

NVIDIAの H200 SXM と RTX 5090 は、それぞれのクラスで最も強力なGPUの一つですが、AIエコシステムにおいてはまったく異なる目的を果たします。RTX 5090は高速な推論と小規模なファインチューニングに優れている一方、H200 SXMはデータセンターにおける大規模なトレーニングとマルチGPU展開に最適化されています。
この記事では、両GPUをアーキテクチャ、メモリ、パフォーマンス、コストの観点から比較し、あなたのワークロードに本当にデータセンター向けGPUが必要なのか、それとも1台のRTX 5090でAIの目標を達成できるのかを判断するのに役立てます。
H200 vs 5090: 詳細スペック
| 詳細 | H200 SXM | RTX 5090 |
| 発売日 | 2024年11月18日 | 2025年1月30日 |
| アーキテクチャ | Hopper | Blackwell |
| GPUメモリ | 141 GB HBM3e | 32 GB GDDR7 |
| メモリインターフェース | 6144-bit | 512-bit |
| メモリ帯域幅 | 4.8 TB/s | 1.792 TB/s |
| NVIDIA デコーダー | 7x NVDEC & 7x JPEG | 3x 第9世代 |
| CUDAコア | 16896 | 21760 |
| Tensorコア | 528 | 680 |
| 最大グラフィックス電力 | 最大 700W | 575W |
H200 vs 5090: 総合パフォーマンスレビュー
NVIDIA H200 SXM と RTX 5090 は、根本的に異なる市場を対象としています。RTX 5090はコンシューマおよびクリエイター向けワークロードを新たな高みへ押し上げるように設計されているのに対し、H200 SXMはスループット、メモリ容量、クラスター展開が重要なデータセンター規模のAI向けに特化して構築されています。
賢く選択するには、各GPUの強みが実際のワークロード要件とどのように一致するかを評価することが不可欠です。
🟩 RTX 5090: トップクラスのコンシューマ向けGPU
愛好家、開発者、クリエイター向けに設計されたRTX 5090は、生の速度、柔軟性、幅広いアプリケーションカバレッジに重点を置いています。モデルがコンシューマ向けGPUのメモリ予算内に収まる限り、高速なイテレーションとAI実験を可能にします。
- ローカルプロトタイピングの最大スループット
超ワイドなメモリ帯域幅と強力なTensor/RTコアにより、高速なモデルイテレーション、レンダリング、複合的なクリエイティブAIワークフローに優れています。- ハイエンドAIへの手頃な入り口
コンシューマクラスのGPUとして、エンタープライズインフラなしで最先端の計算能力を求めるユーザーに、優れた価格性能比を提供します。- 一貫したリアルタイム応答性
RTX 5090の高いクロック速度と効率的なアーキテクチャは、安定したフレーム生成と素早い推論サイクルを実現し、レイテンシが重要なテストやライブクリエイティブセッションに最適です。- 効率的なAI開発とデプロイメント
RTX 5090はローカルでのファインチューニング、推論、モデル最適化を効率的に行えるため、複雑なクラウドインフラに依存せずにAIワークロードをシームレスに反復し、スケールさせることができます。
🟦 H200 SXM: ハイエンドエンタープライズAI GPU
ミッションクリティカルなデータセンター展開向けに設計されたH200は、最新の生成AIシステムにおいて、メモリ容量、スループット効率、マルチGPUスケーラビリティを優先しています。
- プロダクショングレードモデルのための大容量メモリ
141GBのHBM3eを搭載し、大規模言語モデル、高密度検索、長文脈推論をシャーディングのオーバーヘッドを最小限に抑えて処理します。- 高信頼性エンタープライズパフォーマンス
一貫したアップタイム、熱効率、およびミッションクリティカルなワークロードのための厳密に制御されたエラー訂正を実現するよう設計されています。- クラスター効率の最大化
NVLinkと第5世代NVSwitchは、複数のGPU間での高帯域幅インターコネクトをサポートし、分散トレーニングやLLMのスケーリングに最適です。- FP8 & Transformer Engineの最適化
最先端の生成AIを加速し、最適化されたフレームワーク(NVIDIA NIM、TensorRT-LLM)で優れたトレーニングおよび推論スループットを実現します。
まとめ
- RTX 5090 → ローカルワークフローにおいて速度、柔軟性、費用対効果を優先する個人や小規模チームに最適。迅速なプロトタイピングやクリエイティブAIに理想的です。
- H200 SXM → 大規模展開や24時間365日の安定性のために、拡張性、大容量メモリ、超高信頼性の計算能力を必要とするエンタープライズAI環境に最適です。
どちらを選ぶべきか?
RTX 5090とH200 SXMの選択は、最終的にはあなたのデプロイ環境、予算、モデルの規模に依存します。単なる性能スコアだけではありません。
ローカルで実行予定のモデルはどの程度の規模ですか?
モデルの重み(KVキャッシュとアクティベーションを含む)が32GBのVRAMに収まる(または量子化により収まるようにできる)場合、RTX 5090は優れたローカルソリューションです。
それを超える場合、または高スループットの分散コンピューティングが必要な場合、H200 SXMはその規模に合わせて設計されています。
🔍 クイック判断ガイド
| あなたのニーズ / ユースケース | 推奨GPU | 理由 |
|---|---|---|
| 高速なイテレーション、ローカルAIプロトタイピング、クリエイティブワークロード | RTX 5090 | 優れた価格性能比+幅広いワークロードサポート |
| 7B~14BパラメータのFP16モデル、または30Bの量子化モデル | RTX 5090 | 32GB VRAMで中規模LLMのほとんどに十分 |
| 70B以上のLLM、長文脈推論 | H200 SXM | 141GB HBM3eによりモデル全体+KVキャッシュを常駐可能 |
| ミッションクリティカルな本番展開 | H200 SXM | エンタープライズグレードの信頼性、ECCメモリ、熱制御 |
| NVLinkを使用したマルチGPUスケーリングとクラスター | H200 SXM | 並列トレーニングと分散ワークロード向けに設計 |
| 高並行性と高スループット | H200 SXM | データセンターワークロード向けに最適化 |
H200 vs 5090: 価格
| GPU | 標準価格 | 備考 |
|---|---|---|
| RTX 5090 | 約 US$1,999(希望小売価格) | コンシューマ向けグラフィックカード、32GB GDDR7メモリ、ゲーマー&クリエイター向け |
| H200 SXM(単体GPU) | 1 ユニットあたり US$30,000~US$40,000 | データセンター向けGPU、141GB HBM3eメモリ、大規模AI展開向け |
| H200シリーズ(ボード/システム) | 4-GPUボード約 US$175,000、 8-GPUボード約 US$308,000~315,000 |
複数のH200ユニット、NVLink/NVSwitchボード、サーバーインフラを含むマルチGPUシステム全体 |
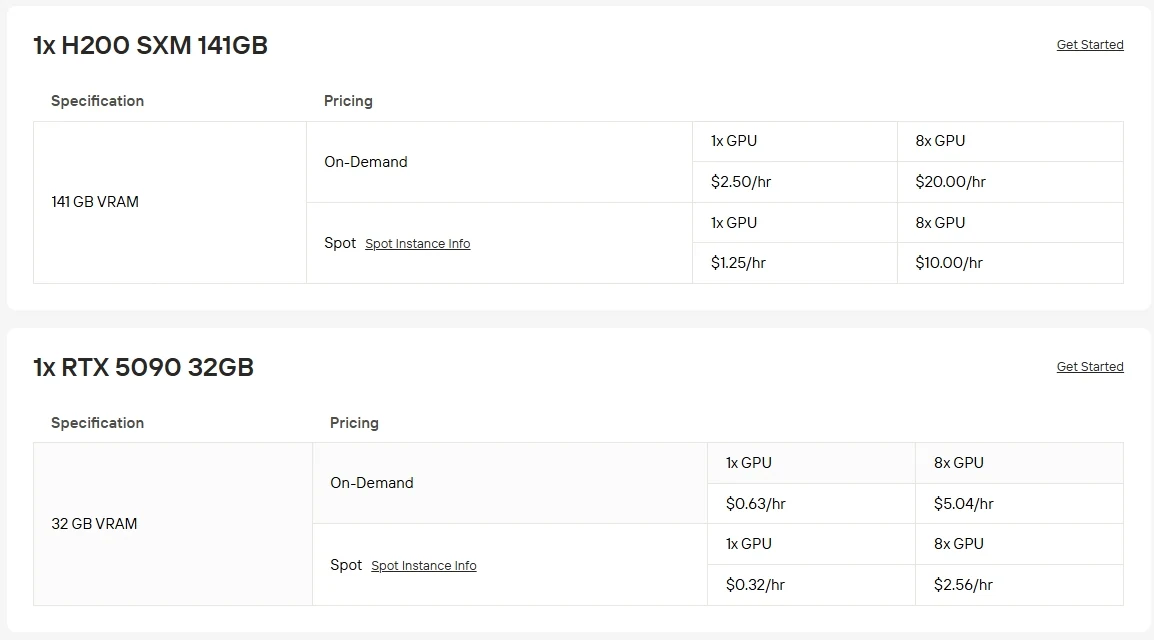
トップクラスのGPUを自前のハードウェアで運用するのは高額でメンテナンスも困難です。Novita AIのGPUインスタンスサービスを使えば、RTX 5090 をわずか $0.63/hr、H200 SXM を $2.5/hr でクラウド上に迅速に立ち上げることができ、ローカルでのセットアップは不要です。また、複数の課金オプションから選択可能です。スポットインスタンスは変動する空き容量で低価格、オンデマンドは使用時のみの支払い、サブスクリプションプランは安定した長期ワークロード向けの一貫した割引を提供します。
Novita AIで柔軟なGPUインスタンスを始めよう
Novita AIは、クラウド上で拡張可能なRTX 5090およびH200 GPUリソースを提供し、負荷の高いコンピューティングワークロードのために高価なハードウェアを購入・管理する必要をなくします。
ステップ1:アカウント登録
ウェブサイトからNovita AIアカウントを作成します。登録後、「GPU」タブに移動して利用可能なリソースを確認し、旅を始めましょう。
ステップ2:GPUを選択
多様なニーズに合わせて、あらかじめ設定された複数のテンプレートを提供しており、カスタムテンプレートを柔軟に作成することも可能です。十分なVRAMとRAMを備えた強力なRTX 5090およびRTX 6000 Ada GPUにアクセスでき、非常に複雑なAIモデルでも効率的なトレーニングを実現します。
プリセットテンプレートライブラリ
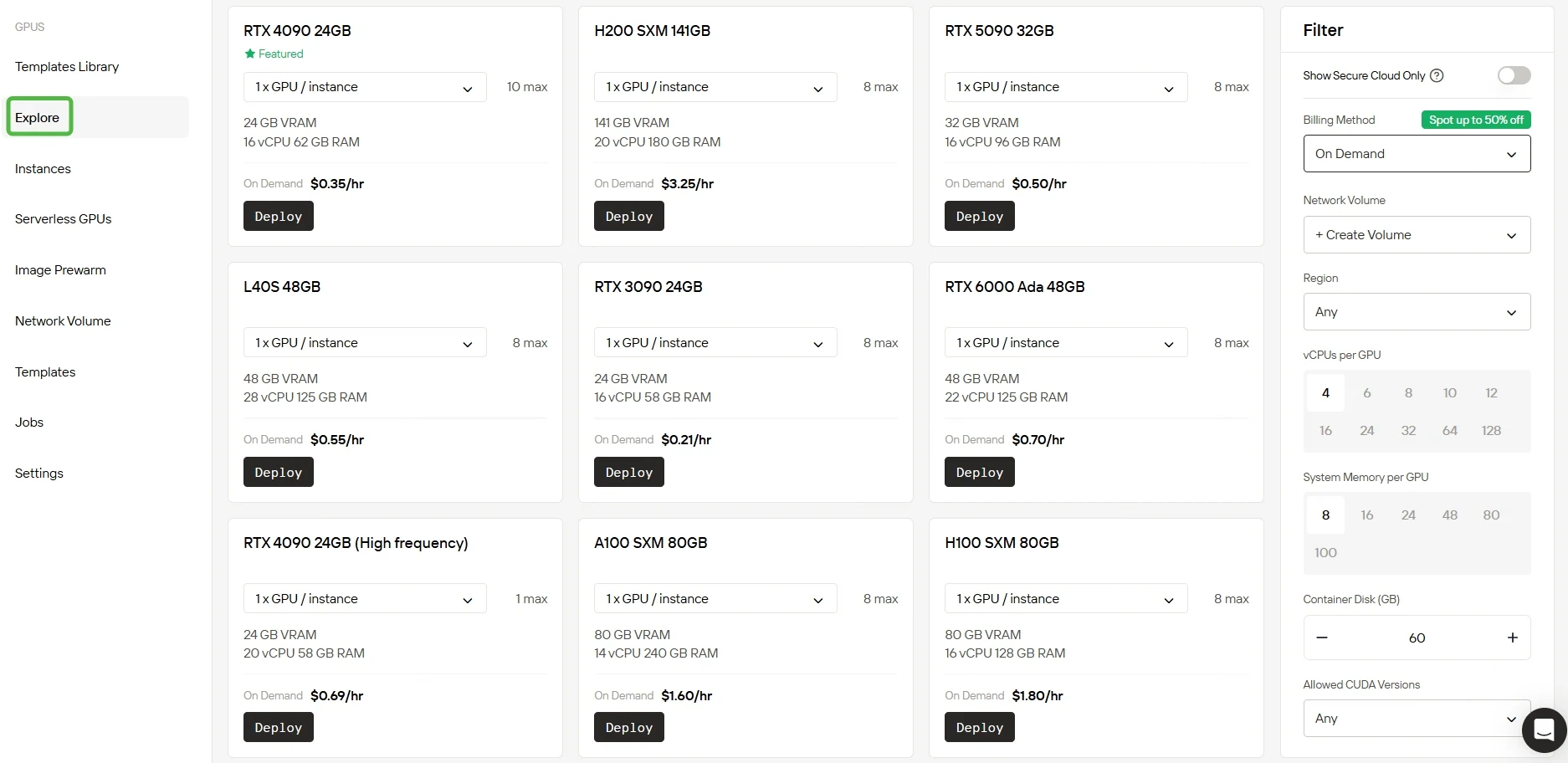
多様なGPUオプションを探索
ステップ3:デプロイをカスタマイズ
AIワークロードのスループットを最適化するため、計算要件に合わせたオペレーティングシステムと設定で環境をセットアップします。起動時には60GBの無料コンテナディスク容量が提供され、プロジェクトの規模拡大に応じて追加ストレージに簡単にスケールアップできます。
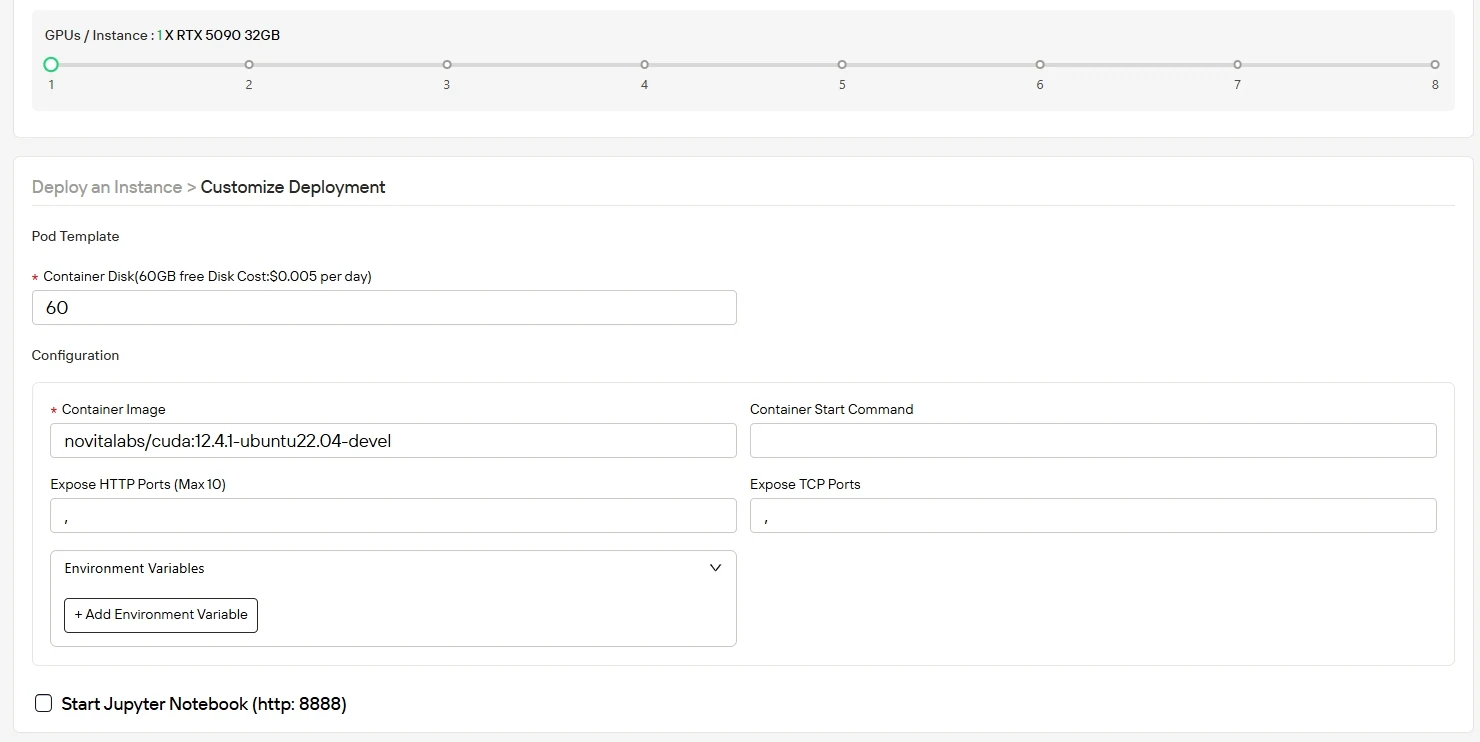
ステップ4:インスタンスを起動
「Deploy」をクリックしてデプロイを開始します。数分以内に高性能GPU環境が準備完了し、機械学習、レンダリング、または計算プロジェクトをすぐに開始できます。
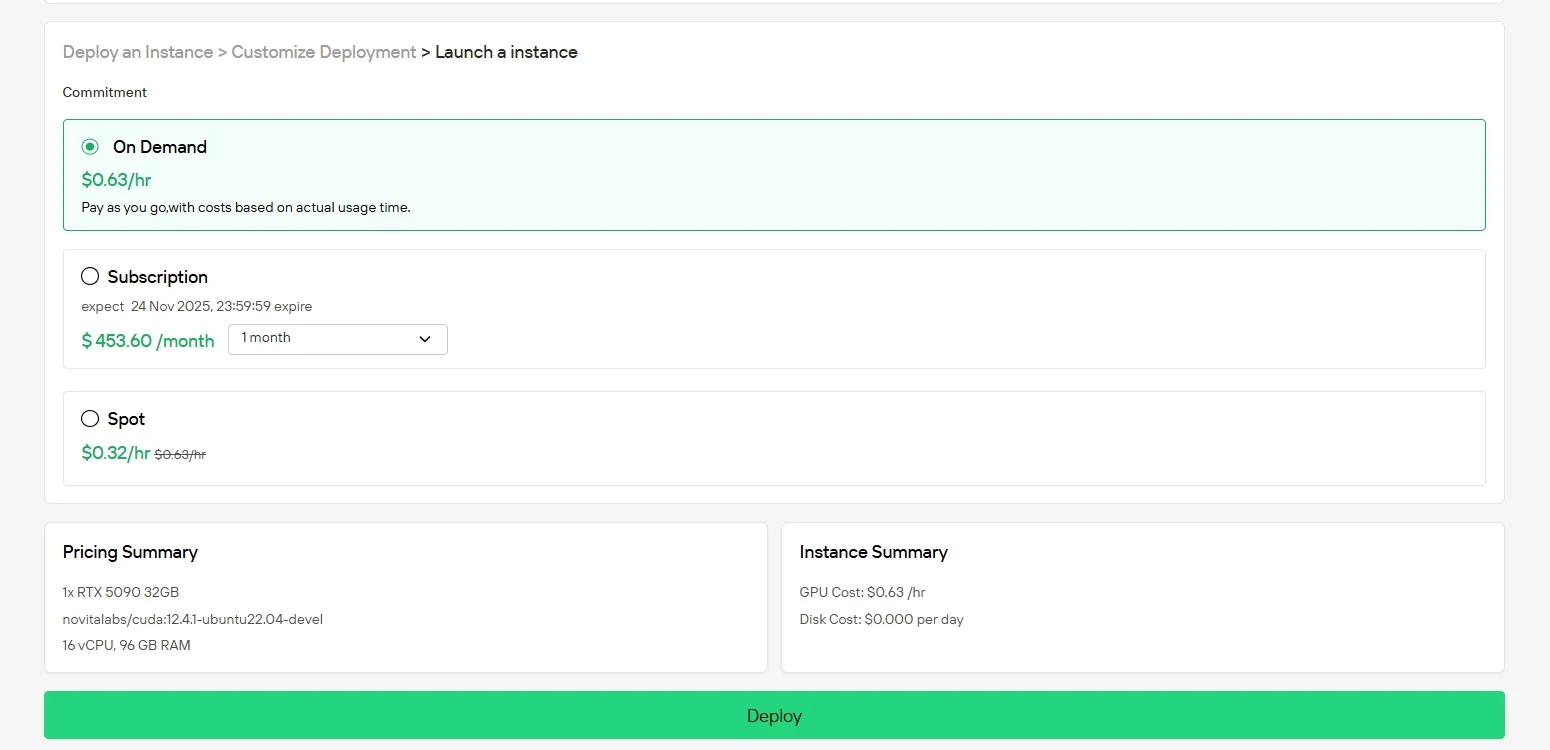
よくある質問
RTX 5090とH200 SXMの主な違いは何ですか?
RTX 5090は高性能デスクトップ向けのコンシューマグレードGPUです。対照的に、H200 SXMはデータセンタークラスのGPUで、エンタープライズグレードの信頼性、NVLinkスケーラビリティ、大容量のHBM3eメモリを備え、大規模モデルや高スループットワークロードをサポートするよう設計されています。
どのようなAIワークロードでH200 SXMが実際に必要ですか?
70B以上のモデル、長文脈推論、分散トレーニング、または高並行性を伴うワークロードは、H200のメモリとインターコネクト帯域幅から大きな恩恵を受けます。
ローカルで大規模言語モデルを実行するのにRTX 5090で十分ですか?
はい — モデルが32GB VRAM内に収まるか、量子化できる限り可能です。約7B~14Bパラメータのモデルはスムーズに動作し、30Bは積極的な最適化で動作する可能性があります。
Novita AI は、シンプルなAPIを使用してAIモデルを簡単にデプロイできるAIクラウドプラットフォームであり、構築とスケーリングのための手頃で信頼性の高いGPUクラウドも提供しています。



