

Die H200 SXM und RTX 5090 von NVIDIA gehören zu den leistungsstärksten GPUs ihrer Klasse, erfüllen aber im KI-Ökosystem völlig unterschiedliche Zwecke. Die RTX 5090 glänzt bei schneller Inferenz und Feinabstimmung im kleineren Maßstab, während die H200 SXM für großangelegtes Training und Multi-GPU-Bereitstellungen in Rechenzentren optimiert ist.
Dieser Artikel vergleicht beide GPUs hinsichtlich Architektur, Speicher, Leistung und Kosten, um Ihnen zu helfen, festzustellen, ob Ihre Workloads wirklich eine Rechenzentrums-GPU erfordern – oder ob eine einzelne RTX 5090 bereits Ihre KI-Ziele erfüllen kann.
H200 vs. 5090: Detaillierte Spezifikationen
| Detail | H200 SXM | RTX 5090 |
| Veröffentlichungsdatum | 18. November 2024 | 30. Januar 2025 |
| Architektur | Hopper | Blackwell |
| GPU-Speicher | 141 GB HBM3e | 32 GB GDDR7 |
| Speicherschnittstelle | 6144-Bit | 512-Bit |
| Speicherbandbreite | 4,8 TB/s | 1,792 TB/s |
| NVIDIA-Decoder | 7x NVDEC & 7x JPEG | 3x 9. Generation |
| CUDA-Kerne | 16.896 | 21.760 |
| Tensor-Kerne | 528 | 680 |
| Gesamtgrafikleistung | bis zu 700 W | 575 W |
H200 vs. 5090: Umfassender Leistungsvergleich
Die H200 SXM und RTX 5090 von NVIDIA bedienen zwei grundlegend unterschiedliche Märkte. Während die RTX 5090 entwickelt wurde, um Consumer- und Creator-Workloads auf ein neues Level zu heben, ist die H200 SXM speziell für KI im Rechenzentrums-Maßstab konzipiert, wo Durchsatz, Speicherkapazität und Cluster-Bereitstellung entscheidend sind.
Um eine kluge Entscheidung zu treffen, ist es unerlässlich, zu bewerten, wie ihre Stärken zu Ihren tatsächlichen Workload-Anforderungen passen.
🟩 RTX 5090: Die High-End-Consumer-GPU
Entwickelt für Enthusiasten, Entwickler und Creator, konzentriert sich die RTX 5090 auf rohe Geschwindigkeit, Flexibilität und breite Anwendungsabdeckung. Sie ermöglicht schnelle Iterationen und KI-Experimente, solange das Modell in den Speicherbudgets von Consumer-GPUs passt.
- Maximaler Durchsatz für lokale Prototypenentwicklung
Dank ihrer extrem breiten Speicherbandbreite und leistungsstarken Tensor-/RT-Kernen glänzt sie bei schneller Modelliteration, Rendering und gemischten Creative-AI-Workflows.- Günstiger Einstieg in High-End-KI
Als Consumer-GPU bietet sie ein hervorragendes Preis-Leistungs-Verhältnis für Nutzer, die modernste Rechenleistung ohne Enterprise-Infrastruktur wünschen.- Konstante Echtzeit-Reaktionsfähigkeit
Die hohen Taktfrequenzen und die effiziente Architektur der RTX 5090 ermöglichen stabile Frame-Generierung und schnelle Inferenz-Zyklen, ideal für Tests oder Live-Creative-Sessions, bei denen Latenz eine Rolle spielt.- Optimierte KI-Entwicklung und -Bereitstellung
Die RTX 5090 ermöglicht effiziente lokale Feinabstimmung, Inferenz und Modelloptimierung, sodass Entwickler KI-Workloads nahtlos iterieren und skalieren können, ohne auf komplexe Cloud-Infrastruktur angewiesen zu sein.
🟦 H200 SXM: Die High-End-Enterprise-KI-GPU
Entwickelt für missionskritische Rechenzentrums-Bereitstellungen, priorisiert die H200 Speicherkapazität, Durchsatz-Effizienz und Multi-GPU-Skalierbarkeit für moderne generative KI-Systeme.
- Massiver Speicher für produktionsreife Modelle
Ausgestattet mit 141 GB HBM3e bewältigt sie große Sprachmodelle, dichte Retrieval-Aufgaben und Langkontext-Inferenz mit minimalem Sharding-Overhead.- Hochzuverlässige Enterprise-Leistung
Entwickelt für konsistente Betriebszeit, thermische Effizienz und streng kontrollierte Fehlerkorrektur für missionskritische Workloads.- Maximierte Cluster-Effizienz
NVLink und NVSwitch der fünften Generation unterstützen eine hochbandbreitige Verbindung zwischen mehreren GPUs, ideal für verteiltes Training und Skalierung von LLMs.- FP8- und Transformer-Engine-Optimierung
Beschleunigt state-of-the-art generative KI und ermöglicht herausragenden Trainings- und Inferenz-Durchsatz in optimierten Frameworks (NVIDIA NIM, TensorRT-LLM).
Fazit
- RTX 5090 → Am besten geeignet für Einzelpersonen oder kleine Teams, die Geschwindigkeit, Flexibilität und Kosteneffizienz in lokalen Workflows priorisieren – ideal für schnelle Prototypenentwicklung und kreative KI.
- H200 SXM → Am besten geeignet für Enterprise-KI-Umgebungen, die Skalierbarkeit, massiven Speicher und äußerst zuverlässige Rechenleistung für großangelegte Bereitstellungen und 24/7-Stabilität benötigen.
Welche sollten Sie wählen?
Die Wahl zwischen der RTX 5090 und der H200 SXM hängt letztendlich von Ihrer Bereitstellungsumgebung, Ihrem Budget und der Größe Ihrer Modelle ab – nicht nur von Leistungswerten auf dem Papier.
Wie groß sind die Modelle, die Sie lokal ausführen möchten?
Wenn Ihre Modellgewichte (plus KV-Cache und Aktivierungen) in 32 GB VRAM passen (oder dorthin quantisiert werden können), ist die RTX 5090 eine hervorragende lokale Lösung.
Wenn sie diese Grenze überschreiten oder hochdurchsatzfähige verteilte Rechenleistung erfordern, ist die H200 SXM speziell für diesen Maßstab konzipiert.
🔍 Schnelle Entscheidungshilfe
| Ihr Bedarf / Anwendungsfall | Empfohlene GPU | Grund |
|---|---|---|
| Schnelle Iteration, lokale KI-Prototypenentwicklung, kreative Workloads | RTX 5090 | Starkes Preis-Leistungs-Verhältnis + breite Workload-Unterstützung |
| 7B–14B-Modelle in FP16 oder 30B quantisiert | RTX 5090 | 32 GB VRAM reichen für die meisten mittelgroßen LLMs aus |
| ≥70B-LLMs, Langkontext-Inferenz | H200 SXM | 141 GB HBM3e gewährleisten die vollständige Resident von Modell + KV-Cache |
| Missionskritische Produktionsbereitstellungen | H200 SXM | Enterprise-Zuverlässigkeit, ECC-Speicher, thermische Regelung |
| NVLink-Multi-GPU-Skalierung & Cluster | H200 SXM | Konzipiert für paralleles Training und verteilte Workloads |
| Hohe Gleichzeitigkeit und Durchsatz | H200 SXM | Optimiert für Rechenzentrums-Workloads |
H200 vs. 5090: Preise
| GPU | Typischer Preis | Hinweise |
|---|---|---|
| RTX 5090 | ~ 1.999 US$ (UVP) | Consumer-Grafikkarte, 32 GB GDDR7-Speicher, für Gamer und Creator entwickelt. |
| H200 SXM (einzelne GPU) | 30.000 ~ 40.000 US$ pro Einheit | Rechenzentrums-GPU, 141 GB HBM3e-Speicher, für großangelegte KI-Bereitstellungen entwickelt. |
| H200-Serie (Board/System) | 4-GPU-Board ≈ 175.000 US$, 8-GPU-Board ≈ 308.000 ~ 315.000 US$ |
Komplettes Multi-GPU-System mit mehreren H200-Einheiten, NVLink-/NVSwitch-Board und Server-Infrastruktur. |
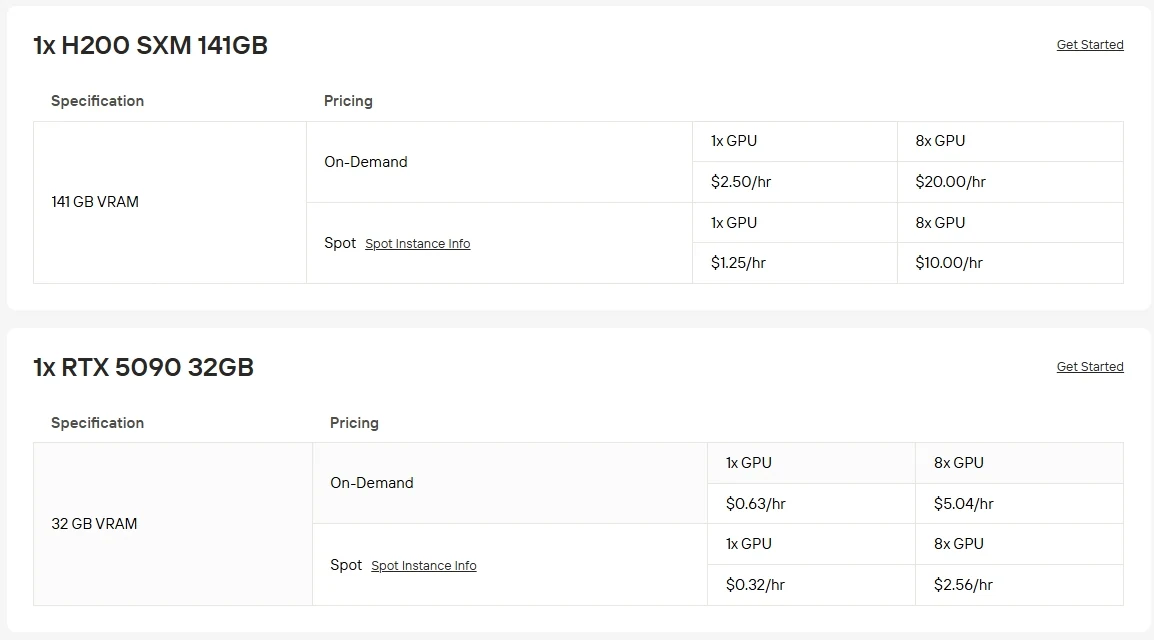
Der Betrieb von Top-GPUs auf eigener Hardware kann teuer und aufwändig zu warten sein. Mit dem GPU-Instance-Dienst von Novita AI können Sie schnell Cloud-Zugriff auf eine RTX 5090 für nur 0,63 $/h oder eine H200 SXM für 2,5 $/h erhalten, ohne lokale Einrichtung. Sie können außerdem aus mehreren Abrechnungsoptionen wählen: Spot-Instances bieten niedrigere Preise bei schwankender Verfügbarkeit, On-Demand lässt Sie nur bei Nutzung zahlen und Abonnement-Pläne bieten konsistente Einsparungen für stabile, langfristige Workloads.
Starten Sie mit flexiblen GPU-Instances auf Novita AI
Novita AI bietet skalierbare RTX 5090 und H200 GPU-Ressourcen in der Cloud, sodass Sie keine teure Hardware für rechenintensive Workloads kaufen und verwalten müssen.
Schritt 1: Registrieren Sie Ihr Konto
Erstellen Sie Ihr Novita-AI-Konto über unsere Website. Nach der Registrierung wechseln Sie zum Reiter „GPUs“, um verfügbare Ressourcen anzusehen und loszulegen.
Testen Sie RTX 5090 & H200 jetzt
Schritt 2: Wählen Sie Ihre GPU
Wir bieten mehrere vorkonfigurierte Vorlagen für unterschiedliche Anforderungen und geben Ihnen gleichzeitig die Flexibilität, eigene benutzerdefinierte Vorlagen zu erstellen. Mit Zugriff auf leistungsstarke RTX 5090 und RTX 6000 Ada GPUs mit viel VRAM und RAM ermöglicht unser Dienst effizientes Training selbst für hochkomplexe KI-Modelle.
Vorkonfigurierte Vorlagenbibliothek
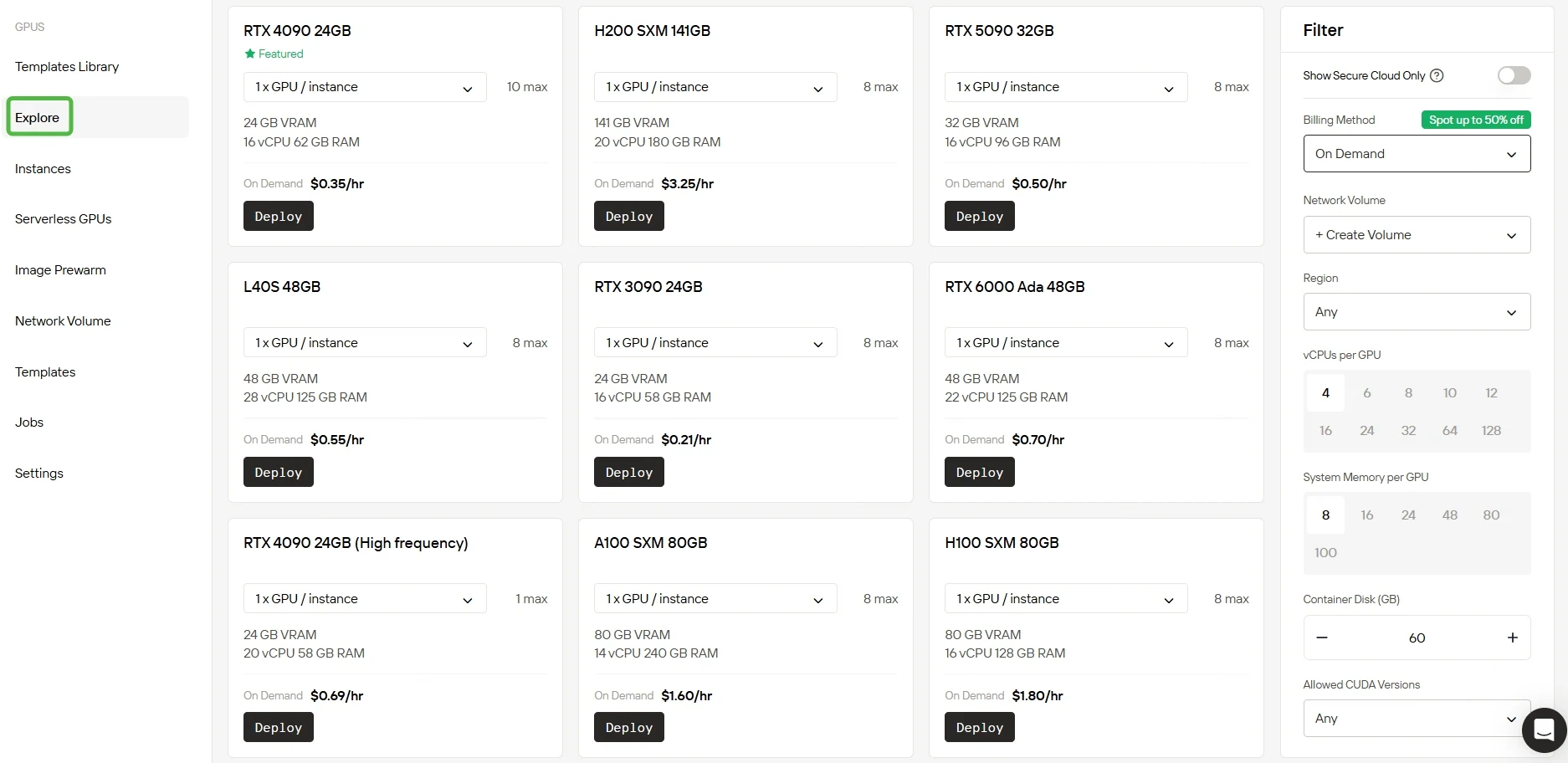
Entdecken Sie vielfältige GPU-Optionen
Schritt 3: Passen Sie Ihre Bereitstellung an
Richten Sie Ihre Umgebung mit dem Betriebssystem und der Konfiguration ein, die Ihren Rechenanforderungen entsprechen, und optimieren Sie den Durchsatz für KI-Workloads. Sie erhalten zu Beginn 60 GB freien Container-Speicherplatz, mit einfacher Skalierung auf zusätzlichen Speicher, wenn Ihr Projekt wächst.
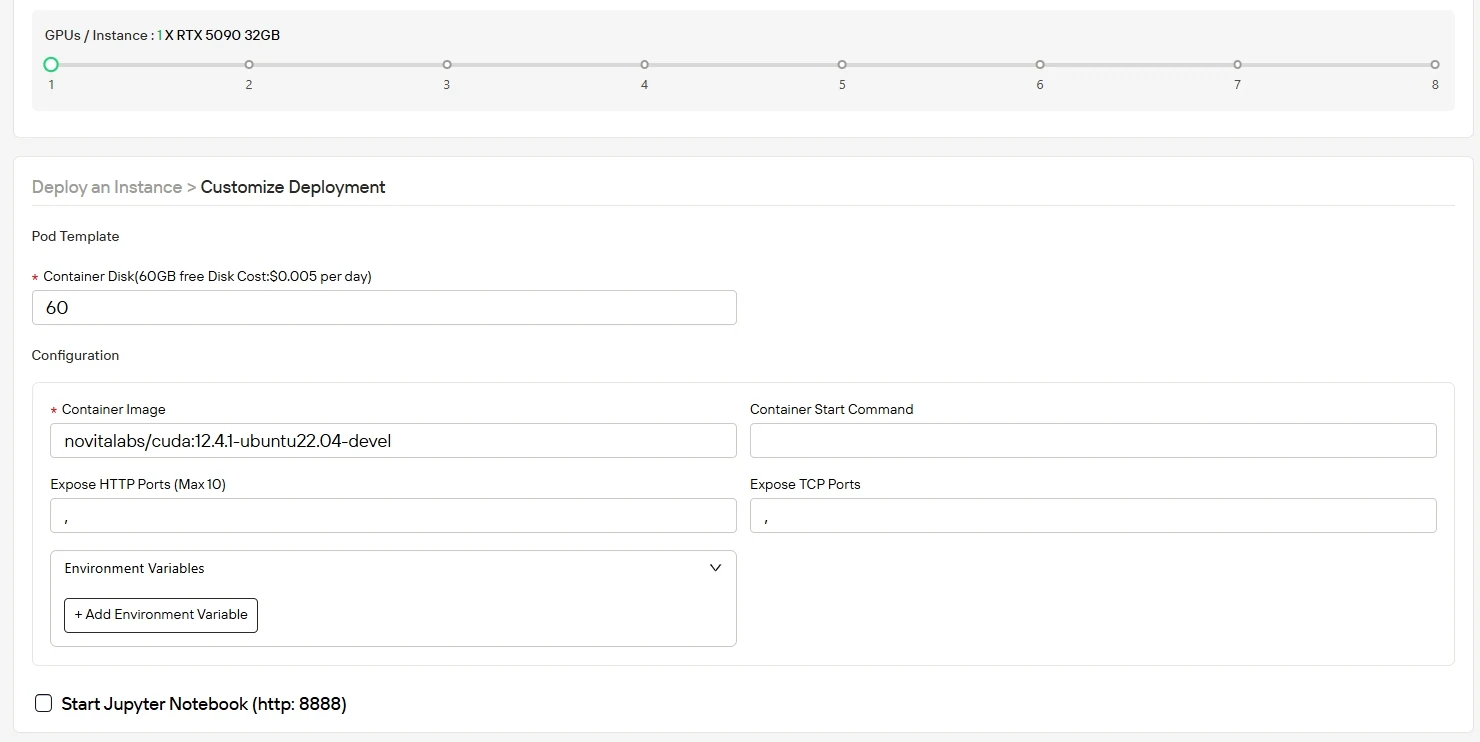
Schritt 4: Starten Sie Ihre Instance
Klicken Sie auf „Bereitstellen“, um Ihre Bereitstellung zu starten. Innerhalb weniger Minuten ist Ihre leistungsstarke GPU-Umgebung einsatzbereit, sodass Sie sofort mit Machine-Learning-, Rendering- oder Rechenprojekten beginnen können.
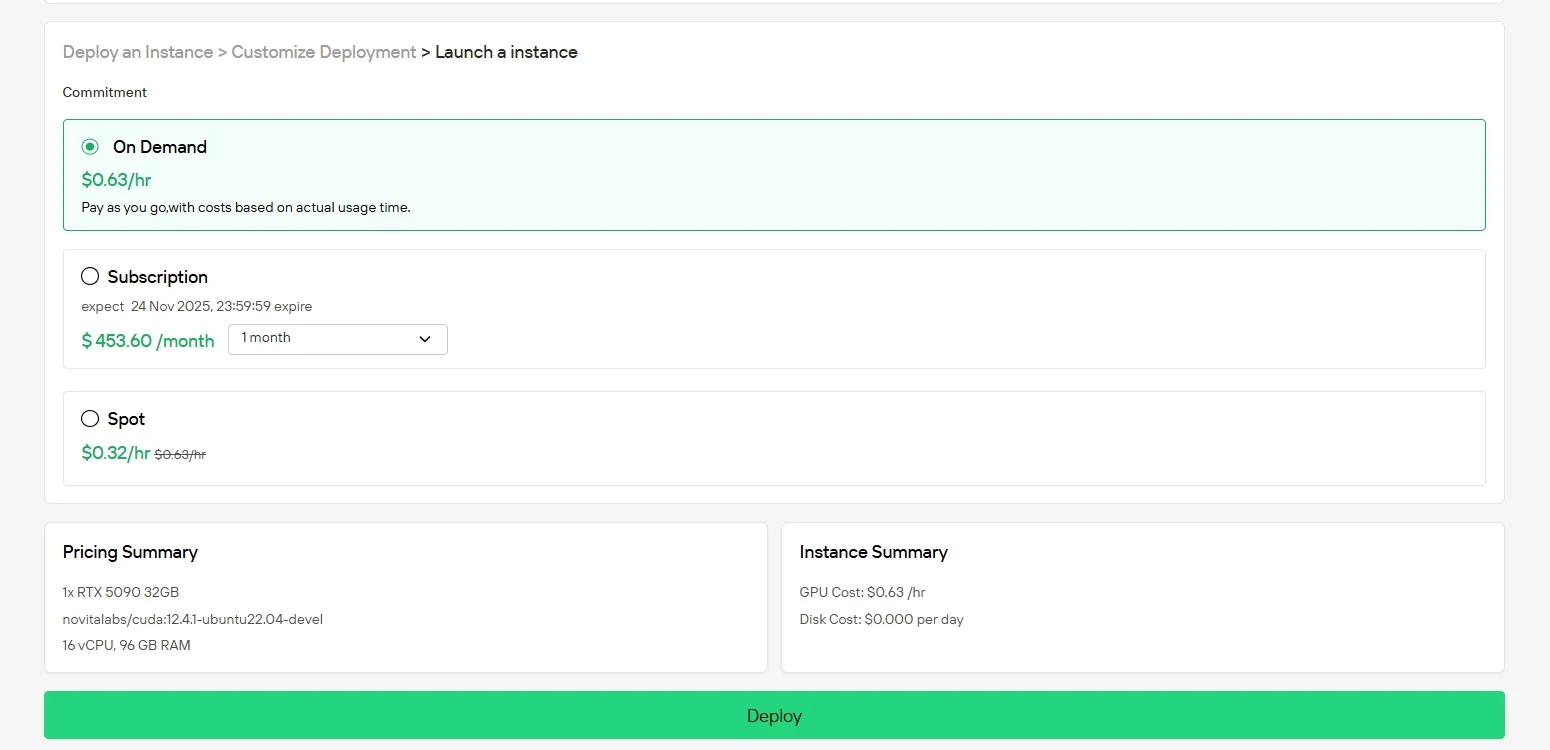
Häufig gestellte Fragen
Was ist der Hauptunterschied zwischen der RTX 5090 und der H200 SXM?
Die RTX 5090 ist eine Consumer-GPU, die für leistungsstarke Desktops entwickelt wurde; im Gegensatz dazu ist die H200 SXM eine Rechenzentrums-GPU, die für großangelegte KI-Bereitstellungen konzipiert ist, mit Enterprise-Zuverlässigkeit, NVLink-Skalierbarkeit und massivem HBM3e-Speicher zur Unterstützung großer Modelle und hochdurchsatzfähiger Workloads.
Welche KI-Workloads erfordern tatsächlich eine H200 SXM?
Workloads mit 70B±Modellen, Langkontext-Inferenz, verteiltem Training oder hoher Gleichzeitigkeit profitieren erheblich von dem Speicher und der Verbindungsbandbreite der H200.
Reicht die RTX 5090 aus, um große Sprachmodelle lokal auszuführen?
Ja – solange das Modell in 32 GB VRAM passt oder dorthin quantisiert werden kann. Modelle mit 7B–14B Parametern laufen reibungslos; 30B können mit aggressiven Optimierungen funktionieren.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Erstellen und Skalieren von Anwendungen bereitstellt.



