação, ambos os modelos brilham—mas de maneiras diferentes:
- Qwen3-Coder é a escolha mais forte para desempenho de codificação pura: escrever e refatorar Python, suportar linguagens de nicho e lidar com grandes bases de código graças ao seu contexto de 256K–1M tokens e custos de token mais baixos.
- GLM-4.5 se destaca quando a codificação se cruza com raciocínio e integração: é mais rápido de rodar, mais eficiente em recursos e domina em chamada de ferramentas, tornando-o ideal para ambientes de programação agentivos.
👉 Se você está construindo software dentro de grandes bases de código, escolha Qwen3-Coder.
👉 Se você está construindo agentes de codificação inteligentes ou aplicações orientadas por API, escolha GLM-4.5.
Perguntas Frequentes
Qual modelo é melhor para programação em Python?
O Qwen3-Coder lidera em benchmarks padrão de Python (HumanEval, MBPP, LiveCodeBench) e é geralmente preferido para notebooks, fluxos de ML e automação de scripts.
Qual modelo é melhor para código multilíngue ou legado?
O Qwen3-Coder suporta 358 linguagens de programação, tornando-o melhor para cenários de desenvolvimento diversos ou de borda.
Qual modelo lida com depuração e fluxos de trabalho em escala de repositório?
O Qwen3-Coder se destaca em depuração de múltiplas interações, grandes edições de código e tarefas em escala de repositório devido ao seu contexto ultra-longo (256K–1M tokens).
Novita AI é a plataforma tudo-em-um na nuvem que impulsiona suas ambições de IA. APIs integradas, serverless, Instância GPU — as ferramentas econômicas que você precisa. Elimine infraestrutura, comece de graça e torne sua visão de IA realidade.
Leitura Recomendada
Llama 3.2 3B vs DeepSeek V3: Comparando Eficiência e Desempenho.
Como Acessar o ERNIE 4.5: Maneiras Simples via Web, API e Código
Acesse o DeepSeek V3.1 no Trae: Guia Completo de Configuração e Integração



