

NVIDIA的H200 SXM和RTX 5090是同級別中最強大的GPU之一,但它們在AI生態系中扮演的角色完全不同。RTX 5090擅長高速推論與小規模微調,而H200 SXM則針對資料中心的大規模訓練與多GPU部署進行優化。
本文將從架構、記憶體、效能與成本等多個維度比較這兩款GPU,幫助你判斷自己的工作負載是否真的需要資料中心級GPU,還是單張RTX 5090就能滿足你的AI需求。
H200 vs 5090:詳細規格對比
| 項目 | H200 SXM | RTX 5090 |
| 發布日期 | 2024年11月18日 | 2025年1月30日 |
| 架構 | Hopper | Blackwell |
| GPU記憶體 | 141 GB HBM3e | 32 GB GDDR7 |
| 記憶體介面 | 6144-bit | 512-bit |
| 記憶體頻寬 | 4.8 TB/s | 1.792 TB/s |
| NVIDIA解碼器 | 7x NVDEC & 7x JPEG | 3x 9th Gen |
| CUDA核心數 | 16896 | 21760 |
| Tensor核心數 | 528 | 680 |
| 總圖形功耗 | 最高700W | 575W |
H200 vs 5090:全面效能評測
NVIDIA H200 SXM與RTX 5090服務於兩個截然不同的市場。RTX 5090是為消費級與創作者工作負載打造,旨在突破效能上限;而H200 SXM則是專為資料中心規模的AI場景設計,在吞吐量、記憶體容量與集群部署方面都有關鍵優化。
要做出正確選擇,你必須評估兩者的優勢是否符合你的實際工作負載需求。
🟩 RTX 5090:頂尖消費級GPU
專為愛好者、開發者與創作者設計,RTX 5090主打高效能、靈活性與廣泛的應用場景覆蓋。只要模型能裝入消費級GPU的記憶體預算內,它就能實現快速迭代與AI實驗。
- 本地原型開發的最大吞吐量
憑藉超寬記憶體頻寬與強大的Tensor/RT核心,它非常適合快速模型迭代、渲染與混合創意AI工作流程。- 高端AI的高性價比入門選擇
作為消費級GPU,它為想要尖端運算能力卻無需企業級基礎設施的用戶,提供了極佳的性價比。- 穩定的即時回應能力
RTX 5090的高時脈頻率與高效能架構能實現穩定的影格生成與快速的推論循環,非常適合需要低延遲的測試或即時創意場景。- 簡化的AI開發與部署流程
RTX 5090支援高效的本地微調、推論與模型優化,讓開發者无需依賴複雜的雲端基礎設施,就能順暢地迭代與擴展AI工作負載。
🟦 H200 SXM:高端企業級AI GPU
專為關鍵任務的資料中心部署打造,H200針對現代生成式AI系統,優先優化記憶體容量、吞吐量效率與多GPU擴展性。
- 生產級模型的大容量記憶體
搭載141GB HBM3e記憶體,可處理大型語言模型、稠密檢索與長上下文推論,且分片開銷極低。- 高可靠性的企業級效能
針對關鍵任務工作負載設計,提供穩定的運行時間、熱效率與嚴格的錯誤校正機制。- 集群效率最大化
支援第五代NVLink與NVSwitch,可實現多GPU間的高頻寬互連,非常適合分散式訓練與大型語言模型擴展。- FP8與Transformer Engine優化
加速最先進的生成式AI運算,在優化框架(NVIDIA NIM、TensorRT-LLM)中實現卓越的訓練與推論吞吐量。
總結要點
- RTX 5090 → 最適合個人或小型團隊,在本地工作流程中追求速度、靈活性與成本效益,非常適合快速原型開發與創意AI場景。
- H200 SXM → 最適合企業AI環境,需要擴展性、超大記憶體與超高可靠運算,用於大規模部署與24/7穩定運行。
你該選擇哪一款?
在RTX 5090與H200 SXM之間做選擇,最終取決於你的部署環境、預算與模型規模,而不僅僅是紙面上的效能分數。
你打算在本地運行的模型有多大?
如果你的模型權重(加上KV快取與激活值)能裝入32GB VRAM(或可以通過量化實現),RTX 5090是非常優秀的本地解決方案。
如果超過這個限制,或需要高吞吐量的分散式運算,H200 SXM就是為這個規模的場景量身打造的。
🔍 快速決策指南
| 你的需求 / 使用場景 | 推薦GPU | 原因 |
|---|---|---|
| 快速迭代、本地AI原型開發、創意工作負載 | RTX 5090 | 性價比高 + 支援廣泛的工作負載 |
| FP16精度下的7B–14B模型,或量化後的30B模型 | RTX 5090 | 32GB VRAM足以應對大多數中等規模的大型語言模型 |
| ≥70B的大型語言模型、長上下文推論 | H200 SXM | 141GB HBM3e可確保完整模型與KV快取常駐記憶體 |
| 關鍵任務的生產部署 | H200 SXM | 企業級可靠性、ECC記憶體、熱控機制 |
| NVLink多GPU擴展與集群部署 | H200 SXM | 專為平行訓練與分散式工作負載設計 |
| 高併發與高吞吐量需求 | H200 SXM | 針對資料中心工作負載優化 |
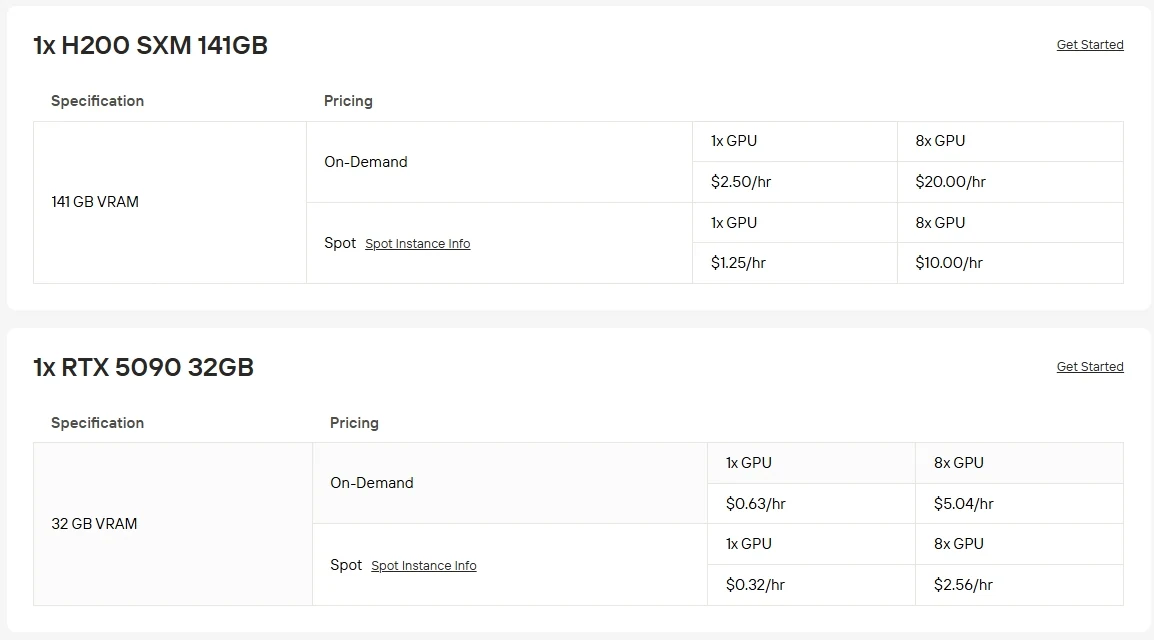
H200 vs 5090:價格對比
| GPU | 典型價格 | 備註 |
|---|---|---|
| RTX 5090 | 約 1,999美元(建議售價) | 消費級顯示卡,32GB GDDR7記憶體,針對遊戲玩家與創作者設計。 |
| H200 SXM(單張) | 每張30,000 ~ 40,000美元 | 資料中心級GPU,141GB HBM3e記憶體,為大規模AI部署打造。 |
| H200系列(板卡/系統) | 4GPU板卡 ≈ 175,000美元, 8GPU板卡 ≈ 308,000 ~ 315,000美元 |
完整多GPU系統,包含多張H200單元、NVLink/NVSwitch板卡、伺服器基礎設施。 |
自行購置頂尖GPU運行不僅成本高昂,維護也相當困難。透過Novita AI的GPU執行個體服務,你可以快速取得雲端RTX 5090的使用權,每小時僅需0.63美元,或H200 SXM每小時2.5美元,无需任何本地設置。我們也提供多種計費選項:Spot執行個體價格較低,但可用性會浮動;On-Demand(隨需)讓你按使用量付費;Subscription訂閱方案則能為穩定、長期的工作負載提供持續的優惠。
立即開始使用Novita AI的彈性GPU執行個體
Novita AI在雲端提供可擴展的RTX 5090與H200 GPU資源,讓你无需購置與管理昂貴的硬體,即可執行高效能運算工作負載。
步驟1:註冊帳號
透過我們的網站建立Novita AI帳號。註冊完成後,前往「GPUs」分頁即可查看可用資源,開始你的使用之旅。
步驟2:選擇你的GPU
我們提供多種預設配置模板,滿足不同需求,同時也支援你自訂配置。你可以使用搭載大容量VRAM與RAM的強大RTX 5090與RTX 6000 Ada GPU,我們的服務能高效執行甚至高度複雜的AI模型訓練。
 預設模板庫
預設模板庫
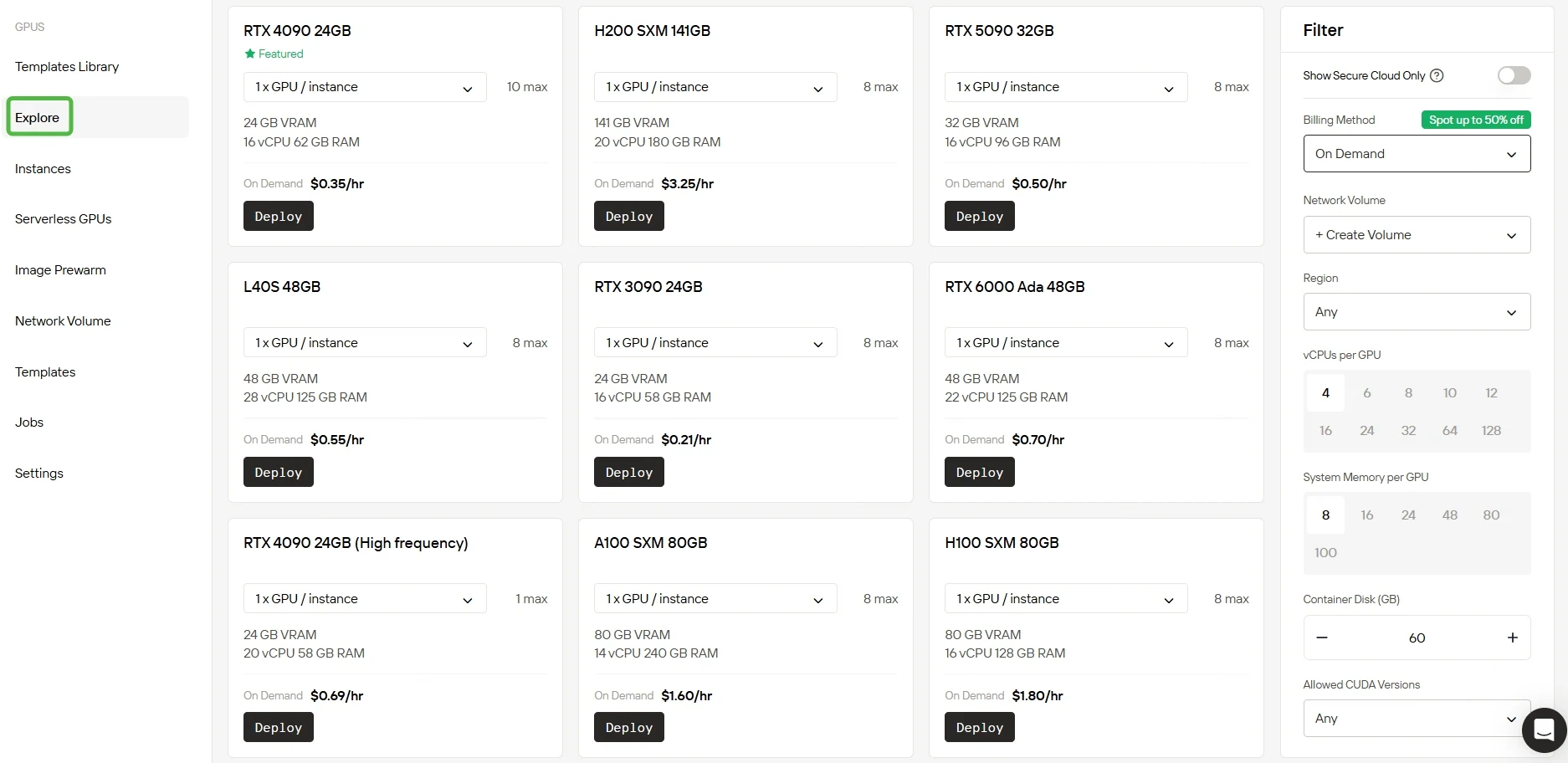 探索多元GPU選項
探索多元GPU選項
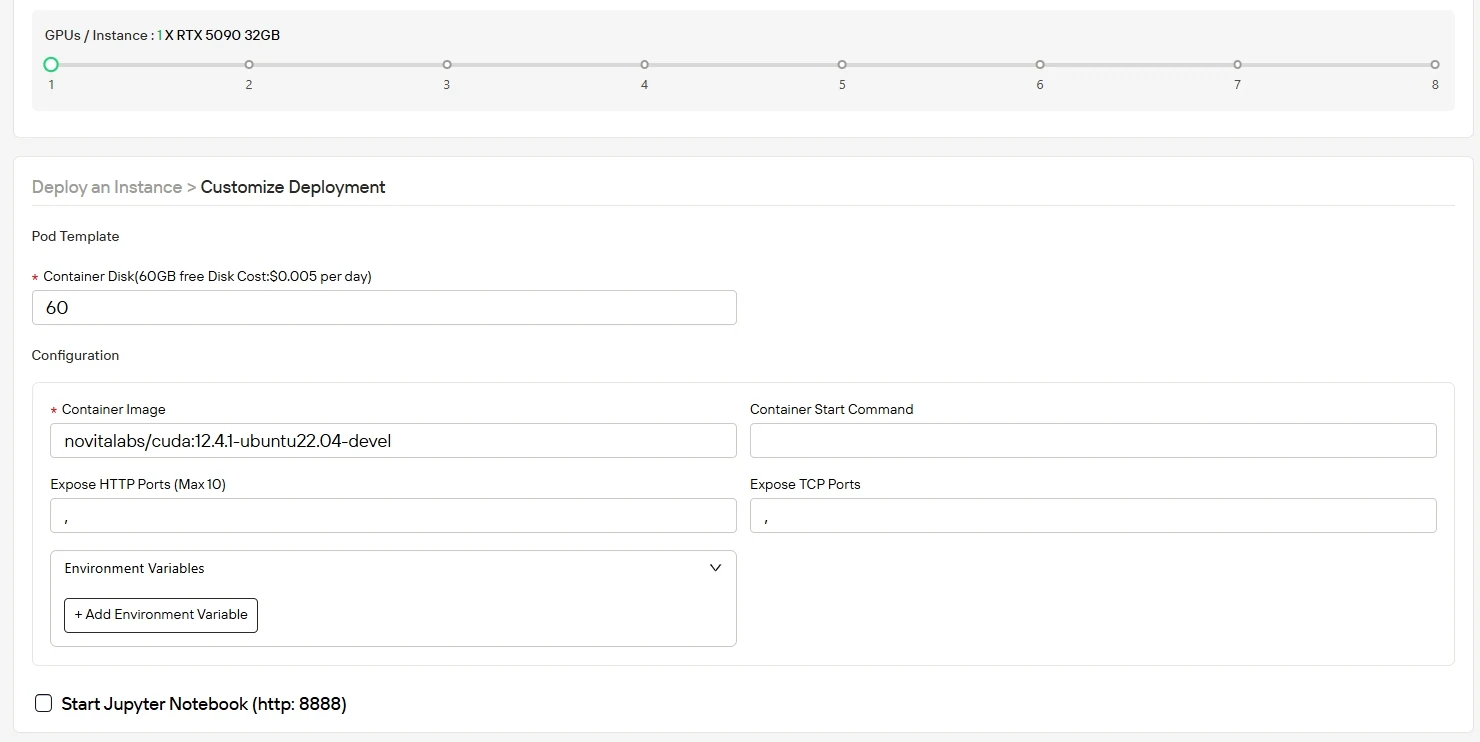
步驟3:自訂你的部署配置
根據你的運算需求選擇作業系統與配置,優化AI工作負載的吞吐量。啟動時你會獲得60GB的免費容器磁碟空間,隨著專案規模擴大,也可以輕鬆擴展至更多儲存空間。
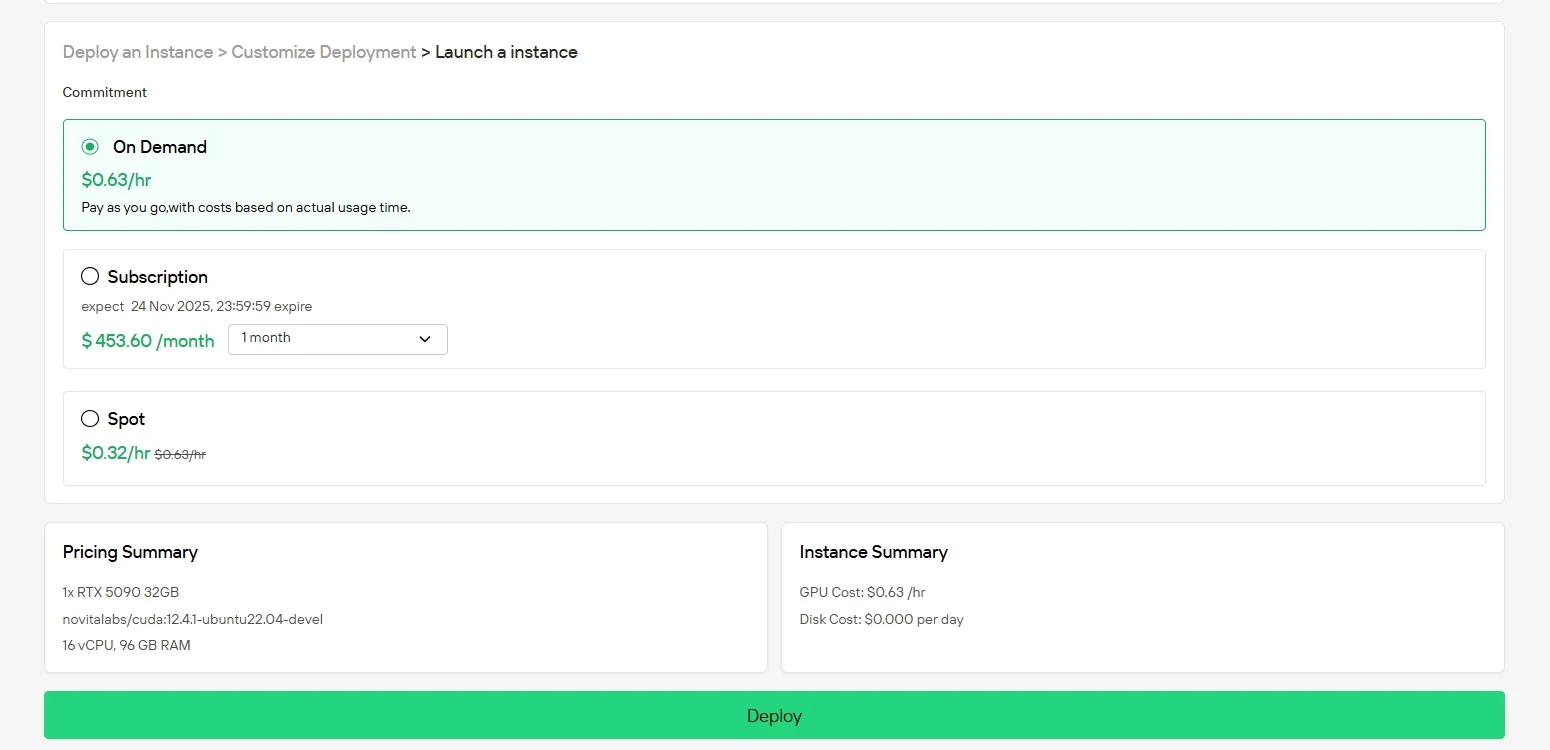
步驟4:啟動你的執行個體
點擊「Deploy」按鈕開始部署。幾分鐘內,你的高效能GPU環境就會就緒,你可以立即開始機器學習、渲染或運算專案。
常見問題
RTX 5090與H200 SXM的主要差異是什麼? RTX 5090是消費級GPU,為高效能桌上型電腦設計;而H200 SXM是資料中心級GPU,為大規模AI部署打造,具備企業級可靠性、NVLink擴展性與超大HBM3e記憶體,可支援大型模型與高吞吐量工作負載。
哪些AI工作負載真的需要H200 SXM? 涉及70B以上模型、長上下文推論、分散式訓練或高併發需求的工作負載,都能從H200的記憶體與互連頻寬中獲得顯著效能提升。
RTX 5090是否足夠在本地運行大型語言模型? 是的——只要模型能裝入32GB VRAM,或可以通過量化實現即可。約7B–14B參數的模型可流暢運行;30B參數的模型在激進優化下也能運行。
Novita AI 是一個AI雲端平台,為開發者提供簡單的API來部署AI模型,同時也提供平價、可靠的GPU雲端服務,用於建構與擴展AI專案。



