

Les GPU H200 SXM et RTX 5090 de NVIDIA figurent parmi les plus puissants de leur catégorie, mais ils servent des finalités totalement différentes dans l’écosystème de l’IA. Le RTX 5090 excelle dans l’inférence à haute vitesse et le fine-tuning à petite échelle, tandis que le H200 SXM est optimisé pour l’entraînement à grande échelle et le déploiement multi-GPU dans les centres de données.
Cet article compare les deux GPU sur les plans de l’architecture, de la mémoire, des performances et du coût, pour vous aider à déterminer si vos charges de travail nécessitent réellement un GPU de centre de données, ou si un seul RTX 5090 peut déjà répondre à vos objectifs en matière d’IA.
H200 vs 5090 : Spécifications détaillées
||| |—|—|—| |Détail|H200 SXM|RTX 5090| |Date de sortie|18 novembre 2024|30 janvier 2025| |Architecture|Hopper|Blackwell| |Mémoire GPU|141 Go HBM3e|32 Go GDDR7| |Interface mémoire|6144-bit|512-bit| |Bande passante mémoire|4.8 TB/s|1.792 TB/s| |Décodeur NVIDIA|7x NVDEC & 7x JPEG|3x 9th Gen| |Cœurs CUDA|16896|21760| |Cœurs Tensor|528|680| |Puissance graphique totale|jusqu’à 700W|575W|
H200 vs 5090 : Analyse complète des performances
Les GPU H200 SXM et RTX 5090 de NVIDIA servent deux marchés fondamentalement différents. Alors que le RTX 5090 est conçu pour repousser les limites des charges de travail des consommateurs et des créateurs, le H200 SXM est spécialement conçu pour l’IA à l’échelle des centres de données, où le débit, la capacité mémoire et le déploiement en cluster sont critiques.
Pour faire le bon choix, il est essentiel d’évaluer comment leurs atouts correspondent aux exigences de vos charges de travail réelles.
🟩 RTX 5090 : Le GPU grand public haut de gamme
Conçu pour les passionnés, les développeurs et les créateurs, le RTX 5090 met l’accent sur la vitesse brute, la flexibilité et une couverture applicative large. Il permet une itération rapide et des expérimentations en IA tant que le modèle tient dans les budgets mémoire des GPU grand public.
- Débit maximal pour le prototypage local
Grâce à sa bande passante mémoire ultra-large et ses puissants cœurs Tensor/RT, il excelle dans l’itération rapide de modèles, le rendu et les flux de travail créatifs-IA mixtes.- Accès abordable à l’IA haut de gamme
En tant que GPU grand public, il offre un rapport qualité-prix exceptionnel pour les utilisateurs qui souhaitent disposer de capacités de calcul de pointe sans infrastructure d’entreprise.- Réactivité en temps réel constante
Les fréquences d’horloge élevées et l’architecture efficace du RTX 5090 permettent une génération d’images stable et des cycles d’inférence rapides, idéaux pour les tests ou les sessions de création en direct où la latence est importante.- Développement et déploiement d’IA simplifiés
Le RTX 5090 permet un fine-tuning local efficace, l’inférence et l’optimisation de modèles, permettant aux développeurs d’itérer et de mettre à l’échelle les charges de travail d’IA de manière transparente sans dépendre d’infrastructures cloud complexes.
🟦 H200 SXM : Le GPU IA entreprise haut de gamme
Conçu pour le déploiement en centre de données à criticité élevée, le H200 privilégie la capacité mémoire, l’efficacité du débit et l’évolutivité multi-GPU pour les systèmes d’IA générative modernes.
- Mémoire massive pour les modèles de qualité production
Équipé de 141 Go HBM3e, il prend en charge les grands modèles de langue, la récupération dense et l’inférence à long contexte avec un surcoût de sharding minimal.- Performances entreprise à haute fiabilité
Conçu pour une disponibilité constante, une efficacité thermique et une correction d’erreurs strictement contrôlée pour les charges de travail à criticité élevée.- Efficacité de cluster maximisée
NVLink et la NVSwitch de cinquième génération prennent en charge une interconnexion à haute bande passante entre plusieurs GPU, idéale pour l’entraînement distribué et la mise à l’échelle des LLMs.- Optimisation FP8 et Transformer Engine
Accélère l’IA générative de pointe, permettant un débit d’entraînement et d’inférence exceptionnel dans des frameworks optimisés (NVIDIA NIM, TensorRT-LLM).
Points clés
- RTX 5090 → Idéal pour les particuliers ou les petites équipes qui privilégient la vitesse, la flexibilité et le rapport qualité-prix dans des flux de travail locaux, parfait pour le prototypage rapide et l’IA créative.
- H200 SXM → Idéal pour les environnements d’IA entreprise nécessitant de l’évolutivité, une mémoire massive et des capacités de calcul ultra-fiables pour des déploiements à grande échelle et une stabilité 24h/24 et 7j/7.
Lequel choisir ?
Le choix entre le RTX 5090 et le H200 SXM dépend en définitive de votre environnement de déploiement, de votre budget et de la taille de vos modèles — et pas seulement des scores de performance sur le papier.
Quelle est la taille des modèles que vous prévoyez d’exécuter localement ?
Si les poids de votre modèle (ainsi que le cache KV et les activations) peuvent tenir dans 32 Go de VRAM (ou peuvent être quantifiés pour y parvenir), le RTX 5090 est une excellente solution locale.
Si ils dépassent cette limite ou nécessitent des capacités de calcul distribué à haut débit, le H200 SXM est spécialement conçu pour cette échelle.
🔍 Guide de décision rapide
| Votre besoin / Cas d’usage | GPU recommandé | Pourquoi |
|---|---|---|
| Itération rapide, prototypage IA local, charges de travail créatives | RTX 5090 | Excellent rapport qualité-prix + prise en charge de charges de travail variées |
| Modèles 7B à 14B en FP16, ou 30B quantifiés | RTX 5090 | 32 Go de VRAM sont suffisants pour la plupart des LLMs de taille moyenne |
| LLMs ≥ 70B, inférence à long contexte | H200 SXM | 141 Go HBM3e garantissent la résidence complète du modèle + du cache KV |
| Déploiements en production à criticité élevée | H200 SXM | Fiabilité de classe entreprise, mémoire ECC, contrôle thermique |
| Mise à l’échelle multi-GPU NVLink et clusters | H200 SXM | Conçu pour l’entraînement parallèle et les charges de travail distribuées |
| Forte concurrence et débit élevé | H200 SXM | Optimisé pour les charges de travail de centre de données |
H200 vs 5090 : Tarification
| GPU | Prix typique | Notes |
|---|---|---|
| RTX 5090 | ~ 1 999 $US (PDSV) | Carte graphique grand public, mémoire 32 Go GDDR7, destinée aux joueurs et aux créateurs. |
| H200 SXM (GPU unique) | 30 000 $US ~ 40 000 $US par unité | GPU de classe centre de données, mémoire 141 Go HBM3e, conçu pour le déploiement d’IA à grande échelle. |
| Série H200 (carte/système) | Carte 4 GPU ≈ 175 000 $US, Carte 8 GPU ≈ 308 000 $US ~ 315 000 $US |
Système multi-GPU complet incluant plusieurs unités H200, carte NVLink/NVSwitch, infrastructure serveur. |
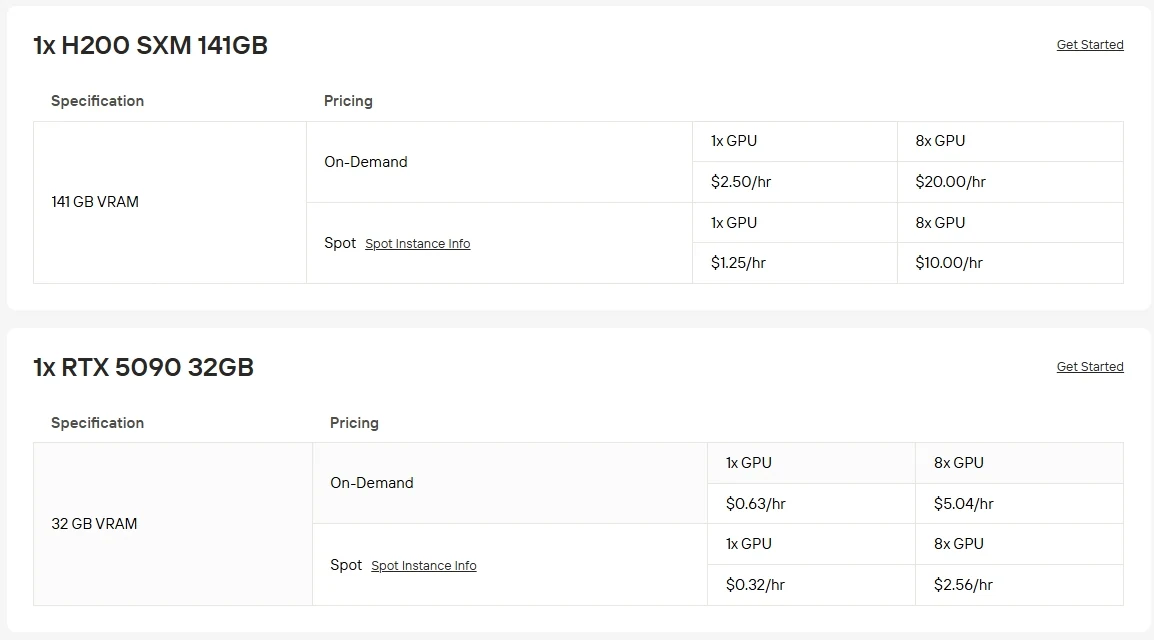
Faire fonctionner des GPU haut de gamme sur votre propre matériel peut être coûteux et difficile à maintenir. Avec le service d’instances GPU de Novita AI, vous pouvez mettre en place rapidement un accès cloud à un RTX 5090 pour seulement 0,63 $/h ou un H200 SXM pour 2,5 $/h sans aucune configuration locale requise. Vous pouvez également choisir parmi plusieurs options de facturation : les instances Spot proposent des prix plus bas avec une disponibilité fluctuante, l’option On-Demand vous permet de ne payer que lorsque vous l’utilisez, et les abonnements offrent des économies constantes pour des charges de travail stables et à long terme.
Commencez avec des instances GPU flexibles sur Novita AI
Novita AI propose des ressources GPU RTX 5090 et H200 évolutives dans le cloud, vous évitant d’acheter et de gérer du matériel coûteux pour des charges de travail de calcul intensif.
Étape 1 : Créez votre compte
Créez votre compte Novita AI via notre site web. Après inscription, rendez-vous dans l’onglet « GPUs » pour consulter les ressources disponibles et commencer votre parcours.
Essayer le RTX 5090 et le H200 maintenant
Étape 2 : Sélectionnez votre GPU
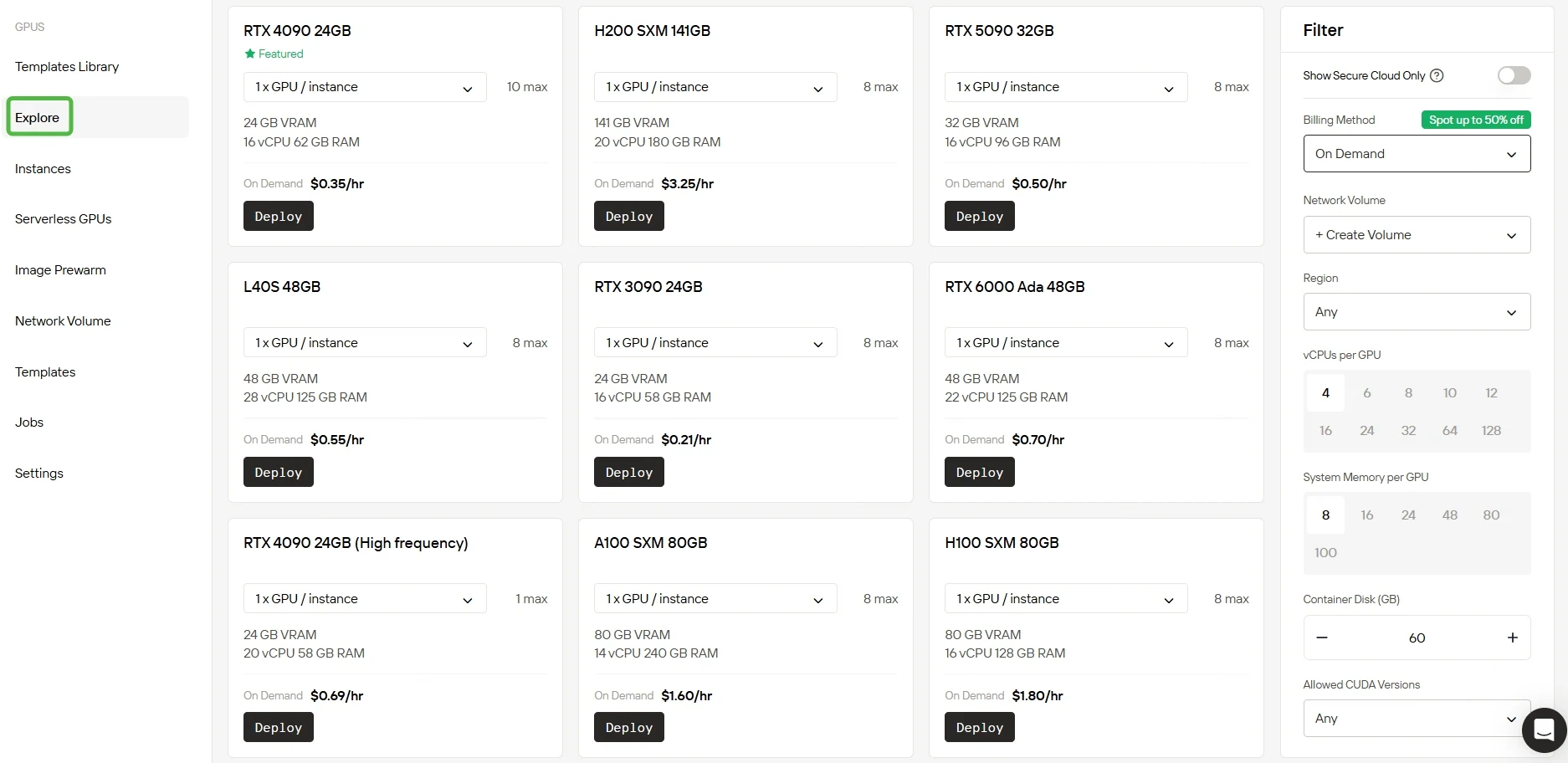
Nous proposons plusieurs modèles préconfigurés adaptés à des besoins variés, tout en vous laissant la liberté d’en créer des personnalisés. Avec accès à des GPU RTX 5090 et RTX 6000 Ada puissants, équipés de VRAM et de RAM importantes, notre service permet un entraînement efficace même pour des modèles d’IA très complexes.
Bibliothèque de modèles préconfigurés
Explorer des options de GPU variées
Étape 3 : Personnalisez votre déploiement
Configurez votre environnement avec le système d’exploitation et les paramètres qui correspondent à vos besoins de calcul, en optimisant le débit pour les charges de travail d’IA. Vous bénéficierez de 60 Go d’espace disque de conteneur gratuit au lancement, avec une mise à l’échelle facile vers un stockage supplémentaire au fur et à mesure que votre projet grandit.
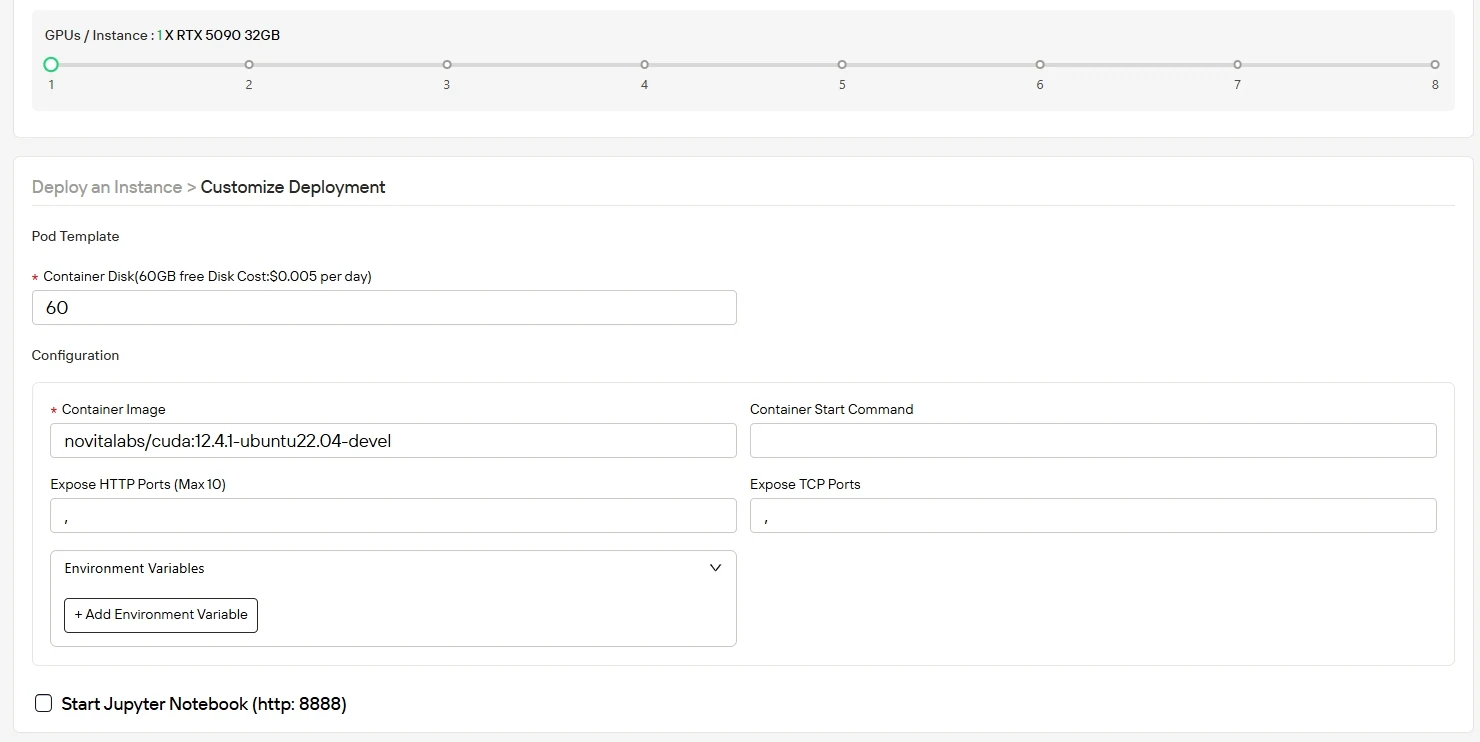
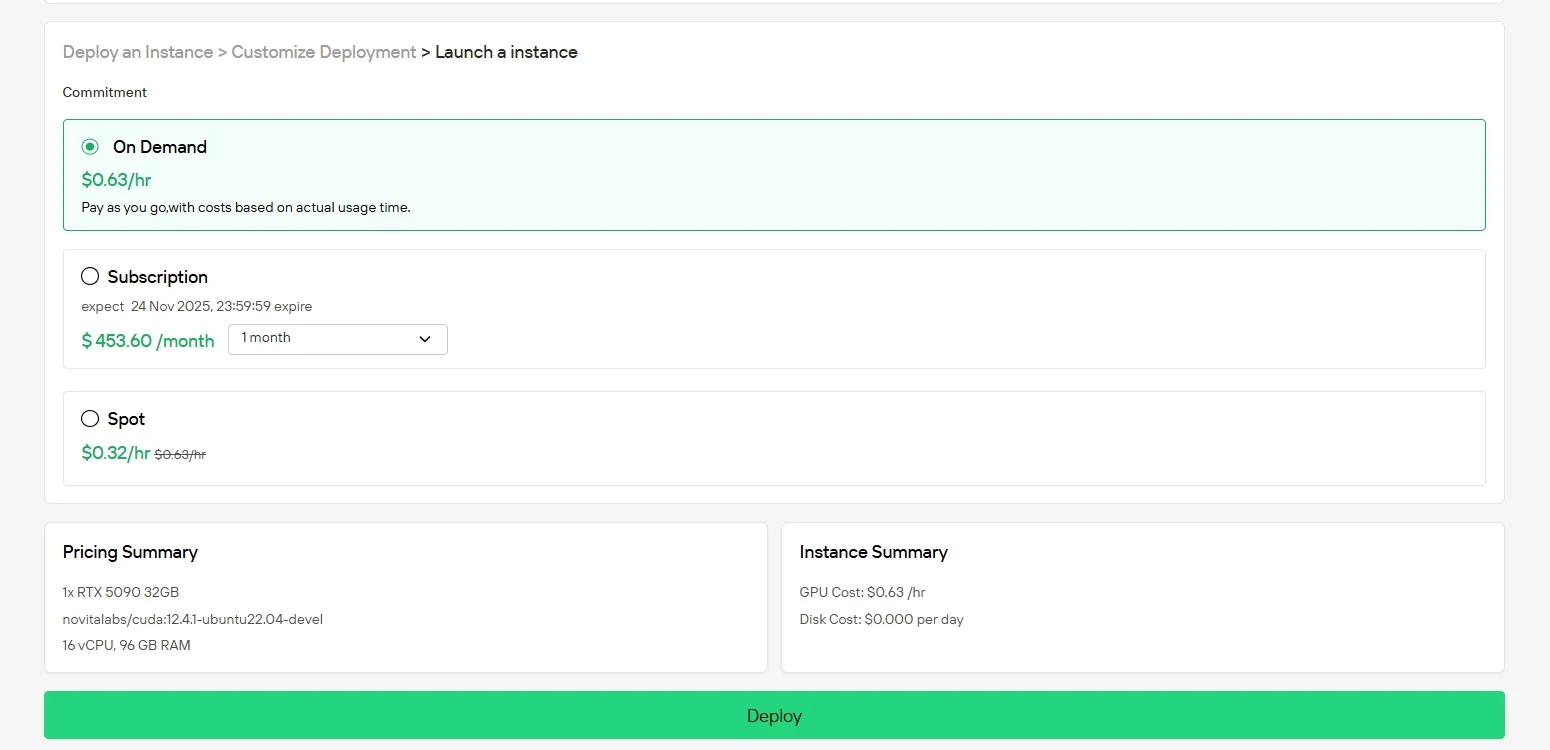
Étape 4 : Lancez votre instance
Cliquez sur « Deploy » pour lancer votre déploiement. En quelques minutes, votre environnement GPU haute performance sera prêt, vous permettant de commencer immédiatement vos projets d’apprentissage automatique, de rendu ou de calcul.
Questions fréquemment posées
Quelle est la principale différence entre le RTX 5090 et le H200 SXM ?
Le RTX 5090 est un GPU grand public conçu pour les ordinateurs de bureau haute performance ; à l’inverse, le H200 SXM est un GPU de classe centre de données conçu pour le déploiement d’IA à grande échelle, doté d’une fiabilité de classe entreprise, d’une évolutivité NVLink et d’une mémoire HBM3e massive pour prendre en charge des modèles volumineux et des charges de travail à haut débit.
Quelles charges de travail IA nécessitent réellement un H200 SXM ?
Les charges de travail impliquant des modèles de 70B ou plus, l’inférence à long contexte, l’entraînement distribué ou une forte concurrence bénéficient grandement de la mémoire et de la bande passante d’interconnexion du H200.
Le RTX 5090 est-il suffisant pour exécuter des grands modèles de langue localement ?
Oui — tant que le modèle tient dans 32 Go de VRAM ou peut être quantifié. Les modèles d’environ 7B à 14B paramètres s’exécutent sans problème ; les modèles de 30B peuvent fonctionner avec des optimisations agressives.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API intuitive, tout en fournissant un cloud GPU abordable et fiable pour construire et mettre à l’échelle des projets.



