

تعد بطاقات معالجة الرسومات H200 SXM و RTX 5090 من NVIDIA من أقوى وحدات معالجة الرسومات في فئتها، على الرغم من أنها تخدم أغراضًا مختلفة تمامًا في نظام الذكاء الاصطناعي البيئي. يتفوق RTX 5090 في الاستدلال عالي السرعة والضبط الدقيق على نطاق صغير، بينما تم تحسين H200 SXM للتدريب على نطاق واسع والنشر متعدد وحدات معالجة الرسومات في مراكز البيانات.
تقارن هذه المقالة بين وحدتي معالجة الرسومات هاتين من حيث الهندسة المعمارية والذاكرة والأداء والتكلفة لمساعدتك على تحديد ما إذا كانت أحمال العمل الخاصة بك تتطلب حقًا وحدة معالجة رسومات لمركز بيانات، أو إذا كان RTX 5090 واحدًا كافٍ بالفعل لتحقيق أهدافك في الذكاء الاصطناعي.
H200 مقابل 5090: المواصفات التفصيلية
| التفاصيل | H200 SXM | RTX 5090 |
| تاريخ الإصدار | 18 نوفمبر 2024 | 30 يناير 2025 |
| الهندسة المعمارية | Hopper | Blackwell |
| ذاكرة GPU | 141 جيجابايت HBM3e | 32 جيجابايت GDDR7 |
| واجهة الذاكرة | 6144 بت | 512 بت |
| عرض النطاق الترددي للذاكرة | 4.8 تيرابايت/ثانية | 1.792 تيرابايت/ثانية |
| مفكك NVIDIA | 7x NVDEC و 7x JPEG | 3x الجيل التاسع |
| أنوية CUDA | 16896 | 21760 |
| أنوية Tensor | 528 | 680 |
| إجمالي طاقة الرسومات | حتى 700 وات | 575 وات |
H200 مقابل 5090: مراجعة أداء شاملة
تخدم بطاقات معالجة الرسومات H200 SXM و RTX 5090 من NVIDIA سوقين مختلفين جذريًا. بينما تم تصميم RTX 5090 لدفع أحمال عمل المستهلكين ومنشئي المحتوى إلى آفاق جديدة، تم بناء H200 SXM خصيصًا للذكاء الاصطناعي على نطاق مراكز البيانات، حيث تعد الإنتاجية وسعة الذاكرة والنشر العنقودي عوامل حرجة.
لاختيار الخيار الأمثل، من الضروري تقييم كيف تتوافق نقاط قوتها مع متطلبات أحمال العمل الفعلية الخاصة بك.
🟩 RTX 5090: بطاقة معالجة الرسومات للمستهلكين من الفئة العليا
تم تصميم RTX 5090 لهواة الجمع، والمطورين، ومنشئي المحتوى، ويركز على السرعة الخام والمرونة وتغطية تطبيقات واسعة. فهو يتيح تكرارًا سريعًا وتجارب في الذكاء الاصطناعي طالما أن النموذج يتناسب مع ميزانيات ذاكرة بطاقات معالجة الرسومات للمستهلكين.
- أقصى إنتاجية للنماذج الأولية المحلية
بفضل عرض النطاق الترددي الفائق للذاكرة وأنوية Tensor/RT القوية، فهو يتفوق في تكرار النماذج السريع والتصيير وأحمال عمل الإبداع والذكاء الاصطناعي المختلطة.- دخول بأسعار معقولة إلى الذكاء الاصطناعي عالي المستوى
كوحدة معالجة رسومات من فئة المستهلكين، فإنها توفر أداءً سعرًا استثنائيًا للمستخدمين الذين يريدون قدرات حاسوبية متطورة دون بنية تحتية للمؤسسات.- استجابة متسقة في الوقت الفعلي
تتيح سرعات الساعة العالية والهندسة المعمارية الفعالة لـ RTX 5090 توليد إطارات مستقر ودورات استدلال سريعة، مما يجعله مثاليًا للاختبار أو جلسات الإبداع المباشرة حيث يعد التأخر عاملًا مهمًا.- تطوير ونشر ذكي للذكاء الاصطناعي
يتيح RTX 5090 ضبطًا دقيقًا محليًا فعالًا واستدلالًا وتحسينًا للنماذج، مما يسمح للمطورين بتكرار وتوسيع نطاق أحمال عمل الذكاء الاصطناعي بسلاسة دون الاعتماد على بنية تحتية سحابية معقدة.
🟦 H200 SXM: وحدة معالجة الرسومات للذكاء الاصطناعي للشركات من الفئة العليا
تم تصميم H200 خصيصًا للنشر في مراكز البيانات للمهام الحرجة، ويهدف إلى سعة الذاكرة وكفاءة الإنتاجية وقابلية التوسع متعدد وحدات معالجة الرسومات لأنظمة الذكاء الاصطناعي التوليدي الحديثة.
- ذاكرة ضخمة للنماذج ذات مستوى الإنتاج
مجهز بذاكرة HBM3e سعة 141 جيجابايت، فإنه يتعامل مع نماذج اللغة الكبيرة والاسترجاع الكثيف والاستدلال طويل السياق مع حد أدنى من تكاليف التجزئة.- أداء enterprise عالي الموثوقية
مصمم لوقت تشغيل متسابق وكفاءة حرارية وتصحيح أخطاء محكم التحكم لأحمال العمل الحرجة.- كفاءة عنقودية قصوى
يدعم NVLink و NVSwitch من الجيل الخامس اتصالًا عالي النطاق الترددي عبر وحدات معالجة رسومات متعددة، مما يجعله مثاليًا للتدريب الموزع وتوسيع نطاق نماذج اللغة الكبيرة (LLMs).- تحسين محرك FP8 و Transformer
يسرع من الذكاء الاصطناعي التوليدي المتطور، مما يتيح إنتاجية تدريب واستدلال استثنائية في الأطر المحسنة (NVIDIA NIM, TensorRT-LLM).
النقاط الرئيسية
- RTX 5090 → الأفضل للأفراد أو الفرق الصغيرة التي تعطي الأولوية للسرعة والمرونة والفعالية من حيث التكلفة في أحمال العمل المحلية—مثالي للنماذج الأولية السريعة والذكاء الاصطناعي الإبداعي.
- H200 SXM → الأفضل لبيئات الذكاء الاصطناعي للشركات التي تحتاج إلى قابلية التوسع وذاكرة ضخمة وقدرة حاسوبية فائقة الموثوقية للنشر على نطاق واسع واستقرار على مدار الساعة طوال الأسبوع.
أي واحد يجب أن تختار؟
يعتمد الاختيار النهائي بين RTX 5090 و H200 SXM في النهاية على بيئة النشر الخاصة بك والميزانية ومقياس نماذجك — وليس فقط درجات الأداء على الورق.
ما هو حجم النماذج التي تخطط لتشغيلها محليًا؟
إذا كانت أوزان النموذج الخاص بك (بالإضافة إلى ذاكرة التخزين المؤقت KV والتفعيلات) يمكن أن تتناسب within 32 جيجابايت من VRAM (أو يمكن تكميمها للقيام بذلك)، فإن RTX 5090 هو حل محلي ممتاز.
إذا تجاوزت هذا الحد أو تتطلب قدرة حاسوبية موزعة عالية الإنتاجية، فإن H200 SXM مخصص لهذا المقياس.
🔍 دليل قرار سريع
| الاحتياج / حالة الاستخدام | وحدة معالجة الرسومات الموصى بها | السبب |
|---|---|---|
| تكرار سريع، نماذج أولية محلية للذكاء الاصطناعي، أحمال عمل إبداعية | RTX 5090 | أداء سعر قوي + دعم واسع لأحمال العمل |
| نماذج 7B–14B بتنسيق FP16، أو 30B مُكمَّى | RTX 5090 | ذاكرة VRAM سعة 32 جيجابايت كافية لمعظم نماذج اللغة الكبيرة متوسطة المقياس |
| ≥70B LLMs، استدلال طويل السياق | H200 SXM | ذاكرة HBM3e سعة 141 جيجابايت تضمن إقامة كاملة للنموذج + ذاكرة التخزين المؤقت KV |
| نشرات إنتاجية للمهام الحرجة | H200 SXM | موثوقية على مستوى المؤسسات، ذاكرة ECC، تحكم حراري |
| توسيع نطاق متعدد وحدات معالجة الرسومات عبر NVLink والعناقيد | H200 SXM | مصمم للتدريب المتوازي وأحمال العمل الموزعة |
| تزامن عالي وإنتاجية عالية | H200 SXM | محسّن لأحمال عمل مراكز البيانات |
H200 مقابل 5090: التسعير
| وحدة معالجة الرسومات | السعر النموذجي | ملاحظات |
|---|---|---|
| RTX 5090 | ~ 1999 دولار أمريكي (MSRP) | بطاقة رسومات من فئة المستهلكين، ذاكرة GDDR7 سعة 32 جيجابايت، موجهة للاعبين ومنشئي المحتوى. |
| H200 SXM (وحدة واحدة) | 30,000 ~ 40,000 دولار أمريكي للوحدة | وحدة معالجة رسومات من فئة مراكز البيانات، ذاكرة HBM3e سعة 141 جيجابايت، مبنية للنشر على نطاق واسع للذكاء الاصطناعي. |
| سلسلة H200 (لوحة / نظام) | لوحة 4 وحدات ≈ 175,000 دولار أمريكي، لوحة 8 وحدات ≈ 308,000 ~ 315,000 دولار أمريكي |
نظام متعدد وحدات معالجة الرسومات بالكامل يتضمن وحدات H200 متعددة، لوحة NVLink/NVSwitch، بنية تحتية للخوادم. |
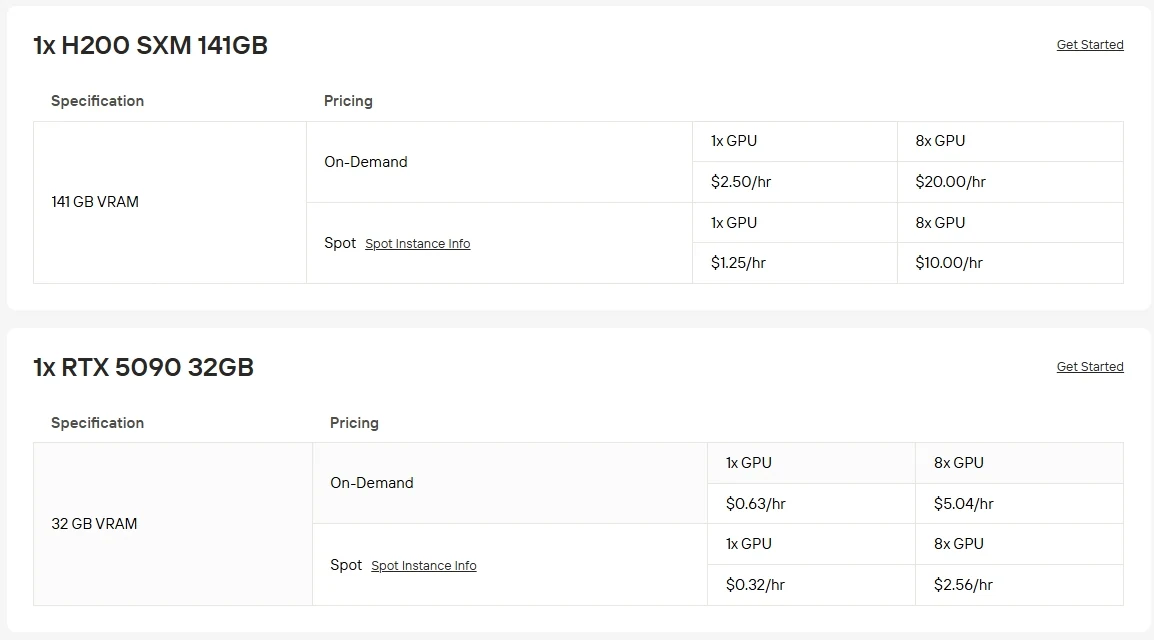
قد يكون تشغيل وحدات معالجة الرسومات من الفئة العليا على الأجهزة الخاصة بك مكلفًا وصعب الصيانة. مع خدمة مثيلات وحدات معالجة الرسومات من Novita AI، يمكنك بسرعة الحصول على وصول سحابي إلى RTX 5090 مقابل 0.63 دولار أمريكي في الساعة فقط أو H200 SXM مقابل 2.5 دولار أمريكي في الساعة دون الحاجة إلى إعداد محلي. يمكنك أيضًا الاختيار من بين خيارات الفواتير المتعددة: تقدم مثيلات Spot أسعارًا أقل مع توفر متقلب، تتيح لك مثيلات On-Demand الدفع فقط عند استخدامها، وتوفر خطط الاشتراك توفيرًا ثابتًا لأحمال العمل المستقرة على المدى الطويل.
ابدأ باستخدام مثيلات وحدات معالجة الرسومات المرنة على Novita AI
تقدم Novita AI موارد قابلة للتوسع لوحدات معالجة الرسومات RTX 5090 و H200 في السحابة، مما يلغي الحاجة إلى شراء وإدارة أجهزة مكلفة لأحمال العمل الحاسوبية المكثفة.
الخطوة 1: سجل حسابك
أنشئ حساب Novita AI الخاص بك عبر موقعنا الإلكتروني. بعد التسجيل، انتقل إلى علامة التبويب “GPUs” لعرض الموارد المتاحة وابدأ رحلتك.
الخطوة 2: اختر وحدة معالجة الرسومات الخاصة بك
نقدم قوالب مسبقة التكوين متعددة لتتناسب مع الاحتياجات المتنوعة، مع منحك أيضًا المرونة لبناء قوالب مخصصة. مع الوصول إلى وحدات معالجة الرسومات القوية RTX 5090 و RTX 6000 Ada المجهزة بذاكرة وصول عشوائي للفيديو وذاكرة وصول عشوائي كافية، تتيح خدمتنا تدريبًا فعالًا حتى للنماذج عالية التعقيد للذكاء الاصطناعي.
مكتبة القوالب المسبقة التكوين
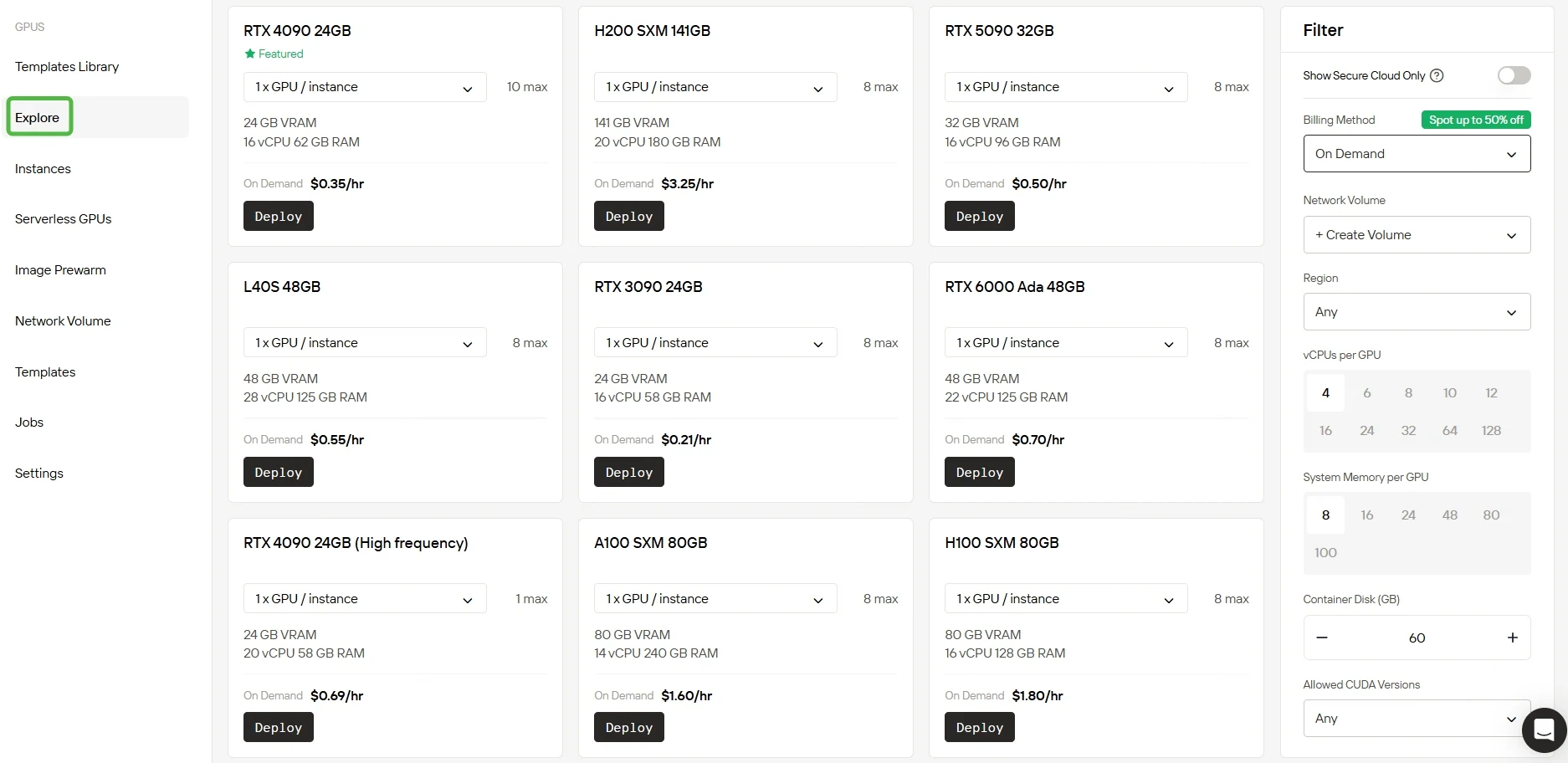
استكشف خيارات وحدات معالجة الرسومات المتنوعة
الخطوة 3: خصص نشرك
قم بإعداد بيئتك بنظام التشغيل والتكوين الذي يتوافق مع متطلبات الحوسبة الخاصة بك، مع تحسين الإنتاجية لأحمال عمل الذكاء الاصطناعي. ستتلقى 60 جيجابايت من مساحة قرص الحاوية المجانية عند الإطلاق، مع إمكانية التوسع بسهولة إلى مساحة تخزين إضافية مع نمو حجم مشروعك.
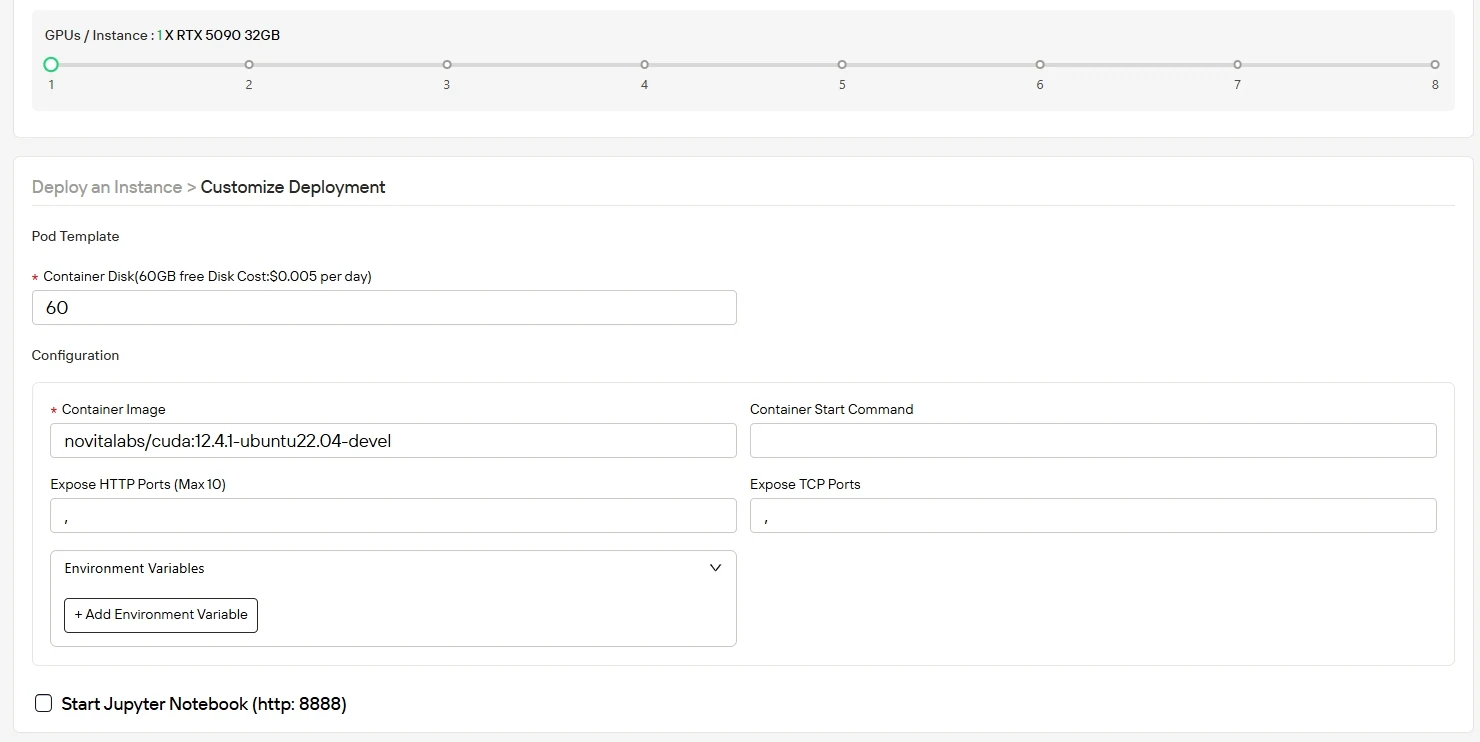
الخطوة 4: ابدأ مثيلك
انقر على “نشر” لبدء نشرك. في غضون دقائق، ستكون بيئة وحدة معالجة الرسومات عالية الأداء جاهزة، مما يتيح لك بدء مشاريع التعلم الآلي أو التصيير أو الحوسبة على الفور.
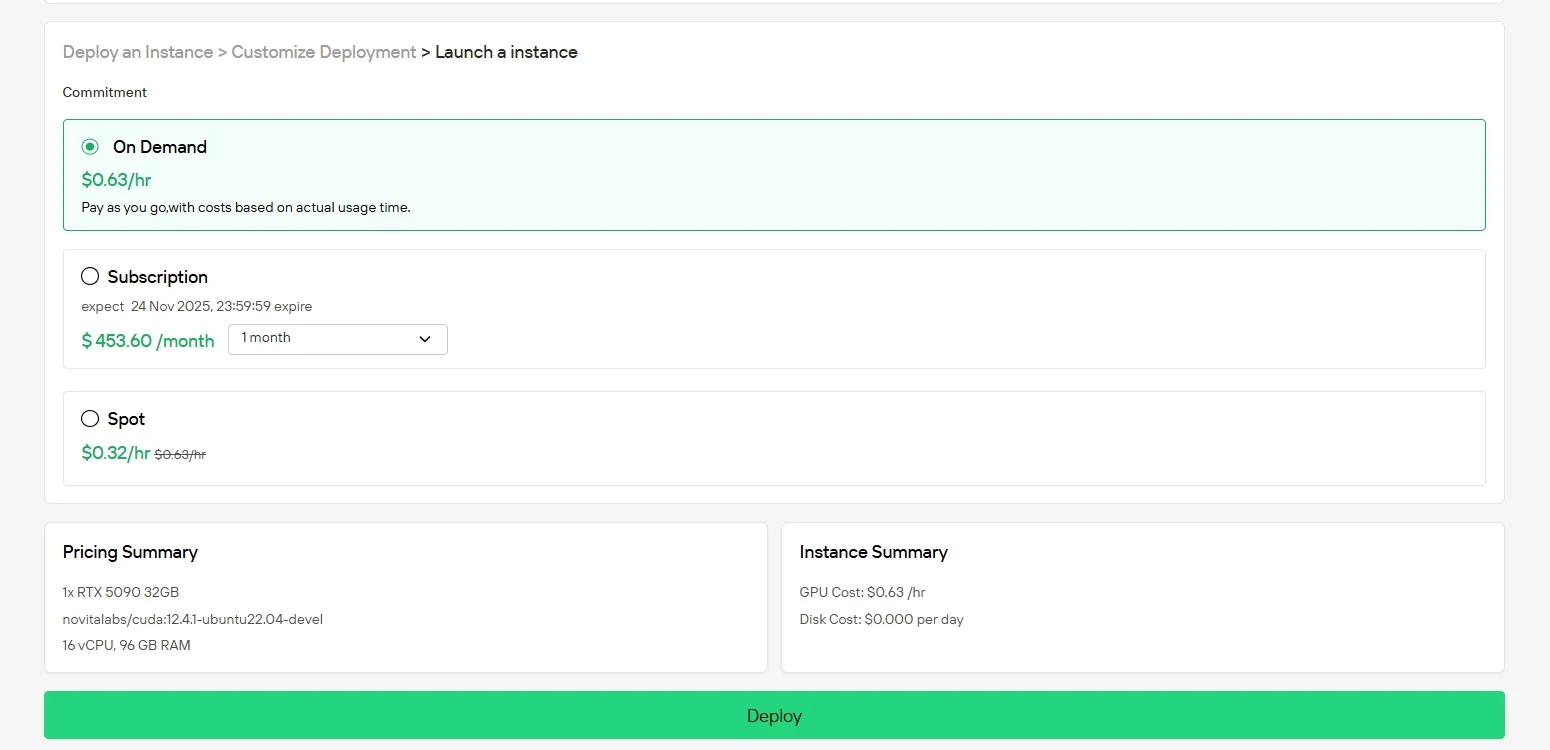
الأسئلة الشائعة
ما هو الفرق الرئيسي بين RTX 5090 و H200 SXM؟
RTX 5090 هو وحدة معالجة رسومات من فئة المستهلكين مصممة لأجهزة الكمبيوتر المكتبية عالية الأداء؛ على النقيض من ذلك، فإن H200 SXM هو وحدة معالجة رسومات من فئة مراكز البيانات مبنية للنشر على نطاق واسع للذكاء الاصطناعي، وتتميز بموثوقية على مستوى المؤسسات وقابلية التوسع عبر NVLink وذاكرة HBM3e ضخمة لدعم النماذج الكبيرة وأحمال العمل عالية الإنتاجية.
ما هي أحمال عمل الذكاء الاصطناعي التي تتطلب فعليًا H200 SXM؟
تستفيد أحمال العمل التي تتضمن نماذج 70B+ أو الاستدلال طويل السياق أو التدريب الموزع أو التزامن العالي بشكل كبير من ذاكرة H200 وعرض النطاق الترددي للاتصال بين المكونات.
هل RTX 5090 كافٍ لتشغيل نماذج اللغة الكبيرة محليًا؟
نعم — طالما أن النموذج يتناسب within 32 جيجابايت من VRAM أو يمكن تكميمها. تعمل النماذج التي يبلغ عدد معلماتها حوالي 7B–14B بسلاسة؛ قد يعمل نموذج 30B مع تحسينات عدوانية.
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة التطبيقات البسيطة الخاصة بنا، مع توفير سحابة وحدات معالجة الرسومات بأسعار معقولة وموثوقة للبناء والتوسع.



